
YOLOS is the newest and potentially most impactful iteration on the YOLO family of object detection models. Outlined in a paper published in June 2021, the YOLOS model is based on transformers, a new breakthrough in the world of computer vision.
In this article, we're going to discuss what YOLOS is, how it works, and how YOLOS compares to other models. Without further ado, let's begin!
What is YOLOS?
YOLOS (You Only Look At One Sequence) is an object detection model that uses the Vision Transformer architecture, based on the transformer architecture established in NLP. YOLOS was designed to illustrate the ways in which transformers could be used in object recognition.
In the following video, we talk through what's new in YOLOS with reference to this blog post. We cover what's new in YOLOS and how it works both in the video and in the following sections.
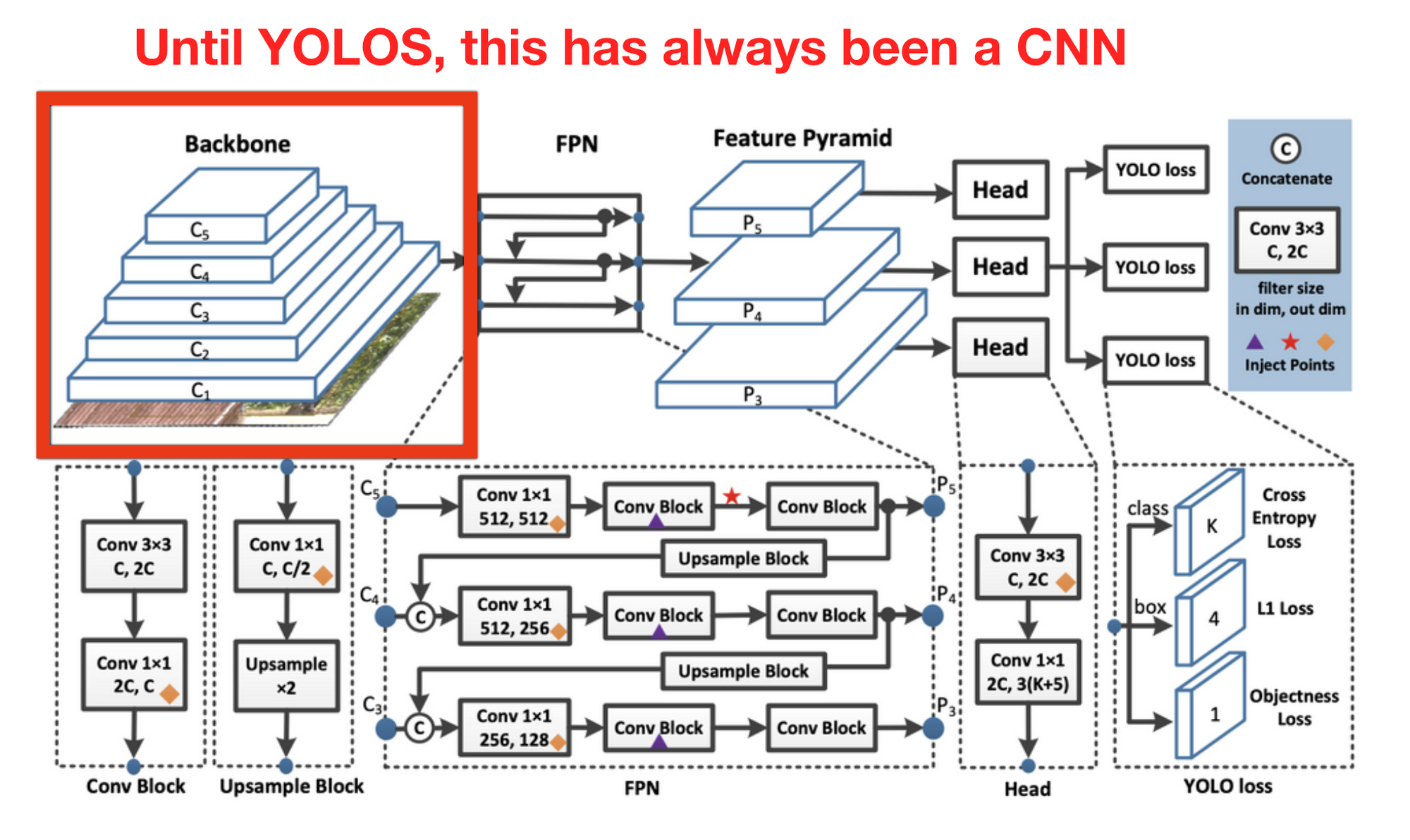
The YOLO backbone before YOLOS
In all other YOLO models, the backbone for creating features from images is a variation of convolutional neural networks. While the YOLO models tend to disagree on exactly how this CNN is formed, they all build the neck of the object detection model on the CNN backbone.
The ascent of transformers
Transformers, from the famous Attention is All you Need, have totally "transformed" the world of NLP, theorized to be even more broad ranging in their ability to model any mathematical transformation between data and predictions. Transformers are actively used in the NLP field to process sequences of text.
In the last year, transformers have broadened their scope to the world of computer vision, setting new standards in image classification with ViT, the first Vision Transformer. The Vision Transformer treats patches of image pixels as sequences, much like the sequences of text tokens that we are familiar hearing about in models like GPT and BERT.
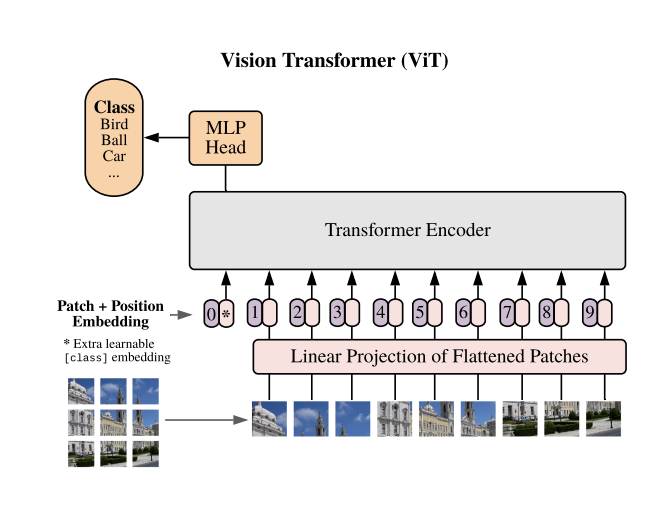
YOLOS Transformer Architecture
Unlike previous CNN based YOLO models, the YOLOS backbone is a Transformer block, much like the first vision transformer for classification. The image below illustrates the structure of a transformer encoder
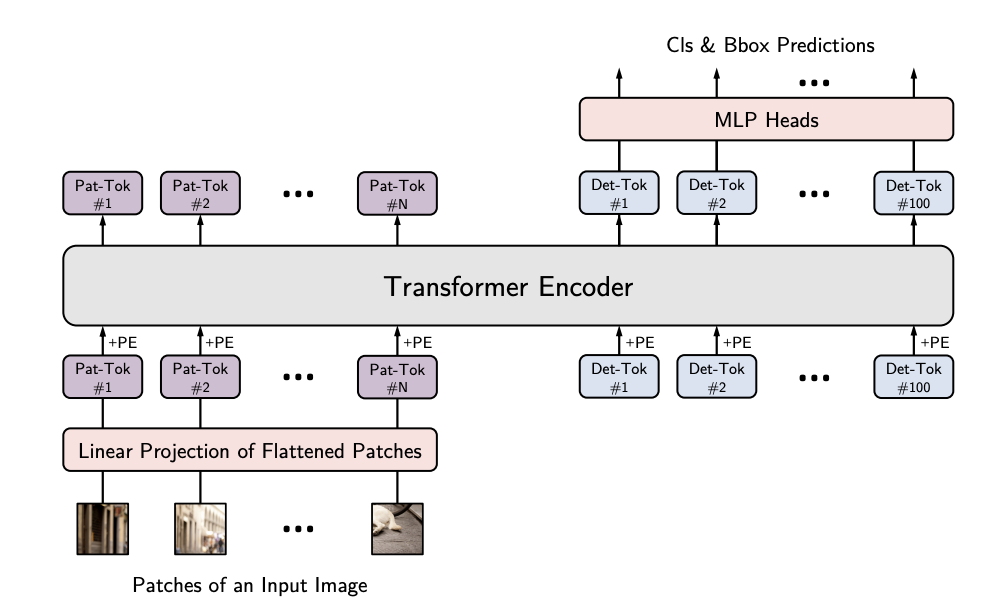
In addition to the Vision Transformer, YOLOS has a detector portion of the network that maps a generated sequence of detection representations to class and box predictions.
YOLOS is a YOLO model through the fact that YOLOS only looks at the sequence of image patches once, making it a "You Only Look Once" model.
Aside from that fact, the YOLOS network architecture shares nothing else with previous YOLO Models.
YOLOS Evaluation: Should I Switch to YOLOS?
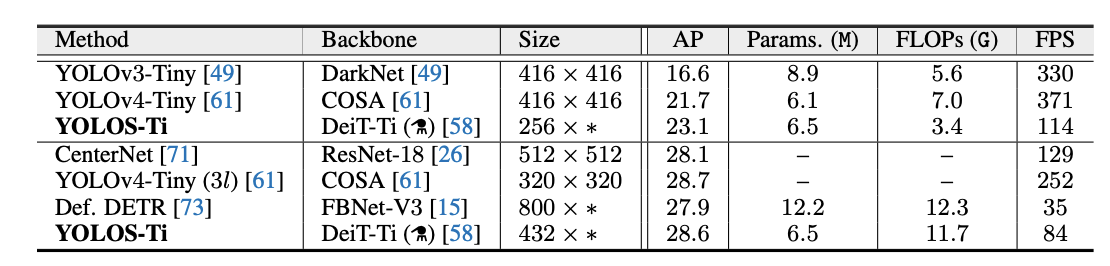
In relation to other YOLO models, the accuracy of YOLOS is not yet the best in class. This is to be expected as the researchers who worked on this paper state explicitly that the model is not designed to be state-of-the-art with regard to performance. Instead, the model is a frontier of exploration in using transformers in computer vision tasks.
It is worth looking into YOLOS for research purposes, but there are other YOLO models that are appropriate for production use cases. Otherwise we would recommend staying tuned for future iterations of transformers in object detection.
Training YOLOS
If you want to train YOLOS on your own data you can read our post, see video below, or you can check out the YOLOS repo source.
If you are just seeking the current best performance on your custom dataset, we recommend starting by training YOLOv5.
Happy training and as always, happy detecting!
Frequently Asked Questions
How does YOLOS perform on COCO?
According to the findings in the YOLOS GitHub paper summary, the YOLOS-B model, the best-performing among the tested variants of YOLOS, achieved an Average Precision (AP) score of 42.0 when benchmarked against the COCO dataset. This was after 1000 pre-train epochs and 150 fine-tune epochs.
How does YOLOS perform compared to other YOLO models?
The most performant variant of YOLOS achieved a 42.0 AP score on COCO, whereas the YOLOv7 E6E (a state-of-the-art model in November 2022) achieved a 56.8 AP. YOLOS does not achieve as high of an AP score as YOLOv4 and more recent variants when benchmarked against COCO.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Oct 28, 2021). What is YOLOS? What's New in the Model?. Roboflow Blog: https://blog.roboflow.com/whats-new-in-yolos/