
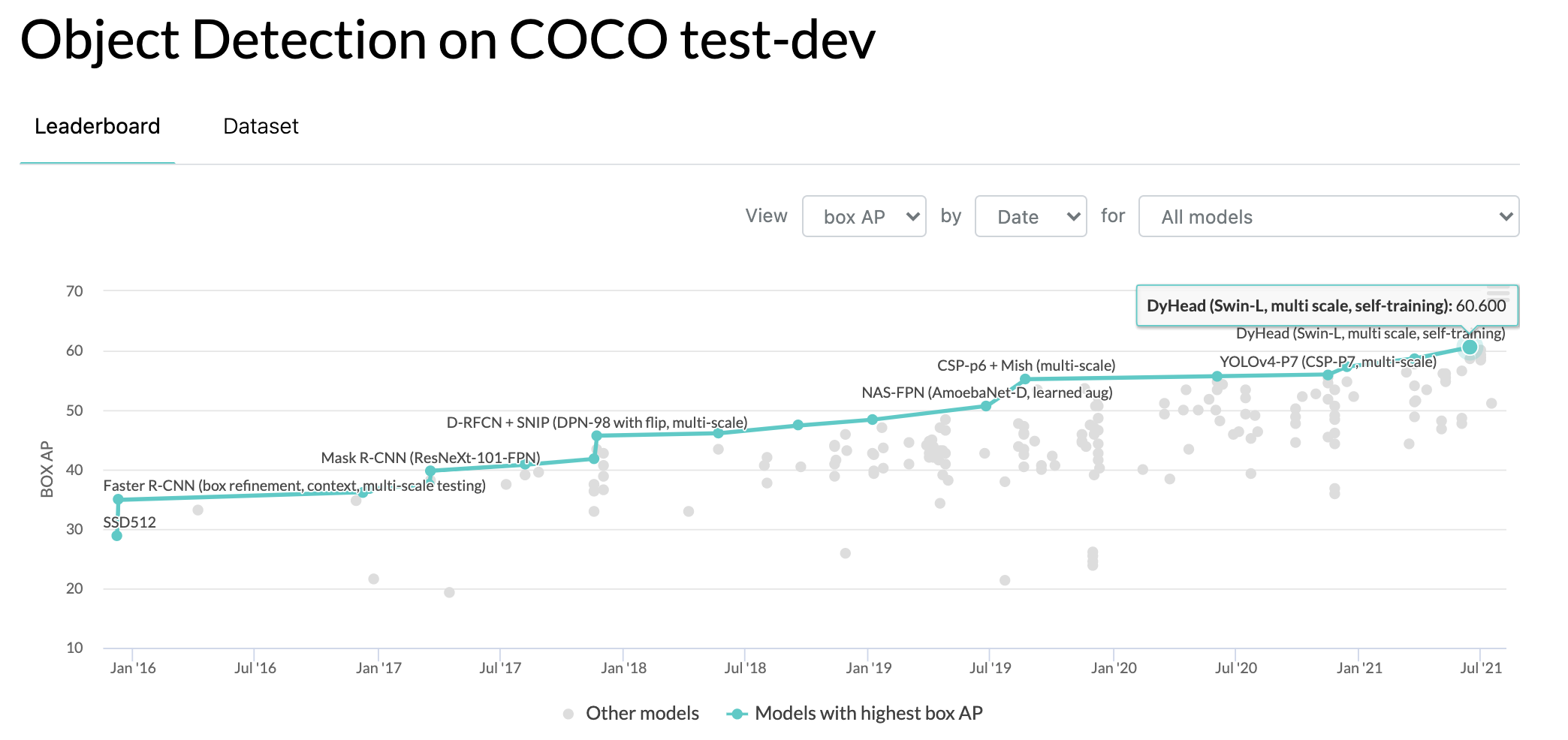
Transformer-based architectures, originally designed for NLP tasks like BERT and GPT, extended their reach into computer vision through image classification with ViT, cross-modal understanding with CLIP, and ultimately object detection with Microsoft's DyHead. DyHead applies a Transformer backbone to achieve state-of-the-art detection accuracy by unifying scale, space, and task attention into a single head, following the same pre-train and fine-tune pattern that proved so effective in language modeling.
It seemed just like a matter of time... and now the Transformer based neural networks have landed - Microsoft's DyHead achieves state of the art object detection using a Transformer backbone.
The Steady March of Transformers
Roots in NLP
In 2017, transformers were originally introduced in NLP research as an improvement on RNN and LSTM approaches in the landmark paper Attention is All you Need. These first Transformers were designed to model against a sequence of text tokens, bits of words.
Big and Bigger Language Models
Transformers made landmark strides in the NLP world by modeling the sequence of language, i.e. which word is likely to appear next in this string of text (GPT, GPT2, GPT3). Or in the case of BERT, if we mask a random word in a the sentence, the model predicts the word that is most likely to occupy that space.
Pre-train and Fine-tune
Transformers proved to be good building blocks for other tasks - that is, you can pre-train a transformer like BERT at web scale and then fine-tune the network to your specific task, like text classification on a small dataset. The big pre-training allows the network to learn all sorts of semantic richness, and the fine-tuning focuses the network's attention to a specific application.
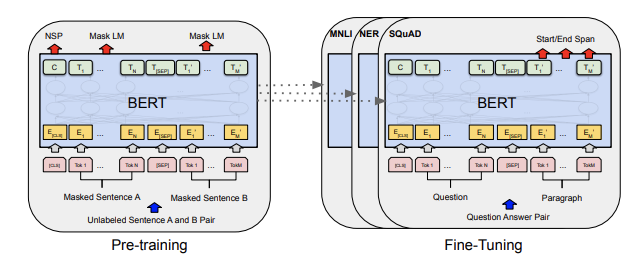
Image Classification
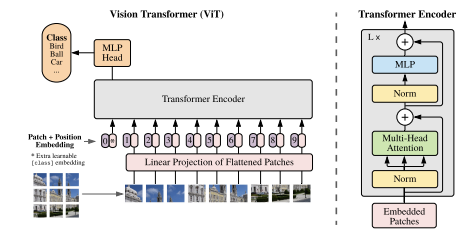
Transformers landed in the computer vision world at the end of 2020 with the introduction of the Vision Transformer for image classification.
The ViT authors sliced an image into 16x16 patches and fed the image patch sequence through the transformer architecture to create features for image classification.
If you want to try training this model on your own dataset, check out our blog post and colab notebook on how to train ViT for image classification.
Text-Image Similarity
Transformer's next major advance into computer vision came with OpenAI's CLIP model, connecting text and images. The CLIP transformer was trained on 400MM image and caption pairs, predicting which image was most likely to belong to which image. This massive training job crystallized a web-scale semantic understanding of images that was previously unavailable in any other dataset.
If you want to try CLIP on your own dataset for zero shot image classification, or for feature extraction, check out our notebook on CLIP for zero shot classification.
And Now... Object Detection!
And now the Transformer backbone has been leveraged to set the state of the art in object detection.
We called it here!
Research Contributions in DyHead
The research contributions in DyHead are predominately focused around how to direct attention at image features when making object detection predictions.
In fact, most of the paper focuses applying the dynamic attention detection head on CNN based backbones in computer vision like Resnet. At the end of the paper, the authors are able to slot the Transformer backbone in for their feature extractor, and as we often see with Transformers, performance improves markedly.
For more on the research findings in DyHead, check out the paper!
The code will eventually be open sourced here.
Conclusion
Transformers are continually eating the artificial intelligence world.
Transformers have officially landed in the computer vision world and are setting the standard for the core computer vision tasks of classification and object detection.
Instance segmentation next? I'm calling Feb 2022.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Aug 6, 2021). Transformers Take Over Object Detection. Roboflow Blog: https://blog.roboflow.com/transformers-take-over-object-detection/