
We are leaving this page only for reference.
We encourage you to try fully-supported Visual Language Models supported by inference, including Qwen2.5-VL.
CogVLM is a Large Multimodal Model (LMM) to which you can ask questions about images and text. For example, consider a scenario where you are aiming to identify luggage on the tarmac in an airport, a potential safety hazard. You could take regular photos of a given section of tarmac and ask CogVLM “is there luggage on the tarmac?”
In this guide, we will discuss what CogVLM is and walk through a few use cases for CogVLM in industry. We will discuss using CogVLM to enforce airport safety precautions, monitoring for defective boxes, and identifying characters in an image.
Without further ado, let’s get started!
What is CogVLM?
CogVLM is a multimodal model that answers questions about text and images. CogVLM, unlike many multimodal models, is open source and can be run on your own infrastructure. In our testing, CogVLM performed well at a range of vision tasks in our testing, from visual question answering to document OCR.
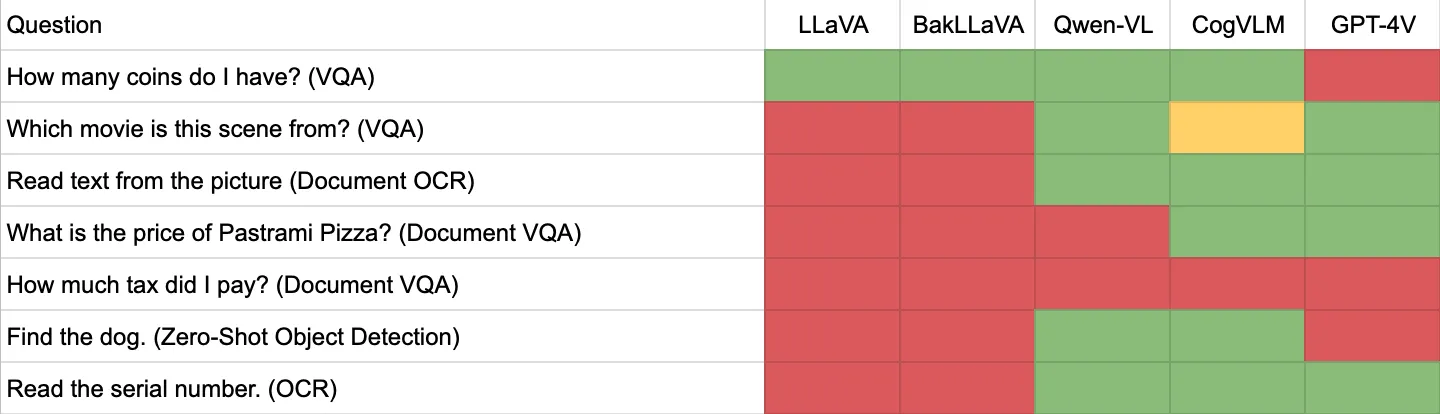
With Roboflow Inference, you can deploy CogVLM with minimal manual setup. Inference is a computer vision inference server with which you can deploy a range of state-of-the-art model architectures, from YOLOv8 to CLIP to CogVLM.
Inference enables you to run CogVLM with quantization. Quantization compresses the model, allowing you to run the model with less memory requirements (albeit with a slight accuracy trade-off). Using 4-bit quantization, you can run CogVLM on an NVIDIA T4 GPU. In our testing, requests with this configuration take around 10 seconds to process.
To learn how to deploy CogVLM on your own infrastructure, refer to our guide on how to deploy CogVLM.
CogVLM Use Cases in Industry
You can deploy a server or multiple servers within your organization to use CogVLM.
CogVLM is ideal for visual question answering where you have an image and you want to ask a question about the image.
CogVLM is particularly useful when the question you are asking is complex, such as “is there a worker close to a conveyor belt?” or “is there luggage on the tarmac?” In the first case, you can leverage the model’s ability to understand how objects relate. In the latter case, you can leverage the model’s ability to generalize to different variants of an object (luggage), a challenge for object detection models because custom logic is required.
Given the slower processing times for multimodal models like CogVLM, we recommend using the model for use cases that cannot be easily solved by fine-tuned object detection and classification models. Fine-tuned models can be run on your own hardware at (close to) real time performance, depending on the computing resources available.
Let’s talk through a few use cases to which CogVLM could be applied.
Enforcing Safety Precautions
When airport workers move luggage onto a plane, it is essential no luggage is left on the runway. This is a safety hazard. Traditionally, you would need to train a luggage detection model. This would take time given the large variation in styles and colors of luggage as well as varying camera angles or distances of objects in the frame.
You can ask CogVLM “is there luggage on the tarmac” to identify if there is luggage on a tarmac. Such a solution could be deployed while you build an accurate, fine-tuned model that works for your use case.
We asked CogVLM “Is there luggage on the airport tarmac?”, with the following image:

To which the model responded:
Yes, there are a few pieces of luggage scattered on the airport tarmac.
CogVLM successfully identified there was luggage on the tarmac, a safety hazard.
Monitoring for Product Defects
Consider a scenario where you need to assure the quality of products in a manufacturing facility. Parcels that have been damaged – dented, for example – should be flagged. A higher incidence rate of dented parcels may indicate that there is an upstream problem in packaging or another part of the distribution pipeline that needs to be addressed.
You could take photos of parcels and ask CogVLM “is this package dented?” or “does this package have a defect?” This will allow you to flag any potential issues. You can also use the output from CogVLM to gather metadata that you can use to better record the issue the model has identified. For example, if the model identified a dent in a box, you can record that there was a dent given the response returned by the model.
For example, we asked CogVLM “Is the package dented?” with the following image as context:

The model responded:
Yes, the package appears to have a dent or a crease on its side.
CogVLM successfully identified the parcel as damaged.
With that said, training your own fine-tuned object detection model may be ideal over time. This model can work in real time, unlike CogVLM. You could use CogVLM to collect data on defective packages that you can then label for use in training a fine-tuned object detection model.
Optical Character Recognition
You can also use CogVLM for Optical Character Recognition (OCR). While a traditional OCR model may be able to assist, the performance of such models varies depending on your use case. If you have struggled to retrieve accurate results from traditional OCR models, we recommend experimenting with CogVLM.
For example, consider a scenario where you need to read the serial number on a car tire. You can use CogVLM to retrieve characters on the tire. For the best accuracy, we recommend running the model without quantization.
We asked CogVLM to read the serial number on the following tire, with the prompt “Read the serial number.”:

The model returned the following response:
The serial number on the tire is 3702692432.
CogVLM successfully read the serial number.
Conclusion
CogVLM is a multimodal model that can answer questions about images and text.
In this guide, we walked through three applications of CogVLM in industry: identifying safety hazards, monitoring for product defects, and OCR.
CogVLM can be deployed on your infrastructure, unlike other multimodal models such as OpenAI’s GPT-4 with Vision and Google’s Gemini. You can run CogVLM with quantization to use the model with less RAM. There is a tradeoff in accuracy, but you should evaluate if the tradeoff is significant enough to use a larger model in testing for your use case
If you are ready to deploy CogVLM on your own infrastructure, refer to our CogVLM deployment guide. This guide walks through everything you need to deploy CogVLM.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 20, 2023). CogVLM Use Cases in Industry. Roboflow Blog: https://blog.roboflow.com/cogvlm-use-cases-in-industry/