
RF-DETR is Roboflow's family of real-time detection transformers for object detection, instance segmentation, and keypoint detection, first introduced on March 20, 2025. It is the first real-time model to break 60 mean average precision on the COCO benchmark, leads RF100-VL, the benchmark measuring transfer to real-world custom datasets, and ships under an open source Apache 2.0 license.
This post covers how RF-DETR works, how it benchmarks against other real-time detectors, and how to train and deploy it.
RF-DETR is accompanied by a paper, RF-DETR: Neural Architecture Search for Real-Time Detection Transformers, which details the architecture, the neural architecture search method behind it, and full benchmark results on Arxiv.
The model is available on GitHub, trainable in Roboflow on hosted GPUs, and fine-tunable via a Colab notebook.
Train RF-DETR on your own data in an afternoon: create a free Roboflow account, upload and label images, and start a Custom Training run.
What Is RF-DETR?
RF-DETR is a transformer-based architecture in the DETR (detection transformer) family, designed to transfer well across domains and dataset sizes while running at real-time speeds, often on limited compute at the edge.
The family spans sizes from Nano to 2XLarge for object detection, a parallel RF-DETR Seg family for instance segmentation, and RF-DETR Keypoint for pose and keypoint tasks, so one architecture covers the core detection workloads at whatever accuracy-latency point your deployment needs.
You can try an RF-DETR model below:
Prefer to call RF-DETR from your own code? The fastest way to run it is the Roboflow serverless API, with no GPU, weights download, or local setup required:
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="YOUR_ROBOFLOW_API_KEY"
)
result = client.infer("image.jpg", model_id="rfdetr-base")
print(result)This runs the COCO-trained RF-DETR-base checkpoint in the cloud. Models you fine-tune on Roboflow deploy to the same hosted endpoint automatically. Your API key is in your workspace settings; if you do not have an account yet, create one free.
RF-DETR Model Performance and Benchmarks
Object detection models face a mini crisis in evaluation. Common Objects in Context (COCO), a canonical 163k image benchmark from Microsoft first introduced in 2014, hasn't been updated since 2017. At the same time, models have gotten really good – and used in contexts well beyond 'common objects.' New state-of-the-art models often increase COCO mAP by fractions of a percent while reaching for other datasets (LVIS, Objects365) to demonstrate generalizability.
This is part of our motivation of introducing a model: we aim to show not only competitive performance on existing benchmarks like COCO, yet also show why domain adaptability ought to be a top level consideration alongside latency. In a world where COCO performance is increasingly saturated for models of similar size, how well a model is able to adapt – especially to novel domains – grows in importance.
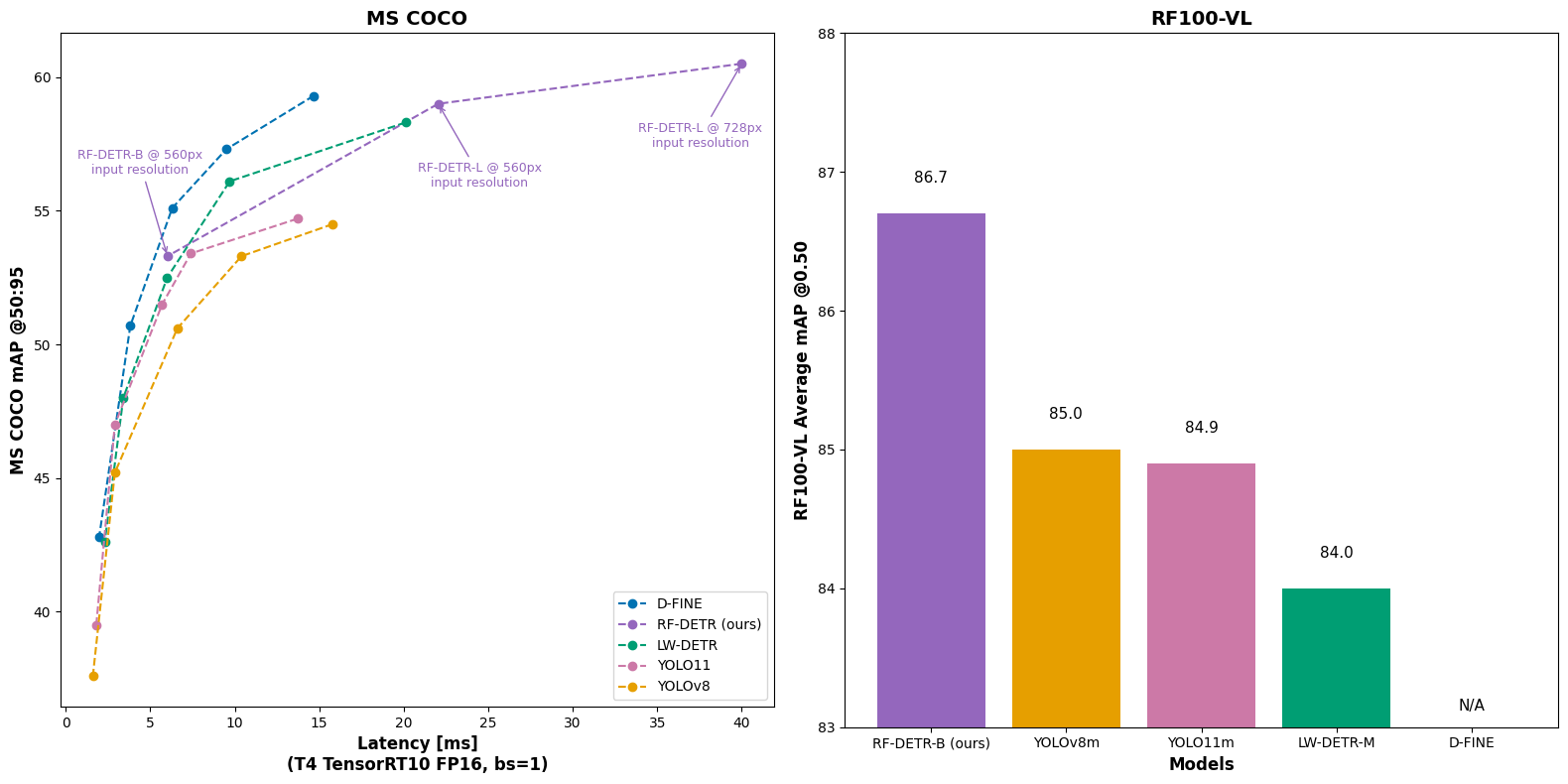
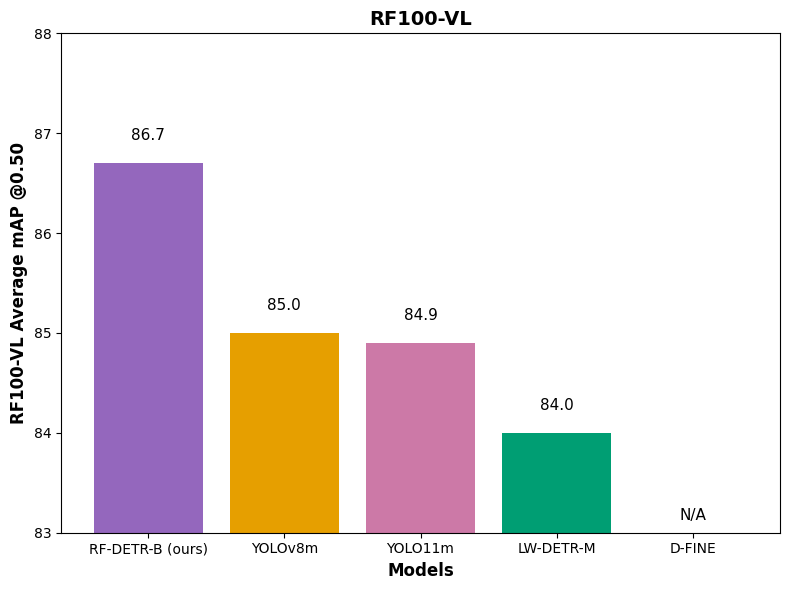
We evaluate performance in three categories: COCO mean average precision, RF100-VL mean average precision, and speed. RF100-VL is a selection of 100 datasets from the 500,000+ open source datasets on Roboflow Universe. It represents how computer vision is actually being applied to problems like aerial imagery, industrial contexts, nature, lab imaging, and more.
That domain transfer is why RF-DETR is the model behind production deployments in manufacturing and logistics, where datasets are custom, objects are occluded, and latency budgets are real.
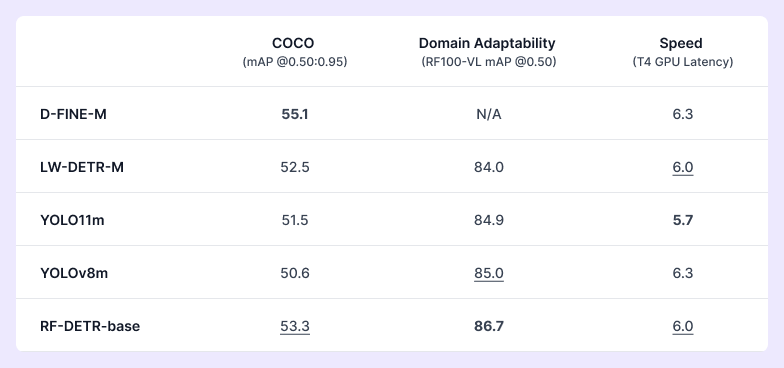
RF100 has been used by research labs like Apple, Microsoft, Baidu, and others. (This also means that in joining us to build open source computer vision on Roboflow, you are improving the entire field's ability to develop visual understanding.) A great model should do well on COCO compared to models of similar size, adapt very well to a domain problem, and be fast.
RF100-VL is our new take on the mission of RF100, designed to not only benchmark object detectors in novel domains but also to allow direct comparison between object detectors and large language models with standardized evaluation criteria.
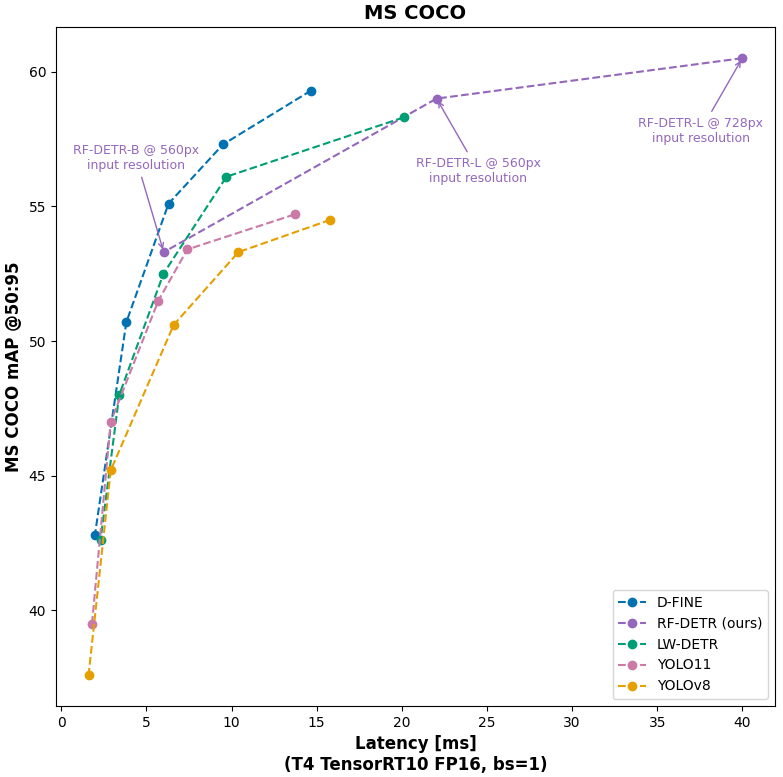
We evaluate RF-DETR relative to realtime COCO SOTA transformer models (D-FINE, LW-DETR) and SOTA YOLO CNN architectures (YOLO11, YOLOv8). With respect to these parameters, RF-DETR is the only model #1 or #2 in all categories.
Of note, the speed shown is the GPU latency on a T4 using TensorRT10 FP16 (ms/img) in a concept LW-DETR popularized called "Total Latency." Unlike transformer models, YOLO models conduct NMS following model predictions to provide candidate bounding box predictions to improve accuracy.
However, NMS results in a slight decrease in speed as bounding box filtering requires computation (the amount varies based on the number of objects in an image). Note most YOLO benchmarks use NMS to report the model's accuracy, yet do not include NMS latency to report the model's corresponding speed for that accuracy. This above benchmarking follows LW-DETR's philosophy of providing a total amount of time to receive a result uniformly applied on the same machine across all models. Like LW-DETR, we present latency using a tuned NMS designed to optimize latency while having minimal impact on accuracy, used only for benchmarking; RF-DETR itself is NMS-free.
Secondly, D-FINE fine-tuning is unavailable, and its performance in domain adaptability is, therefore, inaccessible. Its authors indicate, "If your categories are very simple, it might lead to overfitting and suboptimal performance." There are also a number of open issues inhibiting fine-tuning. We have opened an issue to aim to benchmark D-FINE with RF100-VL.
On COCO, specifically, RF-DETR is strictly Pareto optimal relative to YOLO models and competitive – though not strictly more performant – with respect to realtime transformer based models. However, in releasing RF-DETR-large and using a 728 input resolution, RF-DETR achieves the highest mAP (60.5) for any realtime (Papers with Code defines "real-time" as 25+ FPS on T4).
Based on community feedback, we may release more model sizes in the RF-DETR family in the future.
RF-DETR Architecture Overview
Historically, CNN-based YOLO models have given the best accuracy for real-time object detectors. CNNs continue to be a core component of many of the best approaches in computer vision, e.g. D-FINE leverages both CNNs and transformers in its approach.
CNNs alone do not benefit as strongly from large scale pre-training like transformer-based approaches do and may be less accurate or converge more slowly. In many other subfields of machine learning, from image classification to LLMs, pre-training is more and more essential to achieving strong results. Therefore, an object detector that shows strong benefit from pre-training is likely to lead to better object detection results. However, transformers have typically been quite large and slow, unfit for many challenges in computer vision.
Recently, through the introduction of RT-DETR in 2023, the DETR family of models has been shown to match YOLOs in terms of latency when considering the runtime of NMS, which is a required post-processing step for YOLO models but not DETRs. Moreover, there has been an immense amount of work on making DETRs converge quickly.
Recent advances in DETRs combine these two factors to create models that, without pre-training, match the performance of YOLOs, and with pre-training, significantly outperform at a given latency. There is also reason to believe that stronger pre-training increases the ability of a model to learn from small amounts of data, which is very important for tasks that may not have COCO-scale datasets. Hybrid approaches are also evolving. YOLO-S merges transformers and CNNs for realtime performance. YOLOv12 also takes advantage of sequence learning alongside transformers.
RF-DETR uses an architecture based on the foundations set out in the Deformable DETR paper. Whereas Deformable DETR uses a multi-scale self-attention mechanism, we extract image feature maps from a single-scale backbone.
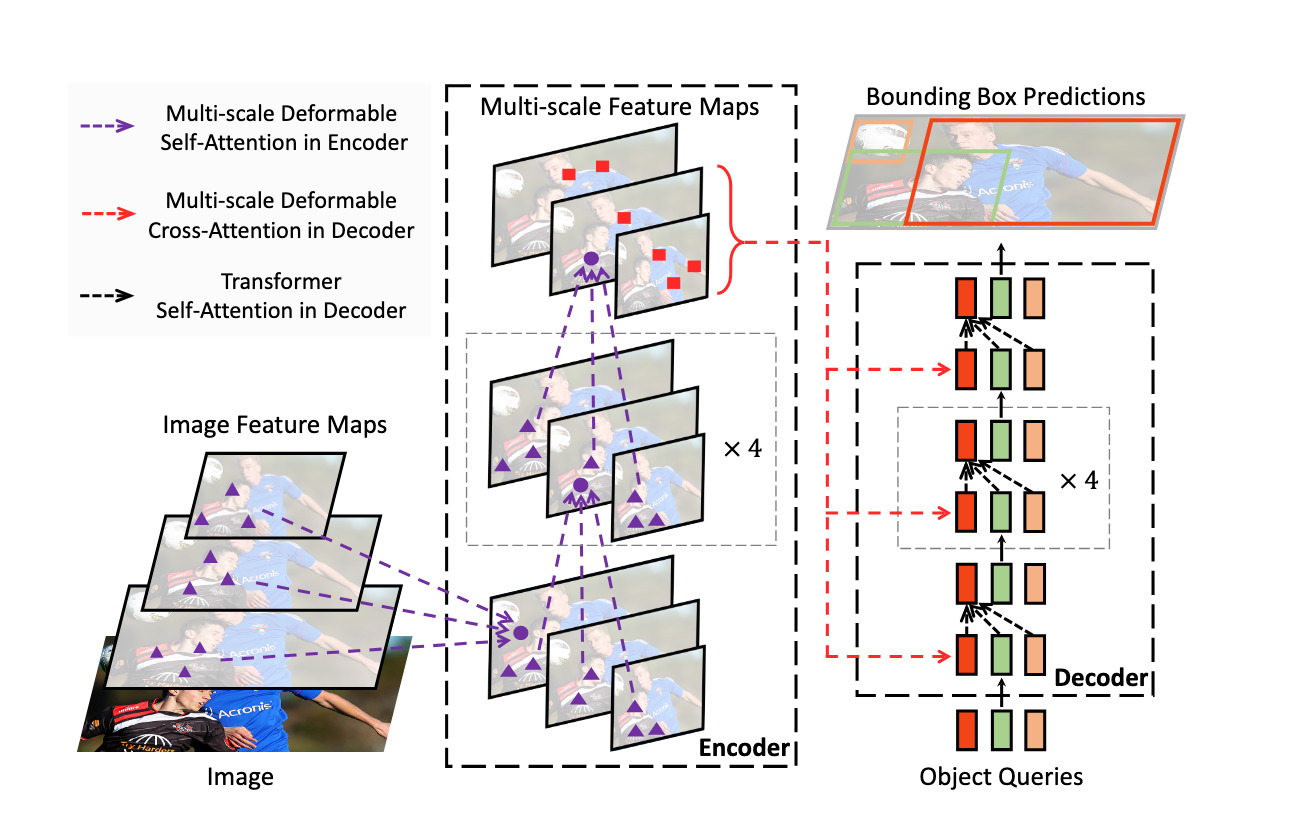
We explored pushing forward the state of the art by combining the best of modern DETRs with the best of modern pre-training. Specifically, we created RF-DETR by combining LW-DETR with a pre-trained DINOv2 backbone. This gives us exceptional ability to adapt to novel domains based on the knowledge stored in the pre-trained DINOv2 backbone.
We also train the model at multiple resolutions, which means we can choose to run the model at different resolutions at runtime to tradeoff accuracy and latency without retraining the model.
How to Use Free Open-Source RF-DETR
We are releasing RF-DETR with a pre-trained checkpoint trained on the Microsoft COCO dataset. This checkpoint can be used with transfer learning to fine-tune an RF-DETR model with a custom dataset.
RF-DETR can be fine-tuned using the rfdetr Python package. We have prepared a dedicated Colab notebook that walks through how to train an RF-DETR model on a custom dataset.
The fastest path is training in Roboflow: create a project, generate a dataset version, select Custom Training and RF-DETR, and train from an optimized checkpoint on hosted GPUs, with no environment to manage.
See the Train and Deploy RF-DETR guide for a walkthrough. Trained models deploy through the Serverless Hosted API, on your own hardware with open source Roboflow Inference, or inside Roboflow Workflows chained with tracking, logic, and notifications.
The RF-DETR docs cover training on custom datasets in COCO or YOLO format, checkpoint management, resuming runs, ONNX export, and uploading fine-tuned weights to Roboflow for hosted deployment.
More to Come
We're introducing RF-DETR because we see a clear opportunity to move the field forward while showcasing our methods so everyone else can improve upon this result too. Making the world programmable takes all of us.
At Roboflow, we pride ourselves on supporting a wide array of vision models – from large vision language models to small task-specific models to adapting closed source APIs. Even as we introduce this novel architecture, we will continue to support any and all models.
Ready to get started with RF-DETR? Check out our model fine-tuning guide which walks through, step-by-step, how to train your own RF-DETR model. You can also view the source code behind the model on GitHub.
RF-DETR vs. YOLOv11
RF-DETR is primarily focused on object detection and segmentation. It's designed to be highly fine-tunable, often converging in fewer epochs than YOLO models on small, custom datasets due to the pre-trained DINOv2 backbone and transformer architecture, making it better than YOLOv11 at handling complex scenes with overlapping objects. YOLOv11 relies on convolutions, scanning the image in patches, which is incredibly fast and efficient but traditionally struggles more with heavy occlusion.
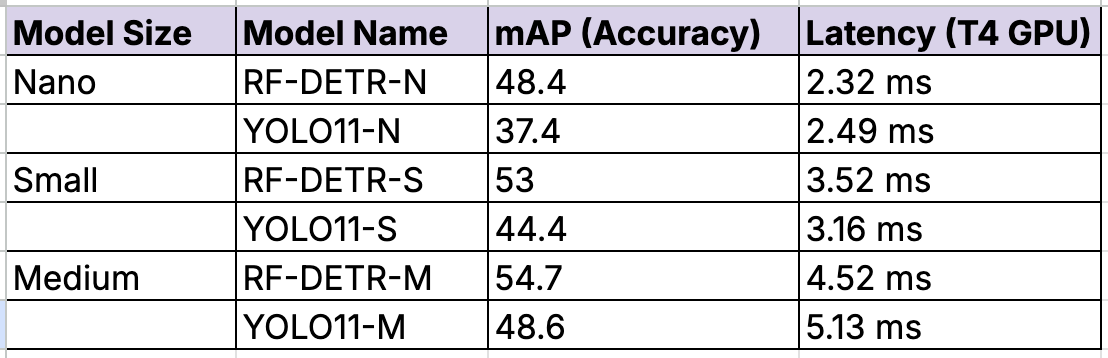
RF-DETR achieves higher accuracy (mAP) than YOLO11 for the same inference speed, particularly in the "Nano" and "Small" model sizes.
RF-DETR is licensed under Apache 2.0, is truly open-source. You can use it commercially, modify it, and distribute it without releasing your source code or paying a fee.
YOLO11 is licensed under AGPL-3.0. If you use it in a product that you distribute, you may be required to open-source your code. For closed-source commercial use, you typically need to purchase an Enterprise License.
As a result, RF-DETR is best when you need the highest possible accuracy, especially for small objects or crowded scenes; you need a permissive license (Apache 2.0) for a commercial product without paying fees; or you have limited data - the transformer backbone often generalizes better with fewer training images.
What does RF-DETR stand for?
Roboflow Detection Transformer. It belongs to the DETR family of models, which predict a set of objects directly with a transformer rather than proposing and filtering candidate boxes.
Is RF-DETR free for commercial use?
Yes. The core models and code are released under the Apache 2.0 license, with no copyleft obligations and no commercial license to purchase.
What tasks does RF-DETR support?
Object detection, instance segmentation (RF-DETR Seg), and keypoint detection (RF-DETR Keypoint), in sizes from Nano to 2XLarge. Detection and segmentation fine-tune from COCO-pretrained checkpoints in Roboflow or with the rfdetr package.
How is RF-DETR different from RT-DETR and D-FINE?
All three are real-time DETR-family models. RF-DETR pairs an LW-DETR-style architecture with a pre-trained DINOv2 backbone and applies neural architecture search across the accuracy-latency curve, which is why it transfers better to custom domains, the RF100-VL result, while remaining competitive on COCO.
Does RF-DETR need NMS?
No. Like other DETR models, it predicts a set of objects end to end, so there is no non-maximum suppression step, and reported latency is the full time to a usable result.
Published: March 20, 2025
Updated: June 1, 2026
Cite this Post
Use the following entry to cite this post in your research:
Peter Robicheaux, James Gallagher, Joseph Nelson, Isaac Robinson. (Jun 1, 2026). RF-DETR: A SOTA Real-Time Object Detection Model By Roboflow. Roboflow Blog: https://blog.roboflow.com/rf-detr/