
YOLOv3 is a real-time object detection model introduced in 2018 by Joseph Redmon and Ali Farhadi, built on a Darknet-53 backbone with feature pyramid networks that allow detection at three different scales in a single forward pass. It was a significant step forward from earlier YOLO versions in accuracy while maintaining fast inference, though it struggles with small objects and carries high memory requirements. Newer models have since surpassed it on both speed and accuracy, but YOLOv3 remains a well-documented reference point in the history of object detection.
Object detection, a core aspect of computer vision, revolves around identifying and detecting different objects within visual data, empowering machines to comprehend their environment.
Among the various object detection algorithms available, we'll delve into YOLOv3 (You Only Look Once, Version 3). Renowned at the time of launch for its capability to swiftly and accurately detect objects, YOLOv3 emerged as a leading algorithm in computer vision applications.
Since YOLOv3 was released, there have been several iterations of new YOLO models that achieve significantly better performance. These include YOLOv5, YOLOv7, and YOLOv8. To learn more about the full family of YOLO models, refer to our YOLO models guide.
In this blog post, we'll delve into the inner workings of YOLOv3 and explore how it revolutionized the field of object detection and computer vision.
What is YOLOv3?
YOLOv3 is a real-time object detection algorithm capable of detecting specific objects in videos and images. Leveraging features acquired through a deep convolutional neural network, the YOLO machine learning algorithm swiftly identifies objects within an image.
Joseph Redmon and Ali Farhadi are the authors behind YOLO versions 1-3, with the third iteration representing the one with the higher accuracy among the iterations. The genesis of the YOLO algorithms traces back to 2016 when Redmon and Farhadi initially created the first version. Subsequently, they unveiled Version 3 in 2018, which marked a significant advancement over its predecessors.
You may be wondering: why hy is it called "You Only Look Once"? In most object detectors, the features learned by the convolutional layers are passed on to a classifier for making detection predictions. However, in YOLO, the prediction is based on a special convolutional layer that uses 1×1 convolutions.
This means that the size of the prediction map is the same as the size of the feature map before it. This clever use of 1×1 convolutions helps streamline the prediction process, enabling the fully connected layer to utilize a compact representation of features when making detection predictions.
How YOLOv3 Works
YOLOv3, the third iteration of the YOLO object detection algorithm, was unveiled as an enhancement over its predecessor, YOLO v2, to improve both accuracy and speed.
The YOLOv3 algorithm takes an image as input and then uses a CNN called Darknet-53 to detect objects in the image. Darknet-53 is derived from the ResNet architecture and it is tailor-made for object detection tasks, boasting 53 convolutional layers and achieving top-notch performance across various object detection benchmarks.
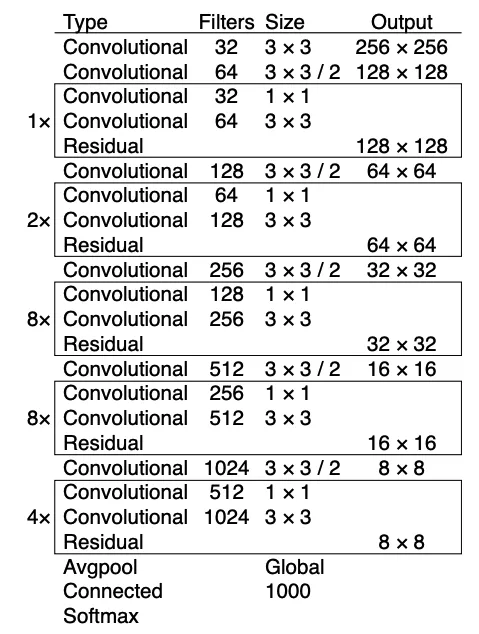
One of the key features of Darknet-53 is its deep structure, which allows it to learn complex patterns and representations directly from raw image data. This deep architecture enables the network to capture intricate details and nuances present in images, leading to improved object detection performance.
Moreover, Darknet-53 incorporates residual connections, similar to those used in ResNet architectures. These connections facilitate the flow of information through the network, mitigating the vanishing gradient problem and enabling more efficient training of deeper networks.
Darknet-53 plays a crucial role in the YOLOv3 algorithm by providing a powerful feature extraction backbone. Its deep architecture and effective feature extraction capabilities contribute to the algorithm's ability to accurately detect objects in real-time scenarios.
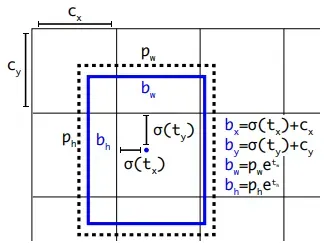
Another notable enhancement in YOLOv3 is the implementation of anchor boxes with diverse scales and aspect ratios. Unlike YOLO v2, where anchor boxes were uniform in size, YOLOv3 employs scaled anchor boxes with varied aspect ratios, enabling the algorithm to better detect objects of varying sizes and shapes.
Furthermore, YOLOv3 introduces the concept of "Feature Pyramid Networks" (FPN), a CNN architecture designed to detect objects across multiple scales. FPNs construct a hierarchical pyramid of feature maps, allowing the model to detect objects at different scales simultaneously. This augmentation significantly enhances detection performance for small objects, as the model can analyze objects across a range of scales.
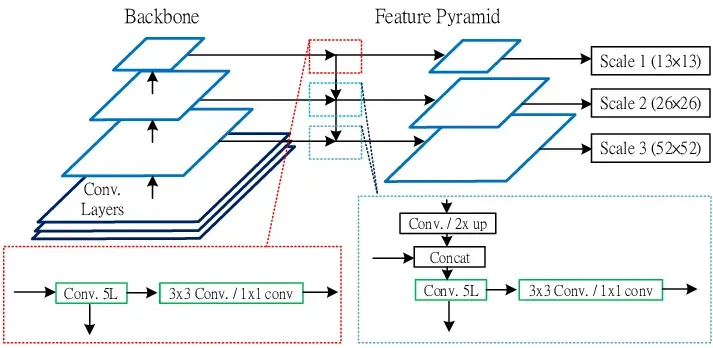
Additionally, YOLOv3 exhibits improved capability in handling a wider array of object sizes and aspect ratios, rendering it more precise and robust compared to its predecessors.
YOLOv3 Performance
In this section, we are going to show the performance comparison between YOLOv3, RetinaNet-50 and RetinaNet-101.
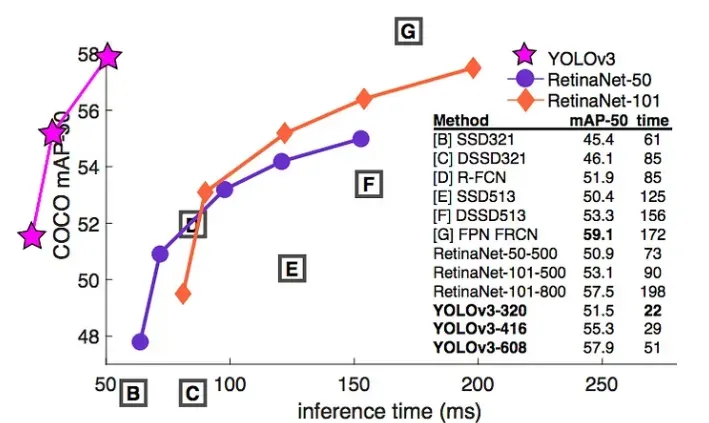
YOLOv3 demonstrates comparable performance to other leading object detectors like RetinaNet, while also boasting significantly faster speeds according to the COCO mAP 50 benchmark. Additionally, it outperforms SSD and its variants.
YOLOv3 Advantages and Limitations
YOLOv3 stands out as a remarkable deep learning model architecture that has greatly advanced object detection. Its remarkable speed, precision, and adaptability have garnered widespread adoption across diverse applications.
Nevertheless, like any technology, it comes with its own set of strengths and weaknesses. Delving into these advantages and limitations can assist in evaluating whether YOLOv3 aligns with the requirements of a particular deep learning project. Let's delve into these aspects in the following section to facilitate a more informed decision-making process.
YOLOv3 Advantages
The following are the reasons why someone may have chosen YOLOv3 when the model was released. Since the model has been superseded by better models, there are models that have the below advantages to a greater degree.
- Swift and Effective: YOLOv3 prioritizes speed and efficiency, rendering it optimal for real-time scenarios like self-driving vehicles.
- Precision: YOLOv3 attains remarkable accuracy in object detection without compromising its speed, owing to its feature pyramid network and prediction module.
- Single-Step Detection: In contrast to conventional object detection frameworks employing multiple stages, YOLOv3 employs a single neural network for detection, simplifying its implementation and usage.
- Versatility: YOLOv3 exhibits the capability to detect objects across diverse environments and circumstances, enhancing its adaptability as a comprehensive model.
YOLOv3 Limitations
- Obsolescence: There are significantly better model architectures available today such as YOLOv5 and YOLOv8.
- Detection of Small Objects: YOLOv3 may encounter difficulty in detecting smaller objects as a result of its anchor box configuration and substantial stride.
- Demanding Memory Requirements: YOLOv3 necessitates considerable memory resources for operation, posing challenges for devices with restricted capabilities.
- Training Duration: Training YOLOv3 can be a time-intensive process, demanding extensive datasets and computational resources.
Conclusion
In conclusion, YOLOv3 represents a significant leap forward in object detection technology. Its one-stage architecture, powered by Darknet-53 and feature pyramid networks, delivers impressive real-time performance. While it outperforms previous state-of-the-art models, YOLOv3 does face challenges in detecting smaller objects and demands high memory resources and training time.
YOLOv3 is now obsolete, with newer models being faster and more accurate. With that said, YOLOv3 still has a notable place in the history of computer vision.
To learn more about the YOLO family of models, read our YOLO models post. To learn about state-of-the-art models, refer to the following guides:
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Mar 26, 2024). What is YOLOv3? An Introductory Guide.. Roboflow Blog: https://blog.roboflow.com/what-is-yolov3/