
EdgeSAM is a segmentation model that you can use to identify the specific location of objects in images, based on the Segment Anything (SAM) model architecture released by Meta AI in early 2023. EdgeSAM reports a "40-fold speed increase compared to the original SAM", making the model more viable to run at scale.
Autodistill combines EdgeSAM with Grounding DINO, a zero-shot object detection model, to create Grounded EdgeSAM. This hybrid model enables you to identify common objects in an image (i.e. a forklift) and then generate segmentation masks. These masks label, to the pixel level, objects in an image.
In this guide, we are going to show you how to use Grounded EdgeSAM to identify objects in images and auto-label images for use in training fine-tuned models (i.e. YOLOv8). We will walk through an example where we identify people and forklifts in an image.
Here is an example result from the model:

Without further ado, let’s get started!
What is EdgeSAM?
EdgeSAM, released by the MM Lab, is an image segmentation model. Given an image, EdgeSAM aims to identify all distinct objects in an image. Each object is assigned a mask. With that said, EdgeSAM cannot assign labels or identify objects.
EdgeSAM reports significant performance gains over the original SAM model released by Meta AI as well as Efficient SAM, a faster variant of SAM. These performance gains make it viable to run EdgeSAM on a device such as a modern iPhone, which was infeasible with the original SAM. However, there is an accuracy trade-off. The original SAM model produces more precise masks.
The following chart shows the FPS and Mean Intersection Over Union (mIoU) of SAM, MobileSAM (another SAM implementation), and EdgeSAM. EdgeSAM is marked as “Ours”, where “Ours” refers to the MMLab.

You can combine EdgeSAM with a “grounding” model that can identify and assign labels to each mask. This allows you to use EdgeSAM to calculate masks and retrieve a label that you can use to understand what objects are in an image.
Note that there will be a performance tradeoff if you use a grounding model with EdgeSAM. For this guide, we will use Grounding DINO, which has a low FPS. This is manageable because we are using Grounding DINO and EdgeSAM to auto-label a dataset. We can then train a fine-tuned segmentation model that can identify classes of interest that will run at multiple FPS.
EdgeSAM Use Cases
Given EdgeSAM is significantly faster than SAM, this opens up many opportunities for incorporating segmentation in applications where this may previously have been infeasible due to speed requirements. EdgeSAM has been tested on iPhones, too, achieving 50+ FPS in benchmarks run by the MMLab team, which opens up mobile use cases.
EdgeSAM could be used for:
- Auto-labeling images for use in training fine-tuned segmentation models;
- Zero-shot segmentation, when combined with a grounding object detection model (i.e. Grounding DINO);
- Removing backgrounds from images, and more.
You can integrate EdgeSAM directly into your business logic through applications like zero-shot segmentation (with grounding), or use EdgeSAM to help you label data for use in training a specialized segmentation model.
In this guide, we will focus on using EdgeSAM to auto-label data.
Step #1: Install Autodistill Grounded EdgeSAM
First, we need to install Autodistill Grounded EdgeSAM. This model is a combination of Grounding DINO, a popular zero-shot object detection model, and EdgeSAM. Grounding DINO will identify objects, then EdgeSAM will assign segmentation masks for each object.
Run the following command to install the required dependencies for this project:
pip install autodistill autodistill-grounded-edgesamNow we are ready to use the model!
Step #2: Run Inference with Grounded EdgeSAM
We can use Grounded EdgeSAM to identify the location of objects in an image. Let’s run the model on the following image and identify all people and forkifts:

Create a new Python file and add the following code:
from autodistill_grounded_edgesam import GroundedEdgeSAM
from autodistill.detection import CaptionOntology
from autodistill.utils import plot
import cv2
base_model = GroundedEdgeSAM(
ontology=CaptionOntology(
{
"person": "people",
"forklift": "forklift",
}
)
)In this code, we import the required dependencies. Then, we initialize a Grounded EdgeSAM model. Above, we set an ontology which specifies what objects we want to identify.
An ontology has two parts: the text prompt you want to send to the model and the class name you want to save for associated predictions. For example, in the ontology above we identify people with the prompt “person” and save the label “people”. We also identify forklifts with the prompt “forklift” and save the associated label “forklift”.
Substitute the ontology for values that are relevant to your project.
Next, add the following code:
results = base_model.predict("logistics.jpeg")
plot(
image=cv2.imread("logistics.jpeg"),
classes=base_model.ontology.classes(),
detections=results
)
In this code, we run inference on a file called “logistics.jpeg”. We then show the results on a file.
When you first run the code above, EdgeSAM will be installed locally and the model weights will be downloaded. This will take a few moments. Then, the weights will be cached for later use.
As mentioned earlier, inference will be slower than EdgeSAM alone because we are combining two models: Grounding DINO and EdgeSAM. Grounding DINO is a relatively slow model. With that said, you can use your labeled data to train a smaller model that will be suitable for running on the edge.
Let’s run our model:

Autodistill Grounded EdgeSAM was successfully able to identify the person and the forklift. The mask is not fully precise around the forklift, but the mask is tight around the person
Step #3: Label a Folder of Images with Grounded EdgeSAM
You can label a folder of images for use in training a model with Grounded EdgeSAM. The result will be a dataset with the labels you need to train a segmentation model.
To do so, add the following code to the end of the script you wrote in the last step:
base_model.label(input_folder="./images", output_folder="./output", extension=".jpeg")Above, replace the input folder with the folder that contains images you want to label. Replace the output folder with the name of the folder where you want your labeled data to be saved.
The amount of time the code above takes to run will depend on how many images you have in your dataset as well as the hardware on which you are running Grounded EdgeSAM. When you run the code, your labeled data will be saved to the specified output folder.
You can then upload this data into Roboflow for manual inspection. The Roboflow Annotate tool can help you identify annotation issues and fix them. You can also use Roboflow’s dataset management features to prepare a dataset with augmentations for training.
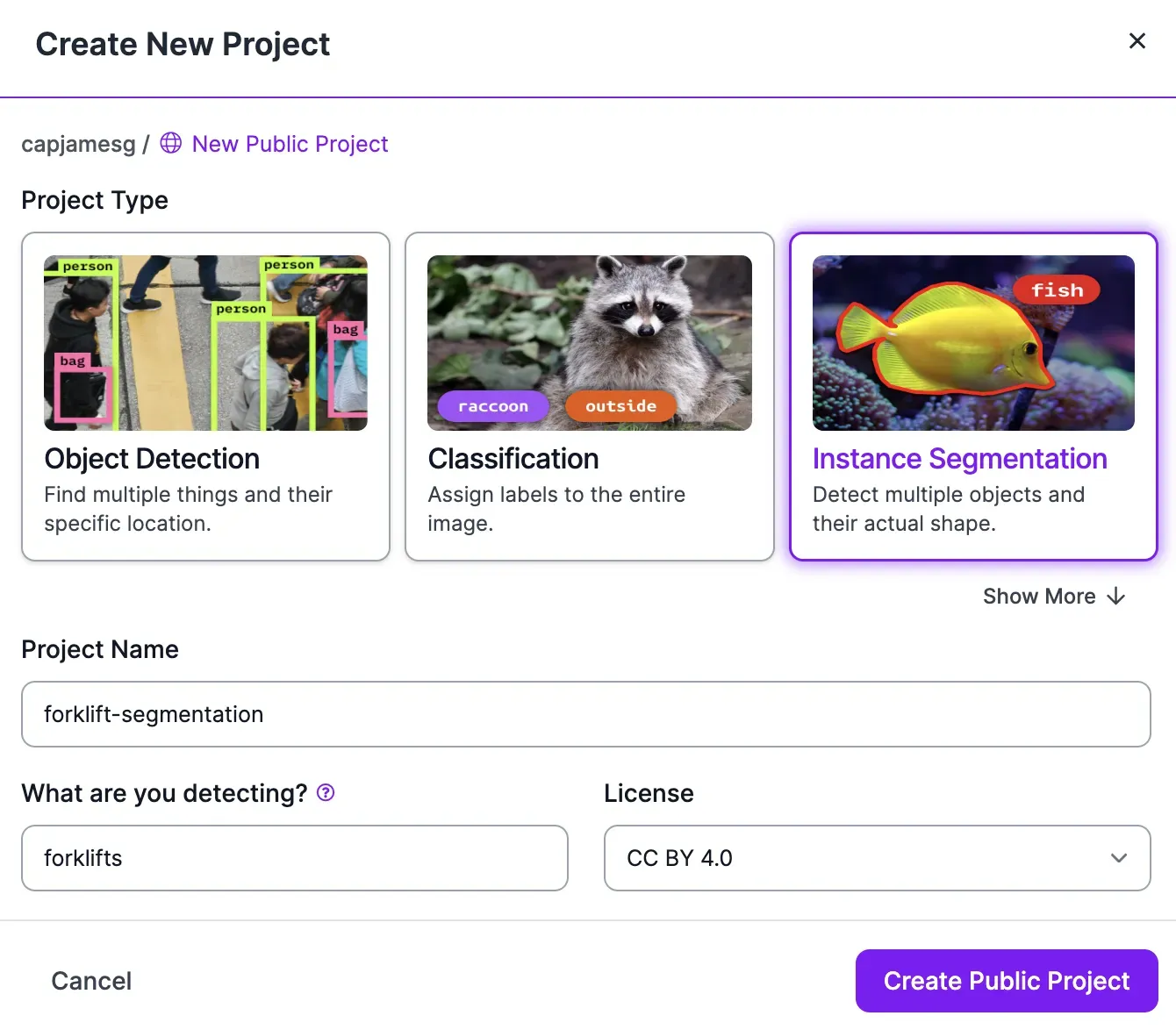
To inspect and correct your annotations, first create a Roboflow account. Then, create a project from the Roboflow dashboard:
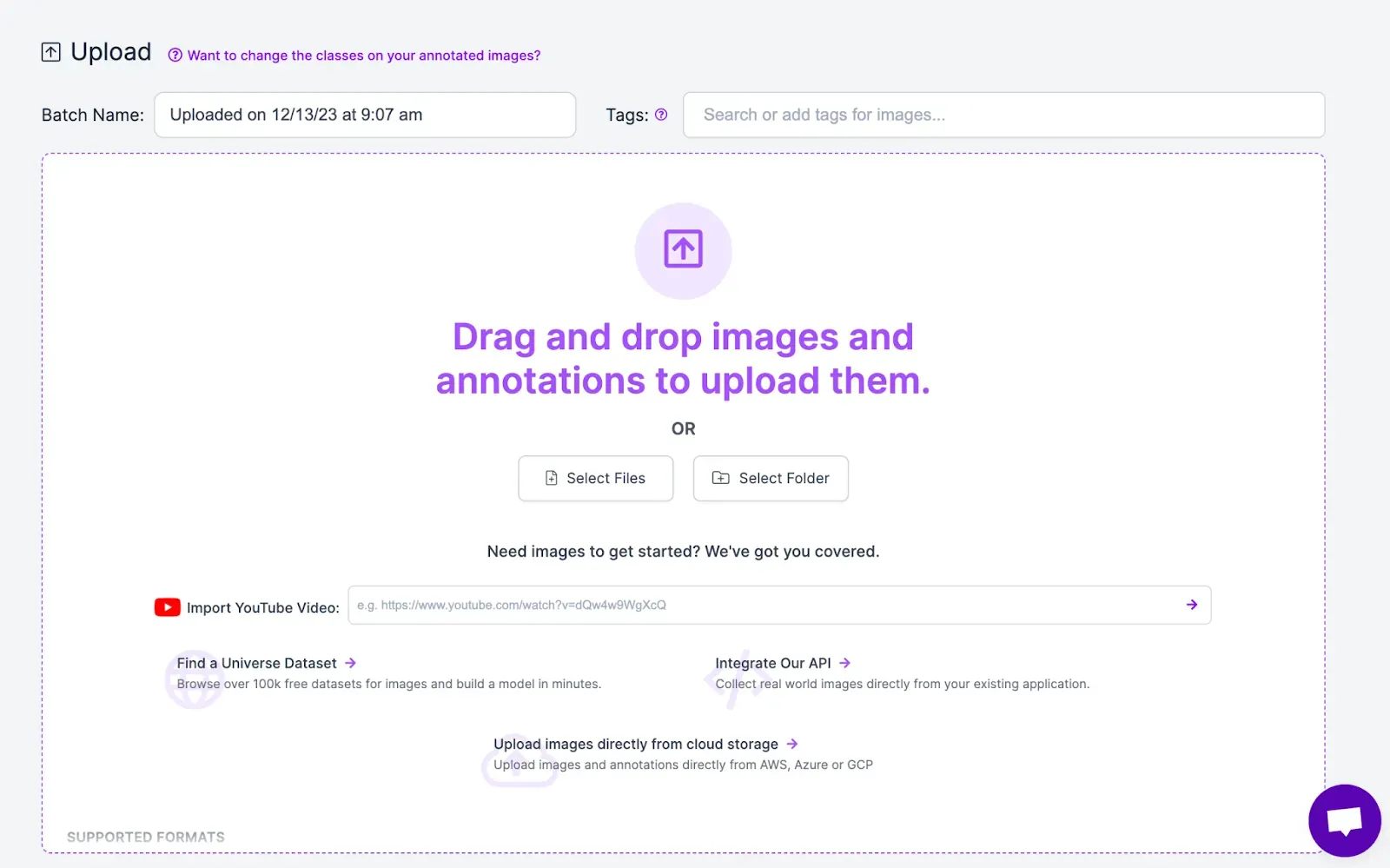
You can then upload your labeled dataset into Roboflow for manual inspection:
You can then open an image in Roboflow Annotate to inspect annotations.
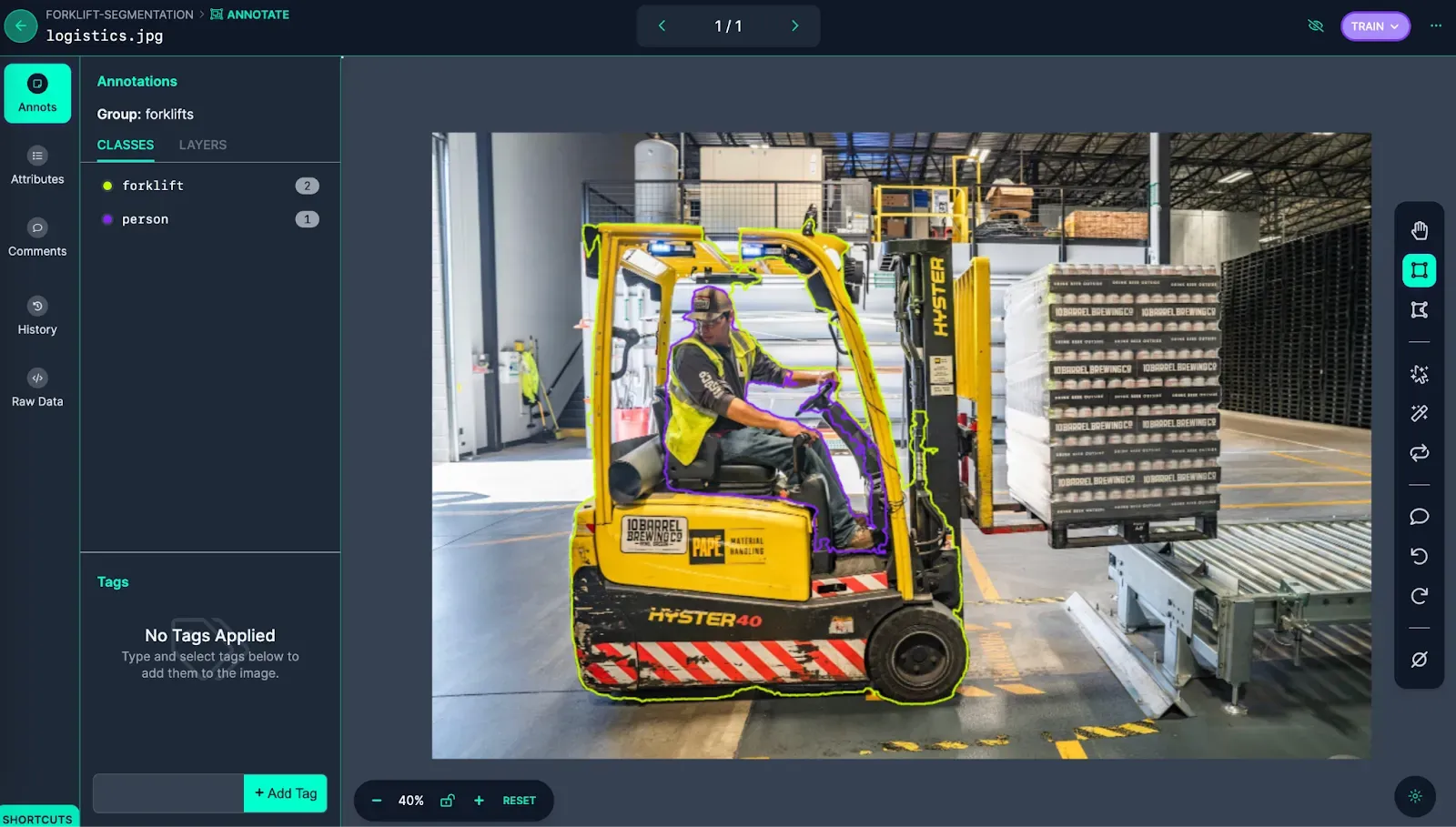
If annotations are mislabeled, you can remove them. If annotations are imprecise, you can use the SAM-powered labeling assistant tool. This tool lets you use Meta AI’s SAM to label regions in an image. You can click where you want to annotate to create a label. Learn more about the Roboflow SAM-assisted labeling feature.
If you train your model on Roboflow, you will have access to an infinitely-scalable API through which you can run your model. You can also run models on your own hardware using Roboflow Inference, a high-performance computer vision inference server trusted by enterprises around the world.
Conclusion
EdgeSAM is a segmentation model. EdgeSAM is faster than the original Segment Anything model which was released by Meta AI in early 2023. But, the masks from EdgeSAM are less accurate.
In this guide, we demonstrated how to use Grounded EdgeSAM, a combination of Grounding DINO and EdgeSAM, with Autodistill. We used Grounded EdgeSAM to identify the location of a person and a forklift in an image. We then showed how to use Grounded EdgeSAM to auto-label images for use in training a fine-tuned model.
Now you have all that you need to use Grounded EdgeSAM!
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 13, 2023). How to Use Grounded EdgeSAM. Roboflow Blog: https://blog.roboflow.com/how-to-use-grounded-edgesam/