
Computer Vision (CV) is a field of artificial intelligence and computer science that focuses on enabling computers to see, interpret, and understand visual information from the world, similar to how humans use their eyes and brain to understand images and videos.
At its core, computer vision involves analyzing and processing images or video streams to extract meaningful information, such as identifying objects, detecting movements, recognizing faces, reading text, or understanding scenes.
In this blog, we explore the key computer vision tasks, including object detection, image classification, image segmentation, multimodal analysis, keypoint estimation, depth estimation, and optical character recognition. And demonstrate how you can easily perform them using Roboflow Workflows.
What is Roboflow Workflows?
Roboflow Workflows is a low-code, open-source platform that streamlines the building and deployment of vision AI applications. With Workflows, you can visually design computer vision pipelines by connecting multiple tasks together as modular blocks. The video below demonstrates all the possible blocks that can be added to a Roboflow workflow:
Capabilities of Roboflow Workflows
- Visual pipeline design with easily searchable and placeable tasks
- Connect multiple computer vision tasks as modular blocks
- Low-code and customizable with optional Python integration
- Built-in preprocessing, post-processing, and visualization blocks
- Real-time image and video stream processing
- Open-source and extensible with custom models
- Scalable deployment on local, cloud, or edge devices
- Monitoring and debugging with intermediate outputs
- Collaboration and sharing of workflows
Example of a Roboflow Workflow
The example below showcases a Roboflow Workflow that combines Object Detection and Image Segmentation (using the Segment Anything 2 model) blocks, along with other Roboflow blocks, to blur the background of an image:
You can try this specific workflow here.
Discover Key Computer Vision Tasks
The following are key computer vision tasks performed using Roboflow Workflows.
Object Detection
Object detection is a computer vision task that focuses on identifying and locating objects within an image or video. It not only classifies the objects present but also determines their precise positions.
Typically, object detection relies on a machine learning model to predict bounding box coordinates and labels for the objects. Such a model can identify multiple objects within a single image or frame.
The Roboflow Workflow below demonstrates RF-DETR, a real-time transformer-based object detection model, detecting a ‘car’ in an image.
The object detection workflow also incorporates visualization blocks, employing Bounding Box Visualization to draw bounding boxes and Label Visualization to display object labels with their confidence scores:
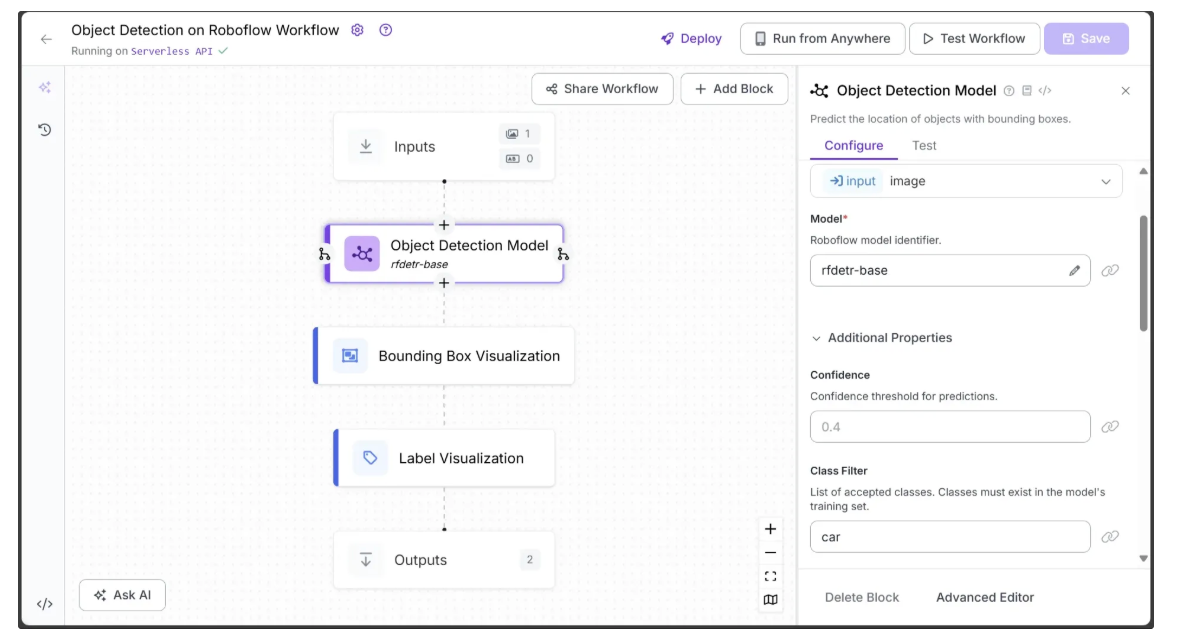
The input and output of the workflow are shown below:

In the output above, the object detection model detected only a car, as ‘car’ was the only class specified in the Class Filter parameter of RF-DETR. This parameter, available in various object detection models such as RF-DETR and YOLO variants, controls which objects the model detects during inference.
The Class Filter can be set to a single class, a list of classes, or left unrestricted to detect all classes. All specified classes must be part of the COCO dataset classes.
- If a single class from the COCO dataset is provided, only objects of that class are detected.
- If no class is specified, all objects in the image belonging to the COCO dataset are detected.
- If a list of COCO classes is provided, only objects belonging to those classes are identified.
You can also train object detection models such as RF-DETR and YOLO on custom datasets to detect objects beyond the predefined COCO classes. This blog explains how to train RF-DETR on a custom dataset, while another blog covers training YOLO on a custom dataset.
Roboflow Workflows also provides a variety of object detection models, allowing you to choose the best one for different use cases and specializations.
Use Cases of Object Detection
- Detecting pedestrians, vehicles, and obstacles in autonomous driving
- Monitoring public spaces for security and surveillance
- Detecting defects or anomalies in manufacturing and quality control
- Identifying tumors or abnormalities in medical imaging
- Tracking objects and players in sports analytics
Image Classification
Image Classification is a computer vision task in which a model is trained to assign a label or category to an entire image. Unlike object detection, which identifies where objects are in an image (using bounding boxes), image classification focuses solely on what is present in the image.
Image classification can be single-label, where each image is assigned one category, or multi-label, where an image can belong to multiple categories simultaneously.
Roboflow Workflows provides blocks for both single-label and multi-label classification.
Single-Label Classification
The Roboflow Workflow below demonstrates the use of a pretrained single-label classification model from Roboflow Universe, called bird-species-detector/851, which can identify the species of a bird in an image.
The single-label classification workflow also employs the Classification Label Visualization block to display the predicted label along with its confidence score on the image:
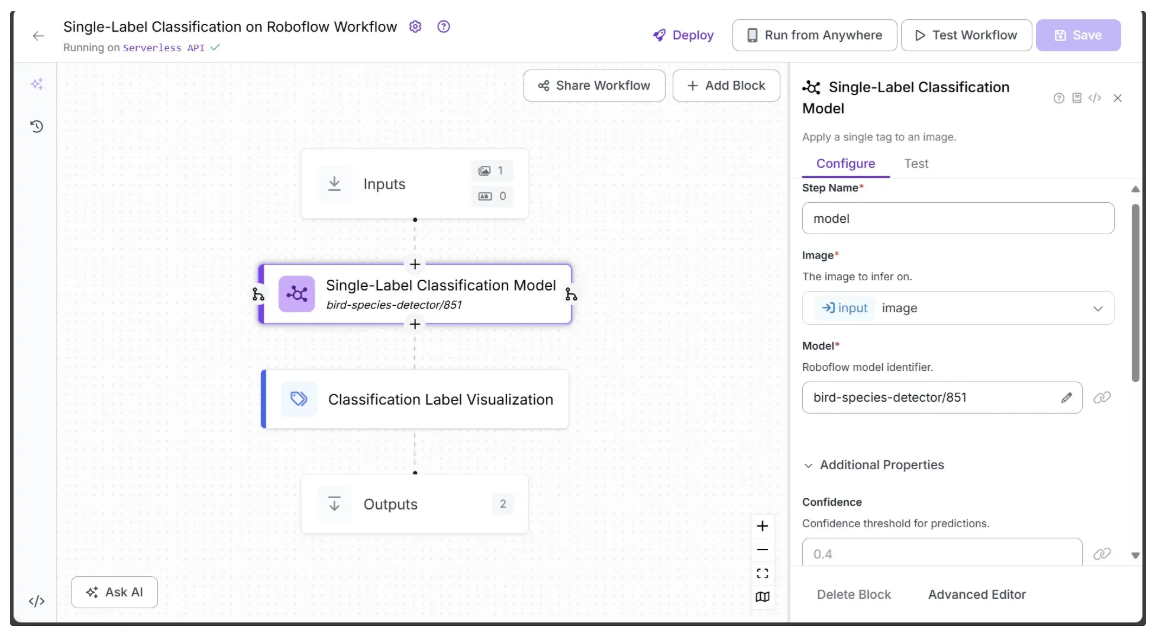
The input and output of the workflow are shown below:

The output contains a single classified label, the bird species, along with its confidence score, both of which are displayed by the Classification Label Visualization block.
Multi-Label Classification
The Roboflow Workflow below demonstrates the use of a multi-label classification model from Roboflow Universe, called power-grid-inspection-wknni/1, which can identify multiple power grid components in an image.
The multi-label classification workflow also employs the Classification Label Visualization block to display the predicted labels along with their confidence scores on the image:
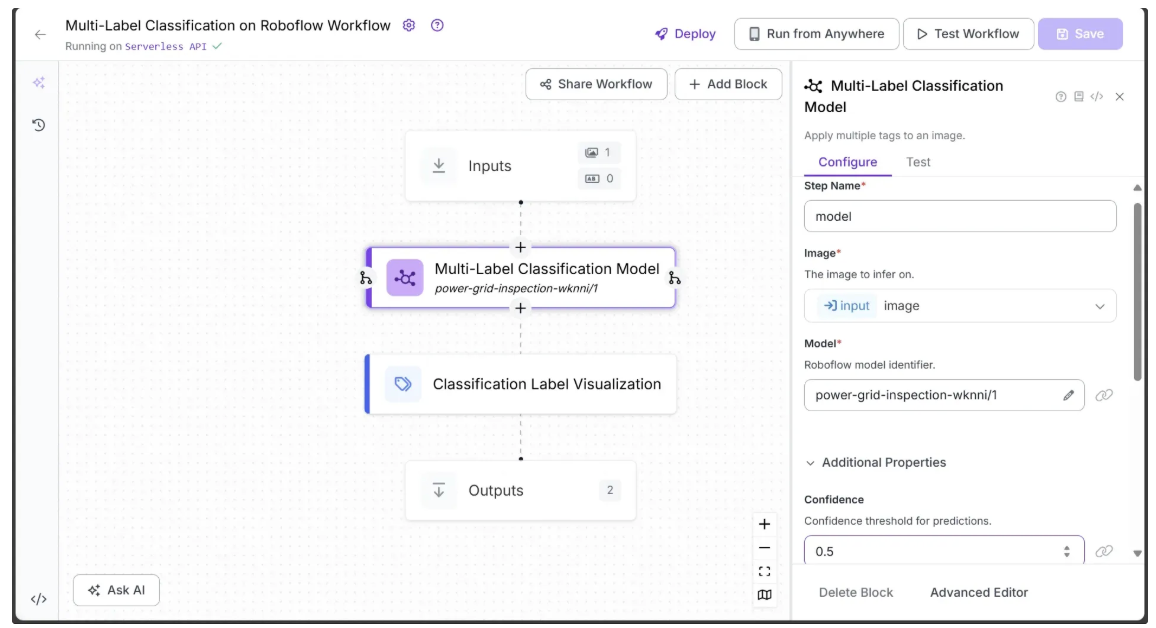
The input and output of the workflow are shown below:

The output contains multiple classified labels corresponding to power grid components, along with their confidence scores, all of which are displayed by the Classification Label Visualization block.
Roboflow Universe offers a variety of pretrained classification blocks, including both single-label and multi-label options. You need to star it to make it available in your workflow.
Use Cases of Image Classification
- Diagnosing diseases by classifying medical images like X-rays or MRIs
- Categorizing products in e-commerce platforms for search and recommendation
- Detecting spam or inappropriate content in images on social media
- Identifying plant species or crop health in agriculture
- Facial recognition for authentication
Image Segmentation
Image segmentation is a computer vision task that divides an image into segments or pixel groups for detailed analysis, assigning a label to each pixel rather than labeling the entire image or using bounding boxes, as in classification or detection. This enables a computer to precisely identify the shape and boundaries of objects within an image.
In computer vision, image segmentation is performed using models such as Segment Anything Model 2 (SAM 2), YOLOv11 Instance Segmentation, and others.
The Roboflow Workflow below demonstrates the use of the YOLOv11 Instance Segmentation model to perform image segmentation on an image.
The image segmentation workflow also employs the Polygon Visualization block to outline the segmented regions in the image:
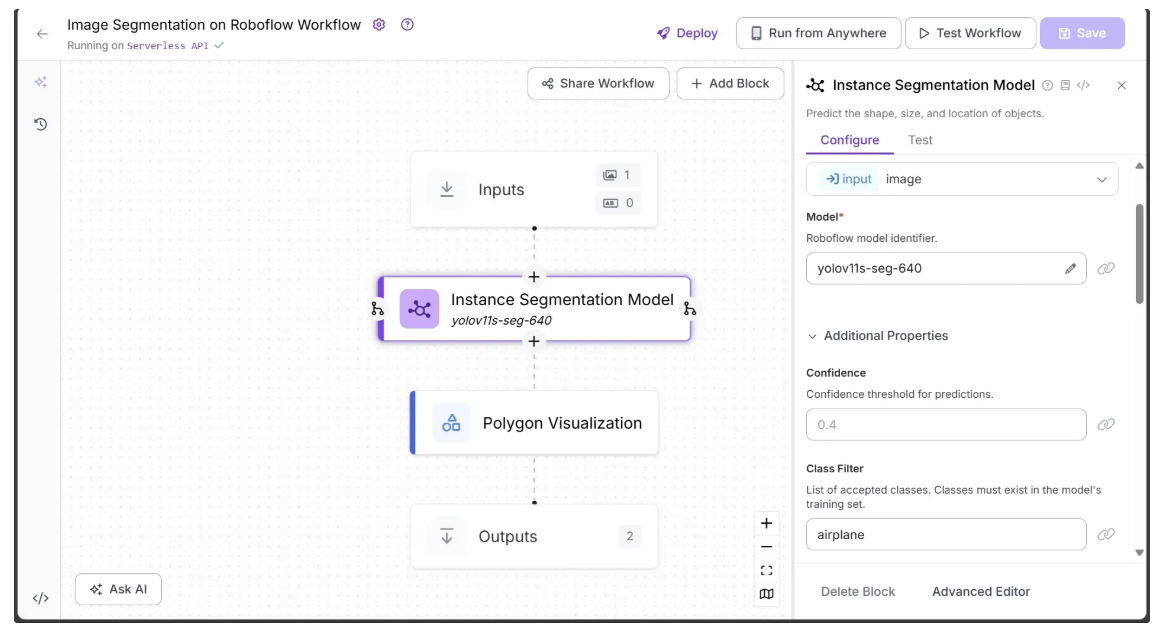
The input and output of the workflow are shown below:

In the output above, the instance segmentation model segments only the airplane in the image, as ‘airplane’ was the only class specified in the Class Filter parameter of the YOLOv11 Instance Segmentation model.
Similar to the object detection variants of YOLO, the Class Filter parameter in YOLOv11 Instance Segmentation (if used) must correspond to COCO dataset classes.
To detect additional classes, you can fine-tune segmentation models on a custom dataset. A variety of such fine-tuned segmentation models are available on Roboflow Universe.
Use Cases of Image Segmentation
- Detecting and outlining tumors, organs, or tissues in medical imaging
- Separating foreground objects from background for photo editing
- Segmenting vehicles, pedestrians, and objects for traffic analysis and safety
- Pixel-level defect detection in manufacturing for quality control
Multimodal Analysis
Large Language Models (LLMs) such as GPT-4o, Google Gemini, and Anthropic Claude have evolved beyond simple text processing. These models are now multimodal, capable of understanding context and integrating various types of input, including images and video alongside text.
This capability allows them to address a wide range of computer vision tasks, including object detection, text recognition, captioning, visual question answering, and more, while also incorporating reasoning abilities.
LLMs with these multimodal capabilities are collectively referred to as Large Multimodal Models (LMMs), and using their reasoning abilities to perform complex tasks is known as Multimodal Analysis.
The Roboflow Workflow below demonstrates the use of Google Gemini, along with a provided Gemini API key, to perform image captioning:
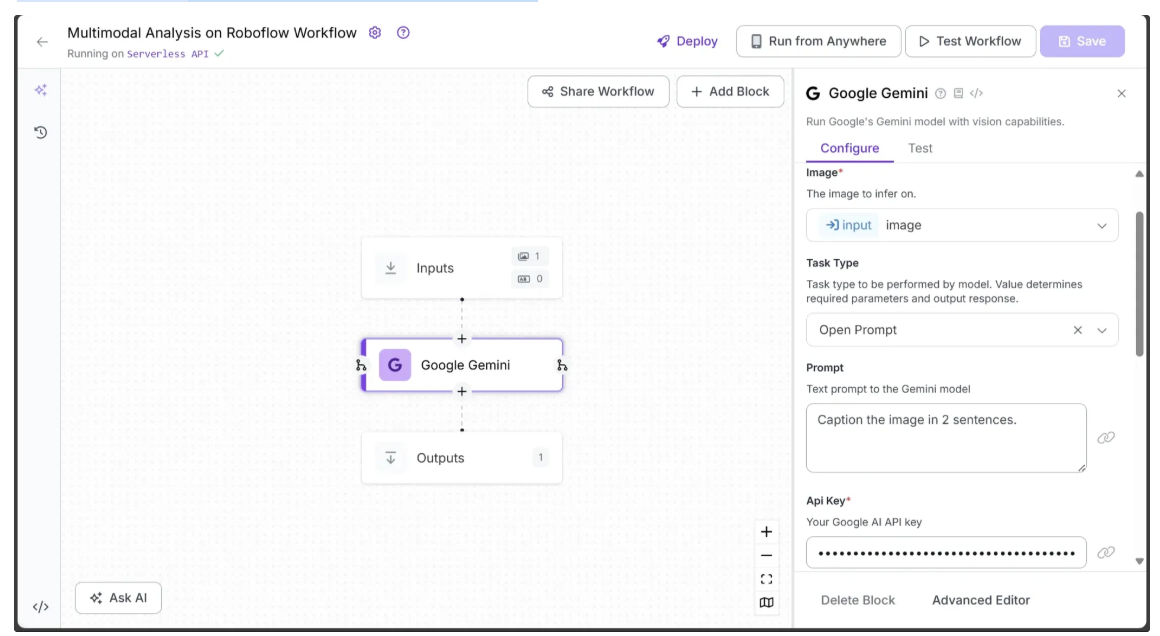
Now running the multimodal analysis workflow on the image below:

Produces the output below:
"This is a well-lit kitchen featuring a white farmhouse sink with a matte black faucet under two windows, allowing natural light to flood the space. Wooden countertops and open shelves adorned with glassware and mugs add warmth and character to the room."
Similar to Google Gemini Blocks, Roboflow Workflows offers a variety of LMMs, such as GPT-4o, QwenVL, CogVLM, and many others, which can be easily switched in and out with no coding required to perform multimodal analysis.
Use Cases of Multimodal Analysis
- Answering questions about images by combining visual content with text queries
- Generating detailed captions for images using both visual and textual context
- Performing visual reasoning tasks, such as identifying relationships between objects in an image
- Interactive AI assistants that understand both images and text to provide insights or explanations
- Translating visual content into text descriptions for accessibility purposes
Keypoint Estimation
Keypoint detection is a computer vision task that identifies specific, meaningful points or “landmarks” within an image rather than detecting entire objects. These landmarks typically represent structural or functional parts of an object, such as body joints in pose estimation, facial features in recognition, or anatomical points in medical imaging.
The process usually involves passing an image through a deep learning model to extract keypoints. Models like YOLO-NAS make this more efficient by combining fast object detection with keypoint estimation in a single pipeline.
For example, YOLO-NAS can detect a person in an image and simultaneously output the positions of their elbows, knees, and other body joints, enabling applications like human pose estimation, gesture recognition, and augmented reality.
The Roboflow Workflow below demonstrates the use of YOLO-NAS Pose as a keypoint detection model on an image.
The keypoint estimation workflow also uses the Keypoint Visualization block to draw skeleton connections that represent the human body’s structure on the image:
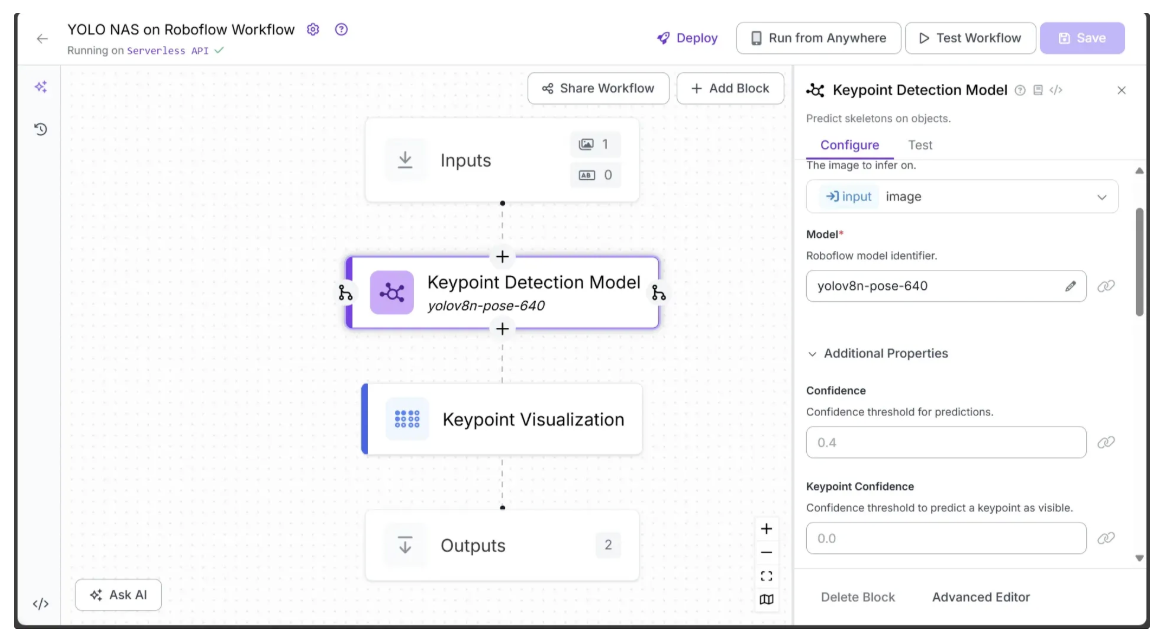
The input and output of the workflow are shown below:

In the output above, the Keypoint Visualization block uses keypoints detected by YOLO-NAS Pose to draw edges forming skeleton connections, illustrating various parts of the tennis player’s body, such as the nose, eyes, shoulders, elbows, hips, and more. It can also be used to draw vertices directly on the detected keypoints.
Use Cases of Keypoint Estimation
- Human pose estimation for activity recognition and sports analytics
- Tracking body movements in physical therapy and rehabilitation
- Gesture recognition for human-computer interaction and AR/VR applications
- Facial landmark detection for expression analysis, emotion recognition, and facial animation
- Motion capture for film, animation, and gaming industries
Depth Estimation
Depth estimation is a computer vision task aimed at determining the distance of objects in an image from the camera. Unlike typical object detection or segmentation, which identifies what and where objects are, depth estimation predicts how far each point or pixel in the image is from the camera. This is often represented as a depth map, where brighter pixels indicate closer objects and darker pixels indicate more distant objects.
The Roboflow Workflow below demonstrates the use of the Depth Estimation block to estimate the depth of an image. Unlike the workflows above, workflows utilizing the Depth Estimation block must be run on a Dedicated Deployment or a Local Device using an Inference Server.
You can run the workflow on a local device, as shown below, by forking the depth estimation workflow and following the instructions in the 'Setup Your Roboflow Workflow' section of this blog.
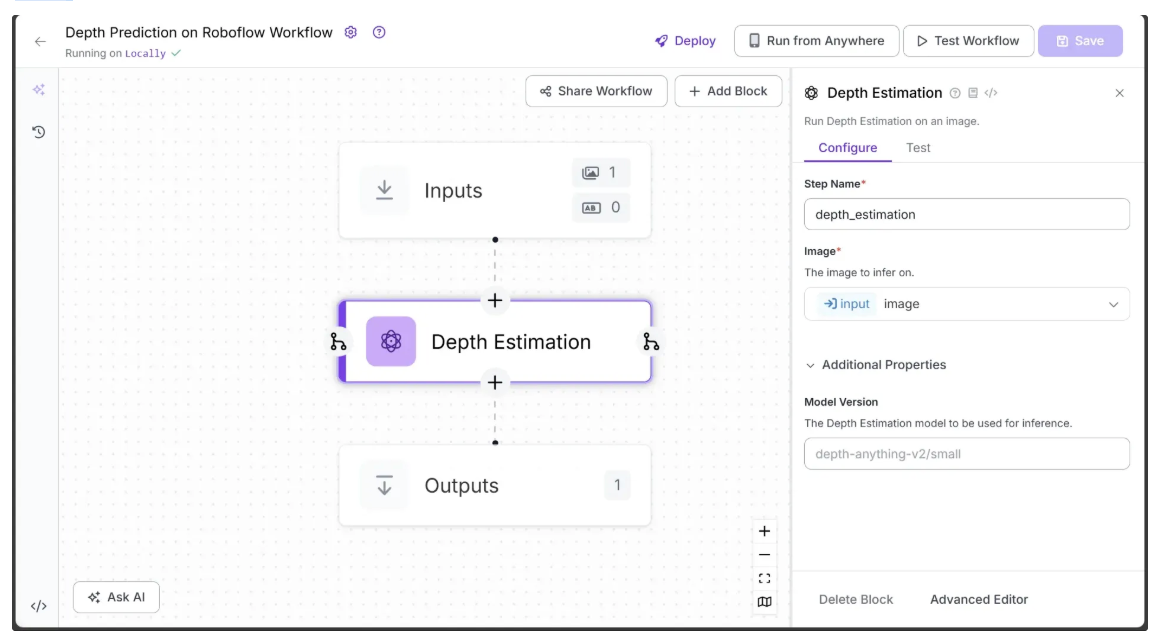
The input and output of the depth estimation workflow are shown below:

In the output above, objects closer to the camera, such as the striker and the ball, appear brighter on the depth map compared to objects farther away, like the referee, defenders, and the striker’s teammates.
Use Cases of Depth Estimation
- Enabling autonomous vehicles to perceive distances and avoid obstacles
- Enhancing augmented reality (AR) applications by understanding scene depth
- Improving camera focus and background blur effects in photography
- Scene understanding in surveillance and security systems
- Object size and distance measurement in industrial inspection
Optical Character Recognition
Optical Character Recognition (OCR) is a computer vision task that detects and extracts text from images, scanned documents, or video frames and converts it into machine-readable text.
OCR serves as a bridge between visual text and digital data, enabling machines to accurately interpret and process the text that humans perceive in images.
Roboflow Workflows provides various vision-capable workflow blocks that can perform OCR tasks. These include, but are not limited to, Florence-2, Qwen2.5-VL, and Google Gemini.
The Roboflow Workflow below demonstrates the use of Google Gemini, along with a provided Gemini API key, as a workflow block to perform OCR on an image.
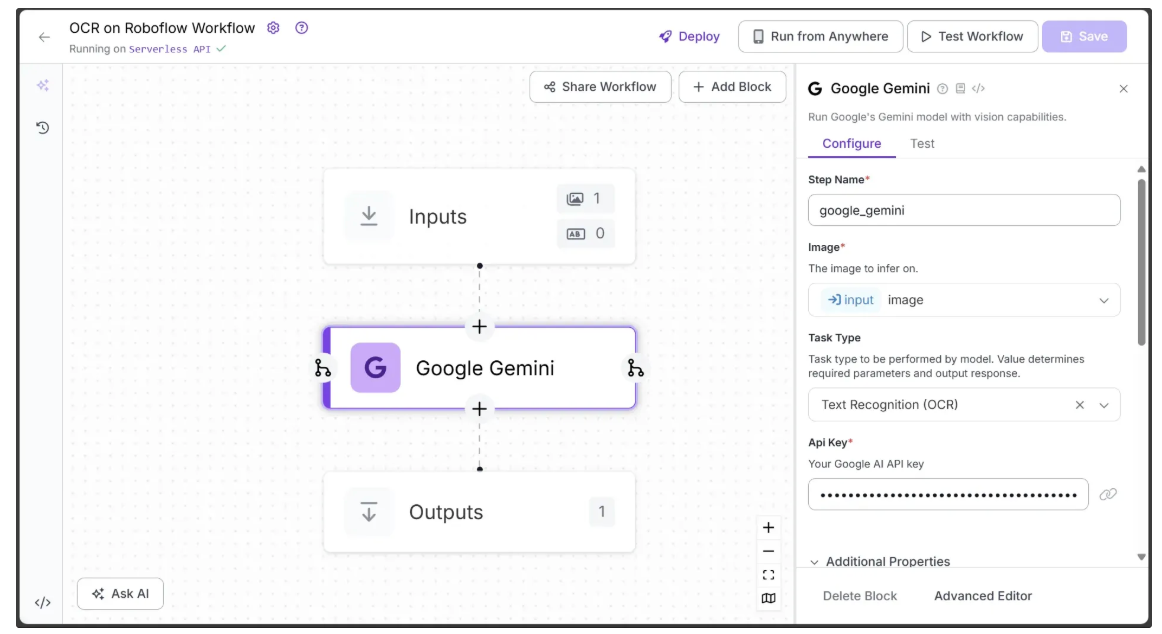
Now running the ocr workflow on the image below:

Produces the output below:
Further information may be obtained M.A., Fellow and Lecturer in Chemistry, from Prof. A. Gilligan, D.Sc., Department Leeds, and from Mr. A. H. Worrall, M.A., College, Jersey.
In the output above, Google Gemini successfully performs OCR on the text in the original image with high accuracy, even preserving the correct line breaks and spacing.
Use Cases of Optical Character Recognition
- Converting printed books, newspapers, and archives into searchable digital formats
- Automating data entry from receipts, invoices, and structured forms
- Extracting and verifying text from identity documents like passports and licenses
- Supporting accessibility tools by reading text from images for the visually impaired
- Translating text in real time from signs, menus, or documents
Exploring Key Tasks in Computer Vision: Conclusion
In this blog, we explored the major tasks in computer vision, including object detection, image classification, segmentation, multimodal analysis, keypoint estimation, depth estimation and Optical Character Recognition.
With Roboflow Workflows, these complex tasks can be executed efficiently using no-code pipelines, enabling developers and businesses to leverage vision AI without extensive coding expertise.
To learn more about building with Roboflow Workflows, check out the Workflows launch guide.
Written by Dikshant Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Sep 22, 2025). Key Computer Vision Tasks. Roboflow Blog: https://blog.roboflow.com/key-tasks-in-computer-vision/