
Fully outsourcing annotation can save time but often costs teams the domain insight needed to build accurate models. Staying closely involved, whether by labeling directly or reviewing outsourced work, helps surface ambiguous task definitions, resolve labeler disagreements, catch model misinterpretations, and enables active learning where model-assisted labeling in Roboflow Annotate feeds performance gaps back into the dataset so quality improves with each iteration.
So you're working on building a machine learning model, and you have hit the realization that you will need to annotate a lot of data to build a performant model. In the machine learning meta today, you will be approached with services offering to fully outsource your labeling woes. You may even be bombarded with memes like this one:

While fully outsourcing labeling could be right for you, we have a few labeling vegetables for you to chew over before you take the plunge.
The Spectrum of Labeling Involvement
When embarking on a labeling task, there is a spectrum of involvement that you can choose to occupy.
Labeling Everything Yourself - You drive the labeling effort, adding each annotation to the dataset.
Having a Full-time Labeler on Staff - You hire someone in house to accomplish the labeling for you.
Hiring a Contractor - Hiring a contractor to label that you can scale up and down, while being able to monitor their labeling progress in Roboflow.
Fully Outsourcing - You pass off a labeling specification sheet along with your images to a service, such as Roboflow Labeling Services.
Let's dive into some considerations around the labeling process.
Reason 1: Better Data not More Data
Less than a decade ago, we lived in a world in AI where it was thought that more data always made your model better. Andrew Ng, a though leader in the AI space, once illustrated the following graph in his deep learning textbook.
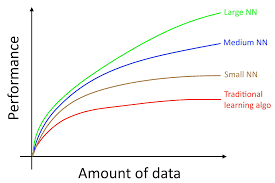
However, as many people are finding, the quality of the dataset is what matters over anything else. Curves like the above might be true for large unsupervised neural networks passing over all of Wikipedia, but if you're training a model on a specific use case with a custom dataset, things are going to look a lot different.
Because the quality of data is so important, taking an active labeling role in the labeling process, whether through direct labeling or through review can be very important.
Reason 2: Problem Formulation and Task Ambiguity
Before you have spent a meaningful amount of time with your dataset, it can be difficult to formulate all of the nuances that will be involved in your labeling task.
Do already have your dataset filtered down to quality images? Do you know have your class list ironed out? Do you know how you'll handle occluded objects?
Many of the specifics of your dataset will be difficult to pass along to a black box service and will require many iteration cycles to nail down. See our guide on how to provide high quality instructions for outsourcing data labeling.
Reason 3: Labeler Disagreement
Outsourced labelers will conflict in their labeling opinion, and while you can average across their decisions, this will always lead to a lower quality dataset than if you had a review step after the labeling has been completed. In our experience, reviewing outsourced labeling tasks, can be equally if not more arduous than having labeled the images ourselves.
Reason 4: Model Interpretation
When you train a model on your newly labeled dataset, the model will succeed in certain areas and it will struggle in others. If you have had intimate experience with your dataset, you will be able to identify parts of the labeling process that could be tweaked and reworked to fix your model. You will also likely have ideas of additional data that you can collect to address the issue at hand.
Which leads us to the most important section of all...
Reason 5: Model Assisted Labeling and Active Learning
By using computer vision automation tools like Roboflow, you can iteratively train models while you are labeling your dataset, enabling Label Assist or fully automating the labeling job with Auto Label. Model assisted labeling applies the predictions of a model as labels. Not only does this allow you to more speedily annotate images, but it allows you to intimately feel the problems that your model is struggling along the way.
When you feel the problems your model is having in labeling, and you gather more data to make your model smarter, you are engaging in a process known as active learning, a strategy that is the cornerstone of any production grade machine learning model.
Conclusion
There are varying levels of involvement you can choose to take through your datasets labeling process, ranging from labeling every image yourself to fully outsourcing your labeling job. In this post, we covered some of the reasons you may want to consider a closer engagement with your dataset including:
- Better Data not More Data
- Problem Formulation and Task Ambiguity
- Labeler Disagreement
- Model Interpretation
- Label Assist and Active Learning
If outsourced labeling makes sense for your use case, Roboflow can help.
Happy labeling, and of course, happy training!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Jul 16, 2021). 5 Reasons to not Fully Outsource Labeling. Roboflow Blog: https://blog.roboflow.com/reasons-to-not-outsource-labeling/