
Released on November 19th, 2025, Segment Anything 3 (SAM 3) is a zero-shot image segmentation model that “detects, segments, and tracks objects in images and videos based on concept prompts.” This model was developed by Meta as the third model in the Segment Anything series.
Unlike its previous SAM models (Segment Anything and Segment Anything 2), you can provide SAM 3 with the prompt “shipping container” and it will generate precise segmentation masks for all shipping containers in an image. SAM 3 generates segmentation masks that correspond to the location of the objects found with a text prompt.
In this guide, we are going to talk about what SAM 3 is, what you can do with SAM 3, and how you can use the model today.
Just looking for links? Explore the most important SAM 3 links here:
- Free SAM 3 demo
- Fine-tune SAM 3
- SAM 3 Github
- SAM 3 SaCo-Gold dataset
- SAM 3 SaCo-vEval dataset
- SAM 3 SaCo-Silver dataset
- SAM 3 paper
- Explore SAM 3 in Colab
Eager to try SAM 3? Drag and drop an image into our interactive playground below with your own text prompt:
Or use Roboflow Playground to experiment with SAM 3 for free. Without further ado, let’s get started!
What Is Segment Anything 3?
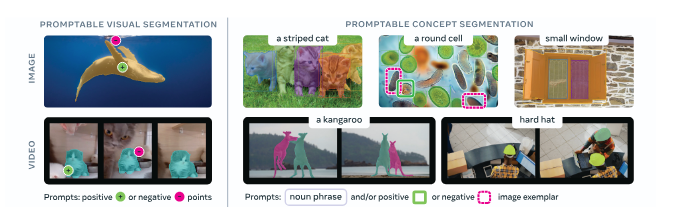
SAM 3 expands the Segment Anything series beyond visual prompts to a new task: Promptable Concept Segmentation (PCS), the task of identifying every instance of a concept in an image or video from a short noun phrase (e.g., “yellow school bus”) or image exemplar.
Unlike SAM 1 and 2, which predicted a single object per prompt, SAM 3 performs open-vocabulary instance detection, returning unique masks and IDs for all matching objects simultaneously. SAM 3 transforms SAM from a geometric segmentation tool into a concept-level vision foundation model.
For more, explore this recorded interview with two researchers from the Meta team that built SAM 3 which includes insights on how the model works, and how you can prompt SAM 3:
How Does Meta Segment Anything 3 Work?
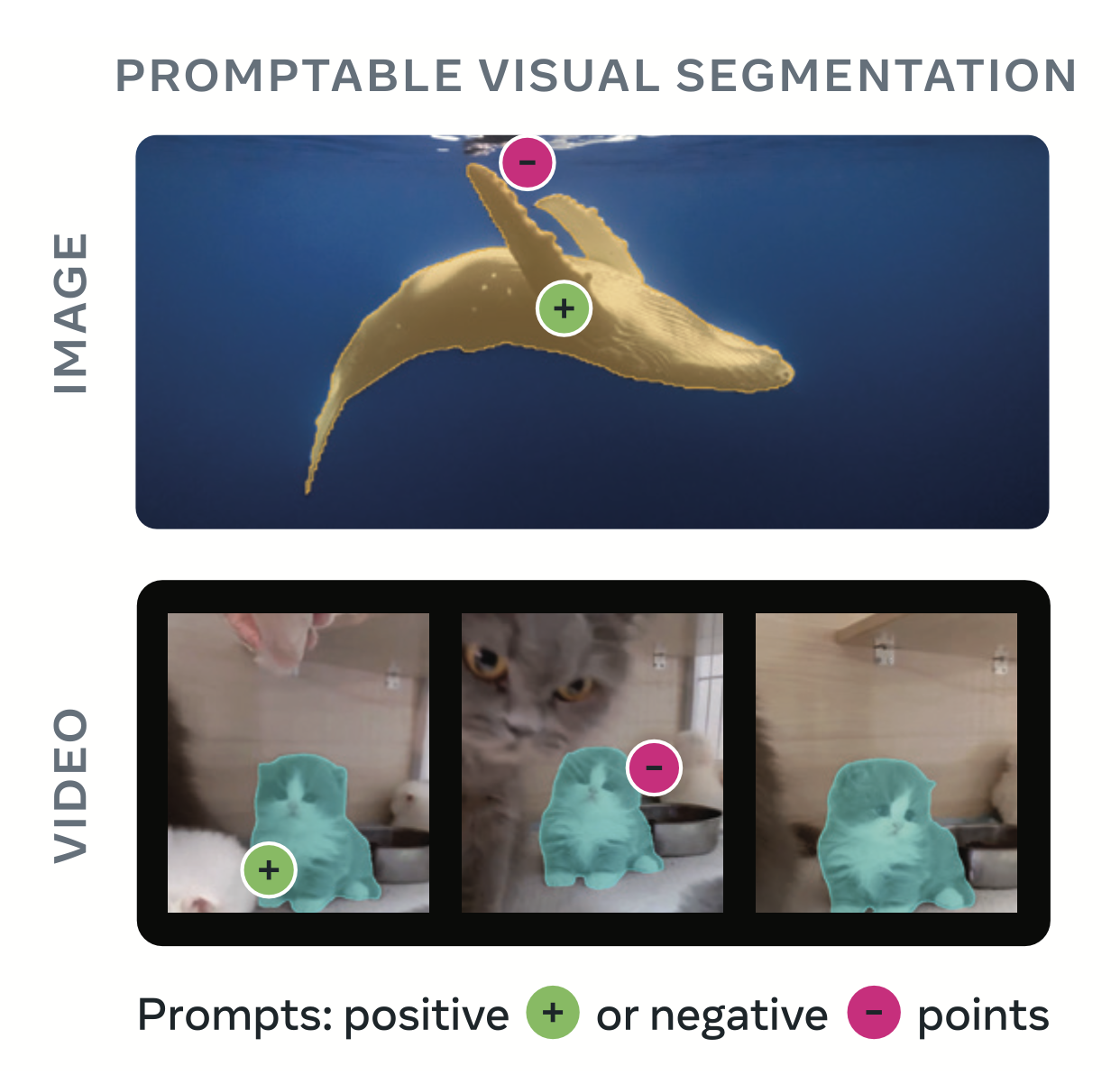
SAM 3 draws precise segmentation masks around the contours of objects that have been identified by a prompt. For example, you can ask SAM 3 to identify a “striped cat” and it will find the striped cats, or you could click on a cat in an image and calculate a segmentation mask that corresponds with the specific cat on which you have clicked:
SAM 3 works across images and videos. If you provide a video as an input to SAM 3, the model will track all identified or selected instances of objects through frames in the video. If you provide an image as an input, SAM 3 will run on the input image.
SAM 3 runs at ~30 ms per image on an H200 GPU, handling 100+ objects, but at ~840 M parameters (≈3.4 GB) it remains a server-scale model. For object detection on the edge, you can use SAM-3 to label data and use the labeled data to train a smaller, faster, supervised object detection model. The smaller model will not have text prompting abilities, but would allow you to detect exactly what objects you have trained the model to find in real time.
You can run SAM 3 without fine-tuning. You can also fine-tune SAM 3 to improve its performance on domain-specific tasks, which we discuss later in this article.
SAM 3 License
SAM 3 is licensed under a custom license developed by Meta. The model is available for public use subject to the terms and conditions provided on the model weights download page.
SAM 3 Task Types
SAM 3 unifies several segmentation paradigms: single-image, video, interactive refinement, and concept-driven detection, under a single model backbone. It can operate in Promptable Concept Segmentation (PCS) mode (text or exemplars), Promptable Visual Segmentation (PVS) mode (points, boxes, masks), or interactive hybrid mode that blends both.
This unified interface means a single SAM 3 checkpoint can handle everything from dataset labeling to live tracking and multimodal reasoning.
SAM 3 Point and Click
As before in SAM 1 and SAM 2, you can prompt SAM 3 with visual positive and negative clicks.
SAM 3 keeps the same interactive refinement loop - positive clicks to add, negative to remove regions - but these can now be applied to concept-wide detections or to individual masklets within videos.
Internally, each click is encoded as a positional token and fused into the prompt embedding space before being re-decoded into refined masks. This design allows incremental correction without restarting inference, enabling fluid dataset annotation and fine-tuning workflows.
SAM 3 Video Processing
SAM 3 deploys the same video memory layer used in SAM 2 where predictions from prior frames are used to inform predictions in new frames.
SAM 3’s tracker inherits the transformer-based memory bank from SAM 2 but introduces tighter coupling between the detector and tracker through the shared Perception Encoder. On each frame, the detector finds new concept instances, while the tracker propagates “masklets” — temporal object segments — from previous frames via self- and cross-attention.
A matching and update stage merges propagated and newly detected masks, ensuring consistency under occlusion or re-appearance.
The tracker also employs temporal disambiguation strategies such as detection-score decay and re-prompting, preventing drift and maintaining identity integrity across clips.
Together, this streaming memory design enables real-time concept tracking across complex video domains.
Meta SAM 3 Prompting Examples
Below, we show a few of the images and text prompts that we have run through SAM 3 to demonstrate the powerful zero-shot segmentation capabilities of the model.
Solar Panels
We gave SAM-3 the prompt “solar panels” and an image that contained several solar panels. The model was able to both successfully identify all solar panels as well as draw precise masks around each, while being careful not to highlight occluded areas on the solar panel:

Vehicles on a Street
We provided SAM 3 with the prompt “vehicle” and a photo of a street with several cars and motorbikes. SAM 3 was able to successfully identify all vehicles:

Boxes in a Warehouse
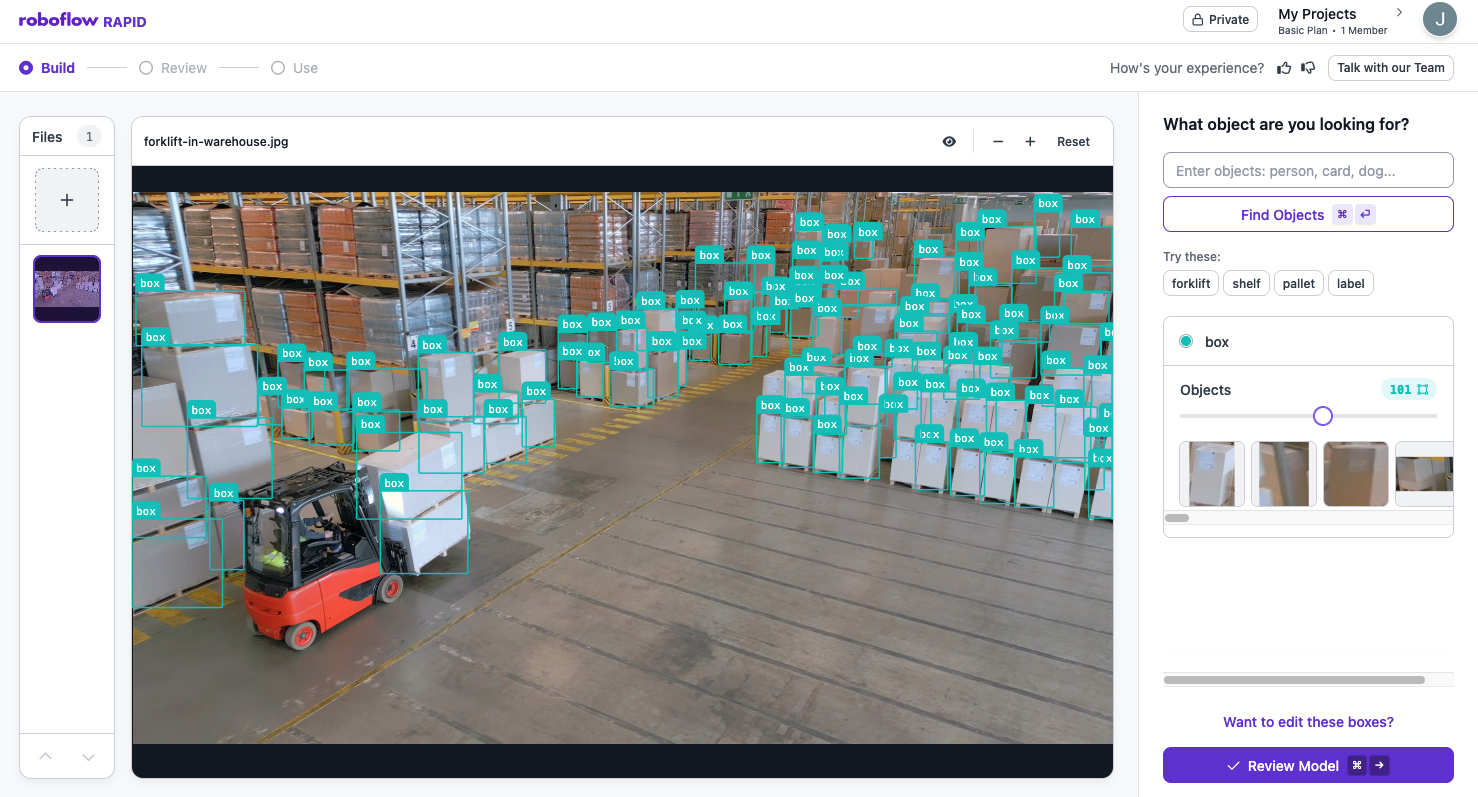
We provided SAM 3 with a photo of dozens of boxes in a warehouse and gave the model the prompt “box”. SAM 3 correctly identified the location of almost every box in the foreground of the image, without fine-tuning:

This demonstrates SAM 3’s proficiency at identifying a large number of objects in a single image.
Aerial Imagery
We asked SAM 3 to identify all trailers and stall numbers in an aerial image of an intermodal yard. SAM 3 was able to successfully identify all instances of the objects we prompted it to identify:

SAM 3 Demo and SAM 3 Playground
If you want to experiment with Meta SAM 3 on your own input data and prompts, you can use Roboflow Playground, a free, web-based playground for experimenting with models. Roboflow Playground lets you upload an image and see the segmentation masks returned by the model.
We also have a widget below that you can drag-and-drop an image into to try SAM-3:
Meta has prepared a web-based tool that is available on the Segment Anything 3 website.
How to Use SAM 3
There are several ways that you can use SAM 3.
Use a SAM 3 API
With Roboflow, you can deploy your own SAM 3 API. You can use this API to make requests to SAM 3 without having to worry about managing your own infrastructure.
To get started, you can click “Fork Workflow” on the widget below:
This will create an endpoint that can run SAM 3. Here is an example of what the code snippet will look like:
# 1. Import the library
from inference_sdk import InferenceHTTPClient
# 2. Connect to your workflow
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key="ZBGiII0DVVkK7LWLjlYE"
)
# 3. Run your workflow on an image
result = client.run_workflow(
workspace_name="roboflow-jvuqo",
workflow_id="sam3",
images={
"image": "YOUR_IMAGE.jpg" # Path to your image file
},
parameters={
"prompt": "PARAMETER_VALUE"
},
use_cache=True # Speeds up repeated requests
)
# 4. Get your results
print(result)Fine-Tune SAM 3
If you notice that SAM 3 doesn’t perform well on a task in a specific domain, you may want to experiment with fine-tuning SAM 3. This will help you achieve better performance on tasks for which the model may not have originally been trained.
To fine-tune SAM 3, you will need:
- An annotated image segmentation dataset focused on the task that you want to fine-tune SAM 3 to solve, and;
- A place to train your model.
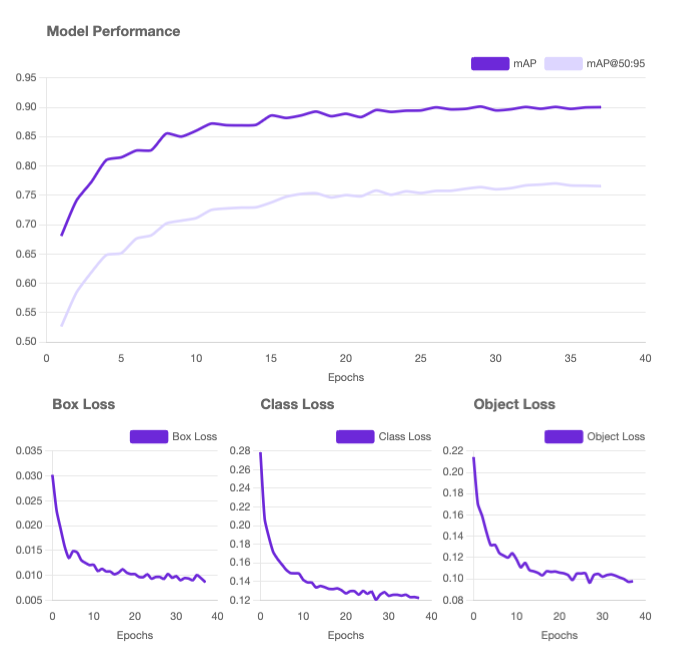
To start fine-tuning the model, you can upload your instance segmentation dataset to Roboflow, in any common format, like COCO JSON, generate a dataset version, then start a SAM 3 fine-tuning job.
As you fine-tune SAM-3 models in Roboflow, you can measure your model performance with each epoch. You can then try your models in a Workflow and deploy them to the cloud or the edge.
Use SAM 3 to Train a Smaller Model
SAM 3 is a computationally expensive model. You need a large GPU to be able to run the model. With that said, you can use the capabilities of SAM 3 to label data for use in training a smaller model that is fine-tuned for your specific task.
All you need are a few images or a short video to get started. You can then use the text prompting capabilities of SAM 3 in the Roboflow interface to label your data. Roboflow uses the fine-tuned SAM 3 model to train an RF-DETR model.
Models can be deployed in the cloud using Roboflow Workflows with serverless API infrastructure, on dedicated cloud infrastructure, or on your own hardware.
SAM 3 Data Engine
In order to train SAM 3 the Meta team took on an enormous data annotation and review process through their SAM 3 data engine.
To power open-vocabulary learning, Meta built a four-phase data engine that combines humans, SAM models, and fine-tuned LLMs in a feedback loop.
Phases 1–3 focused on images, progressively increasing automation, while Phase 4 extended to videos.
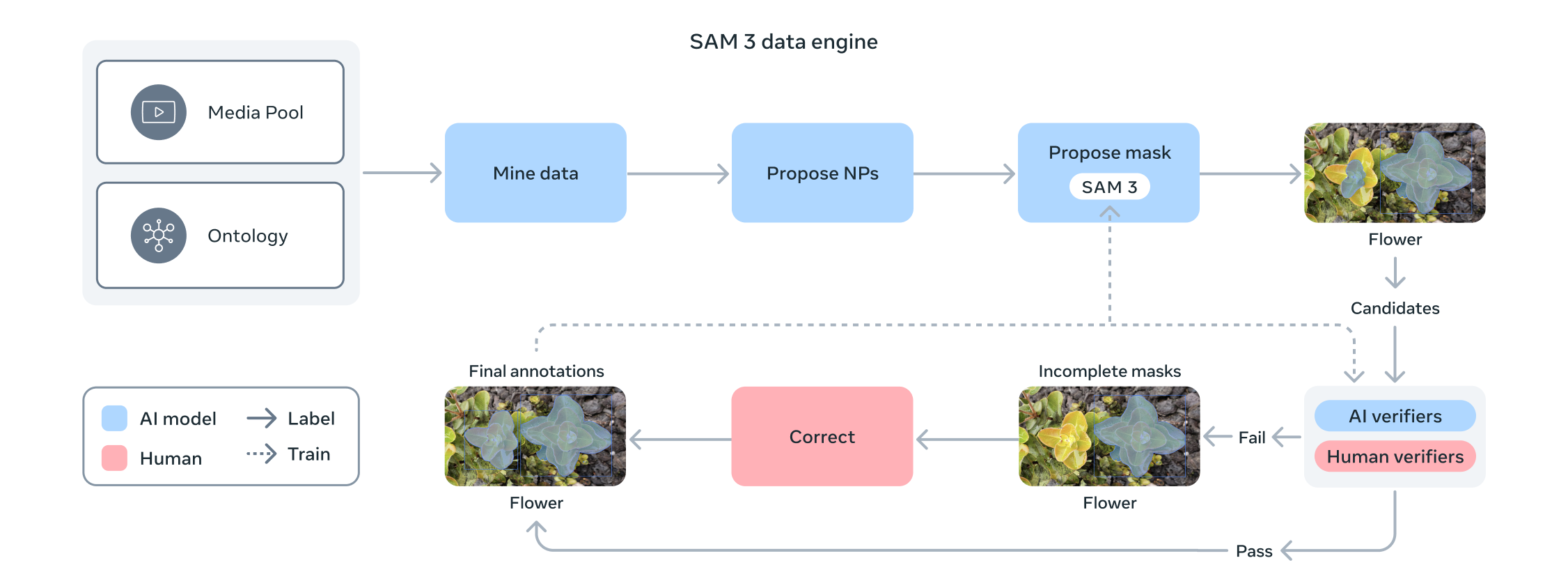
The resulting SA-Co dataset (“Segment Anything with Concepts”) includes ≈ 5.2 M high-quality images and 52.5 K videos with > 4 M unique noun phrases and ≈ 1.4 B masks, making it the largest concept-segmentation corpus to date. Each iteration used AI annotators to propose candidate noun phrases and AI verifiers (fine-tuned Llama 3.2) to assess mask quality and exhaustivity. Human effort was then concentrated on failure cases, a process that doubled throughput compared to human-only pipelines.
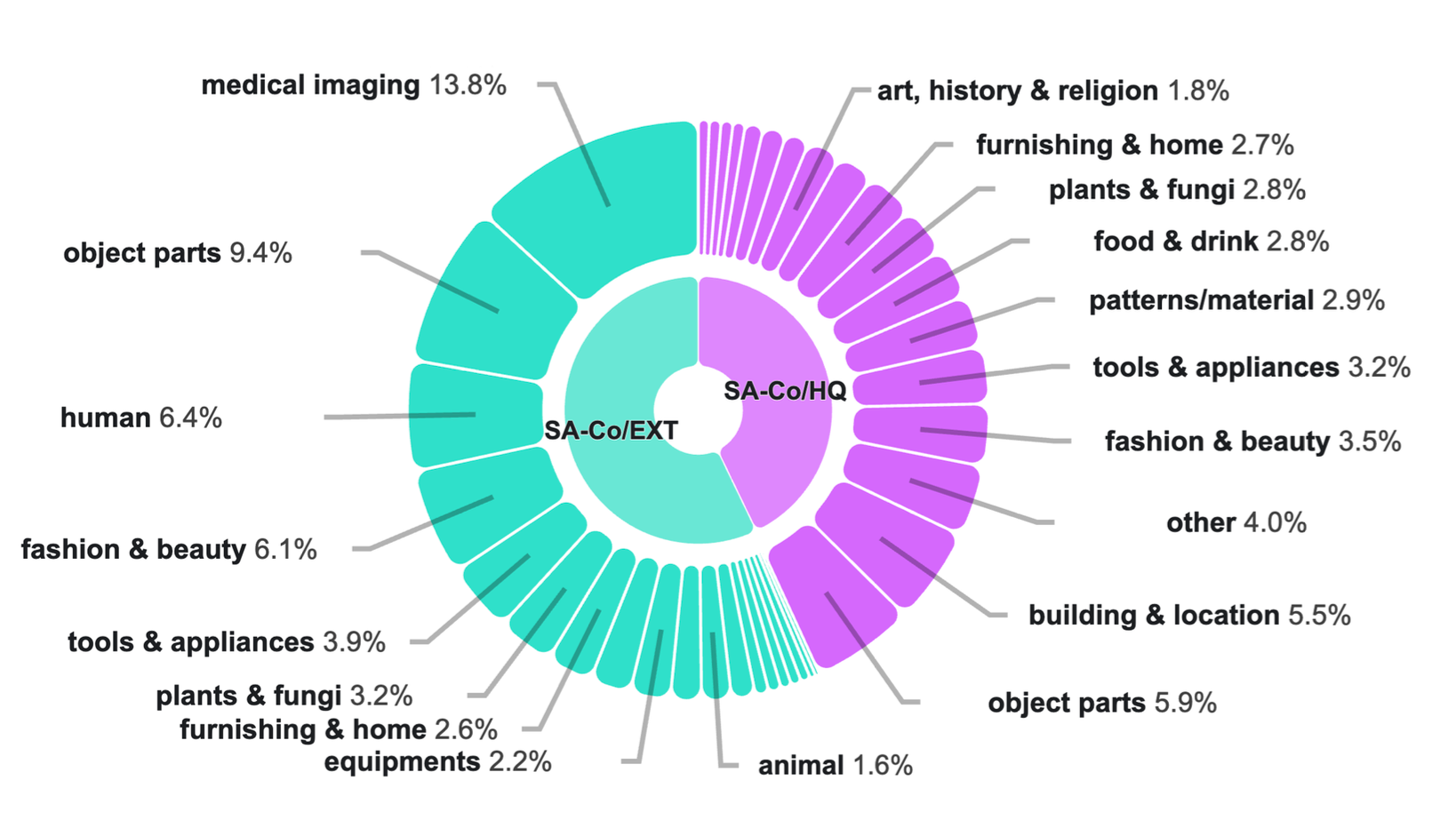
The SA-Co ontology spans 22 million entities across 17 top-level and 72 sub-categories, bringing fine-grained coverage from common objects to long-tail concepts.
| Dataset | Overview | Size |
|---|---|---|
| SA-Co | Entire dataset from 4-phase data engine that combines humans, SAM models, and fine-tuned LLMs in a feedback loop | 5.2 M high-quality images and 52.5 K videos with > 4 M unique noun phrases and ≈ 1.4 B masks |
| SA-Co/Gold | Images paired with text labels (Noun Phrases), each exhaustively annotated with masks | 7 subsets across 2 image sources (MetaCLIP and SA-1B), with all annotations multi-reviewed by 3 human annotators |
| SA-Co/Silver | Images paired with text labels (Noun Phrases), each exhaustively annotated with masks | 10 subsets covering diverse domains including food, art, robotics, and driving, unlike SA-Co/Gold, each datapoint has a single ground-truth, which may introduce variance and underestimate model performance |
| SA-Co/VEVal | Video frames paired with text labels (Noun Phrases), each exhaustively annotated with masks | 3 subsets from YT-Temporal-1B, SmartGlasses, and SA-V |
SAM 3 Architecture Overview
SAM 3 builds on architecture from SAM 1, SAM 2, and Perception Encoder.
- The SAM 3 architecture is a dual encoder-decoder transformer comprising a DETR-style detector and a SAM 2-inspired tracker that share a unified Perception Encoder (PE).
- The PE aligns visual features from the image encoder with text and exemplar embeddings from the prompt encoder, creating a joint embedding space for vision-language fusion.
- To handle open-vocabulary concepts, the detector adds a global presence head that first determines if the target concept exists in the scene before localizing its instances.
- This decoupling of recognition (what) and localization (where) significantly improves accuracy on unseen concepts and hard negatives, which are prevalent in natural imagery.
The result is a zero-shot segment-anything engine capable of detecting all matching objects with minimal user input.
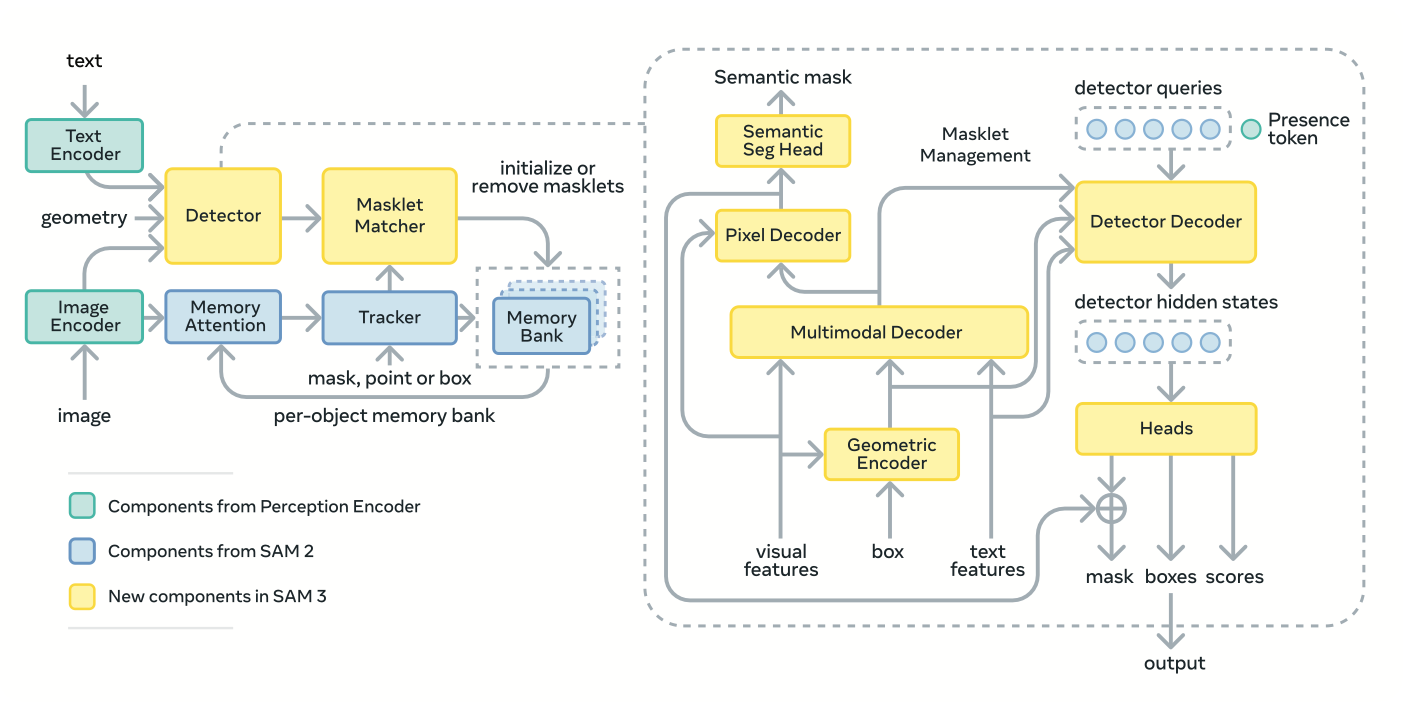
Training occurs in four stages:
- (1) Perception Encoder pre-training
- (2) detector pre-training on synthetic and HQ data
- (3) detector fine-tuning on SA-Co HQ, and
- (4) tracker training with a frozen backbone to stabilize temporal learning.
Promptable Composable Segmentation: A New Vision Task
SAM and SAM 2 were both capable of identifying objects with a specific prompt. SAM 3, however, introduces text prompting, and a new task type to evaluate the efficacy of segmentation models that accept text prompts as inputs: Promptable Concept Segmentation (PCS).
Part of the contributions made in the SAM 3 paper were both the introduction of PCS as a task type as well as a “scalable data engine” that was used to produce a dataset with splits for training and benchmarking. This is discussed in Section 5, Segment Anything with Concepts (SA-Co) Dataset in the SAM 3 paper.
Meta benchmarked SAM 3 across both instance segmentation, box detection, and semantic segmentation, and reported the following results:
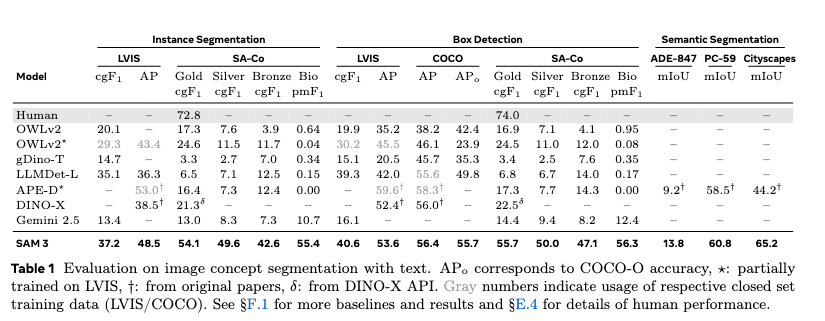
SAM 3 achieves state-of-the-art performance across most of the benchmarks run, including on LVIS and SA-Co for instance segmentation.
Measuring Few-Shot Adaptation
In addition to benchmarking for instance and semantic segmentation and box detection, Meta evaluated the few-shot adaptation capabilities of SAM 3. The Meta research team used the ODinW13 and Roboflow100-VL benchmarks for this purpose.
When reporting on the results on the Roboflow100-VL benchmark, Meta found that “While SAM 3 underperforms the current state-of-the-art Liu et al. (2023) in zero-shot evaluation, it surpasses leading methods Liu et al. (2023); Chen et al. (2024a) in both few-shot and full fine-tuning scenarios.” Their research team concluded this result demonstrated SAM 3’s “strong visual generalization capabilities when provided with task-specific training data.”
Get Started With Segment Anything Model 3
You can use SAM 3 out-of-the-box with text or point prompts. You can also use the model to label data for use in training a smaller, supervised model that specializes in the particular task you are working on. Furthermore, you can fine-tune SAM 3 on a custom dataset, ideal if you want to adapt SAM 3 itself to a particular visual problem you want to solve.
To get started with SAM 3, you can use Roboflow Playground to experiment for free.
You can also begin with SAM 3 production-ready templates designed to segment anything in seconds.
SAM 3 Frequently Asked Questions
Is SAM 3 actually better than SAM 1 or SAM 2?
Compared to SAM 2 and SAM 1, SAM 3 delivers strong rare and unseen object generalization, and high prompt reliability, in addition to stronger performance with thin, small, low contrast, and occluded objects. SAM 3 produces sharper edges, precise contours, and better separation between touching objects.
SAM 3 runs in 30 milliseconds for a single image with more than 100 detected objects on an H200 GPU. SAM 3 uses less VRAM per inference than SAM 2, and fits comfortably on 16 GB GPUs. And performs well across domains from industrial to medical, and aerial.
| Feature | SAM 1 | SAM 2 | SAM 3 |
|---|---|---|---|
| Zero-Shot Segmentation Quality | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
| Small Object Performance | ★☆☆☆☆ | ★★☆☆☆ | ★★★★☆ |
| Boundary Accuracy | ★★☆☆☆ | ★★★☆☆ | ★★★★★ |
| Prompt Types Supported | Points, Boxes | Points, Boxes, Masks | Points, Boxes, Masks, Text, Examples |
| Video Segmentation | – | Limited | Full video support |
| 3D / Volumetric Segmentation | – | Experimental | Supported |
| Inference Speed | Medium | Medium | Faster + more efficient |
| Memory Efficiency | High usage | Moderate usage | Optimized / lower |
| Fine-Tuning Support | None | Limited | Stable + recommended |
| Cross-Domain Robustness | Weak | Moderate | Strong |
| Model Size Options | Multiple sizes | Multiple sizes | Singular, large model |
| License Clarity | Custom | Custom | Custom |
Is SAM 3 Free?
Yes SAM 3 is free. You can try a demo of SAM 3 for free on our web-based playground to test segmentation on your images and videos. View the SAM 3 license here.
Is SAM 3 Open Source?
Yes SAM 3 is open source. Meta shared SAM 3 under the SAM License so you can use it to build your own experiences. Alongside the model, they also released a new evaluation benchmark, model checkpoint, and open-source code for inference and fine-tuning.
Meta SAM 3 Release Date
Meta SAM 3 was released on November 19th, 2025.
SAM 3 Segment Anything with Concepts Github
This repository provides code for running inference and finetuning with the Meta Segment Anything Model 3, links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
What's Meta SAM 3D?
Meta SAM 3D is a new generative model designed to reconstruct full 3D objects including their shape, texture, and spatial layout from just a single 2D image, and includes two specialized models:
- SAM 3D Objects: Designed for robust object and scene reconstruction in everyday environments.
- SAM 3D Body: Which focuses on accurate human body pose and shape estimation even in challenging conditions.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher, Jacob Solawetz. (Nov 19, 2025). SAM 3: Segment Anything with Concepts. Roboflow Blog: https://blog.roboflow.com/what-is-sam3/