
A company has just built a highly accurate computer vision model to detect tiny defects in automotive parts. After weeks of training and testing, the model performs flawlessly on paper. Confident in the results, the team deploys it on the factory floor. But as soon as it goes live, problems begin to appear. The lighting on the assembly line is different, camera angles vary, and parts move faster than expected. The model starts missing defects it once caught with ease.
What went wrong?
This is the challenge of model deployment, the critical step where a machine learning model moves from the lab into the real world. It's not just about having a smart model; it’s about making sure that model works reliably in real, unpredictable environments. In this blog, we’ll explore what model deployment is, walk through a real-world use case in manufacturing, what are popular model deployment tools, and see how tools like Roboflow simplify the lifecycle from development to production, whether you are deploying in the cloud, at the edge, or in a browser.
What Is Model Deployment?
Model deployment is the stage in the machine learning lifecycle where a trained and validated ML model is transitioned into a production (real‑world) environment, making its predictions available to users, applications, or systems.
In simpler terms:
- A model is trained and validated during development.
- Deployment makes it operational, allowing it to accept inputs, process them, and return outputs (inferences) in real‐time or batch scenarios.
- Until deployment, the model remains a theoretical asset; post-deployment, it can deliver business value through automation, insights, or decision support.
Model deployment is the engineering phase in the machine learning lifecycle where a trained, validated ML model is integrated into a production environment. Once deployed, the model becomes operational and is able to receive input (like data or requests), run inference, and return outputs.
In essence:
- It moves a model from development/test to real-world usage.
- The model is made accessible, typically via APIs or services.
- This transition is essential for delivering real business value.
Key concepts:
Model deployment vs. serving: Serving is a subset of deployment, it provides an API endpoint for inference. Deployment includes packaging, infrastructure, security, scaling, and integration.
Production readiness: Deployment ensures the model is scalable, secure, versioned, and can be monitored and maintained continuously.
How Model Deployment Works: Computer Vision Deployment Use Case in Manufacturing
Imagine a manufacturing company that builds precision-engineered automotive parts. They want to automate defect detection on their assembly line using computer vision. Here's the deployment workflow they would follow.
1. Model Development & Validation
To start, the team captures images of parts directly from the production line. These images are annotated to highlight defects like scratches, misalignments, or missing components. Using this labeled dataset, they train a custom computer vision model to identify these issues automatically. The model is then validated against a hold-out test set to confirm high accuracy and reduce false positives and missed detections before going live.
2. Packaging & Serving
Once the model is ready, it’s packaged along with any necessary preprocessing logic, like resizing or normalization, to ensure consistency. The entire pipeline is containerized, typically using Docker, so it can be deployed anywhere with the exact same setup.
3. Deployment & Serving Infrastructure
Next, the model is deployed to an environment optimized for real-time inference. This could be on edge devices at the factory or within a secure private cloud. A REST API endpoint (like /predict) is exposed, allowing production systems to send captured images and receive instant predictions on whether a part is defective, and what kind of defect it might have.
4. Integration and Scaling
The deployed model is integrated into the factory’s production control software. As demand increases or more lines come online, the system scales horizontally by adding more inference instances to handle multiple requests simultaneously without slowing down the line.
5. Monitoring & Maintenance
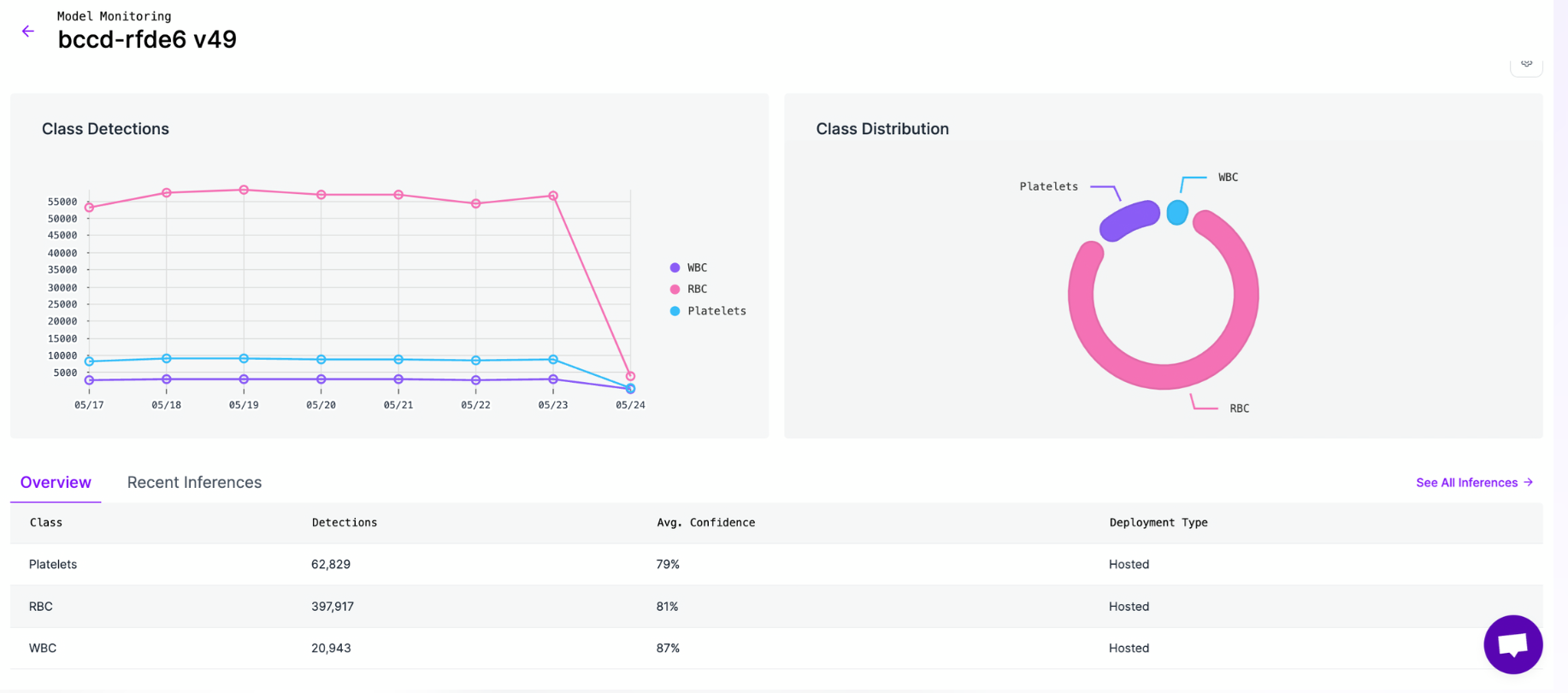
Once deployed, the model’s performance is continuously monitored. Metrics such as confidence scores, detection accuracy (track false alarms, missed defects, etc), and inference time are tracked in real time. If the environment changes - lighting shifts or new defects appear - the model is retrained or fine-tuned and redeployed through a version-controlled pipeline to keep performance sharp.
6. Real-World Operation
Now fully integrated, the vision system runs continuously as parts flow down the line. Each frame is analyzed in real time; defective items are flagged or removed immediately. Over time, the system generates valuable insights, like defect rates and trends, that inform root-cause analysis and continuous improvement. Leading automotive manufacturers like Audi already use similar systems to catch subtle defects in high-precision applications like welding and assembly.
Best Practices for Model Deployment
Here are best practices to follow when deploying an ML model.
Pre-Deployment Considerations
Before deploying a machine learning model to production, whether in the cloud, on a server, or on a factory floor it is important to make sure the model is efficient, reliable, and ready for real-world use. Here are three key things to focus on:
1. Pick the Right Model for Production: The best-performing model during training is not always the best for deployment. A smaller, faster model might give slightly lower accuracy but run 10× faster and use less memory. This can make a big difference when the model needs to respond quickly or run on limited hardware (like in edge devices or factory systems).
For example, in a manufacturing plant, a computer vision model might inspect parts on a conveyor belt. A heavy model with high accuracy might slow down the production line, while a lighter model with 95% accuracy and faster inference keeps everything moving smoothly. Tools like quantization and model pruning can help shrink large models without hurting performance much.
2. Test with Real-World Data: It is important to check how the model performs on real data in real environment, not just the clean, labeled data it was trained on. Real-world conditions can be messy, blurry images, poor lighting, or unexpected inputs.
Imagine the factory again the model was trained on clear, high-resolution photos of defect-free parts. But on the factory floor, it sees dusty, tilted, or half-visible parts. So before going live, test the model with images from the actual production environment to see how it handles these challenges.
3. Define What "Good" Means: Before deployment, decide what success looks like. This includes both accuracy and performance requirements. For instance, the model might need to detect at least 90% of defects, run each prediction in under 100 milliseconds, and work reliably 24/7. If it meets these goals during testing, it is likely ready for production. If not, adjustments might be needed, either to the model or the system around it.
Deployment Strategy and Infrastructure
Once your model is trained and tested, the next step is putting it into use. This means deciding how and where it will run. A good deployment strategy ensures your model runs smoothly, quickly, and reliably no matter what the environment.
Choose the Right Deployment Type: Different use cases need different deployment styles. Here are the main ones:
- Batch Deployment: Best for jobs that don’t need instant results. For example, analyzing a full day's worth of factory sensor logs overnight.
- Online Inference (APIs): Used when quick responses are needed. For instance, a web app where users upload product images and get defect predictions instantly.
- Edge Deployment: Ideal for low-power devices that work offline, like a small camera on a production line to detect faulty items in real-time without needing internet.
- Streaming Inference: Used for continuous, real-time data such as video or sound. For example, monitoring an assembly line with a video feed that checks every item as it moves.
Pick the type that matches your business needs, hardware, and response time requirements.
Package Your Model with Docker: To make your model easy to run anywhere, it is best to containerize it. Tools like Docker help you bundle the model, code, and all software dependencies into one portable package.
This means your model will run the same whether it is on your laptop, a factory server, or the cloud. It also avoids issues like “it works on my machine but not in production.”
Use a Model Serving Framework: Instead of building everything from scratch, use a tool designed to serve machine learning models. These tools:
- Handle incoming requests,
- Run predictions,
- Monitor performance, and
- Let you update models without stopping your system.
Popular frameworks include:
- TensorFlow Serving and TorchServe for TensorFlow or PyTorch models
- NVIDIA Triton for high-performance inference
- ONNX Runtime for cross-platform models
- Roboflow Inference for computer vision models
For example, if a factory uses a vision model to detect defects, Roboflow Inference can help deploy and update that model easily across devices, without having to write low-level code.
Monitoring and Logging
Once your model is deployed, the job is not over. You need to keep an eye on it, just like you monitor machines on a factory floor. If something goes wrong, slows down, or drifts off-target, you want to catch it quickly. That is where monitoring and logging come in.
Keep Track of Key Metrics: To make sure your model stays healthy and performs well, you need to track important metrics like:
- Latency: How long the model takes to respond to a request.
- Throughput: How many predictions it can handle per second.
- Error Rates: How often the model fails or gives bad results.
- Data Drift: When incoming data changes over time and no longer matches the data the model was trained on.
- Resource Usage: How much CPU, GPU, and memory the model is using.
For example, in a manufacturing plant using a computer vision model to check for defects, you would want to know:
- How quickly the model scans each item,
- Whether any part of the system is slowing down,
- If the defect detection rate drops suddenly (which could mean the data has changed, like lighting or camera angle).
Roboflow Model Monitoring feature offers a unified, streamlined way to keep tabs on your production models and catch issues early.
Log Inference Data (Securely): Besides monitoring performance, it is also important to log the inputs and outputs of the model. This helps you:
- Debug problems if predictions go wrong,
- Audit decisions for compliance or traceability,
- Collect data for improving or retraining your model later.
You should log things like:
- What data the model saw,
- What prediction it made,
- The confidence score,
- When it happened,
- And user feedback, if available.
In a factory, logs can show which parts were marked defective, at what time, and under what conditions helping you trace back issues and improve both the model and production process. But remember, if any of this data includes personal or sensitive information, you must protect it. Follow data privacy rules like GDPR and avoid storing anything that identifies people unless necessary and properly secured.
Security and Access Control
When you deploy a machine learning model, it becomes part of your live system and that means it needs protection. Just like you would secure access to factory machines or internal software, your model must be protected from misuse, tampering, or data leaks.
Secure Access to the Model: If your model is exposed through an API or web service, you should make sure only authorized users can access it. This is done using authentication methods like API keys or OAuth tokens. You should also apply rate limiting, which means controlling how often someone can use the API. This protects your system from abuse, such as people trying to flood it with requests or steal predictions.
For example, if your factory has a model that checks product quality and it is exposed through an internal API, only machines on the production line or trusted staff should be able to access it. No one else should be able to query it from outside the network.
Protect the Model Itself: In some cases, your model might be valuable intellectual property (IP). You have invested time and data to build it, and you don’t want someone to steal or reverse-engineer it. To prevent this:
- You can obfuscate the model or encrypt its files.
- Or, instead of sending the model to devices (like in mobile apps), keep the model on a secure server and only send back predictions. This way, the user never sees or touches the actual model.
For example, a manufacturer may use a custom-trained model to detect micro-defects. If competitors gain access to this model, they could replicate your inspection process. Serving predictions from a protected backend helps keep that model safe.
Roboflow Serverless Hosted API (Remote Prediction)
Roboflow provides model protection capability through its hosted API inference, also known as server-side inference. Roboflow allows you to host your model securely in the cloud (on Roboflow’s servers), and make predictions via an API call. This means:
- The model stays on the server; users never download or access the model file.
- You send image data (or URLs) to Roboflow’s secure API.
- The API returns the inference results (e.g., bounding boxes, classes, masks, depth maps, etc.).
- Useful for keeping your model IP protected, handling updates centrally, and offloading compute.
Benefits:
- No model file is distributed to edge devices (ideal for protecting proprietary models).
- Works well in mobile apps, web apps, or IoT devices that can call APIs.
- Easier to update models without pushing new app releases.
- Can support advanced pipelines with workflows.
Example:
# import the inference-sdk
from inference_sdk import InferenceHTTPClient
# initialize the client
CLIENT = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="API_KEY"
)
# infer on a local image
result = CLIENT.infer("YOUR_IMAGE.jpg", model_id="pcb-components-detection-p9j9r-xsqo6/3")
curl -X POST \
"https://serverless.roboflow.com/pcb-components-detection-p9j9r-xsqo6/3?api_key=API_KEY&image=URL_OF_YOUR_IMAGE"
You’ll receive structured JSON prediction results. This is the preferred method when you want to protect your model IP and control inference on the backend.
Protect Against Adversarial Attacks: Some users, or even attackers, might trick your model by feeding it specially crafted data. These are called adversarial attacks and they can make your model behave incorrectly without obvious signs.
For example, someone might slightly alter a product image in a way that is invisible to humans but causes the model to misclassify a defective item as “good.” These tricks can be harmful in sensitive applications like manufacturing or security.
To prevent this, test your model against adversarial examples and improve its robustness with techniques like adversarial training or input filtering.
Versioning and Rollbacks
As your machine learning models improve over time, you will want to update it in production. But just like software updates, model updates can sometimes introduce problems. That’s why it’s important to manage versions carefully and have a plan to roll back if something goes wrong.
Keep Track of Model Versions: Every time you train a new model, give it a version number just like software (e.g., v1.0.2). This helps you keep track of what’s running where, and makes it easy to switch between versions if needed. Also, tag each model with metadata like:
- What dataset it was trained on,
- Which version of the training code was used,
- And who trained it.
This makes troubleshooting and improvement much easier in the future.
For example, In a factory, if your defect detection model suddenly starts missing errors, versioning helps you quickly check if a recent update is causing error. You can compare v1.0.2 with the older v1.0.1 to see what changed.
Use Safe Deployment Strategies: Instead of switching the entire system to a new model at once, roll it out slowly:
- With a canary deployment, you release the new model to just a small part of the system (maybe one machine or a small batch of products). If it works well, you scale it up.
- With A/B testing, you run both the old and new models at the same time on different data or users, and compare results.
This way, if the new model performs worse or causes issues, you can roll back to the stable version without affecting the whole production line.
For example, a manufacturing company might test a new version of its vision model on just one inspection station. If defect detection accuracy drops, they quickly switch back to the older model while investigating the issue.
Roboflow keeps versioning by creating immutable, point-in-time snapshots of datasets including the images, annotations, preprocessing, and augmentations which are then used to train models that are explicitly associated with those dataset versions.
Testing and CI/CD for ML
Just like software, machine learning models need to be tested before they go live, and every time they get updated. Automating this process through CI/CD (Continuous Integration and Continuous Deployment) helps you move fast without breaking things, especially when your model is part of a bigger system like a smart factory or production line.
Test Your Model Like Software: Machine learning pipelines involve more than just the model. You also have data cleaning, feature extraction, post-processing, and API layers. All of these need to be tested. There are three main types of tests to set up:
- Unit Tests: Check that small parts of your code (like a function that scales sensor data or formats image input) behave as expected.
- Integration Tests: Make sure the full prediction pipeline works, including your model API and any supporting code.
- Regression Tests: Run the model on known inputs and confirm the outputs are still correct, helpful when updating the model to catch any unwanted changes.
For example, in a manufacturing plant, if a defect detection model is updated, you can run regression tests on a set of sample images to make sure it still detects the same defects it used to.
Use CI/CD to Automate the Process: Instead of manually retraining and deploying models, set up a CI/CD pipeline that does it for you. Whenever new data is added or the code is updated:
- The pipeline retrains the model,
- Runs all the tests,
- Packages it (e.g., into a Docker container),
- And optionally deploys it to staging or production.
This saves time and reduces errors, especially when models are updated frequently. For example, suppose your factory collects new defect data every day. A CI/CD setup can retrain your model every week using the new data, test it, and deploy it, without anyone having to do it manually.
Considerations for Different Platforms
Where you deploy your ML model matters. The platform, whether it is the cloud, a factory device, a mobile app, or a browser affects how the model should be built, optimized, and delivered. Each platform has different strengths and limitations, so your deployment plan should fit the environment.
Cloud Deployment: Cloud platforms make it easy to host your models. They handle the heavy lifting, like managing infrastructure, scaling resources, and securing APIs.
You can:
- Set up real-time endpoints for online predictions,
- Use auto-scaling so the system handles more traffic when needed,
- And retrain models easily with cloud pipelines.
For example, a manufacturer might send image data from factory cameras to a cloud-hosted model that inspects for defects. The cloud system handles multiple requests at once and scales up during busy hours.
Edge Devices: Edge deployment means running the model directly on small devices, like cameras, sensors, or embedded systems without needing a connection to the cloud. This is useful in environments where:
- Low latency is critical,
- Internet isn’t always available,
- Or data privacy is important.
For example, on a factory floor, a ML model might run on a local edge device to detect faulty items instantly without sending data to the cloud which help reduce delay and internet dependency.
Roboflow supports deployment across three main platforms:
- Cloud via the Serverless Hosted API or Dedicated Deployments with automatic scaling, GPU/CPU options, and centralized APIs.
- Edge deployment using Roboflow Inference, an open-source server you install on hardware like NVIDIA Jetson, Raspberry Pi, or PCs. Ideal for low-latency, offline, or privacy-sensitive setups, with full runtime control.
- Browser based SDK
roboflow.js, a JavaScript library built on top ofTensorFlow.js. It provides utilities for deploying computer vision models hosted on Roboflow directly within a web browser.
Model Deployment Tools
Model deployment is a crucial stage in the machine learning lifecycle, bringing trained models into production for real-world use. Various tools exist to streamline this process, each offering a unique set of features. Here are some popular tools:
Roboflow
Roboflow is a platform specifically designed for computer vision tasks, simplifying the process of building, training, and deploying computer vision models.
Important features for Model Deployment:
- Hosted Inference API: Provides a hosted API to receive predictions from trained computer vision models, making it easy to integrate models into applications.
- Edge Deployment: Offers options to deploy models to edge devices, including deploying Docker containers for private cloud or on-premise environments using their Inference Server.
- Model Training Integration: Allows one-click training of models using Roboflow Train and then provides a hosted API for inference directly.
- Autoscaling Infrastructure: The hosted inference service includes autoscaling capabilities with load balancing to handle varying inference loads.
- Offline Inference: Supports caching weights for up to 30 days to enable completely air-gapped or offline inference in locations with limited internet connectivity.
- Streamlined Workflow: Accelerates model deployment by integrating data preparation, automated data augmentation, seamless model training, and efficient deployment and monitoring within a single platform.
Amazon SageMaker
Amazon SageMaker is a fully managed service from AWS that covers the entire ML lifecycle, including data labeling, model building, training, and deployment.
TensorFlow Serving
TensorFlow Serving is a flexible, high-performance serving system for machine learning models. It's built by Google and focuses on efficient inference.
Google Vertex AI
Google Vertex AI is a unified platform from Google Cloud that provides all the tools needed to build, deploy, and scale ML models across the entire ML lifecycle.
Azure ML Studio
Azure ML Studio is a cloud-based environment from Microsoft Azure for building, training, and deploying machine learning models.
Model Deployment in Roboflow
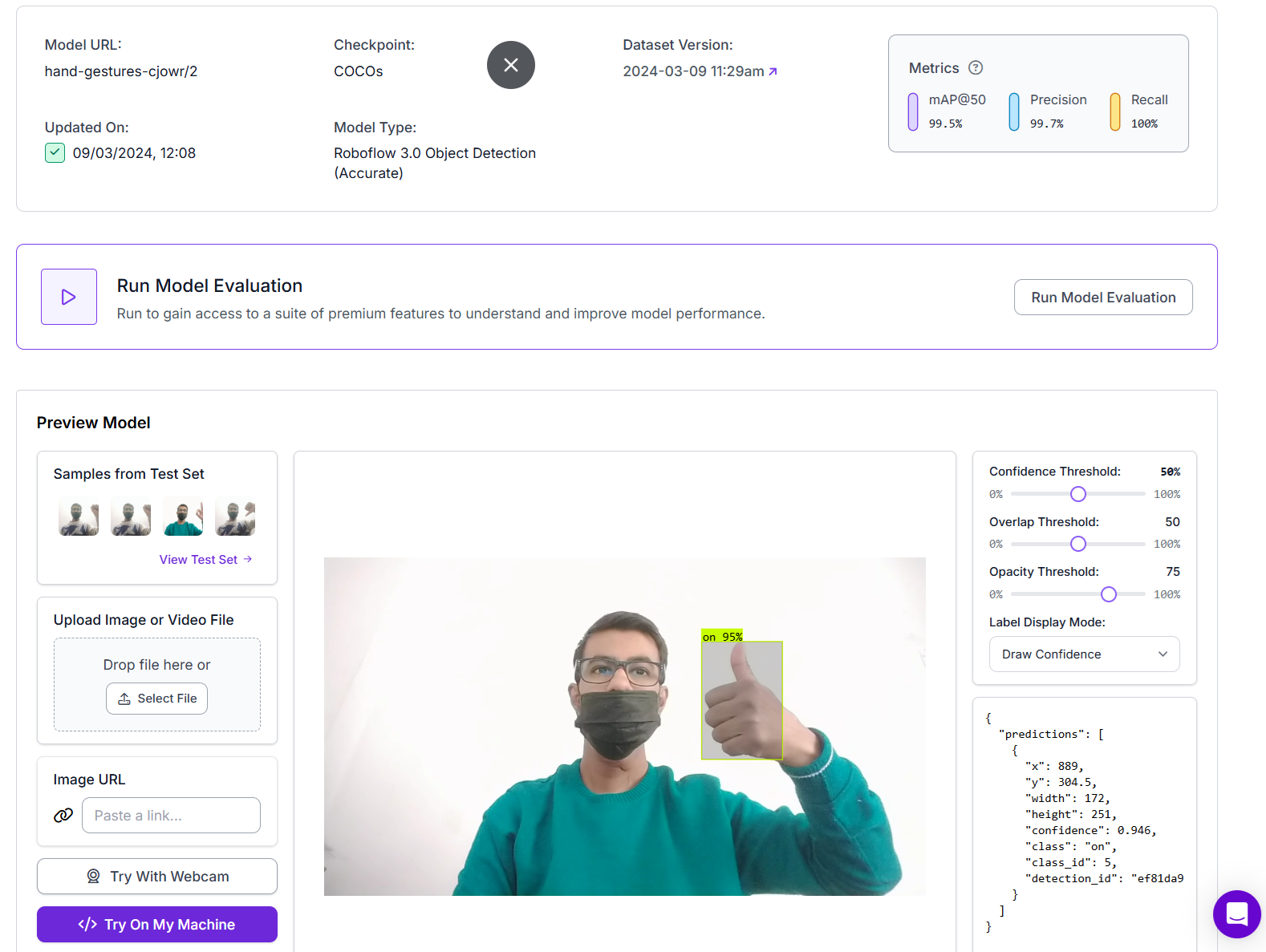
Here's how to easily deploy a computer vision model using Roboflow. We’ll walk through the process using a Hand Gesture Detection model I previously built with Roboflow. You can refer to the full guide for a more detailed walkthrough on how to build the model.
Following are the steps.
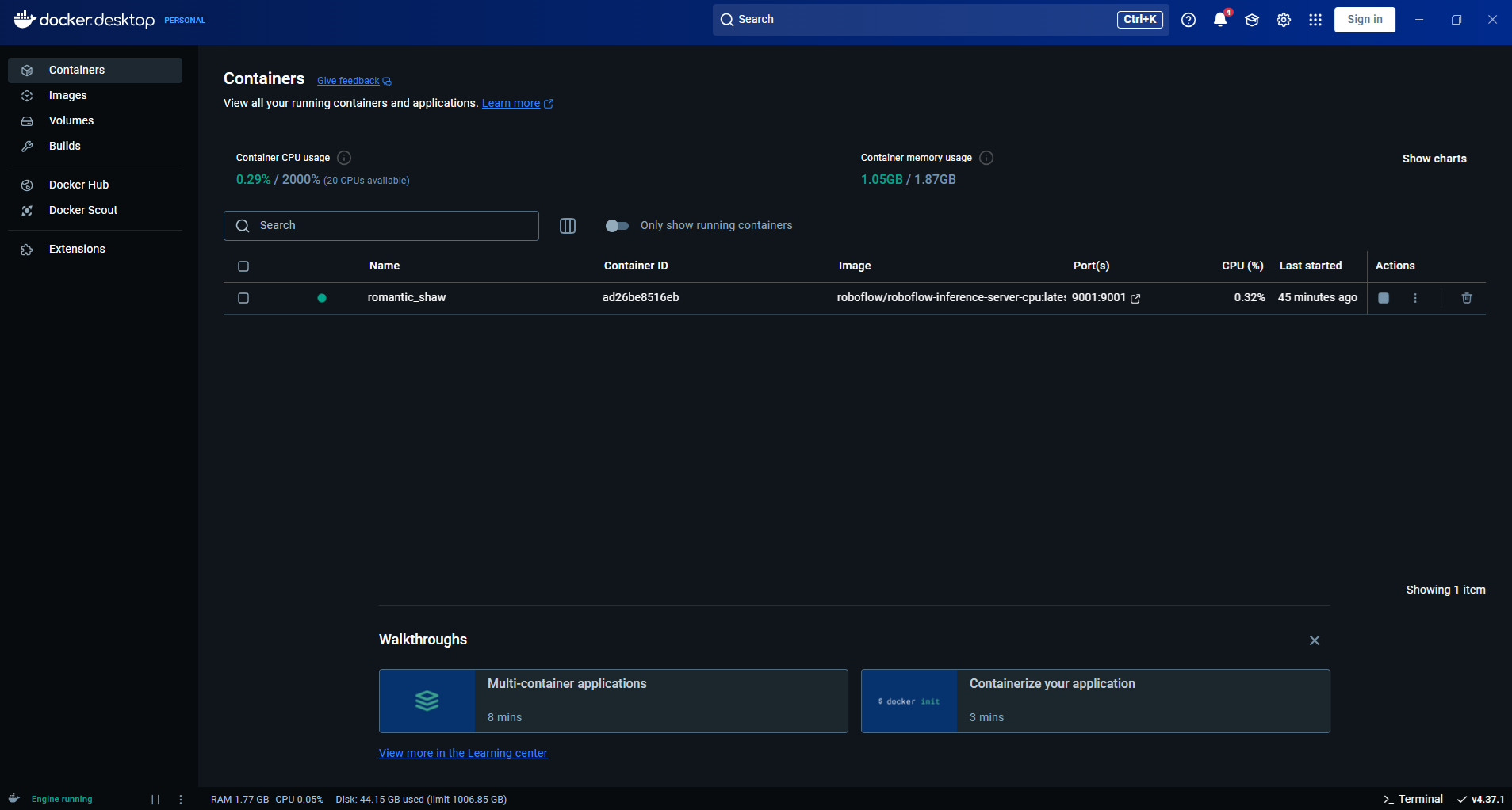
Step #1: Install Docker Desktop
Download and install Docker from docker.com.
Step #2: Install Roboflow Inference
You can install and run Roboflow inference server on local computer with following commands.
For CPU
pip install inference or, for GPU
pip install inference-gpuThe above commands installs Roboflow Inference core libraries and sets up all necessary runtime dependencies so your code can load and run models locally.
Spep #3: Starting the Inference Server Locally
The following command launches a lightweight inference server on your machineby default accessible at http://localhost:9001
inference server startIt internally runs a Docker container (CPU or GPU variant) with all necessary isolation and model-serving interfaces built-in and exposes an HTTP API for inference and workflow execution. It also includes a built‑in Jupyter notebook environment at http://localhost:9001/notebook/start for exploration and initial testing in development mode.
Step #4: Build the Roboflow Workflow
Build the Workflows as shown in image below.
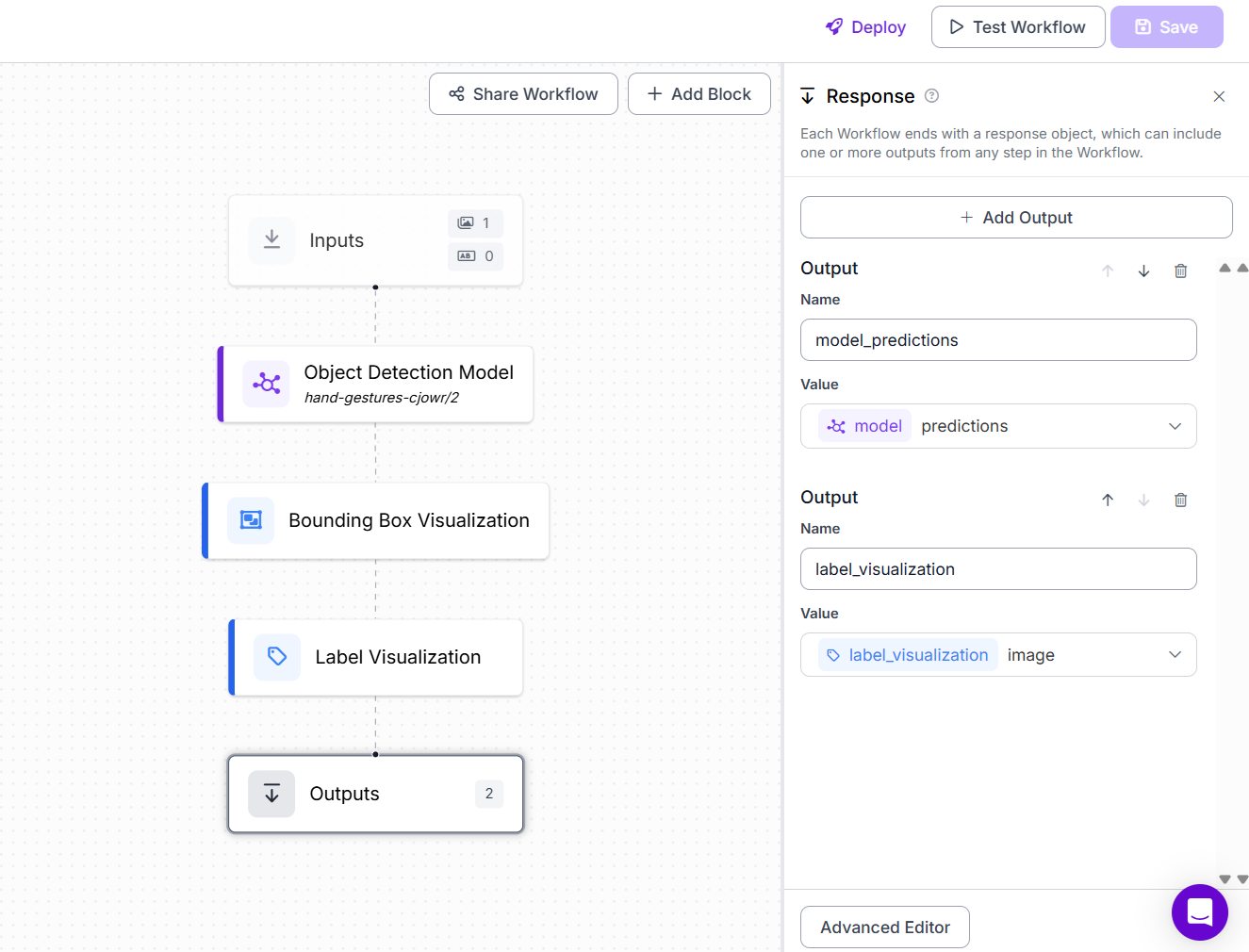
In Roboflow’s visual workflow editor:
- Add an Object Detection Block and configure it with your model: hand-gestures-cjowr/2
- Add Bounding Box Visualization Block
- Add Label Visualization Block
- Choose inference server and click connect.
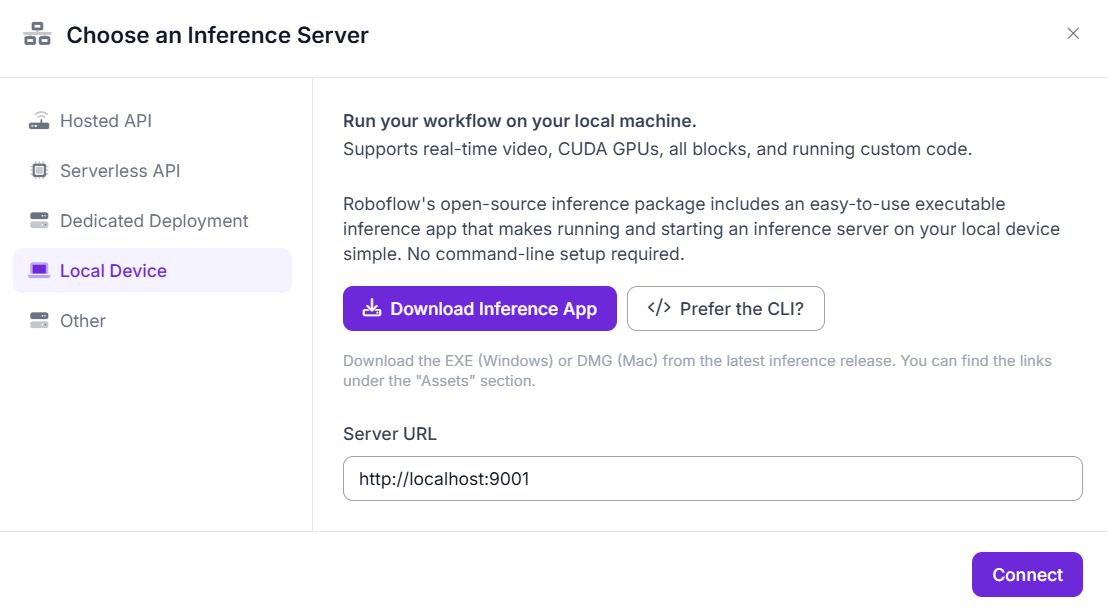
Step #5: Interacting via Python SDK
Once the server is running (from step #3), you use the Python HTTP SDK to communicate with it. Install the SDK on you local machine with following command.
pip install inference-sdkand use the following code to deploy the workflow to your local machine.
# Import the InferencePipeline object
from inference import InferencePipeline
import cv2
def my_sink(result, video_frame):
visualization = result["label_visualization"].numpy_image
cv2.imshow("Workflow Image", visualization)
cv2.waitKey(1)
# initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="API_KEY",
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-21",
video_reference=0, # Path to video, device id (int, usually 0 for built in webcams), or RTSP stream url
max_fps=30,
on_prediction=my_sink
)
pipeline.start() #start the pipeline
pipeline.join() #wait for the pipeline thread to finishThe code loads pre-trained Roboflow or Universe models and trigger a pre-defined pipeline with inputs image as defined in Roboflow Workflows. The following is the output when you run local inference.
Running Deployed Model on Local PC
Roboflow Inference gives you a fully functioning Roboflow inference environment, via Docker, on your local machine. You can then connect to it programmatically using the Python SDK or HTTP API to run workflows or model predictions efficiently and offline.
What actually happens in Inference?
When you run:
inference server start
Local Inference Server is Started: Roboflow launches a Docker container on your machine. This container runs a local inference API server (usually on http://localhost:9001). The server supports REST API calls and exposes endpoints for running models or full workflows.
Model or Workflow is Downloaded from Roboflow: When you first run inference on a When you first run inference on a specific model or workflow (e.g. hand-gestures-cjowr/2), the inference server:
- Authenticates using your Roboflow API key (if required),
- Connects to the Roboflow cloud,
- Downloads the model weights and configuration files,
- Caches them locally inside the container or your machine.
Local Prediction Engine is Used: Once downloaded, all inference is done locally using your system’s CPU or GPU (if GPU version is used). For every image or input you send:
- The image is passed through the locally running model,
- The model outputs results (e.g., bounding boxes, labels, segmentation masks),
- Any workflow blocks (like visualization) are also executed locally in sequence.
Using Roboflow offline inference means your model runs directly on your own computer or edge device, without needing an internet connection. This keeps your data private and secure, since images and videos never leave your system. It also makes predictions faster in real-time because there’s no delay from uploading to the cloud. Offline inference is especially useful in places with poor or no internet, like factories, farms, or remote areas. You can use it as much as you want without paying for every API call, and it works well with cameras, sensors, and other hardware. Overall, it gives you more control, speed, and privacy when using computer vision models.
Offline Roboflow Model Deployment
Deploying a Roboflow model offline is essential for real-time applications on edge devices. It ensures fast response to events without internet delays, allowing immediate actions like alerts or controls, crucial in use cases like safety monitoring, automation, or robotics.
You may love to read following:
Model Deployment
Model deployment is the bridge between machine learning development and real-world impact. It transforms a trained model from a lab experiment into a reliable, accessible tool that powers applications, automates tasks, and delivers insights. By following best practices like versioning, monitoring, secure access, and choosing the right infrastructure you ensure reliability, speed, and scalability. Tools such as Roboflow simplify this process, especially for computer vision applications, by offering flexible deployment options across cloud, edge, and browser. With proper deployment, your model moves from being a research artifact to a source of real business value. Get started today.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M.. (Jul 29, 2025). Model Deployment. Roboflow Blog: https://blog.roboflow.com/model-deployment/