
Computer vision models learn to model a task from a training set, however, like all deep learning models, they are prone to overfit the data they have been shown, making poor inferences in the wild.
Enter Occlusion Techniques
In this post, we take an overview of occlusion techniques in computer vision and discuss how occlusion based data augmentation techniques can be used to combat the problem of overfitting in computer vision.
What is Occlusion in Computer Vision?
Occlusion techniques in computer vision block a portion of an image during training time, challenging the network to learn not to rely canonical features.
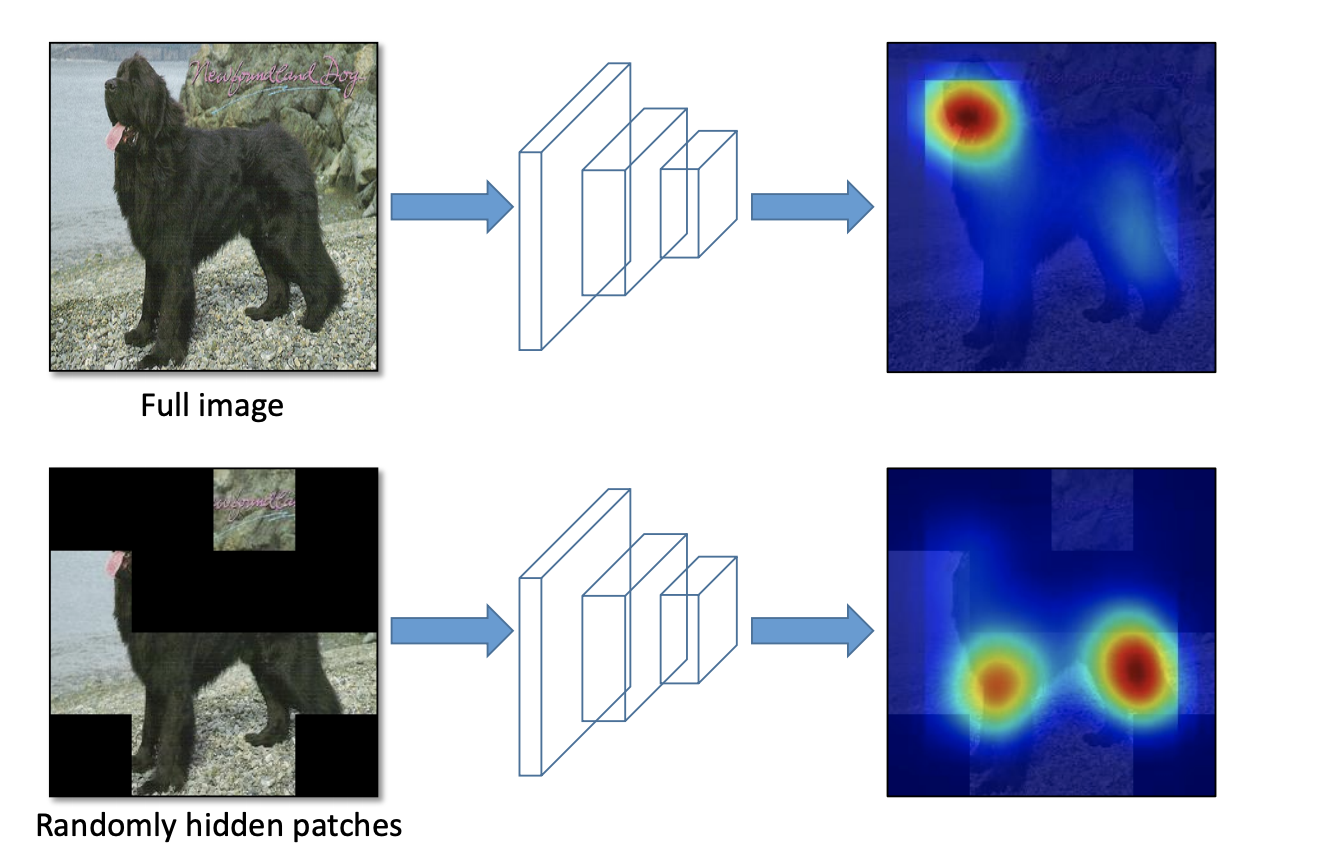
For example, if we were to train an object detection model to detect dogs, we might only have training data with the dog's head in view. Looking at the Class Activation Map - CAM (the pixels that contribute the most to a prediction), we might see that the network relies heavily on the dog's head to make predictions.

But what about when the dogs head is behind a bush? We want our network to be able to generalize to situations like this, so it may be advantageous to occlude some training images to hide the dog’s head and force the network to lead to identify a dog from other parts of its shape.

Predecessor Occlusion Techniques
Research in occlusion techniques for training deep learning computer vision models is not brand new, and started as early as 2017.
Random Erase - A random rectangular section of the image is erased and replace with noisy pixels. Typically, in a training pipeline random erase is implemented with a random location and random width height within a set range. Random erasures can also be applied probabilistically.

Cutout - random squares are cutout from the image. In the original cutout paper, this augmentation is implemented by only hiding these pixels from the first layer of the CNN, meaning downstream connected layers could still peak at the hidden pixels.

Hide and Seek - Divide the image into a grid, and randomly hide sections of the grid with some probability. This is similar to grid mask but with random grids being removed.
Grid Mask - Draw a grid over the image and hide all squares of the grid.

State of the Art Occlusion Techniques
New techniques have grown out of the old techniques, pushing the state of the art in computer vision modeling with data augmentation.
CutMix - A section of the image is randomly cut out and replaced with a section from a different image. This forces the model to not only predict around occlusion, but to learn not to rely too heavily on the surrounding environment it typically finds a given object, or class label in.

Mosaic - Mosaic is not an occlusion technique directly, but it accomplishes a similar goal. Mosaic stiches together 4 images in a window, randomly shifting and cropping them along the way. This forces the model to learn around occluded objects on the side, learn to identify objects within different contexts, and learn to identify objects in different portions of the image, improving resiliency.

A Hands On Occlusion Example (Chess)
Let's suppose we want to train a an object detection model to recognize chess pieces. We have gathered a chess dataset and made our chess dataset public on Roboflow.
With limited training data, it is possible that our model will only see chess pieces in a non-occluded fashion like this image:

Yet, at inference time, our model may need to make predictions on chess pieces that are occluded like this image:

Therefore, it may be advantageous to experiment with adding some occlusion augmentations to our training data to improve our model's resilience.
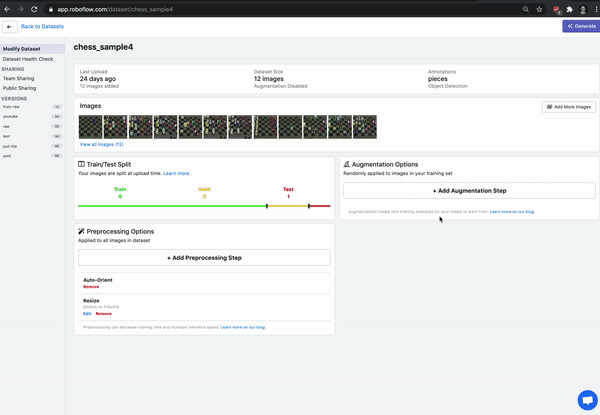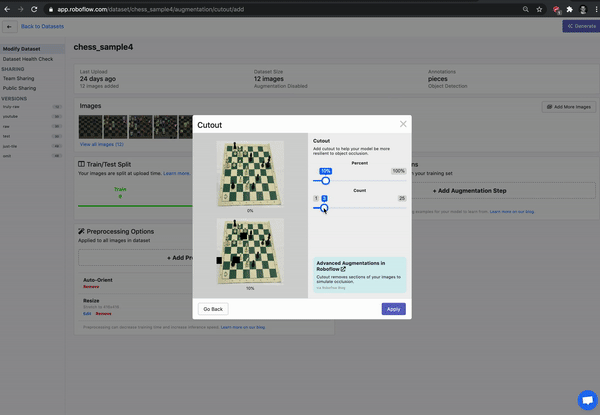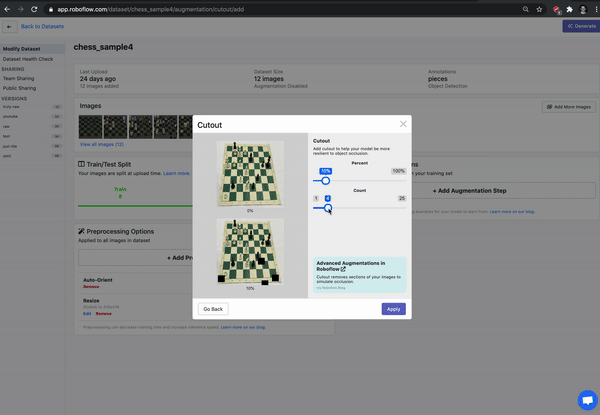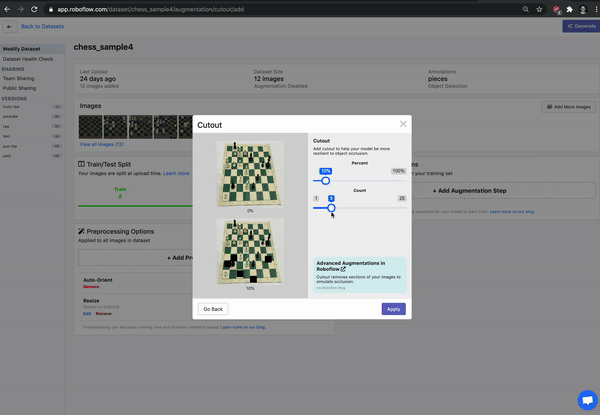
Conclusion
Occlusion techniques can be used to improve the resiliency of your computer vision model, teaching your model to generalize around canonical features of an image.
State of the art computer vision research continues to push the boundary of effective occlusion data augmentation strategies.
Occlusion is an important data augmentation strategy to explore if you believe your model is overfitting to certain features in your training set.
Happy occluding, and as always, happy training.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Nov 6, 2020). Occlusion Techniques in Computer Vision. Roboflow Blog: https://blog.roboflow.com/occlusion-computer-vision/