
YOLO-World is a real-time, zero-shot object detection model from Tencent that identifies objects in images based on a text prompt, without requiring task-specific fine-tuning. Roboflow provides full support for YOLO-World through a hosted API endpoint, edge deployment via Roboflow Inference, and auto-labeling workflows through an Autodistill integration that lets you use YOLO-World to generate training labels for smaller fine-tuned models. The model works best on common or abstract object categories and requires prompt experimentation to get reliable results in specialized domains.
YOLO-World is a real-time, zero-shot object detection model developed by Tencent’s AI research lab. You can use YOLO-World to identify objects in an image without any pre-training.
To use YOLO-World, you can provide a text prompt and the model will aim to find instances of the specified object in an image. For example, you can provide an image and ask YOLO-World to identify the location of potential product defects.
Here is an example of YOLO-World identifying a defect in a cookie:

YOLO-World can be used for both zero-shot object detection on the edge and to auto-label images for use in training fine-tuned models.
In this guide, we will walk through all of the ways you can use YOLO-World with Roboflow, with reference to our hosted API, deployment to the edge, building applications with workflows, and more.
Without further ado, let’s get started!
How to Use YOLO-World with Roboflow
YOLO-World is able to identify a wide range of objects without being fine-tuned for a particular use case. YOLO-World works best on abstract objects, like “package” or “box” or “metal filing”. In contrast, the model will not work as well when tasked with differentiating between different screws, for example.
Consider the following image of a cookie, prompted with the phrase small metal filing:

With the right prompt, YOLO-World was able to accurately identify a metal shaving in the cookie. To learn how we arrived at this prompt, and best practices for prompting YOLO-World, refer to our Tips and Tricks for Prompting YOLO-World guide.
Now consider the following image of a strawberry farm, to which the prompts green strawberry and red strawberry were passed:

In the above image, we show the results from YOLO-World on the farm image. We can see the model successfully identifies the fruits. While there are a few erroneous predictions, these can be filtered out with preprocessing logic (i.e. by removing bounding boxes whose width is greater than a certain amount).
Let’s talk about the ways in which you can use YOLO-World with Roboflow.
Hosted YOLO-World API Endpoint
Roboflow offers a hosted YOLO-World API endpoint. One reason to use the Roboflow hosted endpoint of YOLO-World is because of the compute requirements to achieve real-time performance. YOLO-World is described as a real-time model and achieving a speed of multiple frames per second at inference time can only be achieved on expensive GPUs such as T4s and V100s.
You can use the Roboflow YOLO-World API to identify objects in an image without training and without purchasing your own hardware specifically for running the model and achieve real-time performance.
To learn how to use our hosted endpoint, refer to the Roboflow YOLO-World API reference.
Deploy YOLO-World to the Edge
For real-time applications, it is essential to deploy YOLO-World to the edge. This may involve having a GPU or cluster of GPUs on your own infrastructure that are connected directly to cameras in your facility. Such a connection can be facilitated over a protocol like RTSP.
You can also directly connect cameras to GPU-enabled edge devices such as an NVIDIA Jetson. These devices can be placed across your manufacturing facility for real-time inference.
To deploy YOLO-World to the edge, you can use Roboflow Inference, an open source inference server for running computer vision models. You can use YOLO-World directly through the Inference Python package, or deploy YOLO-World as a microservice to which several clients can send requests using the inference server start command.
You can deploy Inference on both an image and a video stream. A video stream can be a video file whose frames are read, a webcam feed, or an RTSP stream.
Refer to the Roboflow Inference documentation to learn how to get started with YOLO-World.
Automatically Label Image Data with YOLO-World
While YOLO-World may be a large model for which you need a dedicated GPU to run inference in real time, you can use the model to auto-label data for use in training a smaller, fine-tuned model. Your smaller mode can run in real time without requiring an expensive GPU.
To auto-label data, the workflow is:
- Gather data.
- Use YOLO-World with custom prompts to label objects of interest.
- Use the labeled images to train an object detection model.
You can implement this process with Autodistill, an open source framework for using large, foundation vision models to auto-label image data. Autodistill has a custom YOLO-World integration that you can use to label data.
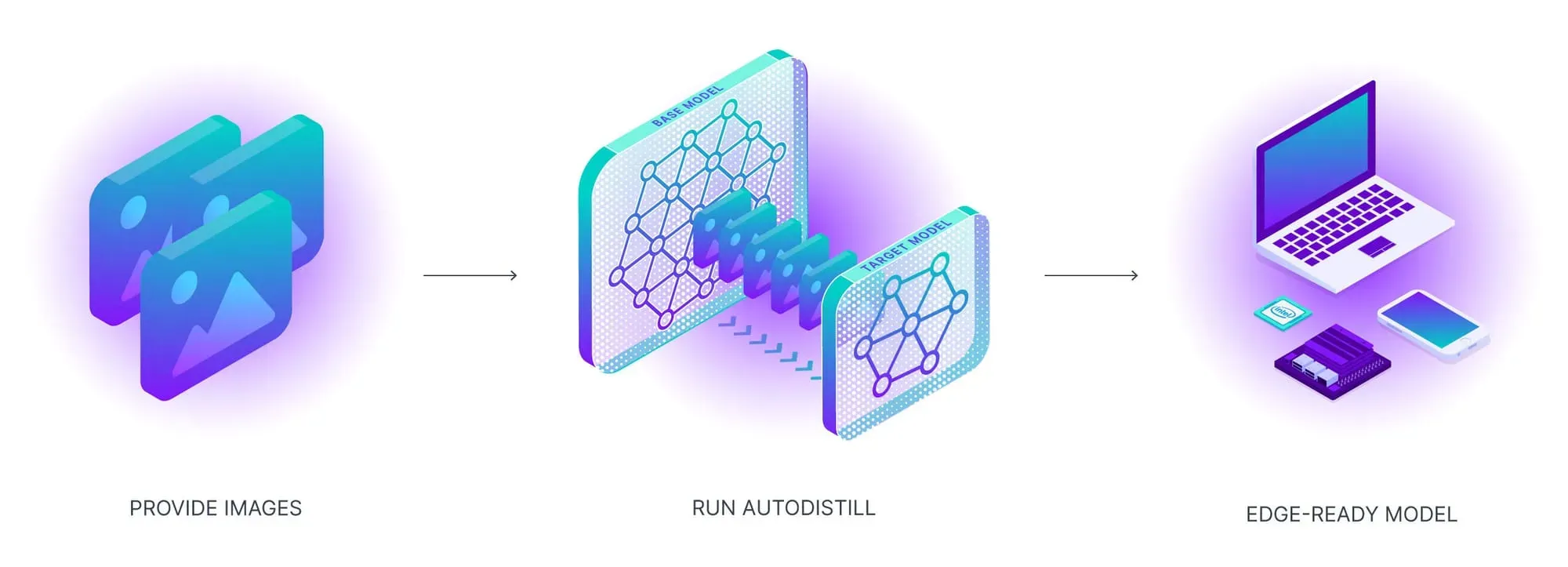
To learn about auto-labeling data with YOLO-World, refer to the Autodistill YOLO-World documentation.
We encourage you to experiment with different prompts to find one that allows you to label your data. Refer to our YOLO-World tips guide for more information on how to best prompt YOLO-World to achieve the desired output.
Conclusion
Roboflow now offers full support for YOLO-World, a zero-shot object detection model. You can provide a text prompt to YOLO-World and the model will aim to retrieve all instances of that object in an image. You can run YOLO-World on images with the Roboflow hosted API, or on images, videos, and video streams on your own hardware using the open source Roboflow Inference solution.
You can also use YOLO-World to auto-label data for use in training a smaller vision model that is tuned to your particular use case.
YOLO-World works best when used to identify common objects. We recommend experimenting with the model to evaluate the extent to which YOLO-World can help you solve a vision problem.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Mar 21, 2024). Launch: YOLO-World Support in Roboflow. Roboflow Blog: https://blog.roboflow.com/yolo-world-roboflow/