
Gemini 3.5 Flash, released at Google I/O on May 19, 2026, currently tops the Roboflow Vision Evals leaderboard across 67 real vision prompts covering defect detection, document understanding, object counting, and spatial reasoning. It outperforms Gemini 3.1 Pro on counting and spatial tasks while running roughly three times faster and at about half the cost of comparable frontier models, which changes the economics of putting a vision-language model inside a production pipeline. It is available now in Roboflow Workflows via the Google Gemini block.
Google released Gemini 3.5 Flash May 19, 2026 at Google I/O and it is the highest performing frontier model on the Roboflow Vision Evals leaderboard, beating Gemini 3.1 Pro on counting and spatial reasoning while running about three times faster.
Six months after Gemini 3 Pro set the bar for visual reasoning, Gemini 3.5 Flash introduces a new model family designed around agentic, long-horizon work. Gemini 3.5 Flash is available today through the Gemini API, AI Studio, Antigravity, Gemini Enterprise, and Roboflow Workflows.
For vision teams, the most notable advancement with Gemini 3.5 Flash is inference at Flash latencies and roughly half the cost of other frontier models. That changes the economics of using a VLM inside a vision pipeline.
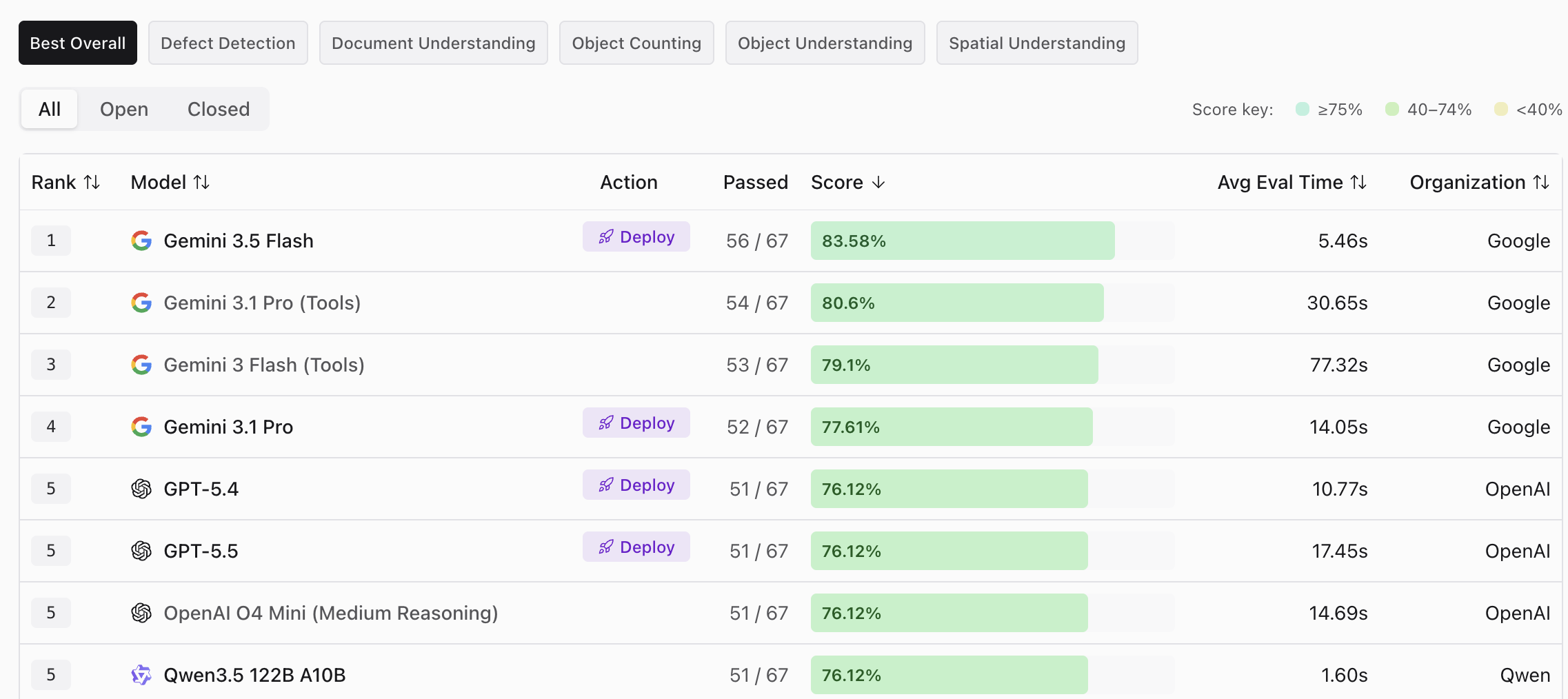
Across 66 models tested, Gemini 3.5 Flash is now on top the vision leaderboard built from 67 real vision AI prompts across Defect Detection, Document Understanding, Object Counting, Object Understanding, and Spatial Understanding.
It is the highest score ever recorded, and it is faster than every model above it in the previous rankings.
What is Gemini 3.5 Flash?
Gemini 3.5 Flash is the first model in Google DeepMind's new 3.5 family. Google's framing for the release is keeping frontier intelligence intact, but make it fast and cheap enough to run inside agentic and multi-step workflows.
According to Google, 3.5 Flash outperforms the previous Gemini 3.1 Pro on several agentic and coding benchmarks while running about 4x faster on output tokens per second than other frontier models in its class.
Where Gemini 3 Pro leaned into Deep Think and very long context, Gemini 3.5 Flash leans into throughput. The model is now the default for the Gemini app and AI Mode in Google Search, and it is the engine behind Gemini Spark, Google's new personal AI agent.
Key features for vision AI teams
- Strong multimodal reasoning at Flash speed. 84.2% on CharXiv Reasoning (information synthesis from complex charts), competitive with much larger flagship models.
- Multi-step agentic capabilities. 83.6% on MCP Atlas and 76.2% on Terminal-Bench 2.1, useful for vision agents that plan, call tools, and iterate on what they see.
- Lower cost per call. Google reports 3.5 Flash running at less than half the cost of other frontier models for comparable agentic workloads, which matters when you are running a VLM over thousands of frames or documents.
First impressions using Gemini 3.5 Flash for vision workflows
A few things stand out after spending time with 3.5 Flash on visual inputs.
What is working well:
- Document and chart understanding at speed. The combination of strong multimodal reasoning and 4x faster output makes 3.5 Flash a credible choice for high-volume document parsing. Ramp is already using it for invoice OCR combined with reasoning over historical patterns, which is one of the launch partner case studies Google highlighted.
- Tool-using vision agents. The jump on MCP Atlas matters as more products open their platforms with MCPs. If you are building an agent that looks at an image, decides what to do next, and calls a tool, the agent loop now has fewer reasons to fail at the planning step.
- Predictable cost at scale. Roughly half the cost of comparable frontier models, at higher speed, makes it realistic to run a VLM step inside a pipeline rather than reserving it for one-off enrichment.
Where to be careful:
- Precise localization is still not the strength of any VLM. If you need pixel-accurate bounding boxes for runtime inference, a specialized detector like RF-DETR will outperform a VLM call on both accuracy and cost.
- Real-time video is a stretch. Even at 4x the speed of other frontier models, a per-frame VLM call is the wrong shape for 30 FPS inference at the edge. Use 3.5 Flash where it makes decisions, not where it processes every frame.
Gemini 3.5 Flash examples
Gemini 3.5 Flash is adept at understanding the intricacies of common objects. Useful for straightforward vision applications.


Gemini 3.5 Flash is able to identify birds from overhead and not be confused by the bird shaped shadows. Models with good reasoning capability are better suited for these types of nuanced visuals.

Applying general knowledge and reasoning produces quality results for common industrial applications like identifying packages, package labels, and open packages.



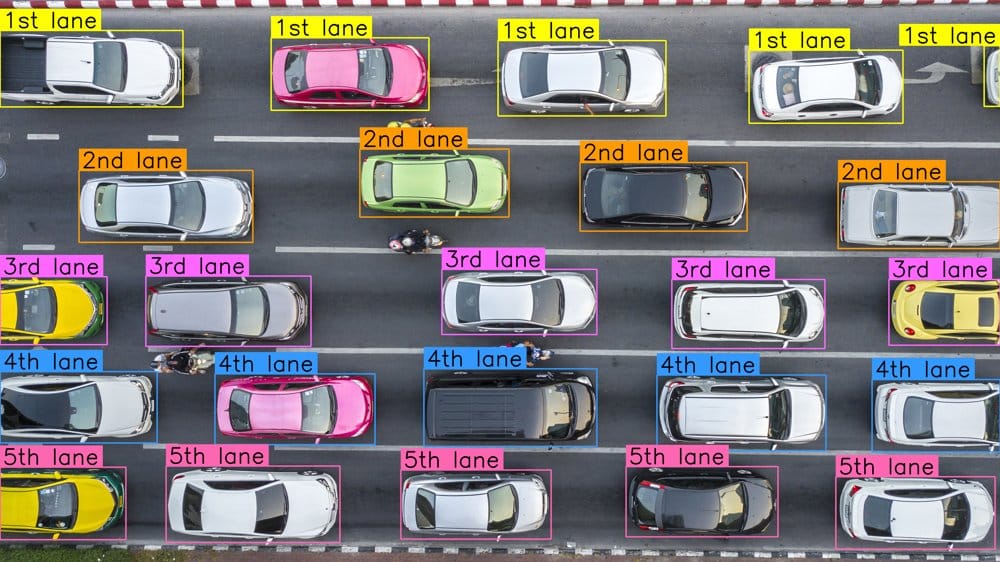
Advanced reasoning capabilities, like relative references, enables for creating application logic with only text inputs. In the past, developing a vision pipeline to understand cars relative to specific lanes would have required creating zones specific to the lanes. Gemini 3.5 Flash can do this automatically.
Where Gemini 3.5 Flash beats Gemini 3.1 Pro
Across 18 prompts where the two models differ, the biggest gains show up in counting and spatial reasoning, the two categories that matter most for industrial vision AI.
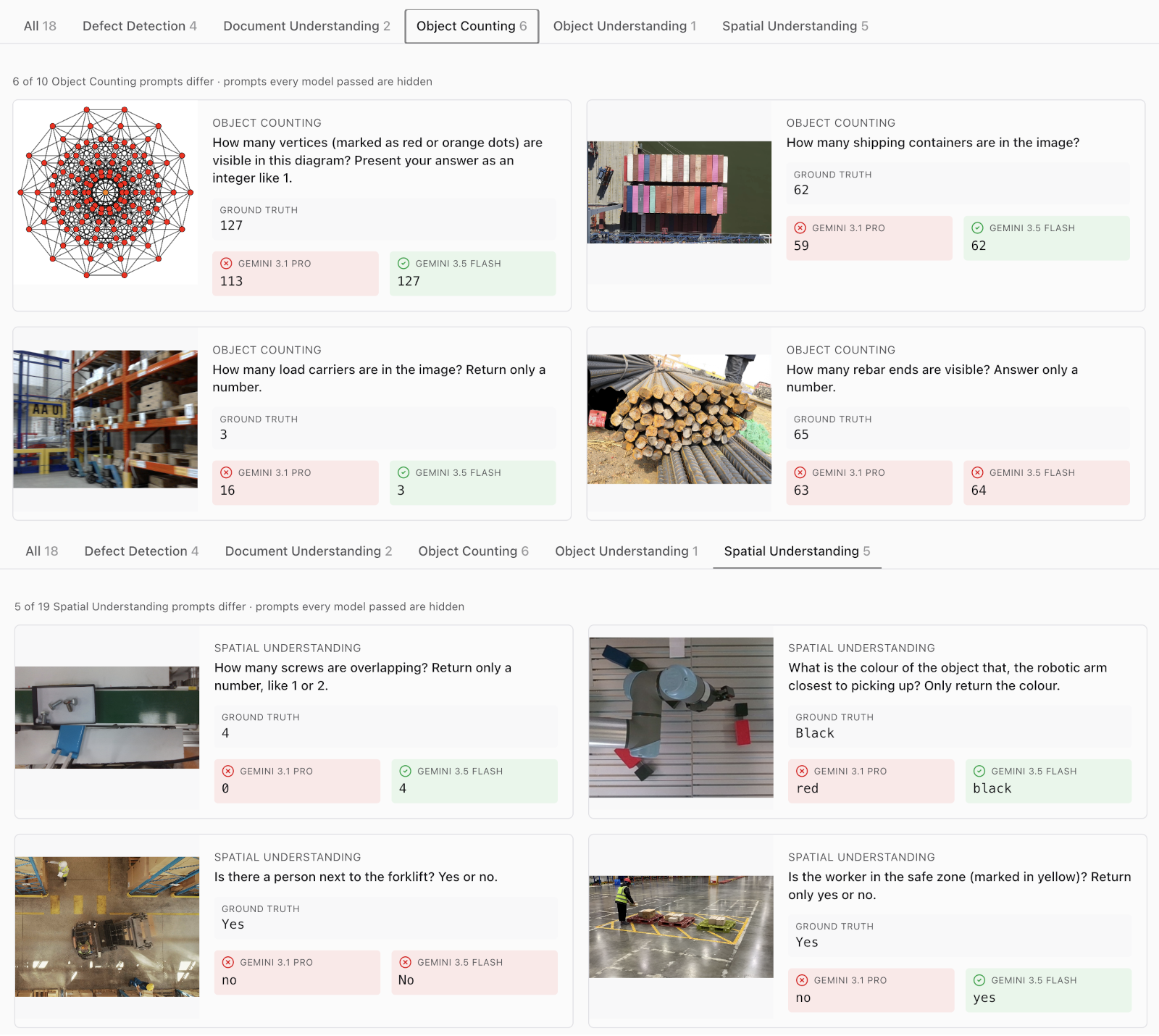
These are the prompts that show up in pallet counting, pick-and-place verification, and safety zone monitoring.
Using Gemini 3.5 Flash in Roboflow Workflows
Roboflow Workflows is the way to assemble pipelines that combine specialized vision models with VLMs and business logic.
A common Workflow shape that benefits from 3.5 Flash:
- RF-DETR or SAM 3 detects and segments objects or regions of interest.
- A dynamic crop block isolates each region.
- A Gemini 3.5 Flash block reasons over each crop with a structured prompt.
- A parsing block turns the JSON response into typed fields you can route into a database, alert, or downstream Workflow.
When should you use Gemini 3.5 Flash?
Gemini 3.5 Flash is a strong choice when:
- You are doing document understanding at volume. Invoices, forms, contracts, lab reports, anything where the value of the answer is high and the latency budget is in seconds, not milliseconds.
- You are building a vision agent. The combination of multimodal reasoning and strong tool-use scores makes it a credible default for agentic loops that involve looking at something and deciding what to do.
- You are generating training data. Using a frontier VLM as an automated labeler, then training a smaller specialized model like RF-DETR for production inference, is one of the most consistent ways to cut cost without giving up quality. 3.5 Flash makes this loop noticeably cheaper.
Stick with a specialized model when:
- You need real-time inference at the edge, especially on video.
- You need precise localization, segmentation, or counting at scale. Counting is still a known weak point for VLMs.
- You are running the same task millions of times on the same kind of input. A specialized detector trained on your data will be faster, cheaper, and more accurate than any frontier VLM at that point.
Conclusion
Gemini 3.5 Flash marks a pivotal shift where frontier intelligence starts being a practical, scalable tool for production use cases.
By topping leaderboards while slashing costs and latency, Google has changed the landscape for using VLMs at scale. Gemini 3.5 Flash unlocks a new generation of agentic, multi-step workflows that were previously too expensive or too slow to be viable in most use cases. Whether you are parsing complex documents at scale or building vision agents that need to plan and act, the barrier to entry just got significantly lower. Start building with Gemini 3.5 Flash today in Roboflow.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (May 22, 2026). Gemini 3.5 Flash for Vision: Evaluation and Benchmarks. Roboflow Blog: https://blog.roboflow.com/use-gemini-3-5-flash-vision/