
In this blog post, we will explore how different cloud providers compare in running custom vision model inference.
Custom RF-DETR Model
If you need OCR, face detection/comparison, or general-purpose COCO-20 classification and detection, the major clouds already offer plenty of managed options, such as AWS Rekognition, GCP Vision, and Azure AI Vision.
Here, we will be looking at serving a state-of-the-art architecture object detection model, RF-DETR, fine-tuned on a custom dataset and optimized for GPU inference.
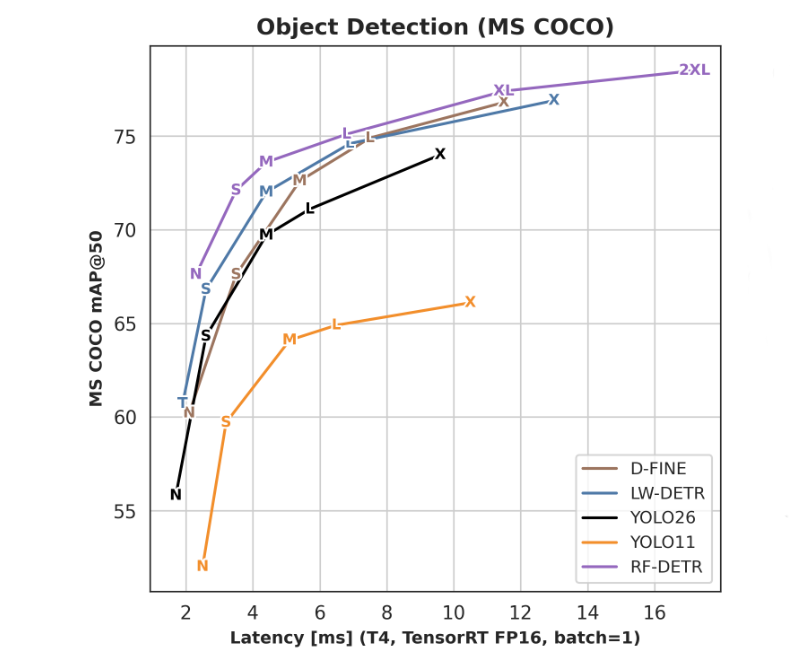
We'll be looking specifically at the RF-DETR XL version, which achieves a score of 77.4 on COCO mAP@50. With TRT compilation at FP16 with batch_size=1 it runs at about 12ms on T4 GPU.
Serverless Inference
We're also specifically looking at inference deployment modes that don't require an always-on GPU. We'll be looking at 3 different use-cases:
- Continuous inference at 1 inference per 10 seconds (360 req/h)
- Continuous inference at 1 inference per 30 seconds (120 req/h)
- Burst mode, 100 requests per 30 minutes (200 req/h)
Cost comparison
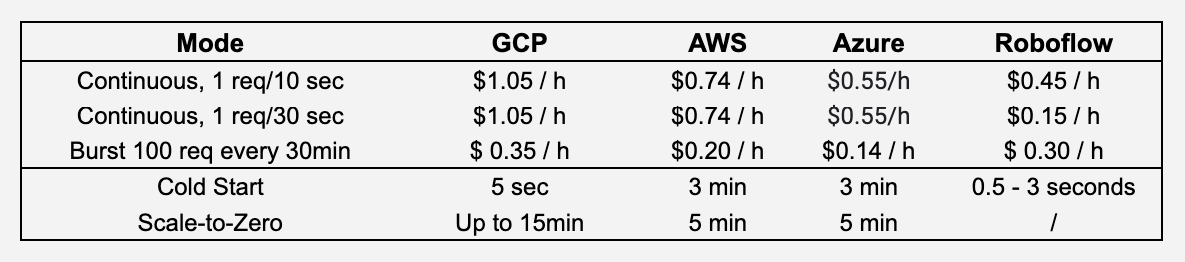
Lets breakdown each provider to understand their functionality and related costs.
Roboflow Serverless Hosted API
Roboflow's Serverless Hosted API is best for low-frequency and sporadic AI workloads. Because of the shared infrastructure and containers, there's no scale-to-zero cost, and cold start is only for the model itself (loading into the GPU).
When it's needed again, only the model itself needs to get loaded into the GPU (takes between 500 and 3000ms, depending on size). Because GPUs are shared between multiple models and clients, inference time can sometimes be less predictable.
Cold start/boot happens more often when inference requests are less frequent. But for continuous inference requests at 10/30 sec, we'll assume it's about 2% (3 sec cold boot). The actual inference time of RF-DETR XL is about 30ms, which gets rounded to 100ms inference time. We'll also take into account that as of April 2026, 1 credit is $4.
- Continuous 1 req/10sec, 2% cold boot: 0.114 credits/h, or $0.45/h
- Continuous 1 req/30sec, 2% cold boot: 0.038 credits/h, or $0.15/h
For burst mode, since it's 30 minutes between the bursts, we assume we'll get cold boots on 3 instances, and Serverless will then route all requests to those GPU instances (that have model warm). This ends up to about 0.075 credits/h, or $0.30 /h.
GCP Cloud Run
Google recommends using Cloud Run for such AI workloads. As it only offers L4 and RTX Pro 6000, we'll be using L4 prices for calculations. Minimum resources alongside an L4 are 4 vCPU cores and 16GB RAM. Total cost per second would be:
- L4 GPU: $0.0001867 / sec
- 16 GB RAM: $0.000032 / sec
- 4 vCPU: $0.000072/sec
- Total: $1.045 / hour
While GCP advertises a 5-second startup time, GPU is only available with instance-based billing (not possible with request-based billing), which means that even if you send a single inference request that completes in 100 ms, you’d pay for up to 15 minutes of inference time, before the instance spins back down (with scale to zero).
For both inference frequencies, we'd need to have always-on GPU instance, as it wouldn't be able to scale to zero. So for both frequencies that'd be $1.05/h.
Burst 100 req/30min: Since L4 is about 3x faster than T4 we'd need about 400 ms of inference time to process 100 images. We'd need an additional 5 sec for cold start, and around 600 seconds to scale to 0. As we're processing bursts every 30min, that ends up to 1211 sec of inference compute every hour, so about $0.35/h.
AWS SageMaker
AWS recommends using AWS SageMaker's Asynchronous Inference for such AI workloads. They also offer Serverless Inference, but that only offers CPU compute, so it wouldn't work for our use case. They offer ml.g4dn.xlarge (T4 with 16 GB RAM, 4 vCPU and 16 GB RAM) at $0.736/hour.
AWS mentions that provisioning takes several minutes, and Scale-to-Zero takes several minutes.
For both inference frequencies, we'd need to have an always-on GPU instance, as it wouldn't be able to scale to zero. So for both frequencies that'd be $0.74/h.
Burst 100 req/30min: T4 would need about 1200 ms of inference time to process 100 images. We'd need an additional 180 sec for cold start, and around 300 seconds to scale to 0. As we're processing bursts every 30min, that ends up to ~962 sec of inference compute every hour, so about $0.198/h.
Azure Serverless GPU
Azure recommends using Serverless GPU in Azure Container Apps for vision AI workloads. They offer either T4 or A100 GPUs, and for a comparable machine that'd cost:
- T4 GPU: $0.00009 / sec
- 16 GB RAM: $0.000048 / sec
- 4 vCPU: $0.000096 / sec active
- Total: between $0.55 - $0.84 / hour (depending on vCPU usage)
No mentions about cold start, but there's a technical guide needing 8-10 minutes for cold start. Let's say I'd take about 3 minutes for a cold start, and they mention 300 seconds for Scale-t0-Zero in their documentation.
For both inference frequencies, we'd need to have an always-on GPU instance, as it wouldn't be able to scale to zero. As CPU would be mostly inactive, that'd be $0.55/h.
Burst 100 req/30min: T4 would need about 1200 ms of inference time to process 100 images. About 962 sec of GPU compute per hour, so about $0.14/h.
Conclusion
Choosing the right cloud provider for vision inference depends entirely on your traffic patterns and your tolerance for cold starts. As our comparison shows, serverless is a spectrum, and the billing mechanics behind each provider can lead to vastly different monthly invoices.
If you want to avoid the headache of managing GPU idle times and instance spin-downs for custom models like RF-DETR, Roboflow provides a frictionless and cost-effective experience for sporadic traffic.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Apr 16, 2026). Serverless GPU Inference Cost Comparison: Roboflow, GCP, AWS, Azure. Roboflow Blog: https://blog.roboflow.com/serverless-inference-vision-ai-cost-comparison/