
In discussions about state-of-the-art AI models, you may hear the word “multimodal” come up. Multimodal models can work across different “modalities” of information. The modalities supported by models vary, but many multimodal models work with images and text, and sometimes audio and video.
In this guide, we are going to walk through the best multimodal vision models available that support images and text as an input. Such models can be used for use cases from document OCR to image classification and object detection to visual question answering.
Here is an example of GPT-4.5, a state-of-the-art model, reading the text in an image:
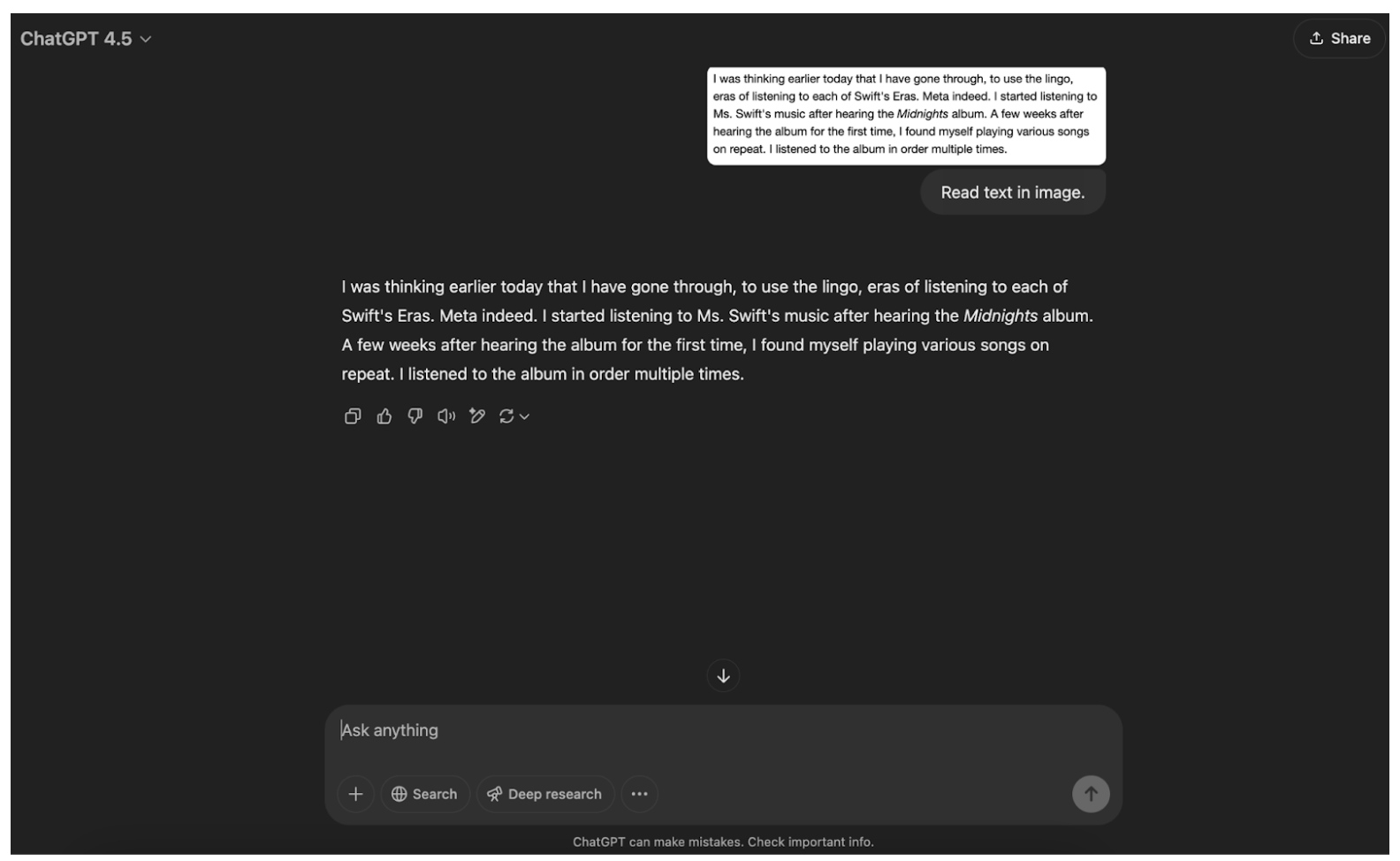
The multimodal models we will cover are:
- CLIP by OpenAI
- Florence-2 by Microsoft
- Qwen2.5-VL by Alibaba
- PaliGemma by Google
- OpenAI’s GPT series
We will also touch on other models with multimodal support like Anthropic’s Claude series of models.
Without further ado, let’s get started!
What is a Multimodal Model?
Multimodal AI models are trained to work with different types of input. The types of input with which a model works depending on the task it is trained to complete. For example, you could train a model with text and image data to build a model capable of answering questions about images. Popular modalities include images, videos, and audio. Specialist models may also use data types like time series sequences and geospatial data.
A common combination of modalities is image and text. With this combination, you can train a model to do tasks like:
- Visual question answering
- Object detection
- Image classification
- OCR
- Document OCR
- Object counting
- Chart understanding
You may hear some multimodal models referred to as “foundation models”. Foundation models are a type of model that excels at a specific task and/or have support for a wide range of models. The models we list in this guide, from GPT-4o to PaliGemma, are all foundation models upon which you can build applications that rely on multimodal understanding.
Below, we are going to talk through a few popular multimodal vision models.
Top Multimodal Vision Models
CLIP
CLIP is a foundational multimodal model. Developed in 2016 by OpenAI and released to the public as an open source project under an MIT license, CLIP combines knowledge of English-language concepts with semantic knowledge of images.
The model was trained on 400,000,000 image-text pairs using a technique called contrastive pre-training. This technique is used to help a model learn the similarity between images and text.
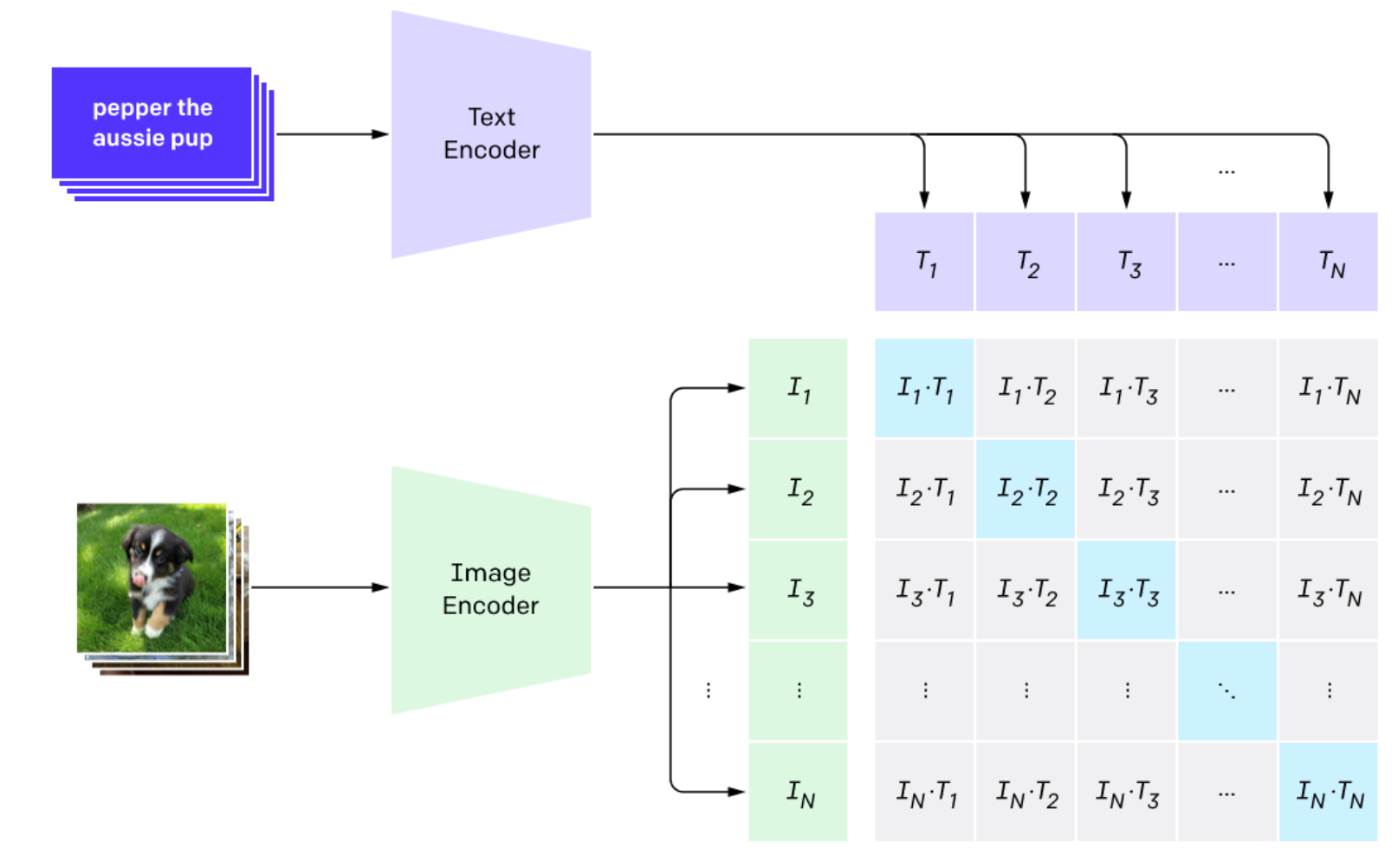
CLIP models let you calculate vectors that can be compared using a distance metric like cosine similarity. The closer two vectors are together, the more similar they are. For example the vector for the word “dog” and an image of a dog will be closer than the vector for the word “cat” and an image of a dog.
CLIP is commonly used for zero-shot image classification. This is a task where you classify images without fine-tuning a model yourself. This works because CLIP already has extensive knowledge of images that it can use.
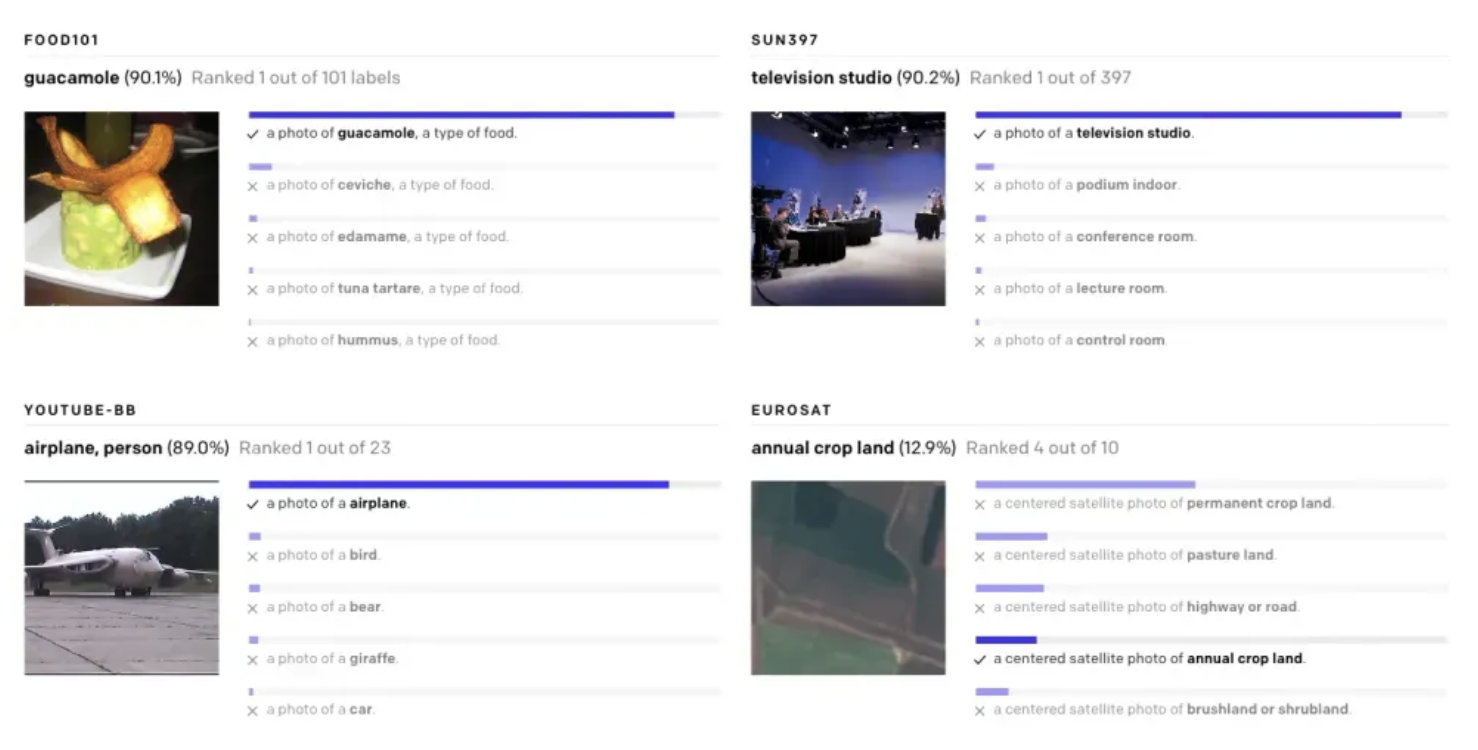
CLIP can also be used to build a multimodal search engine where users can provide text or an image as an input. The search engine will then return the most similar images to the input. This works using the vector comparison method described earlier. Vector databases are commonly used to allow image comparison at scale.
Florence-2
Florence-2 is a vision-language model developed by Microsoft and released under an MIT license. You can use Florence-2 for:
- Object detection
- Image captioning
- Image segmentation
- OCR
Florence-2 can work across an entire image or across a region of an image. For example, you can identify objects across a full image, or in only a specific region of an image.
Florence-2 has two model sizes: base and large. The base model has 230 million parameters. The large model has 770 million parameters.
Here is an example of Florence-2 used for OCR:

Interested in learning how to fine-tune Florence-2 for object detection? We have written a guide that walks through all the steps from dataset preparation to fine-tuning and inference.
OpenAI GPT Models
Starting with GPT-4 with Vision, released in mid-2024, a wide range of OpenAI’s GPT models now have support for multiple modalities. GPT-4o, OpenAI O3 Mini, and GPT-4.5 all allow you to upload images and ask questions about their contents.
Here is an example showing GPT identify the amount of tax paid on a receipt:
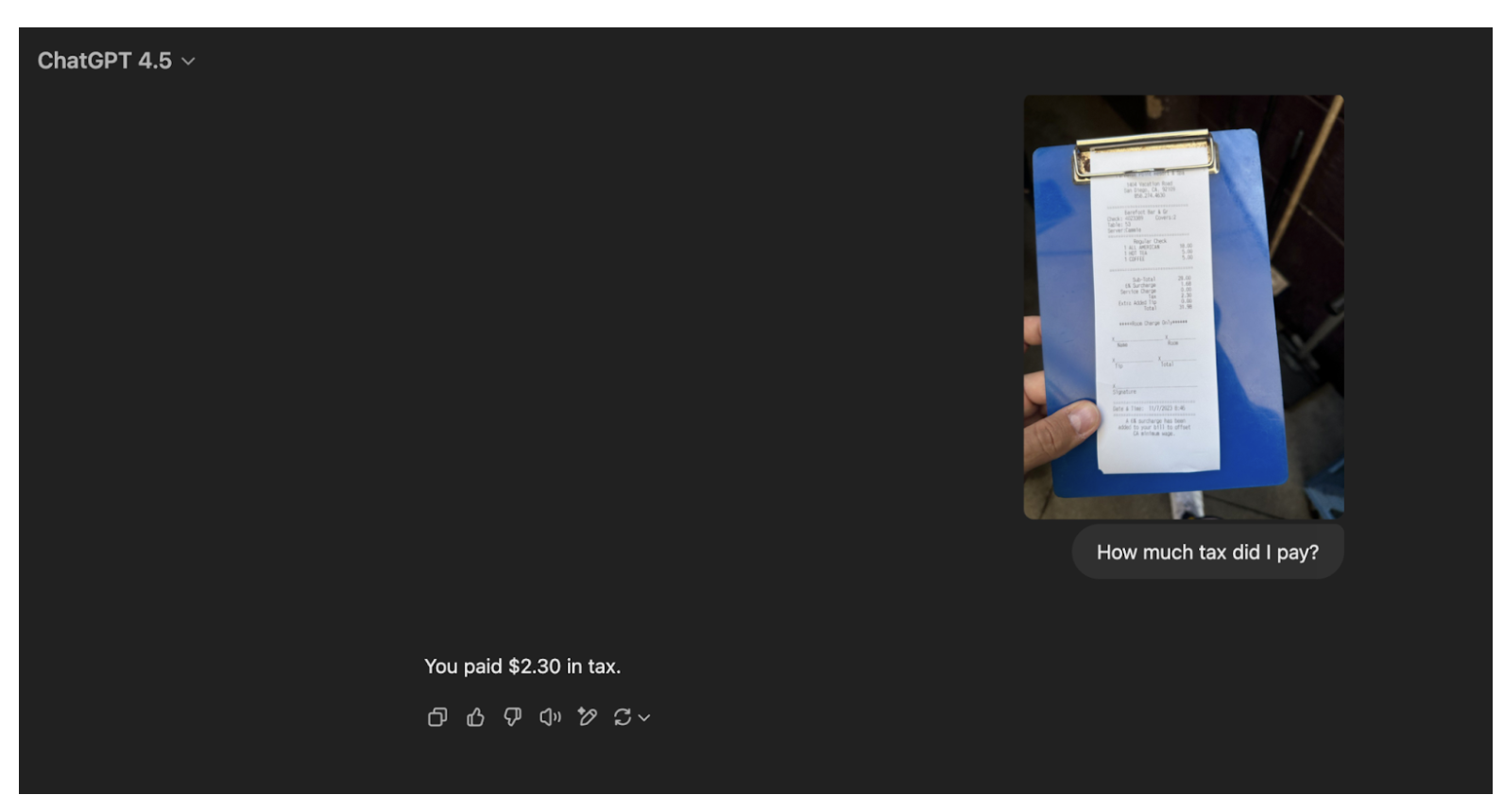
In our tests, OpenAI’s flagship models have done well across a wide range of tasks, including:
- Document OCR
- Handwriting OCR
- Image question answering
- Image classification
OpenAI’s models struggle with object detection. You can fine-tune GPT for object detection, but you can get better performance with other models like Florence-2 or a dedicated object detection model.
You can get a pulse of the tasks that GPT does well with GPT Checkup, a website that runs the same set of prompts over OpenAI’s latest multimodal model to evaluate its visual capabilities.
OpenAI’s GPT models are available exclusively in the cloud. This means that you cannot run them on your device, unlike other models like Qwen2.5-VL.
Qwen2.5-VL
Qwen2.5-VL is a multimodal vision-language model developed by the Qwen team at Alibaba Cloud. You can use Qwen2.5-VL for a wide variety of tasks, including visual question answering, document OCR, and object detection. The model is available in three sizes: 3B, 7B, and 72B.
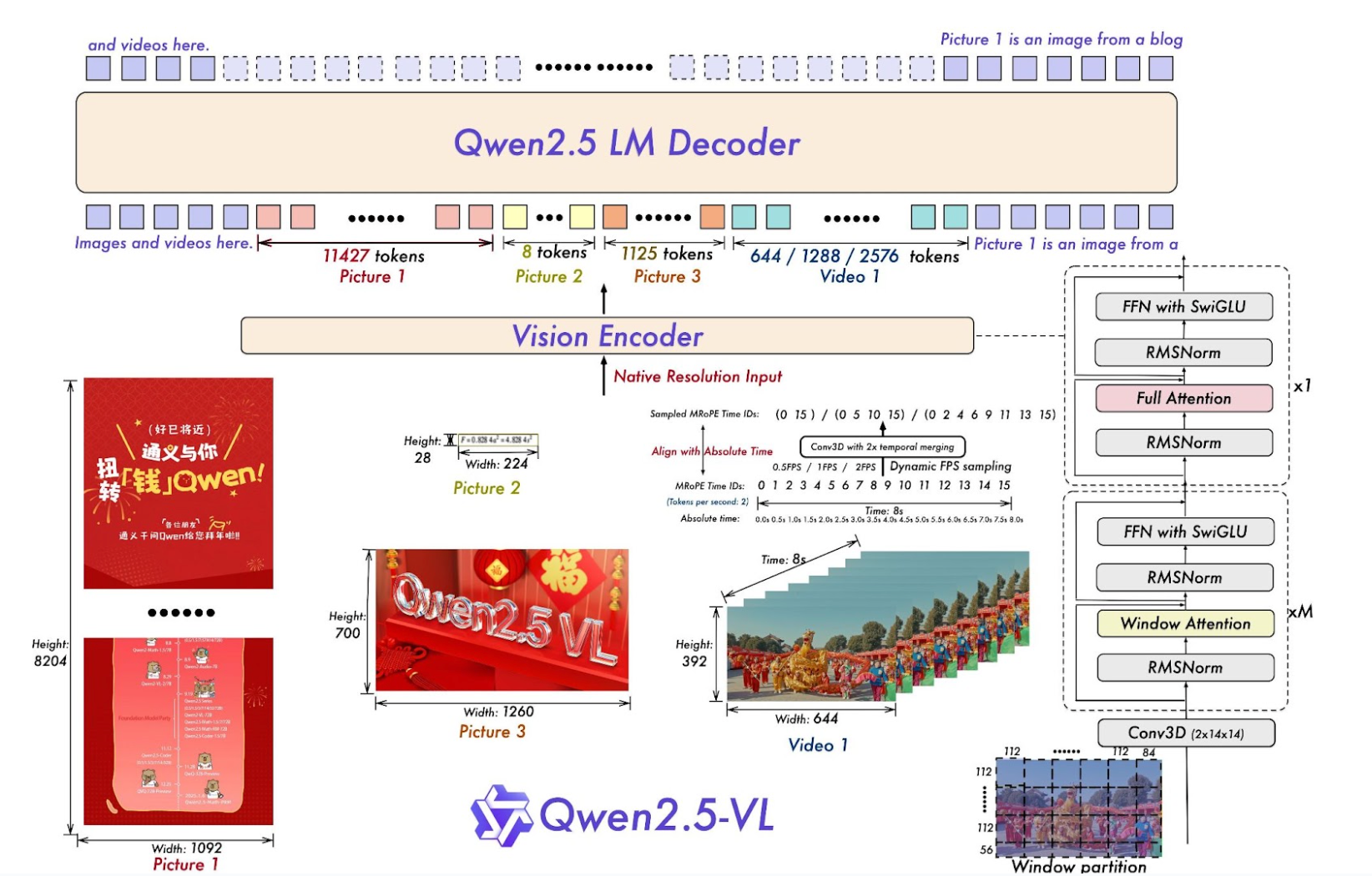
Across benchmarks, the largest Qwen2.5-VL model performs competitively when evaluated against other state-of-the-art models like GPT-4o and Gemini-2 Flash. For example, on the DocVQA, InfoVQA, and CC-OCR benchmarks, Qwen2.5-VL outperforms GPT-4o.
In the Qwen2.5 GitHub repository, the project authors note the following as key tasks on which the model performs better than previous Qwen models:
- Document understanding
- Video understanding
- Object identification and grounding
- Object counting
- Agentic capabilities for computer screen inputs
PaliGemma
PaliGemma, released at Google I/O 2024, is a multimodal model that builds on the SigLIP vision and Gemma language models developed by Google. The model comes in one size: 3B. PaliGemma can run on your own hardware.
You can fine-tune the model for captioning, visual question answering, OCR, object detection, and segmentation. Unlike OpenAI’s GPT-4o and other cloud multimodal models, PaliGemma performs well at object detection when fine-tuned to detect objects.
Here is an example of PaliGemma being used to read the serial number on a tire:
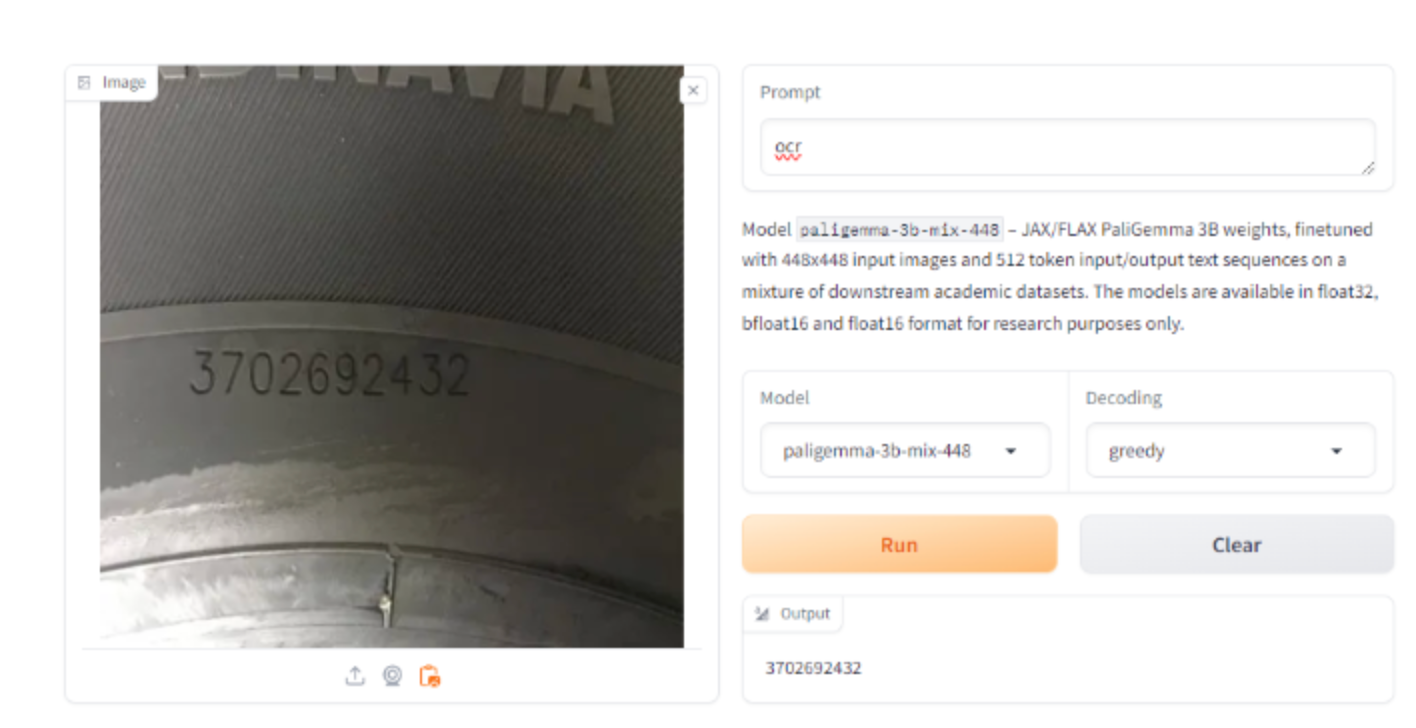
The model successfully returns the serial number: 3702692432.
Here is how the base PaliGemma model performs when compared to other models that were state-of-the-art at the time of PaliGemma’s release:

We have written a full guide that walks through all of the features of PaliGemma and how to fine-tune PaliGemma for vision. We also have a guide that shows how to fine-tune PaliGemma on a custom dataset for object detection.
More Multimodal Models
Multimodal models are being released at a fast pace as architectural improvements lead to better model performance. Generally, models are getting cheaper, faster and more accurate.
With that in mind, there are a few notable models that we didn’t cover that we recommend looking into. These are:
- Google’s Gemini series
- Anthropic’s Claude series
- LLaVA
- ImageBind
Explore 20 of the top multimodal models.
Conclusion
Multimodal models accept inputs in multiple modalities. You can use multimodal models to, for example, ask questions about images, detect objects, classify videos, and more.
In this guide, we walked through five state-of-the-art multimodal vision models: CLIP, Florence-2, OpenAI’s GPT series, Qwen2.5-VL, and PaliGemma. All of these models have their own specialities, benefits, and trade-offs. CLIP is ideal for classification on-device, for example, whereas GPT gives you the best performance on tasks like VQA but must be run in the cloud.
Curious to explore more computer vision and multimodal models? Check out the Roboflow Models directory. This directory features over 100 models covering tasks from object detection to segmentation to OCR.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Mar 7, 2025). Top Multimodal Models: A Complete Guide. Roboflow Blog: https://blog.roboflow.com/multimodal-vision-models/