
Today, Roboflow is announcing Inference 1.0, the most trusted and reliable vision AI inference engine.
As vision AI has entered a period of exponential growth, the technology must evolve to continue serving the needs of the ecosystem. Processing visual data like images, videos, and real-time streams at enterprise scale is compute intensive and models need to be optimized to fully utilize the latest GPUs for real-world applications.
Inference 1.0 is built specifically to handle these unique requirements. The newest version is a modular execution engine with architectural maturity and high-performance, multi-backend support. This gives enterprises a single engine to deploy vision systems at the edge or in the cloud, grounded in four core primitives high scale visual understanding applications require:
- Fast model loading and inference
- Optimized CPU and GPU resource utilization
- Modularity and extensibility
- Separation between serving and model runtime
Over 1 billion inferences a week are already being processed with the new Inference 1.0 engine, supporting applications using models like RF-DETR, Segment Anything models, vision-language models (SmolVLM, Qwen3-VL, PaliGemma, Moondream2), OCR, embedding generation (CLIP, Perception Encoder) and YOLO architectures.
Inference 1.0 upgrades and performance benchmarks
The new Inference engine increases throughput significantly across a variety of models on cloud and edge GPUs.
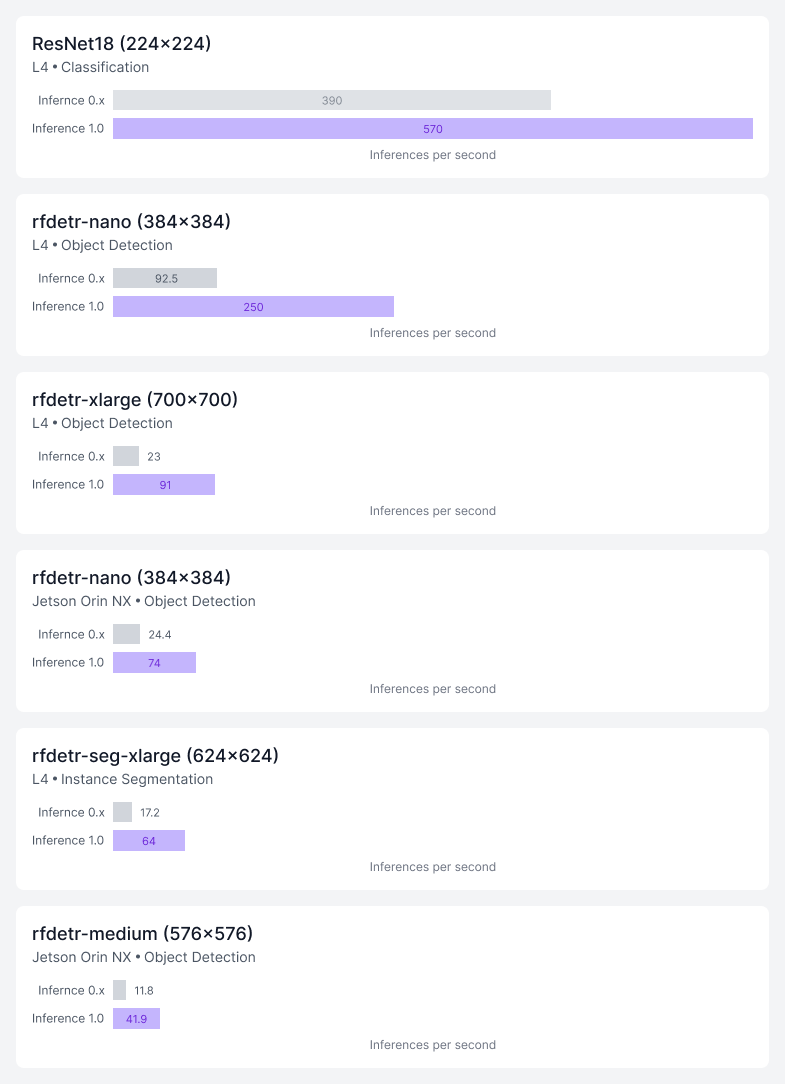
The 1.0 release provides a new core execution engine with multi-backend support for ONNX, PyTorch, and TensorRT. This means the server automatically chooses the best runtime for the underlying hardware (e.g., utilizing CUDA/TensorRT on NVIDIA GPUs or optimized ONNX on CPUs) automatically.
In addition to supporting different runtimes for general speed enhancements, 1.0 has optimizations that further improve overall latency. Cold-start logic reduces the time it takes to swap or load new models into memory, resulting in faster model loading and dynamic batching and multi-threading handles concurrent requests more effectively, optimizing GPU/CPU utilization during high-throughput scenarios, like processing 30fps video streams from multiple cameras.
Beyond performance, the new release makes Inference easier to use in production. Cleaner abstraction between the serving layer (HTTP/REST/gRPC) and the model runtime makes the system more modular and easier to debug or extend. Whether you’re deploying to a Jetson at the edge, a local Docker container, or a scalable Cloud cluster (GCP/Azure/AWS), the environment is abstracted away.
One Engine, Deploy Anywhere
You can self-host or use Inference 1.0 with Roboflow Cloud services. Inference allows you to use the exact same API and integration logic regardless of where a model or workflow is physically hosted.
Use Inference 1.0 in Roboflow Cloud
For teams that prefer not to manage complex infrastructure, Inference 1.0 is available natively within Roboflow Cloud. This provides a fully managed, production-grade inference solution that scales effortlessly with your business needs.
Whether you need dedicated deployments for sustained, real-time throughput or batch processing for large-scale asynchronous workloads, Inference 1.0 adapts to your specific use case. Inference is specifically tuned for vision AI, providing an optimized infrastructure that cuts compute costs significantly compared to alternative cloud providers. Beyond compute costs, we handle the server orchestration and scaling spikes so your team doesn't have to manage the underlying infrastructure.
Just like with the rest of the Roboflow platform, data privacy is built into the foundation of our cloud and we never store your inference inputs or outputs. Roboflow Cloud is SOC 2 Type II certified and HIPAA compliant, ensuring you can confidently deploy mission-critical applications that meet the highest regulatory standards.
Self-host Inference 1.0
Complete backwards compatibility makes Inference 1.0 a drop-in replacement for previous versions (enabled via the USE_INFERENCE_MODELS flag), allowing for easy testing and painless migration for anyone self-hosting Inference. With newly optimized runtimes, you'll achieve significantly better GPU utilization and higher overall output. This means you can process more inferences with less compute, actively driving down your hardware costs. For access to the optimized and pre-compiled TensorRT weights, connect with our Sales team.
With the underlying hardware environment hidden behind a clean interface, you can change infrastructure without rewriting your application. If you decide to move your models from a local Docker container to a cloud instance, you don't have to overhaul your codebase. The Inference engine handles the translation to the new hardware in the background.
Whether you deploy on edge devices or directly inside your own cloud infrastructure, self-hosting Inference gives you control over data residency. By ensuring your data never leaves your environment, it's easier than ever to meet strict in-house security requirements and adhere to regulatory standards like GDPR, HIPAA, and more.
Conclusion
Inference 1.0 is built to power a future where all visual data can be turned into visual understanding.
By stripping away hardware dependencies and infrastructure headaches, we’re giving enterprises the freedom to focus on what actually matters: solving real-world problems.
Whether you’re putting a model on a remote drone in the field or analyzing millions of images in the cloud, Inference is the fast, reliable foundation you need to make it happen. We are moving vision AI out of the research lab and into everyday life, and we can't wait to see the incredible things you create.
Start building using the latest version to run locally, or try it out in Roboflow Cloud.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Mar 12, 2026). Inference 1.0: Foundational Infrastructure for Visual Understanding. Roboflow Blog: https://blog.roboflow.com/inference-1-0/