
Large Language Models (LLMs) such as GPT-4o, Google Gemini, and Anthropic Claude have evolved beyond simple text processing. These models are now multimodal, capable of understanding and integrating various types of input, including images and video, alongside text. This capability allows them to tackle a wide range of computer vision problems, such as object detection, text recognition, and visual question answering, among others.
This blog will guide you on how to effectively structure and use prompts to solve computer vision tasks with Large Multimodal Models (LLMs).
Capabilities of Large Multimodal Models in Computer Vision
- Detecting objects and their positions in images
- Extracting text from images using Optical Character Recognition (OCR)
- Answering questions about visual content through Visual Question Answering (VQA)
- Understanding scenes and analyzing contextual information within images
- Generating descriptive captions or summaries for images
- Integrating text and visual information for complex multimodal reasoning
Large Multimodal Model: Google Gemini
In this blog, we will use Google Gemini as the LLM of choice to demonstrate prompting for solving computer vision problems.
Google Gemini is a family of Large Multimodal Models (LMM) developed by Google DeepMind, designed specifically for multimodality. It includes variants such as Gemini 2.5 Pro, Gemini 2.5 Flash, Gemini 2.5 Flash-Lite, etc., each optimized for different use cases.
Gemini models are free to use but require an API key, which you can easily obtain at no cost from Google AI Studio.
Accessing and Integrating Google Gemini via API
The below script demonstrates how to access Google Gemini models using the API on an example image:
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform Gemini inference using Google Gemini API with text + image input.
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64 in one line
base64_image = base64.b64encode(open("test.jpg", "rb").read()).decode("utf-8")
# Run inference
output = gemini_inference(
base64_image,
prompt="Count the number of objects in the image.",
model_id="gemini-2.5-flash", # Gemini variant
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY"
)
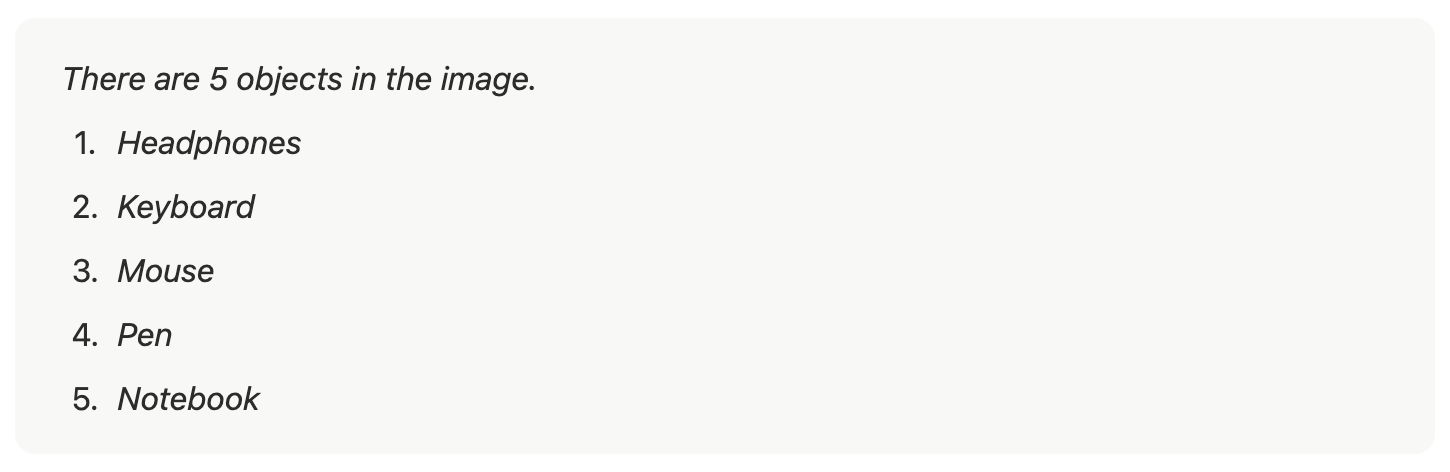
print(output)The example test image used in the above script is:

The output produced by the above script, using the prompt “Count the number of objects in the image.”, would look like this:
Leveraging Google Gemini within Roboflow Workflows
Google Gemini is available as a built-in block in Roboflow Workflows. Roboflow Workflows is a web-based no-code platform for chaining computer vision tasks such as object detection, dynamic cropping, and bounding box visualization, with each task represented as an individual block.
To get started, create a free Roboflow account and log in. Next, create a workspace, then click on “Workflows” in the left sidebar and click on Create Workflow.
You’ll be taken to a blank workflow editor, ready for you to build your AI-powered workflow. Here, you’ll see two workflow blocks: Inputs and Outputs, as shown below:
To add Google Gemini to your workflow, click ‘Add a Model’, search for ‘Google Gemini’, select it, and click ‘Add Model’ to insert the block into your workflow, as shown below:
Now update the ‘API Key’ with your own in the Configure tab, accessible by clicking the ‘Google Gemini’ block in the workflow.
Alongside the 'API Key', the configuration tab includes parameters such as temperature, model version, and max tokens, all of which can be easily adjusted through the Roboflow Workflow UI.
You can now run the workflow as shown below:
Prompting Tips for Multimodal Models to Perform Computer Vision Tasks
Given below are practical strategies for effective prompting, helping you improve accuracy and reduce hallucinations:
Provide Contextual Specificity
Context helps the LLM capture user intent and generate more accurate outputs. Providing detailed situational or background information allows the model to produce more relevant and precise predictions.
The difference is illustrated below, where two different prompts are applied to the same image:

Non Contextual Prompt
The prompt below provides no details about the context in which the description should be generated.
Non Contextual Prompt Output
This output, based on the above Non-Contextual Prompt, provides a general description of the image without emphasizing any particular purpose or audience. It lists objects and details literally but does not highlight features that would make the image appealing for a specific context, such as a real estate catalog.

Contextual Prompt
The prompt below specifies the context for the description, guiding the model to focus on key features such as space, lighting, style, and comfort for a real estate catalog.
Contextual Prompt Output
This output, based on the above Contextual Prompt, is tailored to the context provided. It emphasizes features such as space, lighting, style, and comfort, using persuasive and engaging language suitable for a real estate catalog, rather than merely listing objects in the image.

System Instructions
Rather than including all contextual information within a single prompt, you can use System Instructions to provide additional context alongside your main prompt.
By separating guidance into its own instruction, system instructions simplify the main prompt while still directing the outputs more effectively. For example, the payload below for Gemini Inference demonstrates this:
payload = {
"systemInstruction": {
"role": "system",
"parts": [
{"text": "You are a professional real estate copywriter. Always describe spaces in a way that highlights their value, comfort, and uniqueness. Use engaging, persuasive, yet natural language that helps potential buyers envision themselves in the home"}
]
},
"contents": [
{
"role": "user",
"parts": [
{"text": "Give me a description of the image."},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}Leverage Examples
Including examples in your prompt shows the LLM what a correct response should look like. Few-shot prompts provide several examples, whereas zero-shot prompts provide none. Well-chosen examples help guide the model’s formatting, phrasing, and scope, enhancing both the accuracy and quality of its outputs.
The difference is illustrated below, where two different prompts are applied to the same image:

Zero-Shot Prompt
The prompt below provides no examples for the model to follow, relying entirely on its general understanding of image description:
Zero-Shot Prompt output
This output, based on the above Zero-Shot Prompt, provides a general description of the scene without structured guidance. It captures the overall setting and mood but may lack specific stylistic cues or formatting.

Few-shot Prompt
The prompt below provides specific examples to guide the model. It demonstrates how to structure descriptions, including setting, lighting, camera perspective, and mood:
Example 1 – Rainy Alley Setting: Narrow city alley at night. Lighting: Flickering neon signs, wet reflections. Camera: Low-angle tracking shot. Mood: Tense, mysterious.
Example 2 – Morning Beach Setting: Empty beach at sunrise. Lighting: Soft, warm sunlight; gentle highlights on waves. Camera: Wide shot, slow pan along shoreline. Mood: Calm, serene.
Few-Shot Prompt output
This output, based on the above Few-Shot Prompt, is more structured and detailed. The few-shot prompt conveys structure and stylistic cues in the output without needing to state them explicitly in the prompt.

Best Practices for Leveraging Prompts with Examples
- Use examples that show the model the behavior you want. This is generally clearer and leads to better outputs.
- Avoid using examples that show the model what to avoid. Can be confusing and sometimes counterproductive.
- Keep examples in few-shot prompts uniform, especially regarding XML tags, whitespace, newlines, and separators.
Utilize Structured Output Generations
Most LLMs support Function Calling, which guarantees consistent JSON responses with all required keys. It enforces a structured format, preserves data types, and allows descriptive prompts for each key to capture detailed reasoning, ensuring reliable extraction of insights from images.
The script below demonstrates Function Calling in Gemini, with most of the prompting occurring within function_declarations.
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key, function_declarations):
"""
Perform Gemini inference using Google Gemini API with text + image input.
Uses function calling with a provided schema.
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature},
"tools": [{"functionDeclarations": function_declarations}],
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
fn_call = result["candidates"][0]["content"]["parts"][0]["functionCall"]
return fn_call["args"]
if __name__ == "__main__":
# Encode image to base64
base64_image = base64.b64encode(open("test.jpg", "rb").read()).decode("utf-8")
# Define function schema with descriptions
function_declarations = [
{
"name": "list_objects",
"description": "Identify objects present in the given image.",
"parameters": {
"type": "object",
"properties": {
"objects": {
"type": "array",
"description": "A list of objects detected in the image.",
"items": {
"type": "object",
"properties": {
"label": {
"type": "string",
"description": "The name of the detected object."
}
},
"required": ["label"],
"description": "Details about a single object detected in the image."
}
}
},
"required": ["objects"],
"description": "The structured output containing all detected objects."
}
}
]
# Run inference
output = gemini_inference(
base64_image,
prompt="Identify the objects in the image.",
model_id="gemini-2.5-flash",
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY",
function_declarations=function_declarations,
)
print(json.dumps(output, indent=2))The script output for the prompt “Identify the objects in the image” in the previously provided image of stationery is:
{
"objects": [
{
"label": "headphones"
},
{
"label": "keyboard"
},
{
"label": "mouse"
},
{
"label": "pen"
},
{
"label": "notebook"
}
]
}You can use the Function Calling capabilities in Roboflow Workflows with the Google Gemini block without writing any code by setting the Task Type to 'Structured Output Generation' and providing the output structure below, using the same function declarations from the earlier script as a raw string.
{
"output_schema": "{\"name\":\"list_objects\",\"description\":\"Identify objects present in the given image.\",\"parameters\":{\"type\":\"object\",\"properties\":{\"objects\":{\"type\":\"array\",\"description\":\"A list of objects detected in the image.\",\"items\":{\"type\":\"object\",\"properties\":{\"label\":{\"type\":\"string\",\"description\":\"The name of the detected object.\"}},\"required\":[\"label\"],\"description\":\"Details about a single object detected in the image.\"}}},\"required\":[\"objects\"],\"description\":\"The structured output containing all detected objects.\"}}"
}The below workflow video demonstrates this:
Proper Object Detection Technique
LMMs can perform zero-shot object detection, identifying one or multiple classes simultaneously without any fine-tuning, using only prompts. They can even reason about whether an object should be detected.
When performing object detection with Gemini, always include the instruction: “Return just box_2d, label and no additional text.” in your prompt. For best results, avoid using Gemini’s Function Calling capabilities for object detection and instead rely on its text generation capabilities.
Additionally, the generated bounding box coordinates need to be normalized before use. The script below demonstrates this functionality using the Gemini model:
# Ensure OpenCV is installed before running this script:
# You can install it via: pip install opencv-python-headless
import requests
import json
import base64
import cv2
def clean(results):
"""
Clean the raw JSON output from the Gemini API.
"""
return results.strip().removeprefix("```json").removesuffix("```").strip()
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform object detection using Google Gemini API.
"""
# Fixed, plotting function depends on this.
bounding_box_prompt = "Return just box_2d, label and no additional text."
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt + bounding_box_prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature}
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64
image = "test.jpg"
with open(image, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
# Run inference
output = gemini_inference(
base64_image,
prompt="Detect only the analog objects in the image with correct labels.",
model_id="gemini-2.5-flash",
temperature=0.0,
api_key="YOUR_GEMINI_API_KEY"
)
boxes = json.loads(clean(output))
print(boxes)
# Load image with OpenCV
image_cv2 = cv2.imread(image)
h, w, _ = image_cv2.shape
for item in boxes:
# Gemini model returns [y1, x1, y2, x2] normalized to 0-1000
y1, x1, y2, x2 = item["box_2d"]
y1 = int(y1 / 1000 * h)
x1 = int(x1 / 1000 * w)
y2 = int(y2 / 1000 * h)
x2 = int(x2 / 1000 * w)
# Draw green rectangle
rectangle_thickness = 16
cv2.rectangle(image_cv2, (x1, y1), (x2, y2), (0, 255, 0), thickness=rectangle_thickness)
# Draw text directly
text = item["label"]
font_scale = 3
font_thickness = 6
cv2.putText(image_cv2, text, (x1, max(0, y1 - 4)), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), font_thickness)
# Save and display annotated image_cv2
cv2.imwrite("annotated_image.jpg", image_cv2)You can also integrate the above script into Roboflow workflows using Custom Python code blocks. This example demonstrates how to use the script within a Roboflow workflow for object detection.
The script output for the prompt “Detect only the analog objects in the image with correct labels” is:

Break Complex Prompts into Smaller Tasks
In certain cases when inference on image tasks are complex then you can break it down into more steps to make it manageable.
For example, to perform an OCR task on the image below:

Given the prompt, “List all the contents of the shelf labels in the image,” the output below was produced:
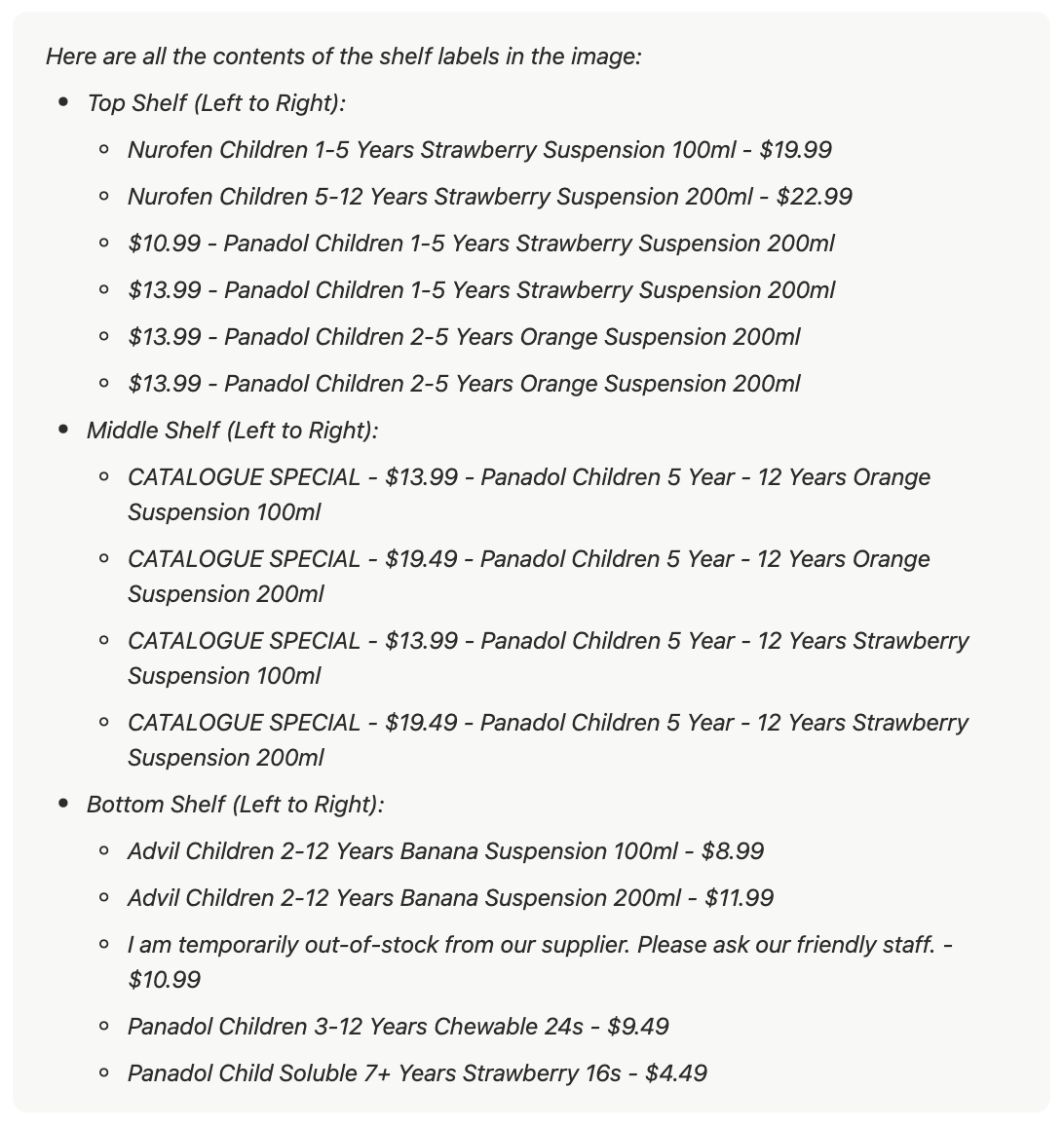
In the above output, various errors and hallucinations can be observed in the product names. The OCR produced incorrect results, such as inaccurate milliliter values, and some words in the full product names have been omitted.
To address this, rather than creating a lengthy prompt detailing every instruction and exception, which can lead to hallucinations and inconsistent results across images, it is more effective to first perform object detection on the shelf labels to identify their bounding boxes, and then use these bounding boxes to crop the shelf label images, as shown below:

The cropped images can then be pre-processed to enhance their quality and individually processed with an LMM for OCR. This approach greatly improves OCR accuracy and overall reliability. An example of this technique is demonstrated in this blog.
Leverage Grounding Search to Reduce Hallucinations
Grounding search in Google Gemini improves computer vision by linking what the model sees in an image to real world knowledge from Google Search, ensuring more accurate, up to date, and reliable recognition while reducing hallucinations.
For example consider the image:

In this image, we can use Gemini inference to detect the phone's brand and apply grounding search to retrieve the latest price for that brand.
The prompt we’ll use is: “Identify the image and retrieve real-time prices from the web with sources.” The code below demonstrates how to use this prompt with grounding search for Gemini inference.
import requests
import base64
import json
def gemini_inference(image, prompt, model_id, temperature, api_key):
"""
Perform Gemini inference using Google Gemini API with text + image input,
and apply grounding search (Google Search Retrieval).
"""
API_URL = f"https://generativelanguage.googleapis.com/v1beta/models/{model_id}:generateContent?key={api_key}"
payload = {
"contents": [
{
"role": "user",
"parts": [
{"text": prompt},
{"inlineData": {"mimeType": "image/jpeg", "data": image}},
],
}
],
"generationConfig": {"temperature": temperature},
"tools": [
{
"google_search": {} # Enable grounding search
}
]
}
headers = {"Content-Type": "application/json"}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
return result["candidates"][0]["content"]["parts"][0]["text"]
if __name__ == "__main__":
# Encode image to base64
base64_image = base64.b64encode(open("phone.webp", "rb").read()).decode("utf-8")
# Run inference with grounding search
output = gemini_inference(
base64_image,
prompt="Identify the image and get me real-time prices from the web with sources.",
model_id="gemini-2.5-flash", # Gemini variant
temperature=1,
api_key="YOUR_GEMINI_API_KEY"
)
print(output)The output of the above script will be similar to the following:

Experiment with Parameters
LMM like Google Gemini provide various parameters that can be used alongside a prompt to fine-tune the outputs. These parameters include:
- Thinking Budget: The thinking budget sets how many tokens the model can use for reasoning. Higher values enable more detailed responses, while lower values reduce latency. Setting it to 0 disables thinking, and -1 enables dynamic adjustment based on request complexity.
- Temperature: Temperature controls the randomness of token selection during sampling. Lower values make responses more deterministic, while higher values increase diversity and creativity. A temperature of 0 always selects the highest-probability response.
- Top P: topP selects tokens whose cumulative probability reaches the topP value. For example, with topP=0.5, only tokens contributing to 50% probability are considered, and temperature determines the final choice.
- Top K: topK limits token selection to the K most probable options. For example, topK=1 selects the single most likely token (greedy decoding), while topK=3 samples from the top 3 tokens, with temperature and topP applied for final selection.
- Stop Sequences: Defines character sequences that make the model stop generating. Avoid using sequences likely to appear in the output.
- Max Output Tokens: Specifies the maximum number of tokens that can be generated in the response. A token is approximately four characters. 100 tokens correspond to roughly 60-80 words.
You can find the default parameter values for the all Gemini models here under ‘Parameter defaults’.
Below is the generationConfig dictionary, which shows how the above parameters can be used with Gemini Inference inside the payload:
"generationConfig": {
"temperature": 0,
"topK": 5,
"topP": 0.9,
"maxOutputTokens": 8000,
"stopSequences": ["<THE END>"], # The LLM stops generating when this sequence appears.
"thinkingConfig": {
"thinkingBudget": -1 # Dynamic thinking enabled
}
}Prompting tips for LLMs with Vision Capabilities Conclusion
Large Multimodal Models like Google Gemini have transformed computer vision by integrating text and image understanding. By carefully structuring prompts, leveraging contextual cues and examples, and using structured outputs or grounding search, you can significantly improve accuracy in tasks such as object detection, OCR, and visual question answering.
Additionally, Roboflow Workflows provides a no-code interface with a variety of multimodal model blocks, including closed-source options like Google Gemini and GPT-4, as well as open-source models such as CogVLM, LLaVA-1.5, and PHI-4, making it easy to quickly develop computer vision applications.
To learn more about building with Roboflow Workflows, check out the Workflows launch guide.
Written by Dikshant Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Sep 8, 2025). Prompting Tips for Large Language Models with Vision Capabilities. Roboflow Blog: https://blog.roboflow.com/prompting-tips-for-large-language-models-with-vision/