
On July 29th, 2024, Meta AI released Segment Anything 2 (SAM 2), a new image and video segmentation foundation model. With SAM 2, you can provide points in an image and generate a segmentation mask for the corresponding point. You can also provide points in a video and generate segmentation masks that are tracked across frames.
SAM 2 follows on from the SAM model released by Meta earlier last year which has been used for tasks such as image segmentation in vision applications and as an image labeling assistant. According to Meta, SAM 2 is 6x more accurate than the original SAM model at image segmentation tasks.
In this guide, we are going to walk through what Segment Anything 2 is, how it works, and how you can use the model for image segmentation tasks.
You might also be interested in using the newer Segment Anything 3 - a zero-shot image segmentation model that detects, segments, and tracks objects in images and videos based on concept prompts.

If you want to explore the detailed information released by Meta, start with these links:
- SAM 2 interactive web demo
- SAM 2 on Github
- SAM 2 paper
- SA-V dataset (interactive dataset explorer tool)
- Condensed SAM 2 overview
Here is an example of SAM 2 running on an image:
Here is an example of SAM 2 running on a video, recorded using the SAM 2 interactive web demo made available by Meta:
We have made an interactive playground that you can use to test SAM 2. In the below widget, upload an image, then run the playground.
The playground will aim to identify bounding boxes for every object in the image using Florence-2, a zero-shot detection model. Then, the playground will calculate segmentation masks for each bounding box using SAM 2.
It may take 15-30 seconds to see the result for your image.
Let’s get started!
What is Segment Anything 2?
Segment Anything 2 (SAM 2) is a real-time image and video segmentation model. SAM 2 works on both images and videos. The previous version of SAM, on the other hand, was built explicitly for use in images. You can use SAM 2 to identify the location of specific objects in images.
There are two ways you can run SAM 2:
- Using the automatic mask generator, that segments all objects in an image or video and generates corresponding masks, or;
- By using a point prompt.
The automatic mask generator is ideal if you want to segment all objects. Using a prompt, on the other hand, allows you to be more specific in your segmentation.
To identify the location of an object, you need to provide a “prompt”. A prompt can be:
- A specific point or series of points that correspond with the object you want to segment;
- A box that surrounds the object you want to segment.
These prompts can be provided to an image or video.

You cannot provide text prompts to SAM 2. This is because the model is not grounded in a text model. You can learn more about how to use SAM 2 in combination with a text model, Florence-2, later in this guide.
If you provide a specific point as a prompt, you can also provide a “negative” prompt that corresponds to a region of an object that you do not want to identify. This allows you to refine your prompts from SAM 2: if the model predicts a mask that is too big, you can remove parts of the mask by specifying a negative prompt.

SAM 2 only runs on CUDA-enabled GPU devices.
Segment Anything 2 Dataset
SAM 2 was trained on the Segment Anything Video dataset (SA-V), which includes 51,000 videos and 643,000 segmentation masks. The SA-V dataset is licensed under a CC 4.0 license. SA-V has “~53x more annotations than the largest existing video segmentation dataset”.
This dataset was labeled using a human-in-the-loop approach. SAM 2 was used to interactively annotate videos by human labelers. This annotated data was then used to improve the underlying SAM 2 model.
In the announcement post for SAM 2, Meta AI noted this approach allowed them to significantly improve the speed of their labeling approach:
Annotation with our tool and SAM 2 in the loop is approximately 8.4 times faster than using SAM per frame and also significantly faster than combining SAM with an off-the-shelf tracker.
Segment Anything 2 Model Versions and Performance
There are four versions of SAM 2 available:
- Tiny (149 MB)
- Small (176 MB)
- Base Plus (b+) (309 MB)
- Large (856 MB)
The larger the model you use, the more accurate the results will be. With that said, larger models will take longer to run. SAM 2 speed and accuracy varies by model size and achieves real-time (30+) FPS for all but the largest model.
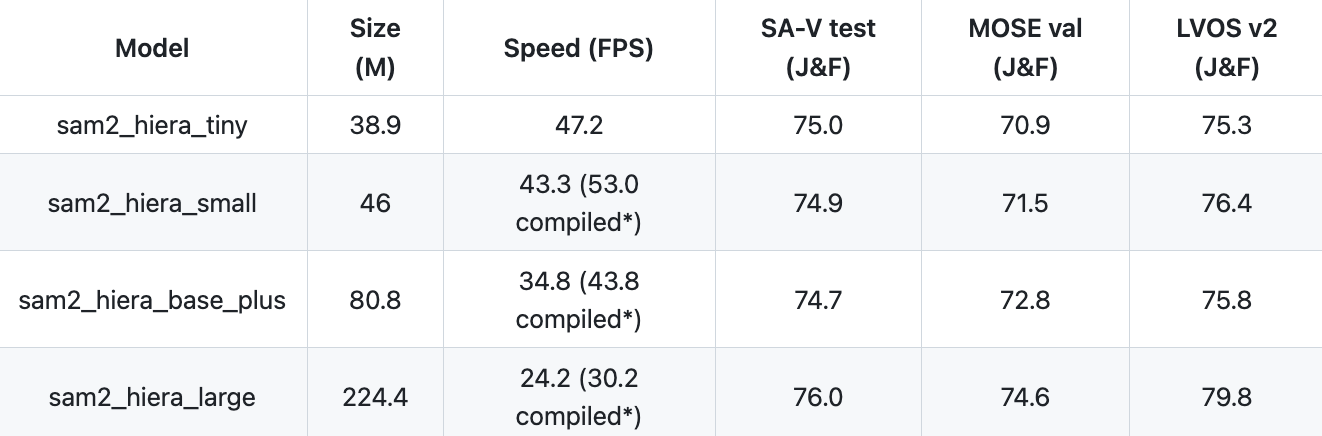
Benchmarking experiments were done on a “single A100 GPU using PyTorch 2.3.1 and CUDA 12.1, under automatic mixed precision with bfloat16”. The FPS measurements for the SA task were conducted using a batch size of 10 images and, for video tasks, a batch size of 1 is used.
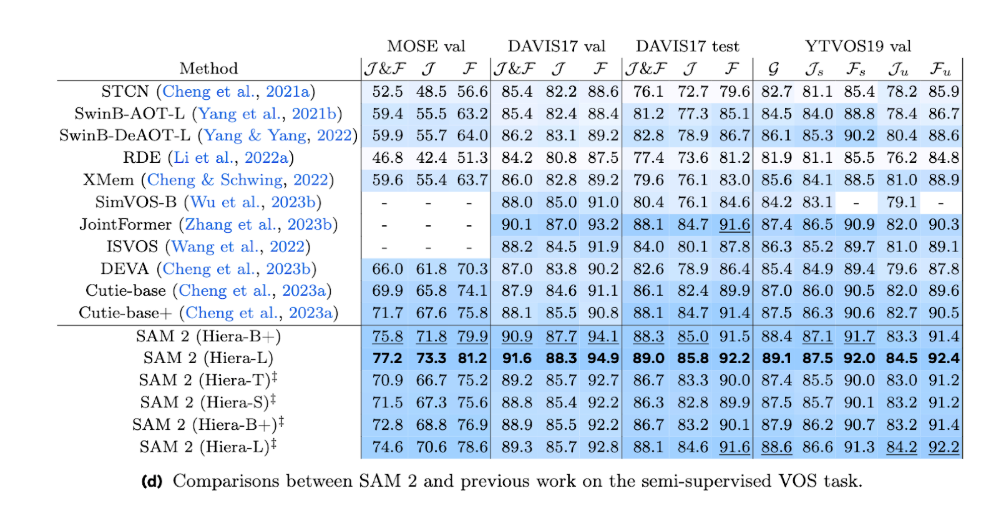
SAM 2 achieves state-of-the-art performance when benchmarked against the MOSE validation, DAVID17 validation, DAVIS17 test, and YTVOS19 validation video segmentation benchmarks, among other benchmarks.
How to Use Segment Anything 2 for Image Segmentation
Segment Anything 2 is distributed as a GitHub repository that you can install from source for use in your vision projects. You can install SAM 2 using the following code:
git clone https://github.com/facebookresearch/segment-anything-2
cd segment-anything-2
pip3 install -e .
The installation process may take several minutes to complete.
Once you have installed the SAM 2 source code, you need to download a model checkpoint. There are four checkpoints available:
- Tiny
- Small
- Base Plus (b+)
- Large
You can download the model checkpoints by running:
cd checkpoints
./download_ckpts.sh
Once you have downloaded the model checkpoints, you are ready to run inference.
Let’s run inference using the automatic mask generator, which will generate masks for all objects in our image.
To get started, create a new Python file and add the following code:
import torch
from sam2.build_sam import build_sam2
from sam2.automatic_mask_generator import SAM2AutomaticMaskGenerator
from PIL import Image
import numpy as np
sam2_checkpoint = "checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
sam2 = build_sam2(model_cfg, sam2_checkpoint, device ='cuda', apply_postprocessing=False)
mask_generator = SAM2AutomaticMaskGenerator(sam2)
image = np.array(Image.open('image.jpeg').convert("RGB"))
masks = mask_generator.generate(image)Above, replace:
- Image.jpeg with the name of the image on which you want to run inference;
- Sam2_hiera_large.pt with the name of the weights you want to use, and;
- Sam2_hiera_l with the name of the checkpoint you want to use.
This code will run inference on an image and generate masks for each object in the image.
We can then visualize the results with supervision, a Python package with utilities for working with computer vision model predictions. To install supervision, run
pip install supervision
You can then load and plot your masks using the following code:
import supervision as sv
mask_annotator = sv.MaskAnnotator()
detections = sv.Detections.from_sam(masks)
detections.class_id = [i for i in range(len(detections))]
annotated_image = mask_annotator.annotate(image, detections)
sv.plot_image(image=annotated_image, size=(8, 8))
Let’s run our code on an example image:

Our image successfully generates segmentation masks for different regions of the image, from the backpack to the hat to the dog.
Use Segment Anything 2 with a Grounding Model
Segment Anything 2 can identify the specific region around objects, but it has no sense of what a particular object is. To identify specific objects in an image and generate segmentation masks for them, we need to combine Segment Anything 2 with a grounding model.
Florence-2, a multimodal vision model with strong zero-shot object detection capabilities, is a good candidate as a grounding model for SAM 2. With Florence-2 and SAM-2, we can provide a text prompt and generate segmentation masks for related regions. For example, we could say “dog” and retrieve a segmentation mask corresponding to the dog in an image.
You can use the Autodistill Grounded SAM 2 package to use SAM with grounding.
To install the package, run:
pip install autodistill-grounded-sam-2
Then, create a new Python file and add the following code:
from autodistill_grounded_sam_2 import GroundedSAM2
from autodistill.detection import CaptionOntology
from autodistill.utils import plot
import cv2
import supervision as sv
# define an ontology to map class names to our Grounded SAM 2 prompt
# the ontology dictionary has the format {caption: class}
# where caption is the prompt sent to the base model, and class is the label that will
# be saved for that caption in the generated annotations
# then, load the model
base_model = GroundedSAM2(
ontology=CaptionOntology(
{
"dog": "dog"
}
)
)
In the code above, we load Grounded SAM 2 and provide the prompt “dog”.
We can then run inference on an image with the following code:
# run inference on a single image
results = base_model.predict("dog.jpeg")
image = cv2.imread("dog.jpeg")
mask_annotator = sv.MaskAnnotator()
annotated_image = mask_annotator.annotate(
image.copy(), detections=results
)
sv.plot_image(image=annotated_image, size=(8, 8))
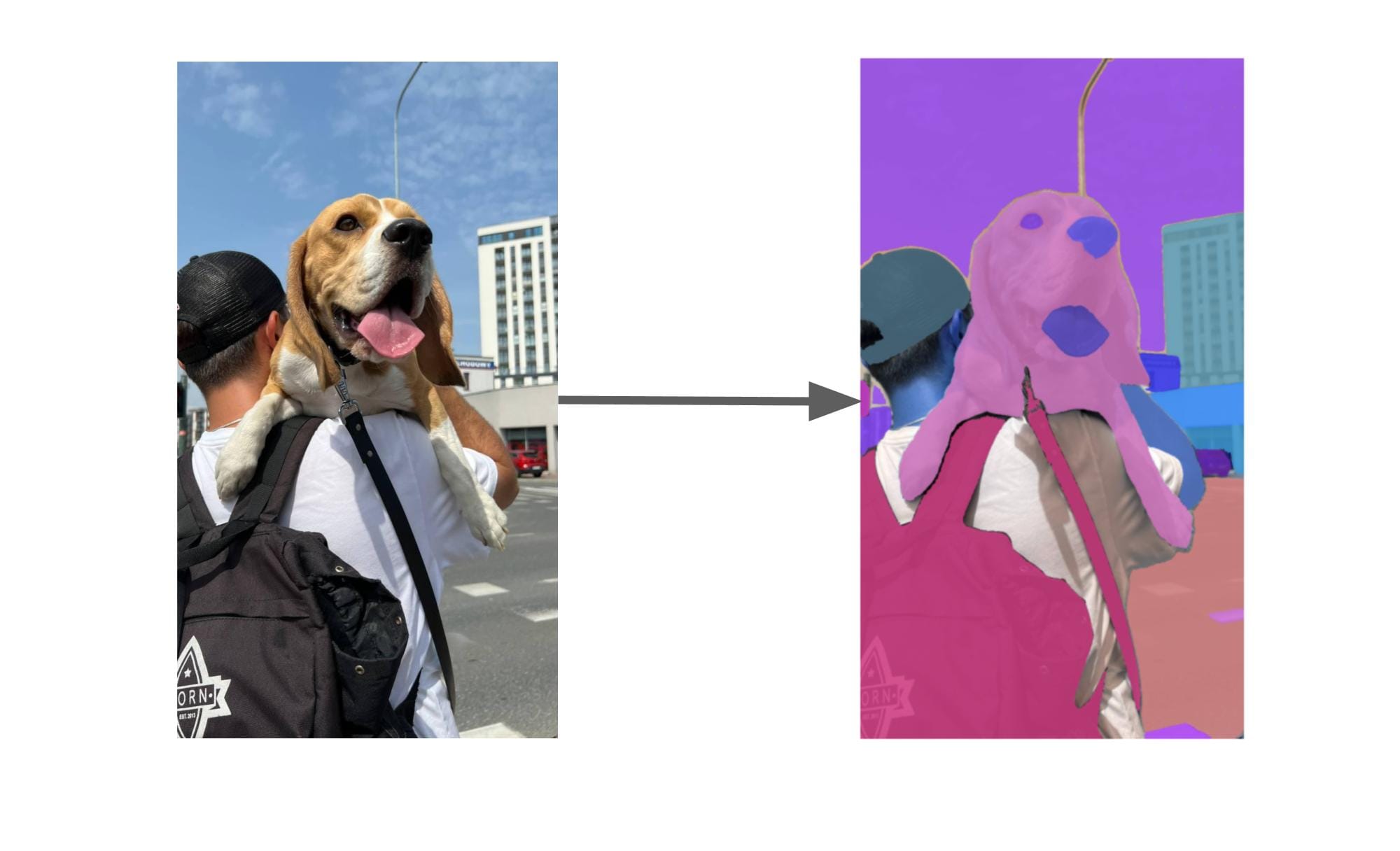
Let’s run inference on the image of a dog from earlier:

Florence-2 was able to successfully identify the location of a dog, then SAM 2 generated a segmentation mask that corresponds with the dog.
Conclusion
Released in July 2024, Segment Anything 2 (SAM 2) is an open source segmentation model. SAM 2 was trained on a large dataset of videos with annotated segmentation masks and is able to segment objects in images and videos.
In this guide, we walked through the basics of SAM 2 and how to use the model. We showed how to use the automatic mask generator to generate segmentation masks for an entire image. We then walked through how to use a version of SAM 2 grounded with Florence-2 to generate segmentation masks for specific regions of an image.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jul 30, 2024). What is Segment Anything 2 (SAM 2)?. Roboflow Blog: https://blog.roboflow.com/what-is-segment-anything-2/