
Vision teams now have two powerful tools: fast, proven object detection models, and a new wave of vision-language models that can reason about what they see. That creates a real decision point: should you build with traditional detection, or reach for a VLM?
The wrong choice can drive up costs, add latency, or leave you with a great demo that never ships. In this guide, we break down the trade-offs with a practical framework grounded in how these models actually behave in production.
Understanding Object Detection vs Vision-Language Models
Object detection models are specialized neural networks trained to identify and locate specific objects in images. Popular architectures include YOLO (You Only Look Once), Faster R-CNN, EfficientDet, and newer models like RF-DETR. These models output bounding boxes with class labels and confidence scores.
How they work: You feed an image into the model, and it returns structured data like:
"predictions": [
{
"x": 36,
"y": 65,
"width": 436,
"height": 269,
"confidence": 0.92,
"class": "raccoon",
"class_id": 1,
"detection_id": "c929d3d0-b78f-4064-96a9-9f072df7ca34"
}
]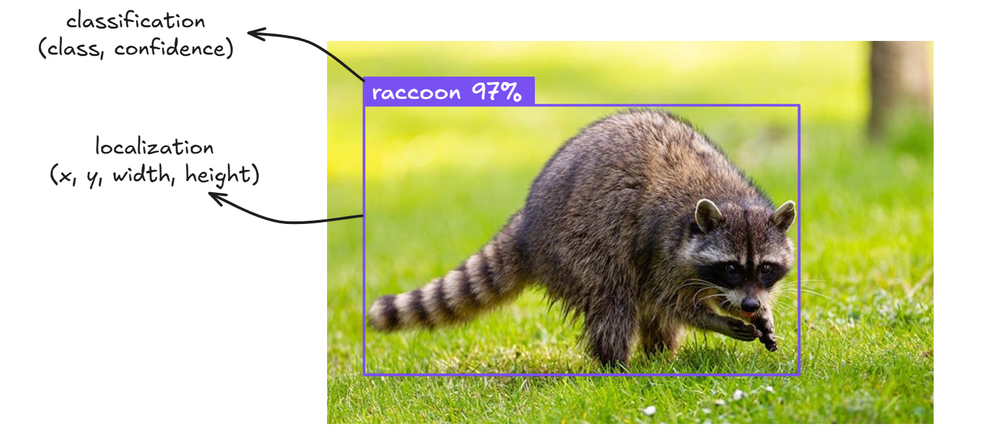
For example, using RF-DETR, you can deploy a custom-trained model that processes images and returns precise bounding boxes in milliseconds. These models are deterministic, meaning the same image produces virtually identical results every time.
Vision-language models are multimodal AI systems that understand both images and text. They can answer questions about images, describe scenes, and perform tasks through natural language instructions. Examples include GPT-5, Claude, Google Gemini, Florence-2 and LLaVA.

How they work: You provide an image and a text prompt. For descriptive tasks, you might ask "which animal in the image?" and the model responds in natural language:
" The animal shown in the image is a raccoon.”
Interestingly, some VLMs like Google Gemini 3 Pro can also find and locate objects with bounding boxes when prompted specifically. For example, in our Playground, try uploading an image to detect an object, and you can see output similar to the following:
VLMs are generally non-deterministic, sometimes potentially giving slightly different answers to the same prompt across multiple runs.
The Decision Framework
Choosing between object detection and vision-language models is a practical decision. It depends on how your system needs to work, not on which model is newer or more popular. Here, we’ll walk through the key factors that should guide your choice.
Factor 1: Are Your Object Categories Known and Fixed?
This is perhaps the most critical question.
Choose Object Detection if:
- You know exactly what you need to detect (e.g., "pedestrians," "vehicles," "traffic signs")
- Your categories won't change frequently
- You're working in a well-defined domain with standard objects
- You need to detect the same things repeatedly at scale
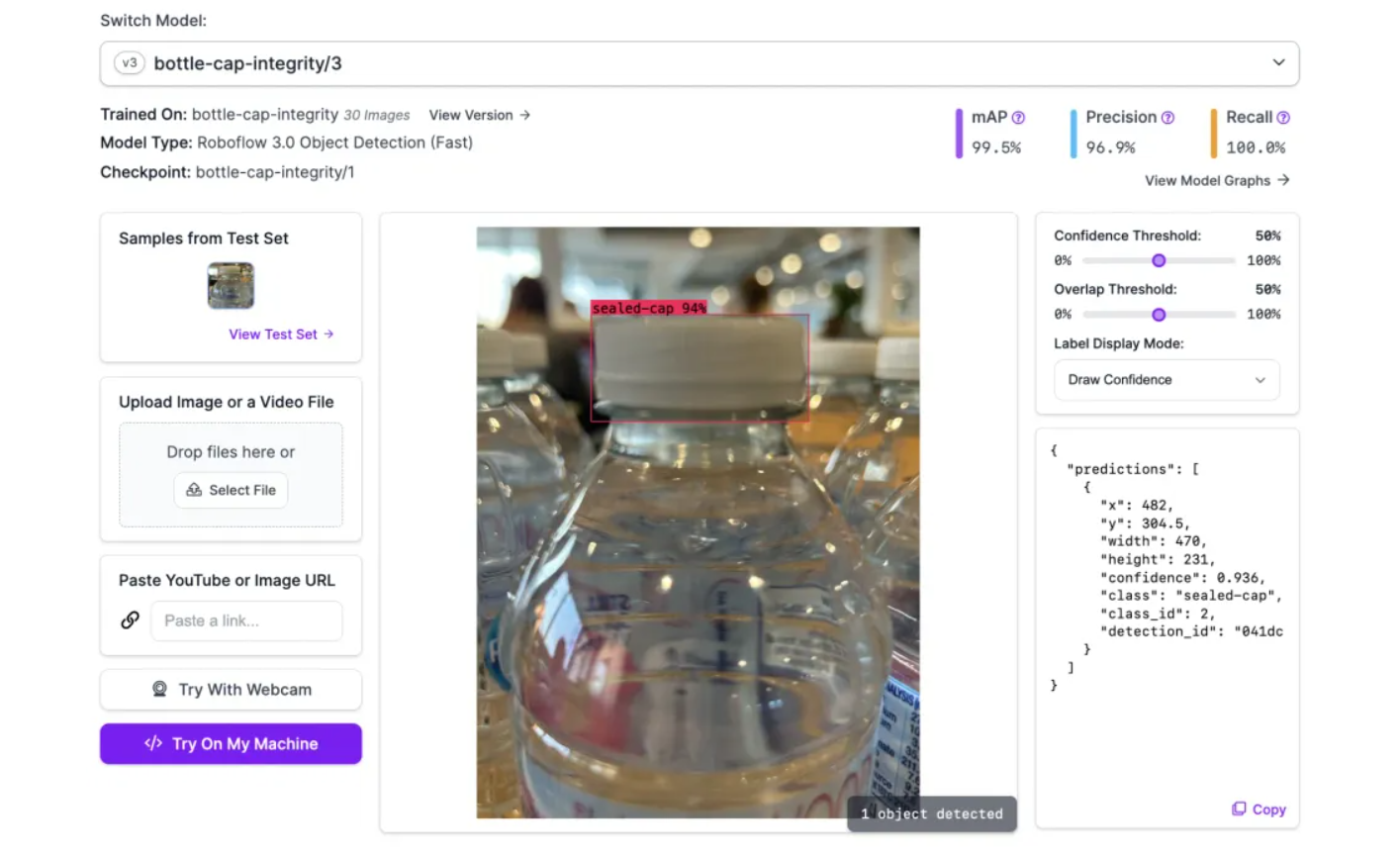
Let’s consider an example: a pharmaceutical packaging line using RF-DETR to detect specific components such as bottles, caps, labels, and boxes. The packaging components are standardized and won't change for years. The system processes 100 bottles per minute, detecting missing caps or misaligned labels with 99.5% accuracy. Categories are fixed, volume is high, and consistency is critical for regulatory compliance.
Choose VLMs if:
- You need flexibility to ask different questions about images
- Your requirements might evolve without retraining
- You're dealing with long-tail or rare objects
- You need multi-modal understanding (object recognition + OCR + spatial relationships + context)
For example, a food processing facility using Google Gemini for quality inspection of baked goods. The VLM needs to:
- recognize product types that change seasonally,
- read printed lot numbers and expiration dates (OCR),
- identify various defect types,
- understand contextual issues like "this cookie is too dark for a sugar cookie but acceptable for a chocolate chip cookie," and
- locate specific defects with bounding boxes for documentation.
Factor 2: Latency Requirements
Latency matters in many vision systems, and these two approaches behave very differently when it comes to performance and response time.
Object Detection Performance:
Object detection models are built for high speed and low latency.
They can:
- Process video in real time
- Return results with very little delay after an image is captured
- Run directly on edge devices like cameras or embedded systems
Because each frame is processed quickly and decisions are made almost immediately, object detection works well in systems that need instant responses.
For example, an automotive factory uses an object detection model to inspect welding points on car frames moving along a conveyor. Cameras capture images continuously as the cars move through the line. Each frame is analyzed almost as soon as it is captured.
If a weld defect is detected, the system raises an alert immediately. This low latency allows the production line to stop before the defective part moves to the next station. Slower models that analyze images one by one would introduce delays and risk missing critical moments.
For applications like autonomous driving, live video analytics, robotics, or high-speed industrial inspection, object detection is the practical choice because it delivers both fast throughput and immediate responses.
Vision-Language Model Performance:
Vision-language models are designed for deeper analysis, not low latency.
They:
- Take longer to process each image
- Have higher response times from image capture to result
- Require more compute, often in the cloud
This higher latency makes them unsuitable for real-time video streams. Instead, they work best in batch processing or human-in-the-loop workflows, where waiting a few seconds per image is acceptable.
For example, a textile factory uses a vision-language model for final garment inspection before shipping. Images of finished garments are captured and sent to the model with instructions to check for defects such as loose threads, stains, color variations, or stitching issues.
The analysis takes several seconds per image, but latency is not a concern at this stage. The model provides detailed observations that help human inspectors make final decisions. Since this is not a time-critical process, the slower response is acceptable.
Factor 3: Accuracy vs Determinism Tradeoffs
This factor highlights an important difference in how these models behave in real systems. It is not just about how accurate a model is, but how consistently it produces the same results.
Object Detection:
Object detection models are remarkably consistent. Run the same image through the model 100 times, and you'll get virtually identical results. This determinism is valuable for:
- Automated quality control systems
- Legal or compliance applications requiring reproducibility
- Systems where consistency matters more than flexibility
However, their accuracy is bounded by their training data. An object detection model trained on 80 categories from COCO dataset will never detect a 81st category without retraining. It might misclassify unknown objects as the closest known category, leading to confident but wrong predictions.
For example, a beverage bottling plant using RF-DETR to detect fill levels. The model is trained on three classes i.e. "properly filled," "underfilled," and "overfilled." Over 10,000 runs, it produces identical bounding boxes and classifications for the same bottle image that is critical for meeting regulatory documentation requirements. Auditors can verify that the system makes consistent decisions. However, when a new bottle design is introduced, the model must be retrained.
VLMs:
Vision-language models often provide richer and more flexible understanding, but their outputs are less consistent.
It can:
- Understand context and relationships in an image
- Describe rare or unusual objects they were not trained on
- Read text inside images
- Explain why something looks wrong
- Handle unclear or ambiguous situations
It can even detect defects they have never seen before and highlight where the issue appears. The tradeoff is determinism. The same image may produce slightly different descriptions or bounding boxes across multiple runs. Vision-language models can also occasionally report things that are not actually present.
For example, an electronics manufacturer uses a vision-language model to inspect PCBs. The model checks for missing components, solder issues, wrong parts by reading labels, and unusual defects. It can catch unexpected problems like debris or fine scratches and judge context, such as whether a defect is critical or acceptable. Results may vary slightly between runs, but this is acceptable because a human reviews the findings. In this case, flexibility is more valuable than perfect consistency.
Factor 4: Cost Considerations
The biggest cost difference between object detection and vision-language models is how those costs grow over time.
Object Detection Costs:
Object detection has most of its cost upfront. You usually pay early for:
- Collecting and labeling data
- Training the model
- Setting up infrastructure to run it
After the system is deployed:
- Running the model is cheap
- Cost per image stays very low
- Processing more images does not increase cost much
This means object detection becomes more economical as volume increases. Once the system is in place, you can process large amounts of images or video without costs growing significantly.
Vision-Language Model Costs:
Vision-language models work differently. They usually:
- Require no training or setup
- Do not need infrastructure to manage
- Charge per image or per request
This makes them easy to start with. However:
- Every image adds cost
- Processing video becomes expensive quickly
- Costs grow directly with usage
VLMs are often cost-effective at low or moderate volumes, but become expensive when used continuously or at scale.
Factor 5: Development and Maintenance Complexity
The engineering effort required differs substantially.
Object Detection Models:
Building an object detection system requires:
- Data collection and labeling (often the biggest bottleneck)
- Model selection and training infrastructure
- Hyperparameter tuning and optimization
- Deployment pipeline setup
- Monitoring and retraining workflows
- Managing model versions
This typically requires a team with ML expertise and takes more time initial deployment. However, once built, the system is relatively stable.
VLM:
Using VLMs through APIs requires:
- Integration with API provider (hours, not weeks)
- Prompt engineering and testing
- Basic error handling
A single developer can integrate VLMs into an application in days. The tradeoff is ongoing dependency on external services and less control over model behavior.
The VLM approach gets to production faster with fewer resources. However, the company may have less control. If the VLM API changes behavior or pricing, they must adapt. With object detection models, they own the entire system.
Deploy model faster with Roboflow
Practical Decision Tree: When to Use Object Detection vs Vision-Language Models
Here's a step-by-step decision process.
Step 1: Can you enumerate all objects you need to detect?
- YES -> Continue to Step 2
- NO -> Use VLMs
Step 2: Do you need real-time or near-real-time processing?
- YES -> Use Object Detection
- NO -> Continue to Step 3
Step 3: Will you process more than 100,000 images per month?
- YES -> Use Object Detection (better economics)
- NO -> Continue to Step 4
Step 4: Is deterministic output critical for your application?
- YES -> Use Object Detection
- NO -> Continue to Step 5
Step 5: Do you have ML engineering resources and time for setup?
- YES -> Object Detection likely better long-term
- NO -> Use VLMs
Step 6: Do you need contextual understanding beyond object location?
- YES -> Use VLMS
- NO -> Use Object Detection
Hybrid Approaches: Using Object Detection and Vision-Language Models Together
Sometimes the best solution is not choosing one approach, but using both object detection and vision-language models together. Below are three common and practical ways teams do this in real systems.
1. Object Detection for Filtering + VLMs for Analysis
Use object detection to quickly filter images, then apply VLMs to interesting cases.
Example: Security camera system
- An object detection model like RF-DETR monitors video feeds in real time.
- When a person enters a restricted area, the system captures a clear image.
- The image is sent to a VLM like Google Gemini.
- The VLM checks context (i.e. Maintenance worker with visible ID badge" vs "Unidentified individual").
- The system responds based on this analysis.
2. VLMs for Data Labeling + Object Detection for Production
Use VLMs to rapidly label training data, then train object detection models for production.
Example: Custom product detection
- Product images are labeled using a VLM.
- The labels are converted into training data.
- An object detection model is trained and deployed.
3. Object Detection for Primary Task + VLMs for Edge Cases
Handle common cases with object detection, escalate unusual situations to VLMs.
Example: Document processing
- Object detection classifies common documents.
- Uncertain cases are sent to a VLM for analysis.
- New document types are added back into training over time.
Common Mistakes to Avoid
Choosing between object detection and vision-language models is not just about capability. Many teams run into trouble because of how they apply these tools. Below are some of the most common mistakes seen in real projects and how to avoid them.
Using Vision-Language Models for High-Volume, Fixed Tasks
VLM feel powerful, so it’s tempting to use them everywhere. But using VLM APIs to process millions of images for the same fixed set of objects is usually a mistake. If you are detecting the same 10 or 20 object types over and over, object detection models are faster, cheaper, and more reliable. In these cases, VLMs often cost much more and deliver no real benefit.
Over-Engineering Object Detection for Changing Requirements
The opposite mistake also happens. Some teams spend months building custom object detection pipelines for problems that keep changing. If your categories change often, or you cannot clearly define them upfront, object detection becomes slow and expensive to maintain. In these situations, VLMs allow much faster iteration and exploration.
Ignoring Latency Until the System is Built
Latency problems are hard to fix after deployment. Teams sometimes design systems around VLMs and only later realize they need real-time or near-real-time responses. Cloud-based models are rarely suitable for strict latency requirements. Performance constraints should be checked early, not after the architecture is locked in.
Expecting Perfect Consistency from Vision-Language Models
VLMs are powerful, but they are not deterministic. The same image can produce slightly different results depending on prompts, context, or model updates. If your workflow assumes identical outputs every time, you will eventually see unexpected failures. VLMs work best when systems are designed to handle uncertainty.
Forgetting That Object Detection Needs Maintenance
Object detection models are stable, but they are not “train once and forget.” The real world changes. Lighting, environments, products, and even clothing styles evolve over time. Models trained on old data can slowly lose accuracy. Successful teams plan for regular monitoring and retraining as part of the system lifecycle.
Most vision application failures come from using the right model in the wrong way. Understanding these common mistakes helps you build systems that scale, stay reliable, and survive beyond the demo stage.
Where Are These Technologies Heading?
Computer vision is moving fast. While today’s choices already matter, understanding where object detection and vision-language models are heading can help you make decisions that last. Below are a few clear trends shaping how these technologies are evolving.
Smaller and Faster Vision-Language Models
Vision-language models are becoming faster and more efficient. Tasks that currently take several seconds per image may soon run in under a second. This will expand where VLMs can be used, especially for interactive and near-real-time applications. However, VLMs still have low speed than object detection models for high-frame-rate or real-time systems.
Open-Vocabulary Object Detection
A new class of models is starting to blur the line between object detection and VLMs. These models allow object detection using text descriptions, even for categories not seen during training. This brings some of the flexibility of vision-language models into object detection workflows. The tradeoff is that results still depend heavily on how prompts are written, and performance can vary across scenarios.

Edge Deployment for Both Approaches
Both object detection and vision-language models are becoming smaller and more efficient. This makes it possible to run them closer to where data is generated such as on cameras, gateways, or edge devices.
As edge deployment improves, costs drop and latency improves. This also enables new use cases in environments where cloud access is limited or unreliable.
Learn more about edge deployments in our guides:
- What Is Edge AI And How Does It Work?
- Edge vs. Cloud Deployment: Which is Right for Your AI Project?
- Deploy a Model or Workflow
Domain-Specific Vision-Language Models
Instead of one general model for everything, we can fine tune VLMs for specific domains like:
- Medical imaging
- Manufacturing inspection
- Satellite imagery
These domain-focused models are often more accurate and more consistent than general-purpose VLMs. In specialized industries, they may shift the balance toward vision-language models for certain tasks.
Read our guides below to learn more about how you can fine tune VLMs on custom data:
- How to Fine-tune Florence-2 for Object Detection Tasks
- How to Fine-Tune Claude 3.7 Sonnet With Roboflow
- How to Fine-tune PaliGemma 2
- How to Fine-Tune a SmolVLM2 Model on a Custom Dataset
- Finetuning Moondream2 for Computer Vision Tasks
The future is not about one model replacing the other. It is about more overlap, better tools, and clearer tradeoffs. Object detection will remain the backbone for fast, reliable, large-scale systems. Vision-language models will continue to improve flexibility and understanding. Teams that design with these strengths in mind will be better prepared as both technologies evolve.
How to Choose Between Object Detection vs Vision-Language Models Conclusion
Choosing between object detection and vision-language models is not about which technology is “better.” It is about which one fits your problem.
Object detection works best when you need fast, consistent results for known categories at scale. Vision-language models are better when requirements are unclear, changing, or need deeper context and understanding.
As both technologies continue advancing, the decision points will shift, but the fundamental framework remains. You need to match your technical choice to your specific requirements for speed, flexibility, cost, and accuracy.
What is your use case? Run through the decision framework, and you'll find your answer, or speak to an AI expert for additional questions.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jan 13, 2026). Object Detection vs Vision-Language Models: When Should You Use Each?. Roboflow Blog: https://blog.roboflow.com/object-detection-vs-vision-language-models/