
Object detection powers countless real-world applications, from autonomous vehicles navigating city streets to smart factories monitoring production lines. With rapid advances in transformer architectures and attention mechanisms, the landscape of state-of-the-art object detection has evolved dramatically in 2025. New models like RF-DETR and YOLOv12 are pushing the boundaries of what's possible, achieving unprecedented accuracy while maintaining real-time performance.
In this guide, we explore the best object detection models available today, from Roboflow's groundbreaking RF-DETR to the latest YOLO iterations, and show how to deploy them efficiently across various hardware platforms.
Best Object Detection Models Criteria
Here are the criteria we used to select these object detection models.
1. Real-time performance
The model should achieve inference speeds suitable for real-time applications, typically processing images at 30+ FPS on standard GPU hardware like NVIDIA T4 or edge devices. This ensures the model can handle video streams and time-sensitive detection tasks without significant latency.
2. Accuracy on standard benchmarks
Models should demonstrate strong performance on industry-standard benchmarks, particularly the Microsoft COCO dataset. We prioritize models achieving at least 45% mAP (mean Average Precision) at IoU 0.50:0.95, indicating reliable detection across various object scales and categories.
3. Model efficiency and scalability
The architecture should offer multiple model sizes (nano, small, medium, large) to accommodate different computational budgets. Efficient models balance parameter count, FLOPs, and accuracy, making them deployable across devices from edge hardware to cloud infrastructure.
4. Domain adaptability
Strong pre-trained models that transfer well to custom datasets and specialized domains are essential. We favour architectures that demonstrate robust performance on domain adaptation benchmarks like RF100-VL, showing they can generalize beyond their training data.
5. Active development and deployment support
Models with strong community backing, regular updates, and production-ready deployment tools are prioritized. Integration with frameworks like Roboflow Inference, Ultralytics, or native PyTorch ensures practitioners can move from experimentation to production smoothly.
To explore top-performing models across computer vision tasks, check out the Vision AI Leaderboard.
Best Object Detection Models
Here's our list of the best object detection models for 2025.
1. RF-DETR
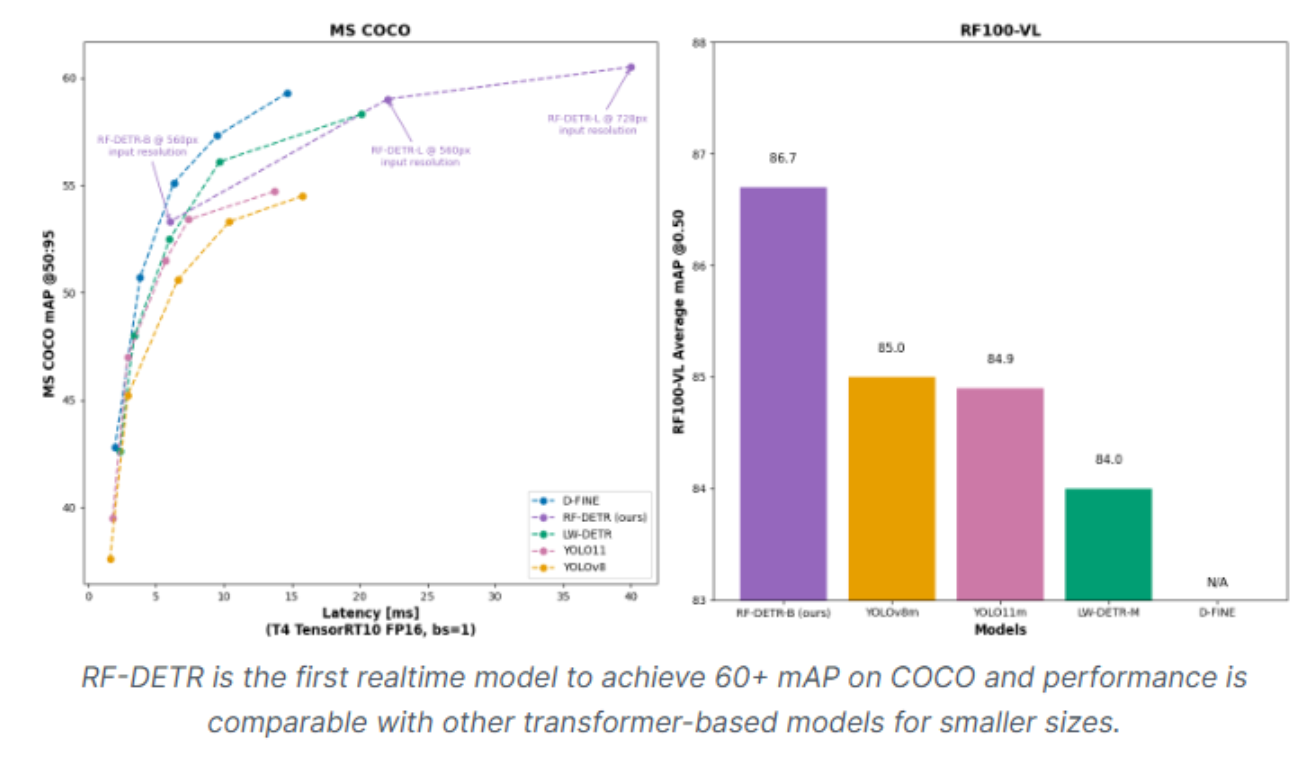
RF-DETR is a real-time, transformer-based object detection model architecture developed by Roboflow and released under the Apache 2.0 license in March 2025. RF-DETR represents a significant milestone as the first real-time model to exceed 60 mAP on the RF100-VL domain adaptation benchmark while achieving state-of-the-art performance across diverse real-world datasets.
What makes RF-DETR particularly impressive is its use of the DINOv2 vision backbone, which provides exceptional transfer learning capabilities. The model was designed from the ground up to adapt well across diverse domains and dataset sizes, making it ideal for both general-purpose detection and specialized applications.
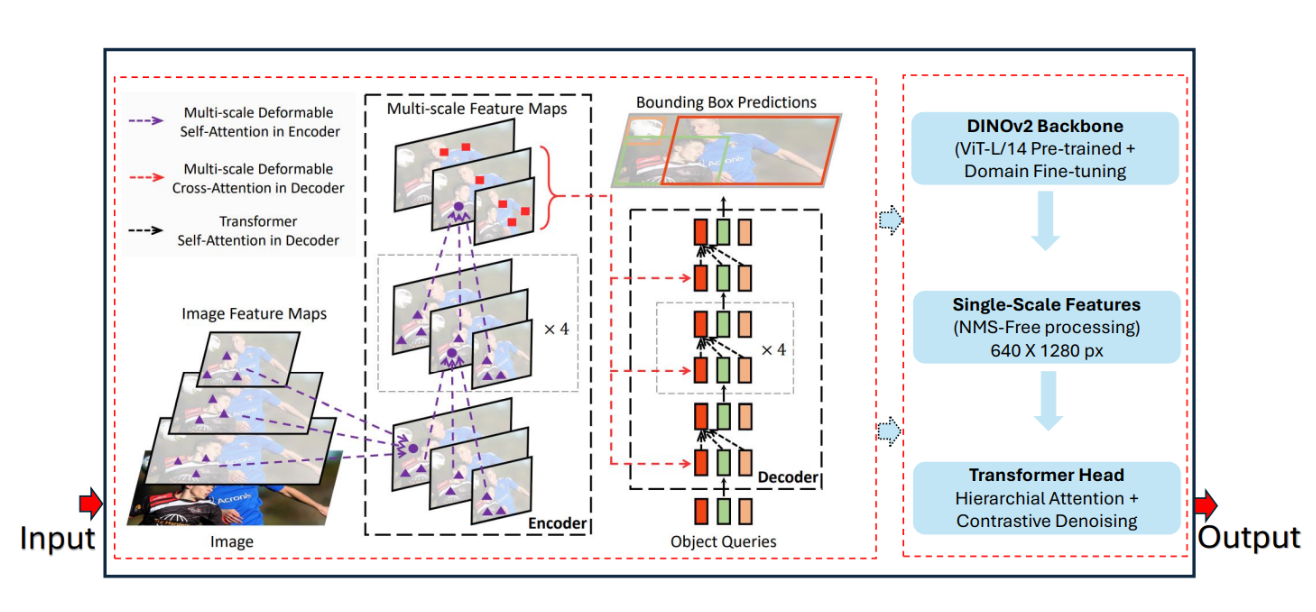
The diagram above shows a Detailed architecture of RF-DETR's components: DINOv2 backbone, transformer encoder with deformable attention, and decoder with query-based detection head. The diagram illustrates how RF-DETR eliminates NMS and anchor boxes through its end-to-end transformer architecture. Shows the flow from input image → backbone feature extraction → encoder processing → decoder predictions → final detections.
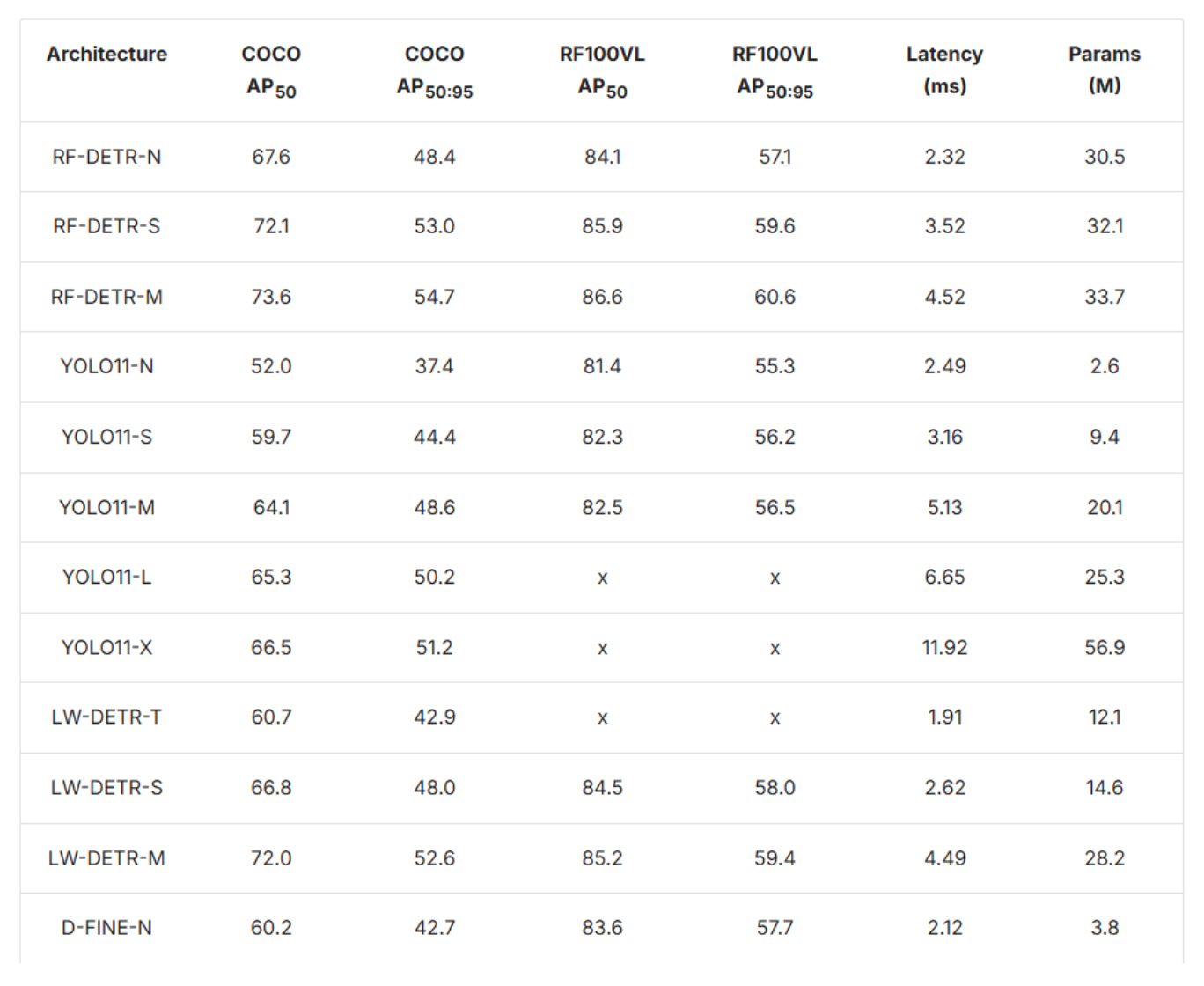
RF-DETR comes in multiple variants to suit different deployment scenarios. The Nano, Small, and Medium models offer excellent accuracy-to-speed ratios, while the preview segmentation variant extends capabilities to instance segmentation tasks. With RF-DETR-M achieving 54.7% mAP at just 4.52ms latency on a T4 GPU, it outperforms comparable YOLO models while maintaining real-time speeds.
RF-DETR benchmark performance:
The chart above is a performance comparison chart showing RF-DETR against YOLOv11, YOLOv8, and other real-time detectors on COCO mAP vs. latency. The RF-DETR variants (N/S/M) form the Pareto frontier, demonstrating superior trade-offs between accuracy and speed. In particular, RF-DETR-M achieves higher mAP with only a marginal increase in latency, highlighting its efficiency in balancing precision and real-time performance. Furthermore, RF100-VL extends this capability by reaching 60.6% mAP, indicating exceptional domain adaptability and robustness across varying visual environments, surpassing many traditional CNN- and transformer-based detectors in both accuracy and generalization.
The model's transformer architecture eliminates traditional detection components like anchor boxes and Non-Maximum Suppression (NMS), enabling truly end-to-end object detection. This architectural choice not only simplifies the detection pipeline but also improves consistency and reduces post-processing overhead.
RF-DETR is small enough to run on edge devices using Roboflow Inference, making it ideal for deployments requiring both strong accuracy and real-time performance without cloud dependencies.
2. YOLOv12
YOLOv12, released in February 2025, marks a pivotal shift in the YOLO series by introducing an attention-centric architecture. Rather than relying solely on convolutional operations, YOLOv12 integrates efficient attention mechanisms to capture global context while maintaining the real-time speeds YOLO is known for.
The model introduces several groundbreaking components, including the Area Attention Module (A²), which optimizes attention by dividing feature maps into specific areas for computational efficiency, and Residual Efficient Layer Aggregation Networks (R-ELAN) that enhance training stability through block-level residual connections. FlashAttention integration further reduces memory bottlenecks, improving inference efficiency across the board.
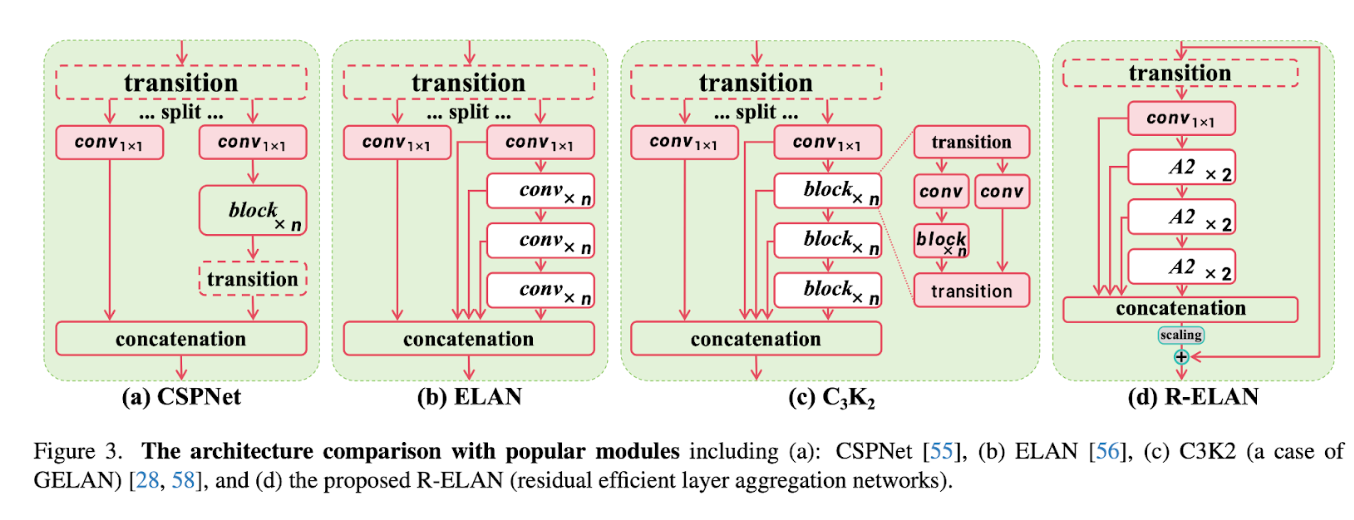
The diagram above can be found here:
YOLOv12 benchmark performance:
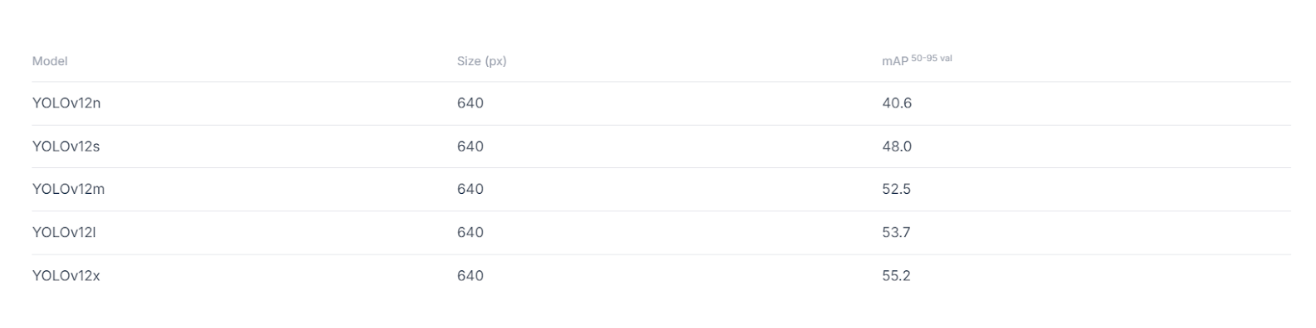
- YOLOv12-N: 40.6% mAP with 1.64ms latency (+2.1% over YOLOv10-N, +1.2% over YOLO11-N)
- YOLOv12-M: 52.5% mAP with 4.86ms latency (+1.0% over YOLO11-M)
- YOLOv12-X: 55.2% mAP with 11.79ms latency, the highest accuracy in the YOLO family
Before diving into YOLOv12's innovations, it's worth noting its predecessors' contributions.
- YOLO11 (released October 2024) refined architectural designs with 22% fewer parameters than YOLOv8m while achieving higher mAP through enhanced feature extraction and optimized training pipelines.
- YOLOv10 (May 2024) pioneered NMS-free training using consistent dual assignments, significantly reducing inference latency.
- YOLOv9 (February 2024) introduced Programmable Gradient Information (PGI) and the GELAN architecture to address information loss in deep networks, improving both accuracy and efficiency.
- YOLOv8 (January 2023) established the anchor-free approach with enhanced CSPNet backbones, becoming one of the most widely adopted frameworks with comprehensive task support.
The trade-off is that YOLOv12 models run slightly slower than their immediate predecessors; YOLOv12-N is 9% slower than YOLOv10-N, and YOLOv12-M is 3% slower than YOLO11-M. However, the accuracy gains make this worthwhile for applications where detection quality is paramount.
YOLOv12 is supported by the Ultralytics Python package, making it accessible for both beginners and professionals with just a few lines of code for training, inference, and deployment.
3. YOLO-NAS
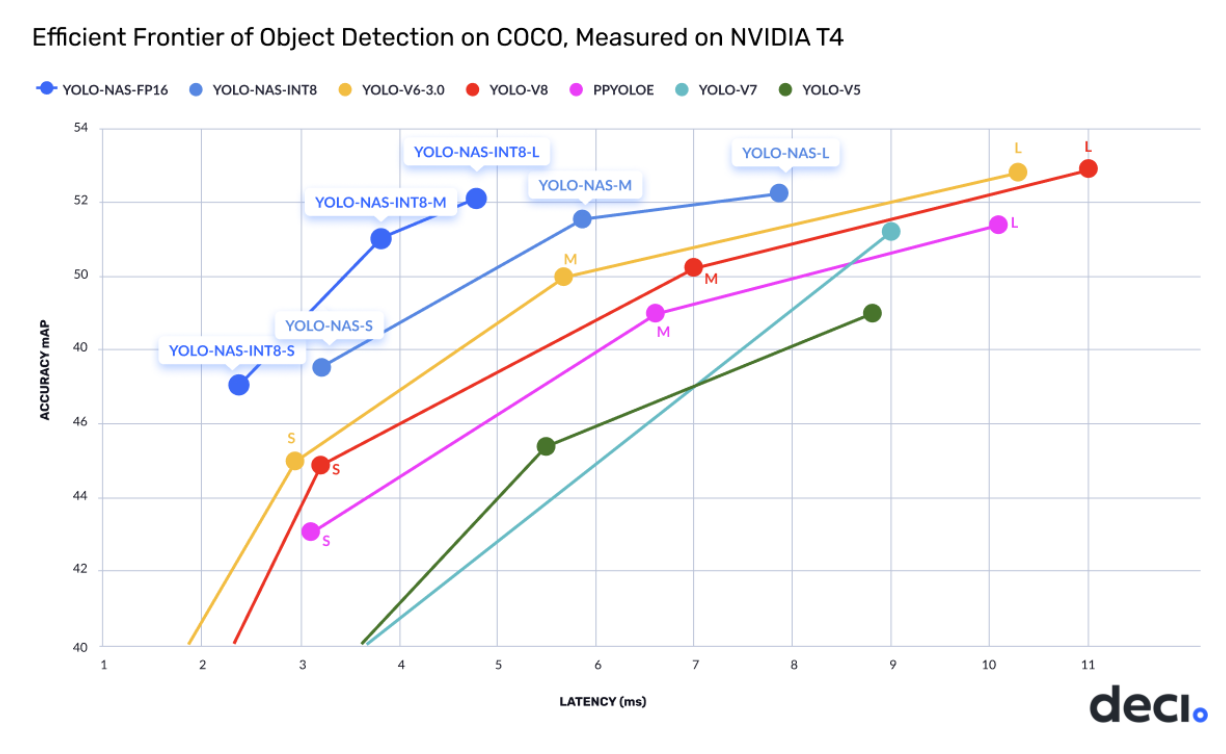
YOLO-NAS, developed by Deci AI and released in May 2023, represents a breakthrough in object detection through the application of Neural Architecture Search (NAS) technology. Rather than manually designing architectures, YOLO-NAS was discovered through Deci's AutoNAC (Automated Neural Architecture Construction) engine, which explored an enormous search space of 10^14 potential architectures over 3,800 GPU hours.
The key innovation of YOLO-NAS is its quantization-friendly architecture. While most models experience significant accuracy drops when quantized to INT8 for faster inference, YOLO-NAS was designed from the ground up with quantization in mind. Its quantization-aware blocks minimize precision loss during INT8 conversion, resulting in a model that maintains performance while achieving enhanced efficiency.
YOLO-NAS addresses critical limitations of previous YOLO models through sophisticated training schemes, including pre-training on the Objects365 dataset (365 categories, 2 million images), leveraging pseudo-labelled COCO images, and incorporating knowledge distillation with Distribution Focal Loss (DFL). This comprehensive training approach helps the model handle class imbalance and improve detection accuracy for underrepresented classes.
YOLO-NAS performance metrics:
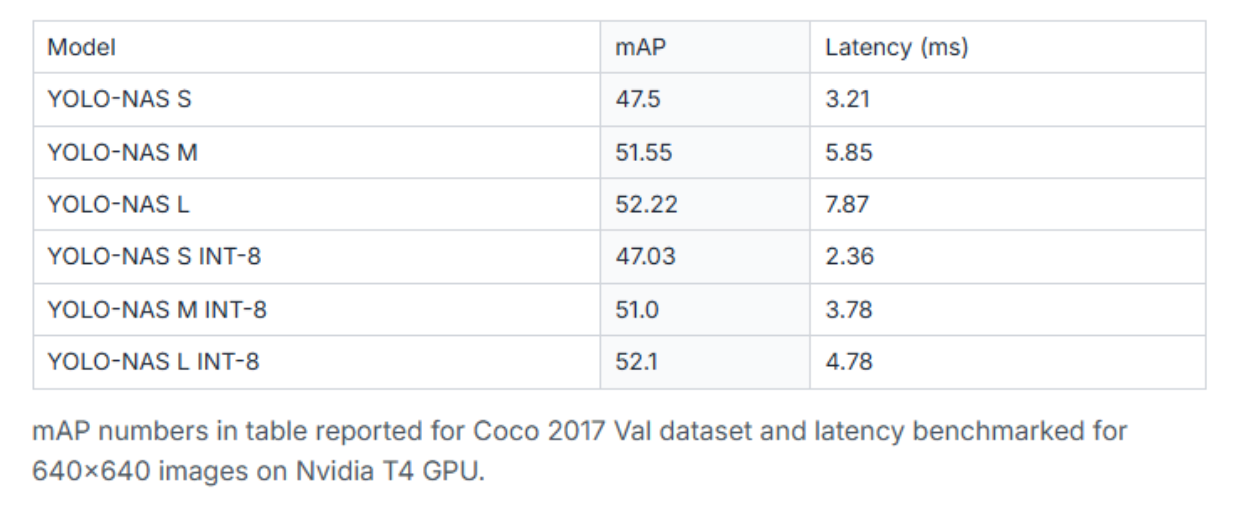
Performance improvements over predecessors are substantial: YOLO-NAS shows a 20.5% boost over YOLOv7, 11% improvement over YOLOv5, and 1.75% gain compared to YOLOv8. These enhancements make YOLO-NAS particularly attractive for production deployments requiring both speed and accuracy.
The model comes pre-trained on COCO, Objects365, and Roboflow 100 datasets, making it highly suitable for downstream object detection tasks and transfer learning to custom domains. YOLO-NAS is available through Deci's SuperGradients library, which includes advanced training techniques like Distributed Data Parallel, Exponential Moving Average, Automatic Mixed Precision, and Quantization Aware Training.
Important note: Deci has been acquired by NVIDIA, and these models are no longer actively maintained by the original team, though Ultralytics continues to support their usage. The model uses an Apache 2.0 license, though the pre-trained weights have special licensing considerations.
4. RTMDet
RTMDet, developed by OpenMMLab, is an efficient real-time object detector that achieves an incredible 52.8% AP on COCO at 300+ FPS on an NVIDIA 3090 GPU. This makes RTMDet one of the fastest and most accurate object detectors available, setting new standards for high-throughput detection scenarios.
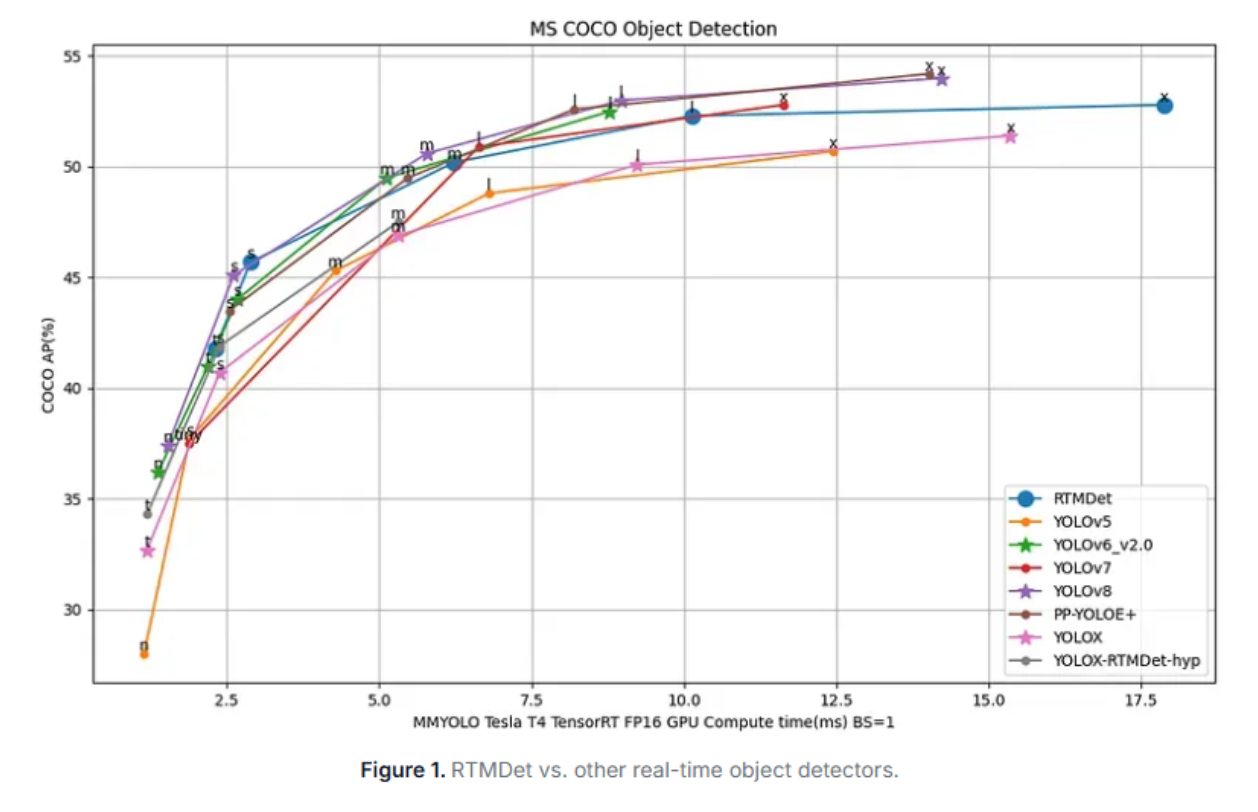
The model's speed comes from several architectural innovations:
- Lightweight backbone optimized for parallel processing
- Dynamic label assignment improves training efficiency
- Shared convolution layers reduce computational overhead
- Optimized inference pipeline leveraging GPU parallelism
RTMDet offers variants across the accuracy-speed spectrum:
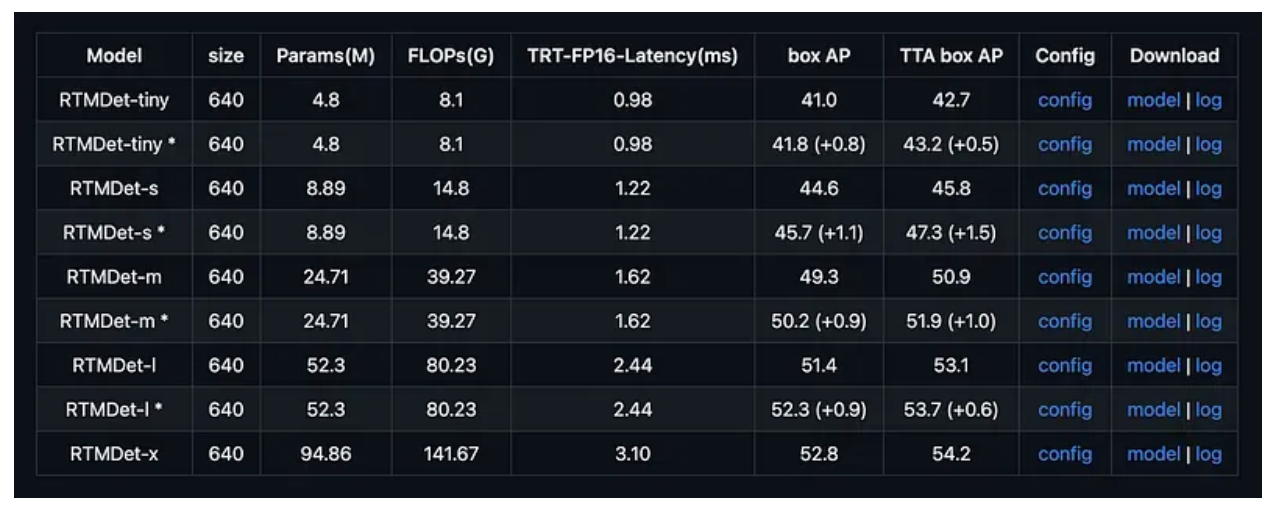
- RTMDet-Tiny: 40.5% AP at 1020+ FPS; fastest variant for extreme speed requirements
- RTMDet-Small: 44.6% AP at 819 FPS; balanced option for most applications
- RTMDet-Medium: 48.8% AP; higher accuracy while maintaining excellent speed
- RTMDet-Large: 51.2% AP; maximum accuracy at 300+ FPS
- RTMDet-Extra-Large: 52.8% AP; peak performance for demanding scenarios
Even the larger variants maintain frame rates exceeding 200 FPS, making RTMDet suitable for high-throughput video processing where other models would bottleneck.
RTMDet excels in applications requiring maximum throughput:
- High-speed video processing analyzes hundreds of frames per second
- Real-time tracking of fast-moving objects in sports or surveillance
- Manufacturing quality control, inspecting products at line speed
- Autonomous robotics requiring sub-millisecond detection latency
- Batch inference scenarios where GPU utilization directly impacts cost
RTMDet's packaging with MMDetection makes deployment straightforward, and its MIT license allows unrestricted commercial use.
Best Zero-Shot Object Detection Models
5. YOLO-World
YOLO-World represents a fundamental shift in object detection by introducing zero-shot, open-vocabulary capabilities to the YOLO architecture. Released by Tencent's AI Lab in January 2024, YOLO-World addresses a critical limitation: the need to retrain models for new object classes.
Unlike traditional detectors limited to predefined categories from training datasets like COCO's 80 classes, YOLO-World can detect objects by simply prompting it with text descriptions. This is achieved through vision-language pre-training that aligns visual and textual representations, enabling the model to understand and detect objects it has never seen during training.
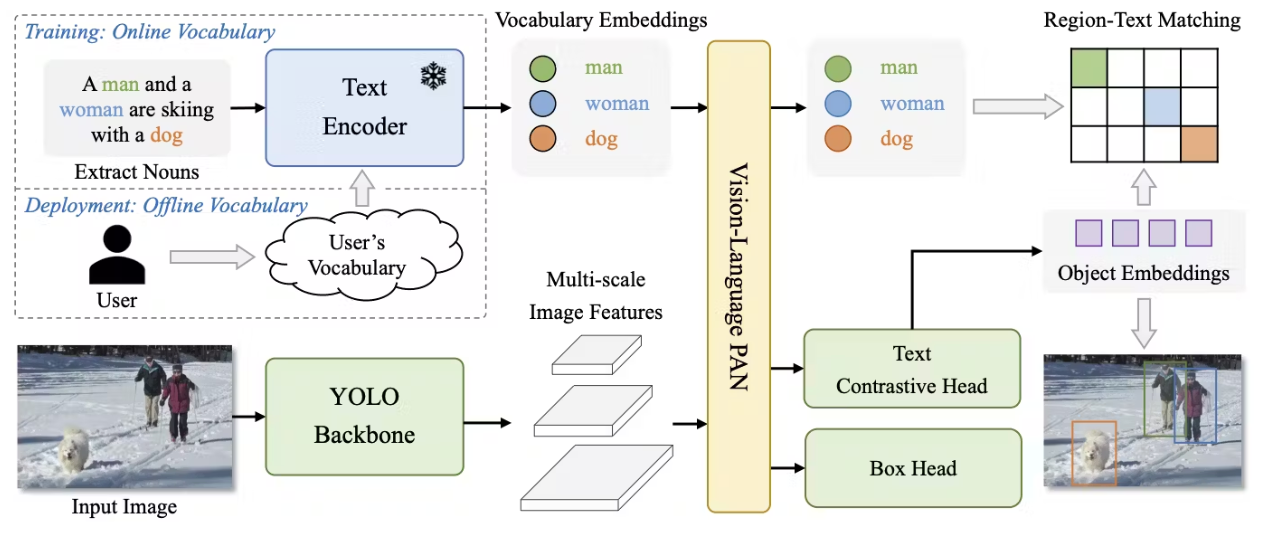
The diagram above is an architecture diagram showing YOLO-World's vision-language integration. It displays the YOLOv8 backbone, RepVL-PAN (Re-parameterizable Vision-Language Path Aggregation Network), and region-text contrastive learning components. It shows how text embeddings and image features are fused through cross-modal attention mechanisms.
What makes YOLO-World particularly impressive is that it maintains the speed advantages of the CNN-based YOLO architecture while achieving zero-shot capabilities previously only seen in slower transformer-based models like Grounding DINO. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP at 52.0 FPS on V100—making it approximately 20x faster than competing zero-shot detectors while being 5x smaller.
YOLO-World performance:
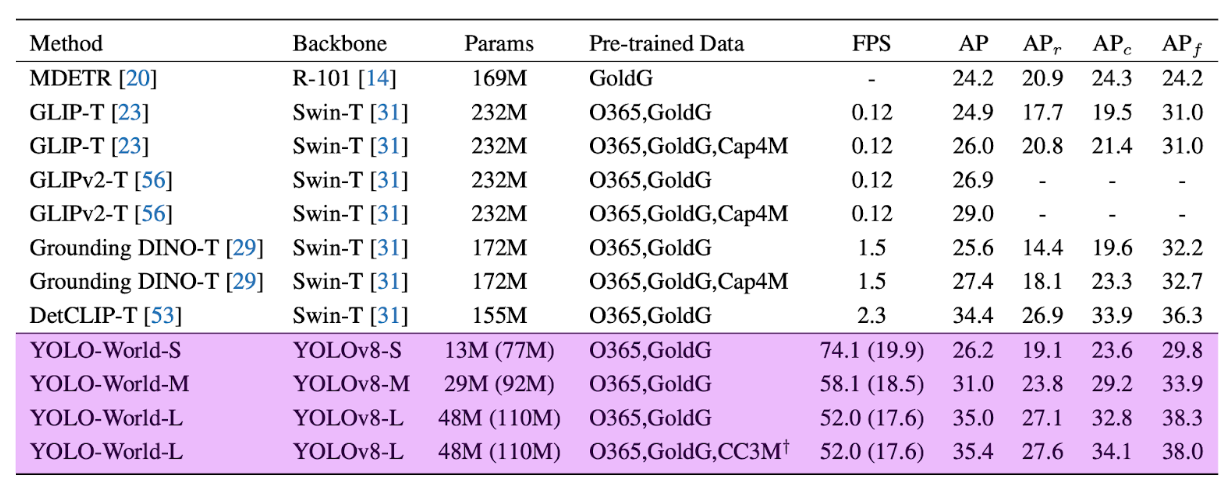
- Zero-shot LVIS: 35.4% AP at 52.0 FPS
- After fine-tuning: Remarkable performance across downstream detection and segmentation tasks
- Real-time capability: Suitable for video processing and edge deployment
The model builds on the YOLOv8 backbone and incorporates a Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss for effective vision-language modelling. This architecture enables YOLO-World to process both image features and text prompts efficiently.
YOLO-World is available through Roboflow Inference, making it easy to deploy zero-shot detection capabilities without the computational overhead of larger vision-language models.
6. GroundingDINO
GroundingDINO is a state-of-the-art zero-shot object detection model developed by IDEA Research that combines the power of transformer-based detection with grounded language understanding. Released in March 2023 and enhanced with version 1.5 in 2024, GroundingDINO excels at detecting objects through natural language descriptions without requiring any task-specific training.
The model achieves remarkable zero-shot performance: 52.5% AP on COCO without any COCO training data, and after fine-tuning, reaches 63.0% AP. On the challenging ODinW zero-shot benchmark, it sets a record with 26.1% AP, demonstrating its ability to generalize across diverse domains.
What distinguishes GroundingDINO is its dual capabilities. Beyond traditional object detection, it supports Referring Expression Comprehension (REC), identifying and localizing specific objects based on complex textual descriptions. For example, instead of detecting all chairs and people separately, then writing logic to find occupied chairs, you can simply prompt "chair with person sitting," and the model will directly detect only those instances.
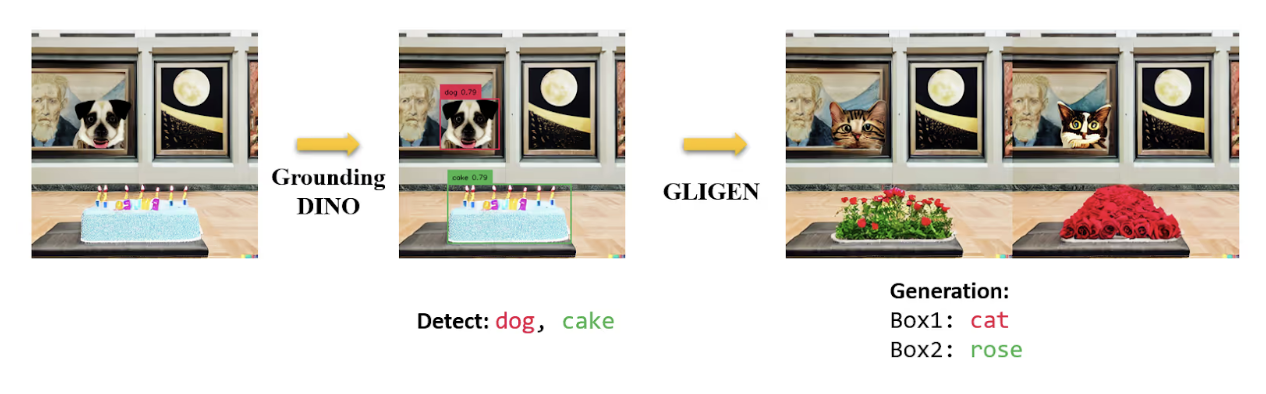
GroundingDINO 1.5 introduced two variants optimized for different scenarios:
- GroundingDINO 1.5 Pro: 54.3% AP on COCO zero-shot, 55.7% AP on LVIS-minival, setting new benchmarks for accuracy
- GroundingDINO 1.5 Edge: 36.2% AP on LVIS-minival at 75.2 FPS with TensorRT, optimized for edge devices
The architecture eliminates hand-designed components like Non-Maximum Suppression (NMS), streamlining the detection pipeline while improving efficiency. GroundingDINO's transformer-based design with Vision Transformers (ViT) enables it to effectively fuse visual and language information, making it highly versatile for various real-world tasks.
GroundingDINO is available through Roboflow Inference with support for both CPU and GPU deployment, including Raspberry Pi and NVIDIA Jetson devices.
So, which object detection model is the most usable?
RF-DETR is a breakthrough transformer-based object detection model that combines real-time speed with state-of-the-art accuracy. Its use of the pre-trained DINOv2 backbone enables it to generalize well across diverse visual domains, from autonomous vehicles to industrial inspection. Unlike traditional models, RF-DETR removes the need for anchor boxes and Non-Maximum Suppression, simplifying the detection process and reducing latency.
Benchmark results show RF-DETR-Medium achieving 54.7% mAP on the COCO dataset at just 4.52 ms latency on an NVIDIA T4, outperforming comparable YOLO variants. Moreover, on the RF100-VL domain adaptation benchmark, it reaches 60.6% mAP, proving its robustness across varied environments.
In comparison, YOLOv12 introduces efficient attention mechanisms, yielding slightly lower latency on smaller models but with somewhat reduced accuracy. Zero-shot models like YOLO-World and GroundingDINO enable flexible detection without retraining but currently lag behind RF-DETR in raw performance. NAS-optimized YOLO-NAS balances speed and quantization well but does not surpass RF-DETR’s overall accuracy-speed tradeoff.
Running RF-DETR with Roboflow Inference
Now that we've covered our list of models, let's see how to deploy the current state-of-the-art model, RF-DETR, using Roboflow Inference. Roboflow offers multiple deployment options: you can use Roboflow Workflows to build complete vision pipelines on cloud servers, or self-host the inference engine locally for full control.
In this example, we'll demonstrate how to run RF-DETR for object detection using the Inference package.
Step 1: Install Roboflow Inference
Start by installing Inference with the required dependencies:
pip install inferenceStep 2: Import Dependencies
import supervision as sv
from inference import get_model
from PIL import Image
from io import BytesIO
import requestsStep 3: Load the Image
For this demonstration, we'll use a sample image:
url = "https://media.roboflow.com/dog.jpeg"
image = Image.open(BytesIO(requests.get(url).content))Step 4: Initialize the Model
Load the RF-DETR model and run inference:
model = get_model("rfdetr-medium")
predictions = model.infer(image, confidence=0.5)
Step 5: Visualize Results
Use Supervision to annotate and display the detections:
detections = sv.Detections.from_inference(predictions)
labels = [prediction.class_name for prediction in predictions.predictions]
annotated_image = image.copy()
annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels=labels)
This simple pipeline leverages Roboflow Inference’s managed models for blazing-fast, accurate object detection without complex local setup. Whether running on NVIDIA Jetson devices or cloud GPUs, RF-DETR maintains high precision with low latency.
Conclusion: Best Object Detection Models
The 2025 object detection landscape is diverse, with models optimized for various needs. Transformer-based models like RF-DETR deliver state-of-the-art accuracy and real-time speed. Built on the powerful DINOv2 backbone, RF-DETR removes traditional anchors and Non-Maximum Suppression, achieving 54.7% mAP at under 5ms latency on COCO and 60.6% mAP on the RF100-VL benchmark, showing exceptional domain adaptability.
Attention-centric models like YOLOv12 introduce efficient area attention and R-ELAN networks, pushing single-stage detectors with slightly different speed-accuracy trade-offs. Zero-shot models such as YOLO-World and GroundingDINO remove the need for large labelled datasets, enabling flexible detection. NAS-driven YOLO-NAS balances quantization and accuracy for edge deployments.
Compared to others, RF-DETR consistently excels in handling occlusions, complex scenes, and domain shifts, making it ideal for precision-critical applications. With frameworks like Roboflow Inference and Ultralytics, transitioning from research to production is streamlined.
Compare models anytime with the Vision AI Leaderboard, explore the Object Detection Playground, or visit Roboflow Models to deploy these models instantly.
Written by Aarnav Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Oct 20, 2025). Best Object Detection Models in 2025. Roboflow Blog: https://blog.roboflow.com/best-object-detection-models/