
The field of object recognition, also known as object detection, answers the question of "what is in this image or video, and where is each object?" Using an object recognition model, you can identify both the presence and location of different objects in an image.
In this guide, we are going to talk about what object recognition is, how it works, and how you can use object recognition to solve problems. Without further ado, let's get started!
What is Object Recognition?
Object recognition is a computer vision task where you aim to identify different objects in images. Object recognition might involve identifying all objects in an image for use in captioning, or identifying specific objects for data analysis. Systems called computer vision models are used to detect objects; each model can be trained to identify different objects.
There are two main types of object recognition models: zero-shot models and fine-tuned models.
Zero-shot models are large, pre-trained models that can identify a set of objects in an image without additional training. These models may perform well at common classes, such as people, but struggle with more obscure classes such as product defects.
Fine-tuned or custom models, on the other hand, are smaller and are trained to identify a select set of specific classes. This is in contrast to the broad set of classes zero-shot models aim to identify. For instance, a fine-tuned model may be trained to identify scratches on a particular car part, or distinguish between different package types on a conveyor belt.
Zero-shot models usually require substantial compute power compared with fine-tuned models, since zero-shot models are trained on massive amounts of data and aim to identify a large number of classes.
Object Recognition Use Cases
Finding specific objects in images is useful for a myriad of applications. For example, you could use object recognition to:
- Count the number of shipping containers in a yard
- Identify when someone enters a zone in a construction site
- Identify and flag defects in products
- Count the number of products in an stock room
- And more
Using object recognition, you can automatically trigger business logic when a condition occurs. This might mean doing something when:
- An object is identified (i.e. a defect)
- An object is not identified (i.e. there are no cans present on a manufacturing line when there should be)
- There are too many objects in an image (i.e. there is a blockage on a manufacturing line)
- There are the right amount of objects in an image (i.e. there are four screws in a piece of metal)
- Among many other use cases.
Let's talk through an example of object recognition. Consider the following image:

In this image, different objects have been identified using a fine-tuned logistics computer vision model. A "fine-tuned model" is a system that has been trained to identify different objects. In the example above, we used a logistics model. This model has been trained to recognize 20 different objects, from helmets to shipping containers to people.
Object recognition models return:
- The position of the object.
- The class that has been identified.
- How confident the model is that a prediction is correct.
Such a model could be used for logistics and safety projects, such as counting the number of shipping containers in a yard or ensuring that all workers are wearing hard hats.
Object Recognition Models and Architectures
Model architectures describe the structure of a model. A model architecture is used to train a vision model which can identify different objects. RF-DETR is one of the most capable real-time object recognition architectures available today, known for its superior accuracy compared to alternatives.
RF-DETR, developed by Roboflow, is a transformer-based detection model used by companies around the world to identify objects. RF-DETR achieves state-of-the-art real-time performance by combining a powerful backbone with a Detection Transformer (DETR) decoder. You can learn more about RF-DETR and how it works in our RF-DETR guide.
There are other model architectures, too. Transformers are behind many well-known vision models such as OWLv2, used for object detection, and CLIP, which is used for image classification. In addition, Convolutional Neural Networks (CNNs) have been used in a range of object detection architectures. For example, R-CNN and Faster R-CNN are used for object recognition.
How to Recognize Objects
To recognize objects with computer vision, you can:
- Use a fine-tuned model relevant to your use case that someone else has trained, or;
- Use a zero-shot model;
- Train your own model.
Using a fine-tuned model that someone else has trained is a great place to start, allowing you to explore computer vision without training your own vision model. Roboflow Universe features more than 50,000 pre-trained vision models that you can use to identify a range of objects.
Here are a collection of a few different recognition models with which you can explore:
- Detect solar panels
- Rock paper scissors detection
- Identify empty spaces in retail coolers
- Identify players on a football field
- Distinguish cat species
You can use all of the above models in your browser using the interactive Roboflow web interface. You can upload an image to test, use your webcam, or paste an image or video URL. You can also run models on your own hardware, allowing you to deploy models to the edge for use in building a vision-enabled application.
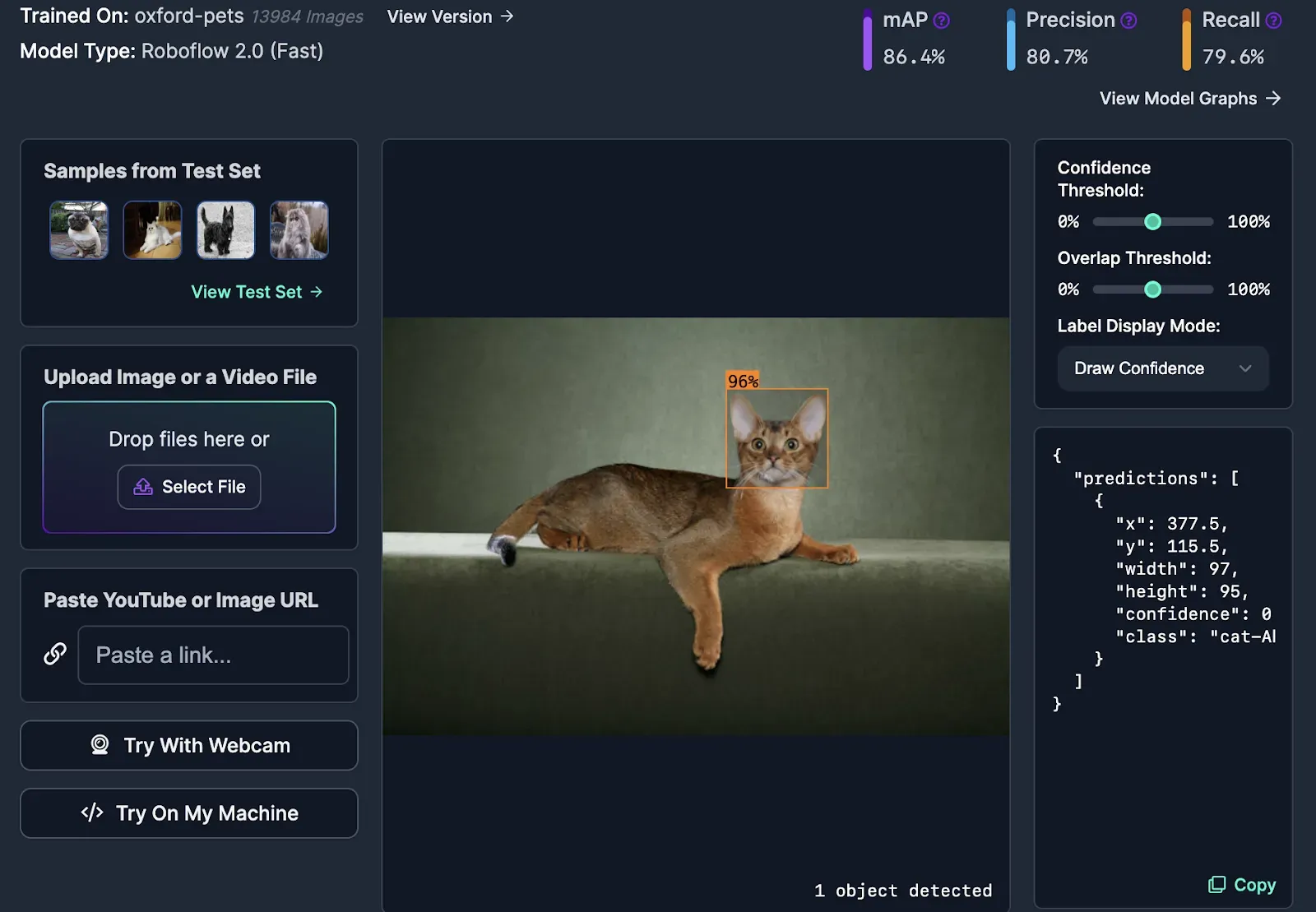
You can also train your own detection model. This is ideal if you cannot find an existing model to identify the objects you want to find, or if you are identifying uncommon objects (i.e. specific products, defects).
To create an object recognition model, you need to:
- Gather data representative of your use case.
- Annotate objects of interest in each image by drawing boxes closely around each object of interest.
- Review annotations to make sure they are accurate.
- Prepare a dataset that splits images into a training dataset, a test set, and a validation set. The training dataset is used for training, the test set is used for testing, and the validation set is used for validating model performance.
- Train a vision model using an architecture like RF-DETR.
- Test the model on images from your test dataset, or new images.
The Roboflow platform offers an end-to-end solution you can use to train vision models. With Roboflow, you can go from a folder of unlabeled images to a fine-tuned model in an afternoon. Get started with Roboflow.
Conclusion
Object recognition, also referred to as object detection, involves identifying specific objects in an image. The two most common types of object recognition models are zero-shot and fine-tuned.
Zero-shot models are models trained on large datasets that can identify a wide range of common classes. Fine-tuned models are smaller models that are trained to identify a limited set of classes.
You can use Roboflow to train a computer vision model. Roboflow provides an intuitive web interface for all steps of model development, from labeling images to training and deploying a model.
Roboflow also offers an API that you can use to deploy a model. This API powers millions of model inferences for companies around the world. You can also deploy your model to a range of edge devices such as an NVIDIA Jetson or Raspberry Pi. Learn more about Roboflow's deployment offerings.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 16, 2023). What is Object Recognition?. Roboflow Blog: https://blog.roboflow.com/what-is-object-recognition/