
Completed in cooperation with Odakyu Electric Railway in Japan, this project builds a computer vision system to detect three high-fatality scenarios: a person fallen onto tracks, a person or vehicle stuck at a level crossing, and a person standing dangerously close to a platform edge. The model is trained using Roboflow to identify people, cars, tracks, level crossings, and station platforms within train camera feeds. Detections trigger responses like emergency braking and horn alerts, offering a faster and far cheaper intervention than physical infrastructure upgrades.
Public mass transit is used all over the world with nearly sixty billion riders in 2019. Trains offer a sustainable, affordable, and consistent way to commute, but accidents are a tragically common occurrence. In Japan, with one of the highest transit journeys per capita, over 7000 people have died since 2010 due to mostly preventable train accidents, with a recent daily average of over two fatalities every single day.

In the project, we will explore how to prevent and mitigate railroad accidents using the power of computer vision.
Identifying Problem Cases
A majority of train accidents occur from people or vehicles on the tracks colliding with oncoming trains. There are existing solutions, like lifting tracks above level crossings and platform gates, but lifting tracks cost tens of millions or more per mile and platform gates cost on average over seven million dollars to install per station, according to one article.
Railroad reports and statistics in public transit in Japan and across the world show that most accidents occur primarily in two places: the station and level-crossings (where people and/or cars cross the tracks).
Specifically, the two scenarios in which the highest degree of fatalities occur are: when a person falls onto the track and when a person/vehicle is stuck at a level crossing.
Identifying a Solution
To mitigate, prevent, and avoid accidents in these problem areas, we identified three ways to detect either possible or imminent dangers and initiate mitigating strategies:
- A person who has fallen onto the tracks in a station: Triggering the brake, Horn, etc.
- A person or vehicle stuck in the middle of a level crossing: Triggering the brake, Horn, etc.
- A person who is dangerously close to the edge of the track: Horn.
To detect these, we will develop a computer vision model capable of identifying the following objects in within train video feeds:
- People
- Cars
- Train tracks
- Level railroad crossings
- Station platforms
Detecting these items quickly is imperative in this use case, so to make processing each frame of the video feed efficient, we’ll create two different types of models. For detecting people and cars, since they occupy a relatively small area of the video feed, the bounding boxes provided by an object detection model is sufficient and will be fast. Since precision is important for making sure where tracks, platforms and crossings are, we’ll create an instance segmentation model (which is usually slower) that detects those railroad infrastructure items.
To support the quick detection and response of potential incidents, we can deploy these solutions to devices on the trains so they can rapidly react without the dependency of an internet connection.
Creating a Passenger Train Dataset with Roboflow
We collected data to label the previously mentioned items to use in our accident prevention model using a GoPro placed at the front of a limited express passenger service on the Odakyu Line for the 35 mile (55km) stretch between Fujisawa Station to Shinjuku Station near Tokyo, stopping at five stations and passing through thirty three stations.
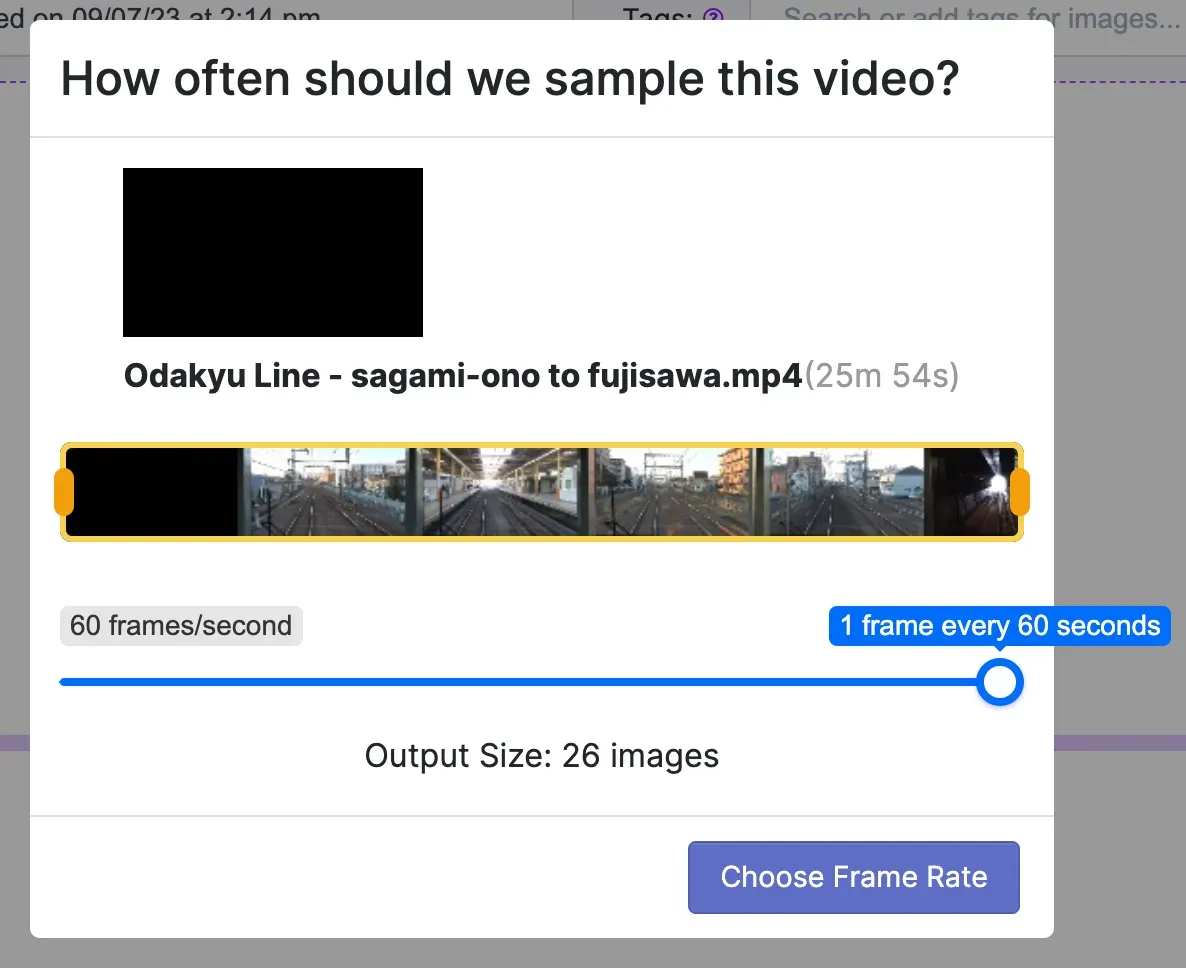
We will start with building a model for detecting the train infrastructure (platform, tracks, crossings). After collection, we initially wanted to train a preliminary model so that we could use model-assisted labeling to speed up our labeling process. To start, we imported our two-hour-long captured video by selecting a low rate at which to sample frames.
Then, we start labeling the dataset, using Smart Polygon to help speed up the process.
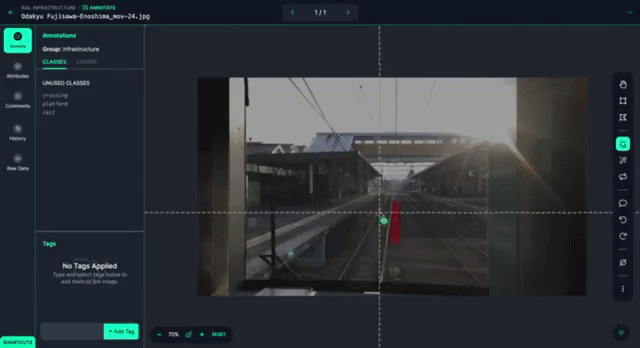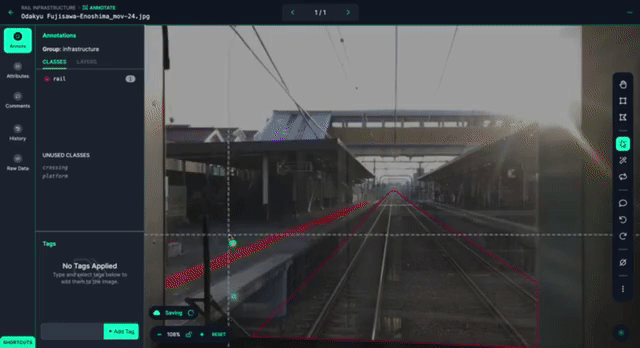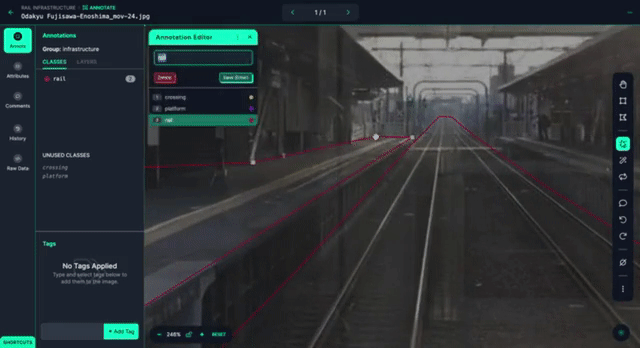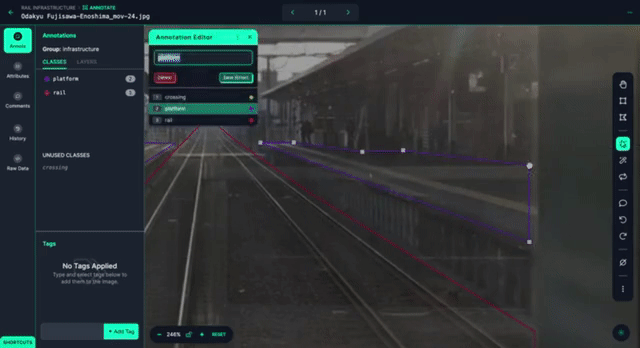
After labeling about thirty images, we trained an initial model for the purposes of helping us label our next iteration, and see where the model needs to improve.
Our initial model training yielded impressive results, with a mAP (mean average precision) of 83.7%. Looking at the results from our test split, it performs somewhat well but reveals room for improvement.

From our results, we can see that the model primarily struggles to identify crossings and the station platform. To help the model learn these areas better, instead of sampling fifty images from the entire trip, we sampled fifty images from the span of one station to another, at a higher rate of images per minute. This way, there will be more training data containing platforms and level crossings for the model to learn from.
We continued this process several times and after a few iterations, we got a mAP of 89.5%, a ~7% improvement, with a dataset of 200 labeled images. When we look at the sample results from the test split, we see that the model detects platforms, the edges of tracks, and crossings much more smoothly, accurately, and consistently.
Now we can move on to detecting people and vehicles so that we can correctly identify those objects in dangerous areas.
Using the same video data, we imported a collection of short segments stopping at or passing through stations. We did this so that we could specifically get training data that would include people, most of whom would be at the train stations.
Since there is already a dataset for people detection on Roboflow Universe, we used that model to help us label the images quickly. In less than an hour, we had a model that performed very well.

Detecting Passenger Train Incidents with Computer Vision
Now we can consistently see where the people are, where they should be (platform), where there might be an issue (platform edge), and where they shouldn’t be and where the train would need to make an emergency stop (tracks). Taking inspiration from previous use cases involving detection-powered actions, we combine the two models to see all the elements we need to create the safety system.

Although running inference on a video does reveal some additional room for improvement on the model, it does accurately detect most of the critical areas well, which should allow tracking of where instances of people (marked green) start leaving the platform (marked yellow) or enter the tracks, (marked red) triggering respective alerts.
For our purposes, we will take the central bottom of each person’s bounding box (which usually correlates well with their feet) as where they are standing. We can match those points against the result of the instance segmentation model to tell if they are standing safely on the platform, or if they are in a location that requires action.

By using generative image models, we can edit an existing real-life image to create a simulated image of what an unsafe situation might look like. In this case, we see that most people are standing safely within the areas marked as a platform (green dots) but one person is standing within the area marked as a track (red dot).
This is where the quick reaction time of a train powered by computer vision could trigger as many measures as necessary to ensure a safe outcome, such as triggering the emergency brake and horn, as well as other measures including alerting the driver and station staff, alerting first responders and much more.
Conclusion
Further explorations of this use case could involve preemptive automated verbal warnings for passengers walking too close to the edge of the platform, computer vision systems attached directly to level crossings, and much more.
Using Roboflow and computer vision, not only were we able to build a safety system that has the potential to quite possibly save lives, but we were able to do so extremely quickly and in a way that didn’t require years of construction and hundreds of millions of dollars of additional construction.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Sep 19, 2023). Using Computer Vision to Improve Railway Safety. Roboflow Blog: https://blog.roboflow.com/railway-safety-computer-vision/