
Over the last year, thousands of custom computer vision models have been trained with Roboflow Train and millions of inferences have been made via Roboflow Deploy.
Recently, we took a big step back to incorporate advancements in computer vision research and our learnings from working with our users into new training and deployment infrastructure.
Roboflow Train Now Has Fast and Accurate Model Types
Automatic machine learning solutions like Roboflow Train derive most of their value through abstracting and automating decisions about machine learning (like whether or not and how to anneal your model's learning rate during training). That said, sometimes it is advantageous to expose some of those decisions - and we made the call to allow users to choose their model size.
You can learn more about how to think about model sizes in this blog post on Roboflow Train model size tradeoffs.
Roboflow Train is Free to Try
Previously, Roboflow Train was only available to paying Roboflow customers but now you are able to use Train credits to build models using our managed solution with only a few clicks.
New users will receive three Roboflow Train Fast credits to train on our cloud GPUs. This means that you can kick the tires on Roboflow Train and Roboflow Deploy before making any decisions about it. Try Roboflow for free today.
If you are interested in Roboflow Train Accurate, please reach out to our Sales team for more information.
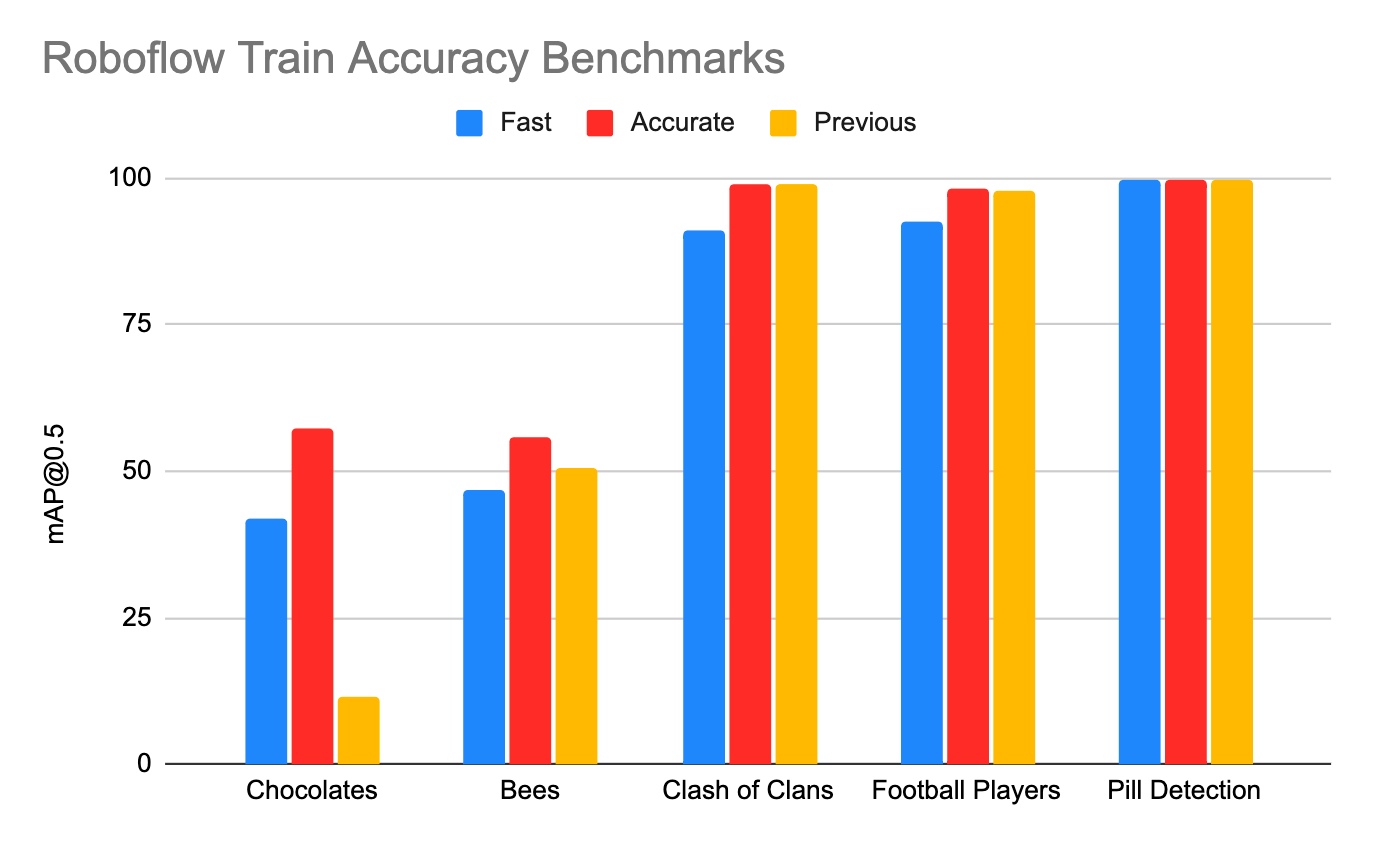
Roboflow Train is Now Faster and More Accurate
When making a computer vision model, the two primary axes of interest are model accuracy and model inference speed. With our new training infrastructure, most custom tasks will see an improvement in modeling accuracy.
On the inference front, the new Roboflow Train Fast model offers users the ability to accelerate inference speeds across deployment targets.
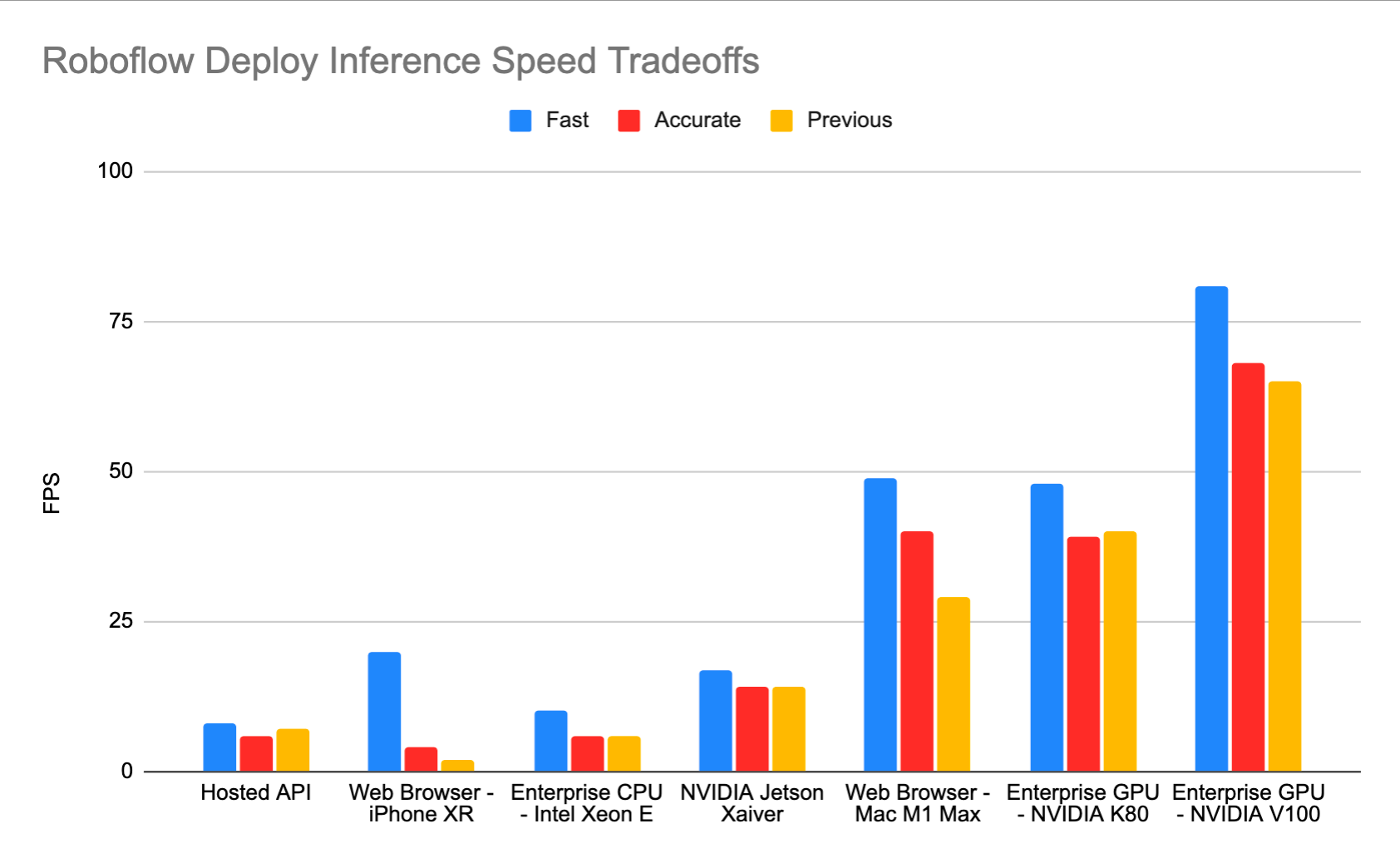
Throughput vs Latency
At first glance, this might look dire for the Hosted API. Why would you send images across the Internet to get a prediction back if it's going to be so slow? The answer is throughput.
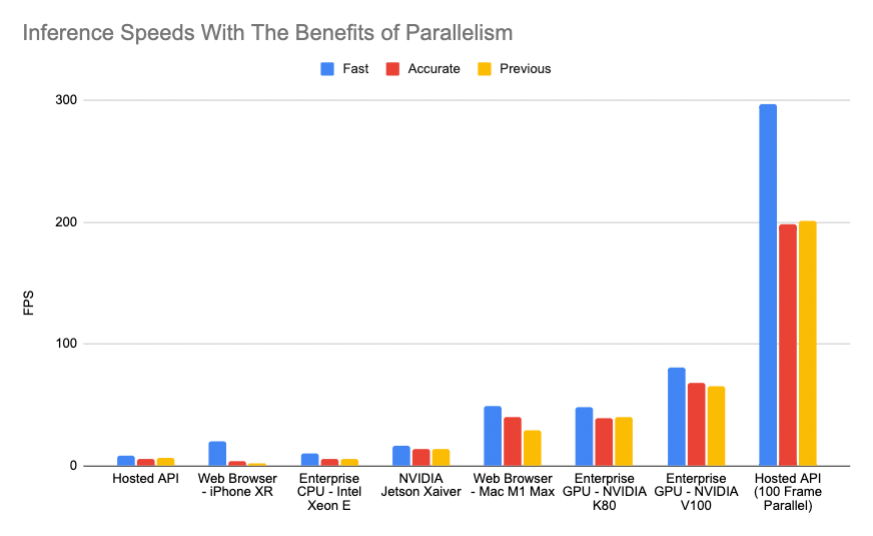
Because the hosted API automatically scales up to infinity (it will propagate your model to additional machines on-demand), you can send many images at it in parallel to get inference speeds bounded only by your Internet connection. You can see an example of this in our Python webcam demo on Github ("async mode") which runs at 30+ fps using the Hosted API and a small buffer to handle parallel requests.
It also means that your model can serve many clients and handle spiky traffic loads (including the type of insane load you might see if your project gets featured on something like Hacker News) which is incredibly difficult when running on your own hardware without having to pay an arm and a leg for GPUs that sit idle most of the time.
Conclusion
At Roboflow, we have been striving to make computer vision easier and more streamlined. For us, that means keeping up with the pace of computer vision research, listening to the problems are users are having, and sunsetting old routines when new ones are clearly better.
We are excited to release the newest version of Roboflow Train and Deploy.
Happy training! And of course, happy inferencing!