
At the heart of the field of computer vision is a fundamental concept: enabling computers to understand visual inputs. This idea can be broken down into many tasks: identifying objects in images, clustering images to find outliers, creating systems by which to search large catalogs of visual data, and more. Image embeddings are at the heart of many vision tasks, from clustering to image comparison to enabling visual inputs with Large Multimodal Models (LMMs).
In this guide, we are going to talk about what image embeddings are, how they can be used, and talk about CLIP, a popular computer vision model that you can use to generate image embeddings for use in building a range of applications.
Without further ado, let's get started!
Embeddings 101: What is an Image Embedding?
An image embedding is a numeric representation of an image that encodes the semantics of contents in the image. Embeddings are calculated by computer vision models which are usually trained with large datasets of pairs of text and image. The goal of such a model is to build an "understanding" of the relationship between images and text.
These models enable you to create embeddings for images and text, which can then be compared for search, clustering, and more. See our post on clustering with image embeddings to see a tutorial on the topic.
Embeddings are different from images in their raw form. An image file contains RGB data that says exactly what color each pixel is. Embeddings encode information that represents the contents of an image. These embeddings are unintelligible in their raw form, just as images are when read as a list of numbers. It is when you use embeddings that they start to make sense.
Consider the following image:

This image contains a bowl of fruit. An image embedding will encode this information. We could then compare the image embedding to a text embedding like "fruit" to see how similar the concept of "fruit" is to the contents of the image. We could take two prompts, such as "fruit" and "vegetable", and see how similar each one is. The most similar prompt is considered the most representative of the image.
Let's discuss CLIP, a popular image embedding model created by OpenAI, then walk through a few examples of embeddings to see what you can do with embeddings.
What is CLIP?
CLIP (Contrastive Language-Image Pretraining), developed by OpenAI, is a multimodal embedding model developed by OpenAI and released in 2019. CLIP was trained using over 400 million pairs of images and text. You can calculate both image and text embeddings with CLIP. You can compare image embeddings and text embeddings.
CLIP is a zero-shot model, which means the model does not require any fine-tuning to calculate an embedding. For classification tasks, you need to calculate a text embedding for each potential category, an image embedding for the image that you want to classify, then compare each text embedding to the image embedding using a distance metric like cosine similarity. The text embedding with the highest similarity is the label most related to the image.
Classify Images with Embeddings
Image classification is a task where you aim to assign one or multiple labels to an image from a limited number of classes. For example, consider the following image of a parking lot:

We could compare this image with the words "parking lot" and "park" to see how similar each are. Let's pass the image through CLIP, a popular embedding model and compare the similarity of the image to each prompt. CLIP is a zero-shot classification model powered by embeddings. This means you can classify images without training a fine-tuned model using embeddings.
Below are the confidence results from an embedding comparison. These results show how confident CLIP is that a given text label matches the contents of an image.
- Parking lot: 0.99869776
- Park: 0.00130221
Since the class parking lot has the highest "confidence", we can assume the image is closer to a parking lot rather than a park. Confidence in the example above is measured by the number closest to 1. You can multiply each value by 100 to retrieve a percentage. We used the demo code in the OpenAI CLIP GitHub repository to run the calculation.
Classify Video Scenes with Embeddings
A video contains a series of frames. You can think of each frame as its own unique image that you can classify. You can run frames in a video through CLIP for zero-shot video classification. You can find how similar each frame, or every n-th frame is, in an image, to a list of text prompts.
The following video shows CLIP running to classify how close a video frame is to the text prompt "coffee cup":
You could use CLIP to identify when an object appears in a video. For instance, you could add a tag to say the video contains a person if CLIP becomes confident that a video frame contains a person. Or you could keep track of how many frames contain cats so you can track where the cat scenes are in a video. See our end-to-end tutorial on analyzing videos using CLIP if you’d like to try on your own data.
Video classification with CLIP has many applications, including identifying when a particular concept is present in a video and if a video is not safe for work (evidenced by the presence of violent or explicit content).
Cluster Images with Embeddings
Embeddings can be used to cluster images. You can cluster images into a defined set of groups (i.e. three groups), or you can cluster embeddings without a set number of clusters. In the former case, you can identify patterns between images in a limited set of clusters; in the latter, you can calculate the distance between images in a dataset. Clustering is often used for outlier detection, where you aim to find images that are sufficiently dissimilar.
k-means clustering is commonly used to cluster embeddings into a set number of categories. There are many algorithms that let you cluster images into an undefined number of clusters according to your embeddings. DBSCAN is one such example. We have written a guide that walks through how to cluster image embeddings.
The following image shows CLIP used to cluster an image dataset, visualized using Bokeh:
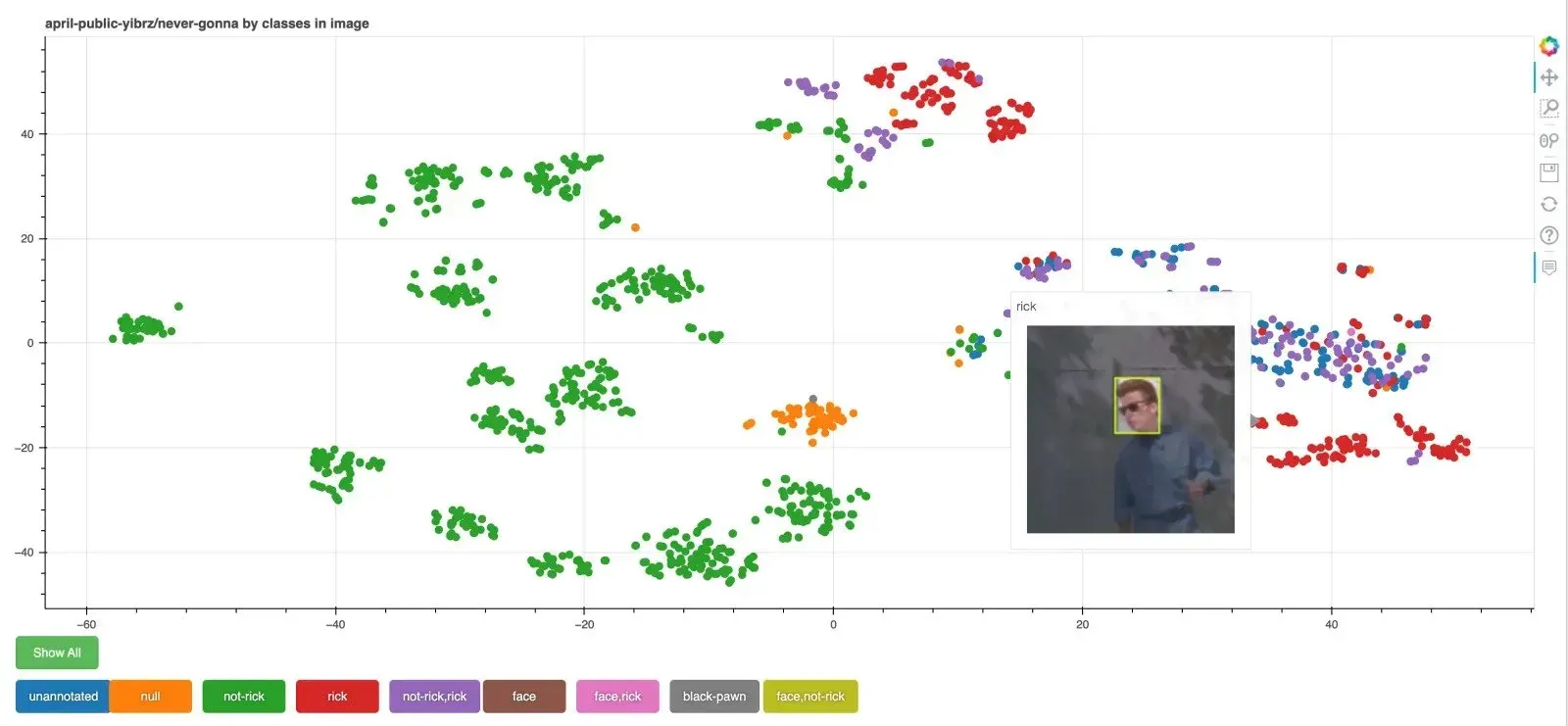
Image Search with Embeddings
Above, we introduced two concepts:
1. The text embedding.
2. The image embedding.
These values are both calculated by an embedding model. You can compare text and image embeddings to see how similar text is to an image. You can save embeddings in a special database called a vector database (used to store embedding) to run efficient searches between image and text embeddings. This efficient searching enables you to build a "semantic" image search engine.
Semantic image search engines are search engines that you can query with natural language concepts. For instance, you can type in "cats" to find all cats in a dataset, or "hard hat" to find images that are related to a hard hat in a dataset. Building such a search engine used to be prohibitively expensive and a technological challenge. With embeddings and vector databases, building an image search engine that runs fast is possible.
The Roboflow platform uses semantic search to make it easy to find images in a dataset. The following video shows an example of providing a natural language query to retrieve images in a dataset:
Try querying the COCO dataset on Roboflow Universe to experience semantic search powered by image embeddings.
Conclusion
Embeddings are numeric, semantic representations of the contents of an image. Image embeddings have a wide range of uses in modern vision tasks. You can use embeddings to classify images, classify video frames, cluster images to find outliers, search through a folder of images, and more. Above, we have discussed each of these use cases in detail.
To learn more about calculating embeddings, check out our guide to using Roboflow Inference with CLIP for classification. Roboflow Inference is an open source server for deploying vision models that powers millions of API calls for large enterprises around the world. You can also use Roboflow’s hosted inference solution, powered by the same technology, to calculate embeddings for use in vision applications.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 16, 2023). What is an Image Embedding?. Roboflow Blog: https://blog.roboflow.com/what-is-an-image-embedding/