
Liquid neural networks are continuous-time recurrent networks, developed at MIT, whose neurons adapt their dynamics to incoming data instead of learning one fixed input-to-output mapping.
Since MIT's original research in 2021, liquid neural networks have moved from paper to product: closed-form variants removed the original speed penalty, liquid networks have flown drones through environments they never saw in training, and Liquid AI, the MIT spin-off, now ships foundation models built on the architecture, including compact vision-language models that run on edge hardware.
This post explains what liquid neural networks are, what they are good at, how to experiment with them, and where they fit in a computer vision stack today.
The Backdrop: Before Liquid Neural Networks
Artificial intelligence research and applications involve the construction and training of deep neural networks. Until liquid neural networks, all deep learning systems have shared the same vulnerability - namely, that they learn a fixed mapping from input data to output prediction based on the training data that they are shown, making them brittle to the shifting environment around them.
Furthermore, most deep learning models are context independent. For example, when applying an object detection model or a classification model to a video, the video will be processed frame by frame without relying on the context around it.
Inferring frame by frame (without context) on the Roboflow Ranch
To fix this problem, developers and engineers using artificial intelligence typically gather very large, representative datasets and engage in active learning to continuously improve their systems through re-training cycles as new edge cases are discovered.
However, all of this re-labeling, re-training and re-deployment can be tedious - wouldn't it be nice if the network you were using learned to adapt to new scenarios online?
Enter the Liquid Neural Network.
What Is a Liquid Neural Network?
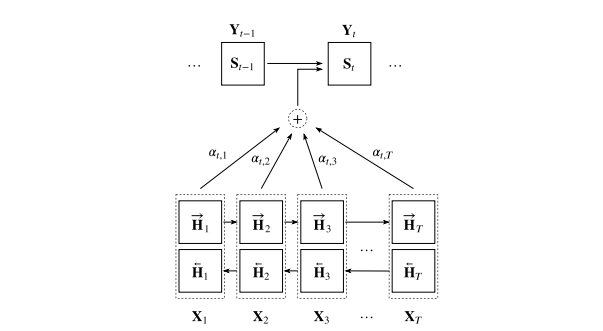
Liquid neural networks, introduced by Ramin Hasani and colleagues at MIT, attack both weaknesses. They are a form of recurrent network built from liquid time-constant (LTC) neurons: instead of a fixed activation, each neuron's behavior is governed by a differential equation whose time constant changes with the input. The network's hidden state evolves continuously in time, so its response adapts to the data flowing through it.
Two properties made the original paper notable: strong performance on sequence tasks with remarkably small networks, and interpretability, since a system of tens of neurons can be inspected in a way a million-parameter block cannot. The famous demonstration steered a car with 19 liquid neurons.
The original formulation required a numerical ODE solver at every step, which made it slow. The follow-up closed-form continuous-time (CfC) networks solved the governing equations analytically, removing the solver and making liquid networks fast enough to be practical.

What Liquid Networks Are Good At
The architecture's home turf is sequential data: time series, sensor streams, and control. The most striking vision-adjacent result came in autonomous flight: MIT researchers trained liquid networks to pilot drones toward targets in the woods, then deployed them in urban environments, in winter, and under distribution shift, where they kept working while conventional policies failed.
The network learned the task's causal structure (head toward the target) rather than memorizing the training scenery, which is precisely the robustness that fixed-mapping models lack.
That out-of-distribution resilience, achieved with networks small enough to run on tiny flight controllers, is why liquid networks draw attention for robotics, drones, and edge deployment.
Try One: The ncps Package
Liquid networks are a pip install away. The ncps package (Neural Circuit Policies), maintained by the architecture's authors, provides LTC and CfC layers for both PyTorch and TensorFlow:
pip install ncpsimport torch
from ncps.torch import CfC
model = CfC(input_size=20, units=50)
x = torch.randn(2, 3, 20) # batch, sequence, features
output, hidden_state = model(x)A CfC or LTC layer drops in where you would use an LSTM or GRU. The common vision pattern pairs a convolutional feature extractor with a liquid layer on top: the CNN sees each frame, the liquid network carries the temporal state across frames. That is the arrangement behind the drone results.
Liquid Foundation Models
The clearest signal of the architecture's maturity is Liquid AI, the MIT spin-off founded by the researchers behind the papers. Its LFM2 family of foundation models uses a hybrid architecture descended from the liquid line of work, built for fast on-device inference rather than datacenter scale.
The family now spans language models small enough for phones (LFM2.5) and compact vision-language models: LFM2.5-VL-450M packs image understanding with bounding box prediction into 450 million parameters that run on hardware like Jetson Orin modules and flagship phone SoCs.
Where Liquid Networks Fit in a Vision Stack Today
For the core perception tasks, detecting, segmenting, and classifying objects in images, liquid networks are not the tool. Transformer-based detectors hold the accuracy-latency frontier; RF-DETR leads real-time models on COCO and on RF100-VL, the benchmark for transfer to real-world domains, and is what you should train for a custom detection task.
Where liquid ideas earn a place is above and around the detector: temporal reasoning over sequences of detections, control policies that act on what a camera sees, and compact multimodal models at the edge. And the problem liquid networks were conceived to address, models that degrade as the world shifts, still gets solved operationally today: monitor production inference, pull the failures into your dataset, retrain, and redeploy. Roboflow automates that loop, and it works with whatever architecture sits at the center of it.
How do liquid neural networks compare to transformers?
They optimize for different things. Transformers scale with data and parameters and dominate perception and language benchmarks. Liquid networks excel at continuous-time sequential tasks with tiny parameter counts, strong out-of-distribution behavior, and low power draw. Liquid AI's foundation models borrow from both.
Can I train a liquid neural network myself?
Yes. The ncps package provides LTC and CfC layers for PyTorch and TensorFlow, and they slot into a training loop the way an LSTM does. The original research code is also public.
Should I use a liquid neural network for object detection?
No. Train RF-DETR for detection and segmentation tasks; it is more accurate, faster to fine-tune, and production-proven. Consider liquid architectures for the temporal or control layer that consumes the detector's output.
Conclusion
Liquid neural networks went from a striking paper to shipped edge models in a few years, and they are worth watching, especially if your work involves control, drones, or tight power budgets. For the vision model at the center of your application, create a free Roboflow account, train RF-DETR on your data, and let the retraining loop handle the shifting world.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Feb 12, 2026). Liquid Neural Networks in Computer Vision. Roboflow Blog: https://blog.roboflow.com/liquid-neural-networks/