
Split your dataset three ways to prevent overfitting: a training set the model learns from (70%), a validation set for tuning and early stopping during training (20%), and a test set you touch once at the end for an unbiased read on production performance (10%). Augmentations go in the training set only, and watch for train/test bleed, where duplicate images land in different splits and inflate your metrics.
At Roboflow, we often get asked:
"What is the train, validation, test split and why do I need it?"
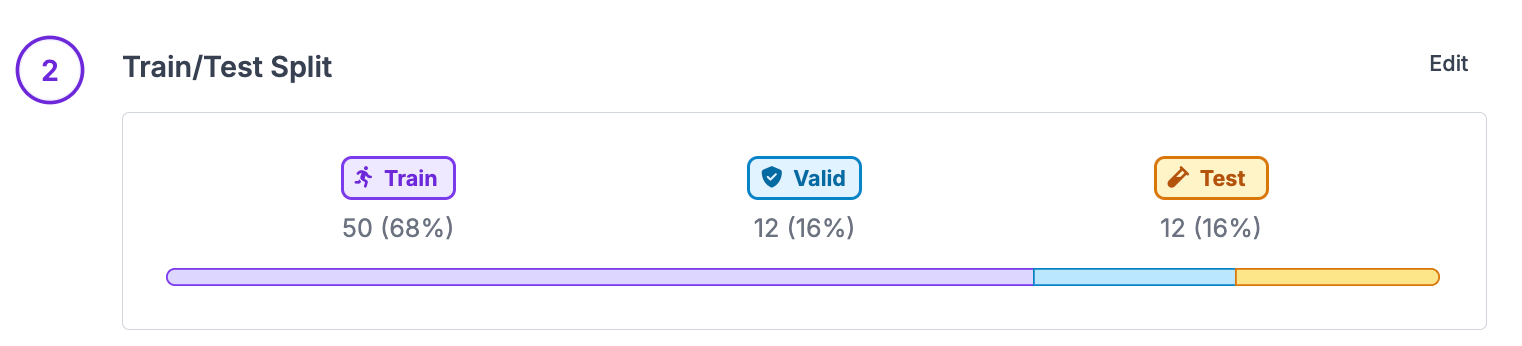
A train, validation, test split divides your dataset into three parts: a training set the model learns from, a validation set for tuning and monitoring during training, and a test set held back until the end for an unbiased measure of how the model will perform in production. The split exists to prevent overfitting and to keep your evaluation honest. The motivation is simple; the practice is more nuanced, and today I will cover both.
What Is Overfitting in Computer Vision?
When training a computer vision model, you show your model example images to learn from. In order to guide your model to convergence, your model uses a loss function to inform the model how close or far away it is from making the correct prediction. A loss function is a way of describing the "badness" of a model. The smaller the value of the loss function, the better the model.
The model formulates a prediction function based on the loss function, mapping the pixels in the image to an output.
The danger in the training process is that your model may overfit to the training set. That is, the model might learn an overly specific function that performs well on your training data, but does not generalize to images it has never seen.
This is a 2D example.
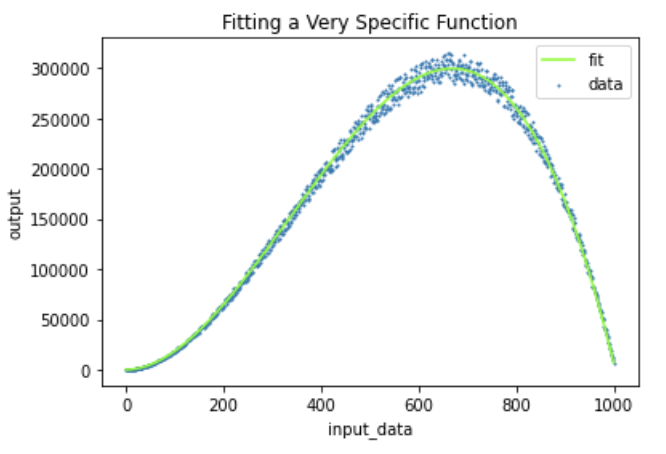
If your model hyper-specifies to the training set, your loss function on the training data will continue to show lower and lower values, but your loss function on the held-out validation set will eventually increase. You can see this plotted below with two curves visualizing the loss function values as training continues:
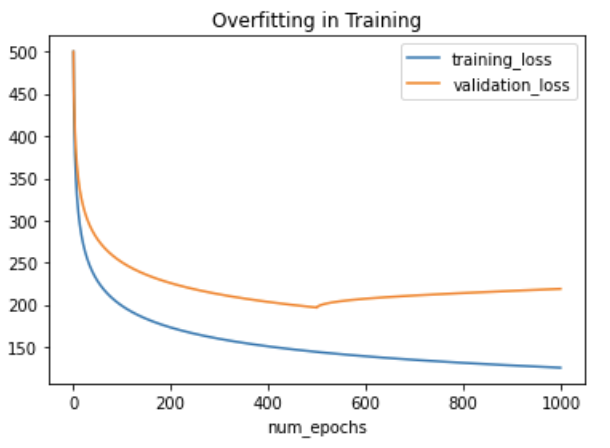
This means that your model isn't learning well, but is basically memorizing the training set. This means that your model will not perform well on new images it has never seen before.
The train, validation, and testing splits are built to combat overfitting.
What Is the Training Dataset?
The difference between the training set and the validation set is the training set is the largest corpus of your dataset that you reserve for training your model. After training, inference on these images will be taken with a grain of salt, since the model has already had a chance to look at and memorize the correct output.
For a default, we recommend allocating 70% of your dataset to the training set. (If you're an advanced user and feel comfortable not using defaults, we've made it easier for you to change these defaults in Roboflow.)
What Is the Validation Dataset?
The validation set is a separate section of your dataset that you will use during training to get a sense of how well your model is doing on images that are not being used in training.
During training, it is common to report validation metrics continually after each training epoch such as validation mAP or validation loss. You use these metrics to get a sense of when your model has hit the best performance it can reach on your validation set. You may choose to cease training at this point, a process called "early stopping."
As you work on your model, you can continually iterate on your dataset, image augmentations, and model design to increase your model's performance on the validation set.
We recommend holding out 20% of your dataset for the validation set.
What Is the Test Dataset?
After all of the training experiments have concluded, you probably have gotten a sense on how your model might do on the validation set. But it is important to remember that the validation set metrics may have influenced you during the creation of the model, and in this sense you might, as a designer, overfit the new model to the validation set.
Because the validation set is heavily used in model creation, it is important to hold back a completely separate stronghold of data - the test set. You can run evaluation metrics on the test set at the very end of your project, to get a sense of how well your model will do in production.
We recommend allocating 10% of your dataset to the test set.
How Train Validation and Test Relate to Preprocessing and Augmentation
Naturally, the concept of train, validation, and test influences the way you should process your data as you are getting ready for training and deployment of your computer vision model.
Preprocessing steps are image transformations that are used to standardize your dataset across all three splits. Examples include static cropping your images, or gray scaling them. All preprocessing steps are applied to train, validation, and test.
Image augmentations are used to increase the size of your training set by making slight alterations to your training images. These occur only to the training set and should not be used during evaluation procedures. For evaluation, you want to use the ground truth images, residing in the validation and test sets.
Common Pitfalls in the Train, Validation, Test Split
Here are some common pitfalls to avoid when separating your images into train, validation and test.
Train/Test Bleed
Train Test bleed is when some of your testing images are overly similar to your training images. For example, if you have duplicate images in your dataset, you want to make sure that these do not enter different train, validation, test splits, since their presence will bias your evaluation metrics. Thankfully, Roboflow automatically removes duplicates during the upload process, so you can put most of these thoughts to the side.
Overemphasis on the Training Set
The more data, the better the model. This mantra might tempt you to use most of your dataset for the training set and only to hold out 10% or so for validation and test. Skimping on your validation and test sets, however, could cloud your evaluation metrics with a limited subsample, and lead you to choose a suboptimal model.
Overemphasis on Validation and Test Set Metrics
At the end of the day, the validation and test set metrics are only as good as the data underlying them, and may not be fully representative of how well you model will perform in production. That said, you should use them as a guide post, pushing your models performance and robustness ever higher.
How to Create a Train, Validation, Test Split
In Python, the standard tool is scikit-learn's train_test_split, called twice to produce three sets. A 70/20/10 split looks like this:
from sklearn.model_selection import train_test_split
# First split: 70% train, 30% held out
train_files, holdout_files = train_test_split(
image_files, test_size=0.30, random_state=42
)
# Second split: divide the holdout into validation (20%) and test (10%)
val_files, test_files = train_test_split(
holdout_files, test_size=1/3, random_state=42
)Setting random_state makes the split reproducible, which matters when you want to compare models trained on identical data. For object detection, remember you are splitting image-annotation pairs, and every class should appear in all three sets.
In Roboflow, the split happens automatically when you generate a dataset version: images are assigned to train, validation, and test at upload, duplicates are removed so near-identical images cannot land in different splits, and you can adjust the ratios per project. The split is then frozen into the version, so every training run and comparison uses exactly the same partition.
Test Set vs. Training Set vs. Validation Set
The three sets differ in what they are for, when the model sees them, and how often you are allowed to look at their metrics.
| Training set | Validation set | Test set | |
|---|---|---|---|
| Purpose | The model learns from it | Tuning, early stopping, model selection | Final, unbiased evaluation |
| When the model sees it | Every epoch | Evaluated each epoch, never trained on | Once, at the end |
| Augmentations | Yes | No | No |
| Typical share | 70% | 20% | 10% |
The subtle one is validation versus test. The model never trains on either, but you make decisions based on validation metrics, so over many experiments you gradually overfit your choices to the validation set. The test set exists to catch that: because nothing about the model was chosen using it, its metrics are the closest preview of production performance you can get before deploying.
As always, happy training.
Further Reading:
- What is Data Augmentation? The Ultimate Guide
- What is Mean Average Precision (mAP)?
- How to Label Images for Computer Vision
What size should the train, validation, and test sets be?
A 70/20/10 split is a solid default for computer vision datasets. With very large datasets (tens of thousands of images), 80/10/10 works because 10% is still plenty of images for reliable evaluation. Avoid shrinking validation and test below a few hundred images each; metrics computed on a tiny sample are noisy.
What is the difference between a validation set and a test set?
The model trains on neither, but the validation set guides your decisions during development (hyperparameters, early stopping, model selection), while the test set is touched only once at the end. Because your choices were influenced by validation metrics, only the test set gives an unbiased estimate of production performance.
Why not just use a train and test split?
Without a validation set, you end up tuning against the test set, and by the time you deploy, its metrics are no longer unbiased since your decisions overfit to it. The two-way split works only when you make no iterative decisions, which almost never describes a real project.
Should augmentations be applied to the validation or test set?
No. Augmentations belong in the training set only, to expand what the model learns from. Validation and test sets should contain unmodified ground truth images, because their job is to represent the real images the model will see in production. Preprocessing (resizing, auto-orient) applies to all three splits.
What About Cross-Validation?
K-fold cross-validation is the main alternative to a fixed split. Instead of one validation set, the data is divided into k equal folds; the model trains k times, each time holding out a different fold for validation, and the metrics are averaged. Every image gets used for both training and validation, which produces a more reliable performance estimate from a small dataset.
The cost is compute: k folds means training the model k times. For classical machine learning that is cheap; for deep learning vision models, where a single training run takes real time and money, it rarely pays. In practice, computer vision teams use a fixed train, validation, test split and spend the saved compute on more training data, and reserve cross-validation for very small datasets where a single 20% validation slice is too few images to trust.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Apr 7, 2026). Train, Validation, Test Split for Machine Learning. Roboflow Blog: https://blog.roboflow.com/train-test-split/