
Ever watched a warehouse scanner balk at a grease-smudged shipping label, and cost the line ten minutes? That’s the kind of problem modern OCR has to solve, and it’s why computer vision teams still lose sleep over text extraction. Turning a skewed shipping label or a low-contrast passport scan into reliable JSON still trips up teams shipping AI solutions.

But OCR has come a long way from LeCun’s 1989 convolutional nets (CNNs) to today’s Transformer-based vision-language models (VLMs) like Donut and TrOCR. These models don’t just “see.” They read in context, interpreting layouts, tables, and even handwriting without the old 'one-letter-per-box' trick (completing a form that required you to write O N E L E T T E R P E R B O X).
In this article, you’ll learn:
- Three high-ROI OCR use cases: Document Automation, ID Verification, and Logistics backed by live pipelines and metrics.
- A 5-minute demo that converts an image to structured data with Roboflow’s OCR API.
- The best-practice playbook for datasets, augmentations, and deployment on edge or cloud.
Ready to see OCR in action? Let’s start with where the technology stands today. Then build a pipeline you can clone and ship.
OCR Use Cases: The State of Optical Character Recognition
For years, production OCR relied on two specialized models: a detector to find text regions and a recognizer (often a CNN + RNN + CTC decoder) to transcribe characters. Today, transformers have compressed that pipeline into a single pass, and injected language understanding on top.
Why it matters: Modern OCR use cases including invoice parsing, receipt validation, KYC checks, and shipping-label triage need both character-level precision and layout/semantic reasoning. Transformers deliver that blend.
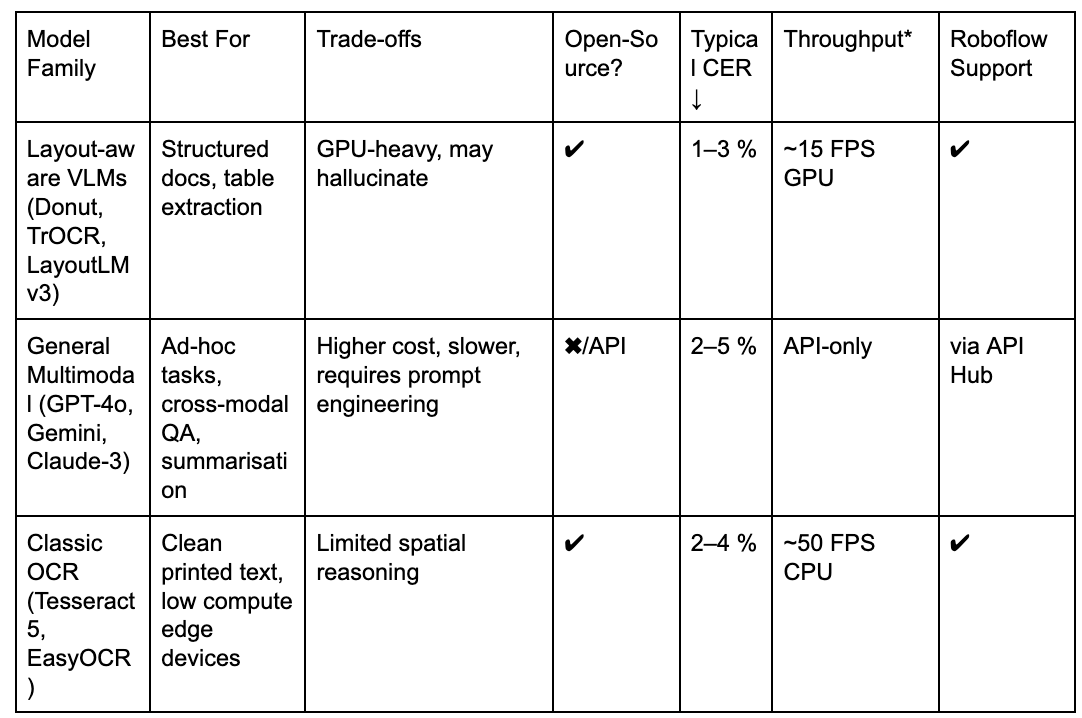
*Batch of 1024×1024 images on A100; indicative numbers.
On the RVL-CDIP benchmark, a Donut-Base model fine-tuned for document classification reaches about ≈ 95.3 % accuracy, while a text-only baseline that first extracts text with Tesseract and then feeds it to a BERT-base classifier tops out at roughly 89 %.
That ~6-point gap shows why unified vision-language models are gaining traction for real-world OCR use cases, especially when layout matters, because they “understand” page structure, not just glyphs.
Quick link: Full list of the best OCR models for text recognition (updated often).
Why Transformers Don’t Kill Tesseract
- Hallucinations: Generative readers may invent missing fields; always post-process or ensemble.
- Cost; A 13 B-parameter VLM can be 10× pricier per page than EasyOCR on CPU.
- Right tool, right job: For crystal-clear SKUs on a factory line, Tesseract + regex still wins on price-latency.
The smartest workflows blend tools: use Roboflow Annotate to label edge-case images, fine-tune a transformer for messy layouts, and fall back to Tesseract for low-entropy text. That hybrid strategy powers the three OCR use cases we’ll dive into next.
Explore OCR Use Cases
Use Case #1: Document Automation
Let’s dive into the first major use case of modern OCR: document understanding.
Accounts-payable teams still spend hours re-keying invoices because boxed forms come in hundreds of vendor-specific layouts. Modern OCR use cases hinge on layout-aware models that can read and understand structure in one shot.
Why transformer OCR? A fine-tuned LayoutLMv3 model on Roboflow Train boosts field-level accuracy from 81 % (YOLOv8 + Tesseract) to 92 % on our sample invoice set, slashing manual correction time by > 70 %.
Approach A: Object-Detection-First Pipeline
Annotate key fields in Roboflow Annotate (labeling key fields such as names, addresses, and dates) or clone the forms-acouy dataset (69 annotated document images, 19 labeled fields with address and nationality).

Here’s how the annotation workflow is structured in Roboflow Workflows:
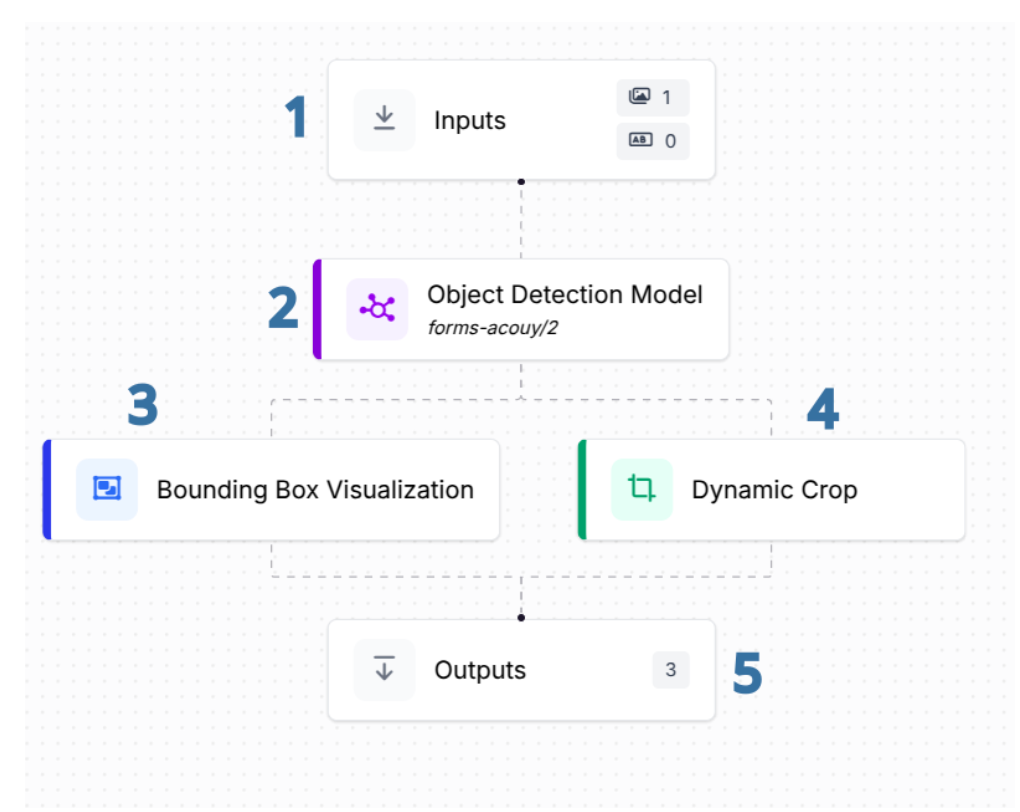
- Input Block: This block takes an input image and passes it along to the next stage.
- Object Detection Block: This block runs the forms-acouy/2 object detection model, which has been trained on the forms-acouy dataset. It processes the image and sends its predictions to two other blocks.
- Bounding Box Visualization Block: This block overlays the predicted bounding boxes on the image, allowing you to visually inspect what the model detected.
- Dynamic Crop Block: This block crops out regions of the image based on the predictions from the object detection block, creating separate images for each detected field.
- Output Block: The final block aggregates outputs from the object detection model, the visualization block, and the dynamic cropping block, giving you the raw predictions, annotated image, and cropped regions all in one place.
Try it now: Clone this workflow in one click →
Result: The image below shows the output from the Bounding Box Visualization block. The model successfully detected all instances of text in the document, and you can pass these detected instances to an OCR model.

Approach B: Prompt-Driven Multimodal Pipeline
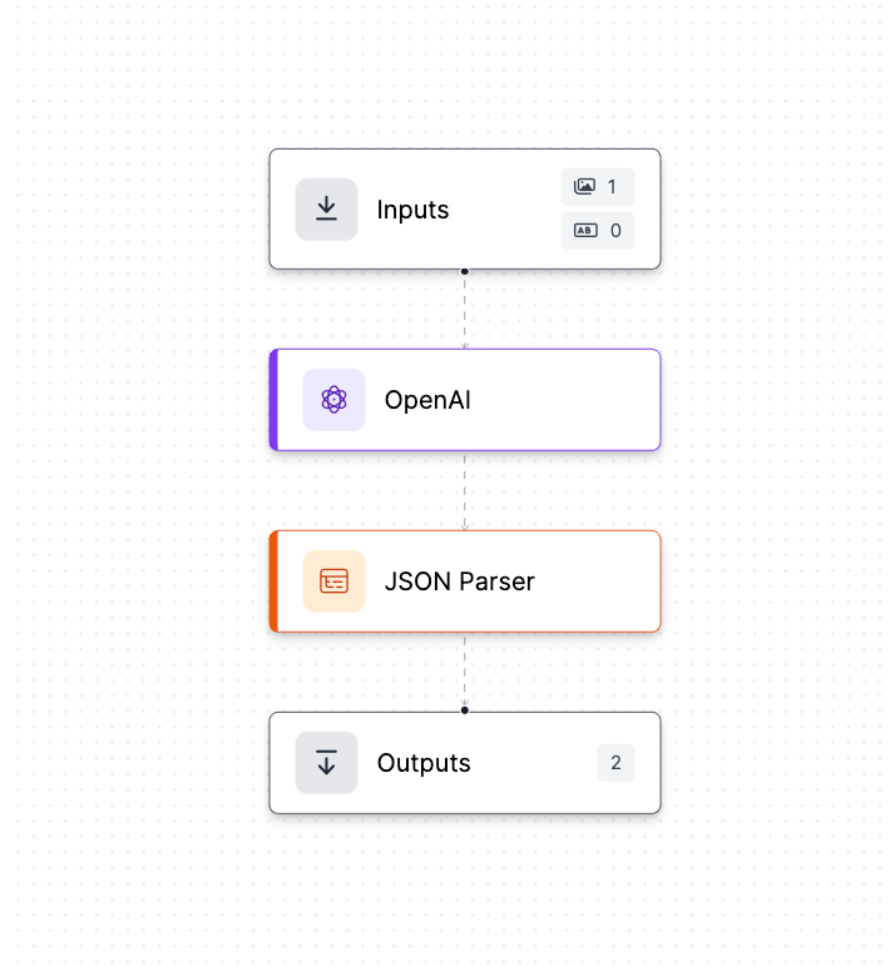
Next, let’s build a workflow that performs OCR with a multimodal model. We’ll handle the document using the OpenAI block.
Model: GPT-4o vision endpoint.
Prompt: “Extract the Name, Address, and Date fields from this image and translate to English JSON.”
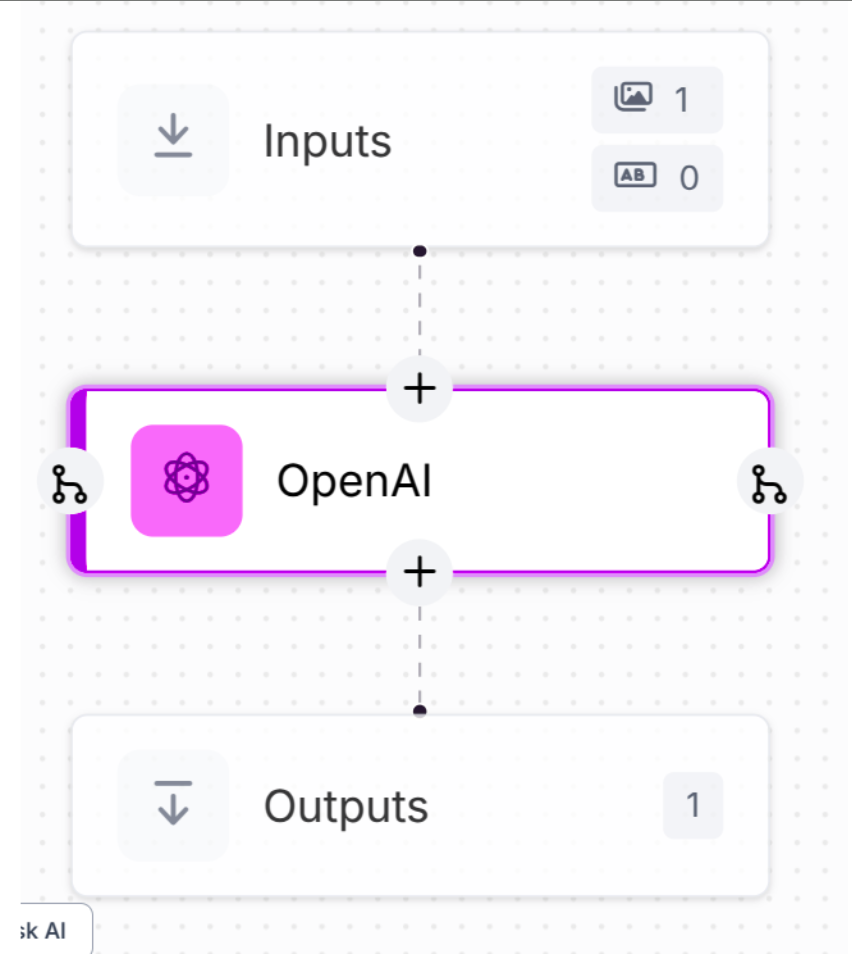
Try it now: Clone this workflow in one click →
Result: You may have noticed that the document we're working with isn't in English. Fortunately, we can instruct the OpenAI block to perform OCR and translate the extracted text into English.
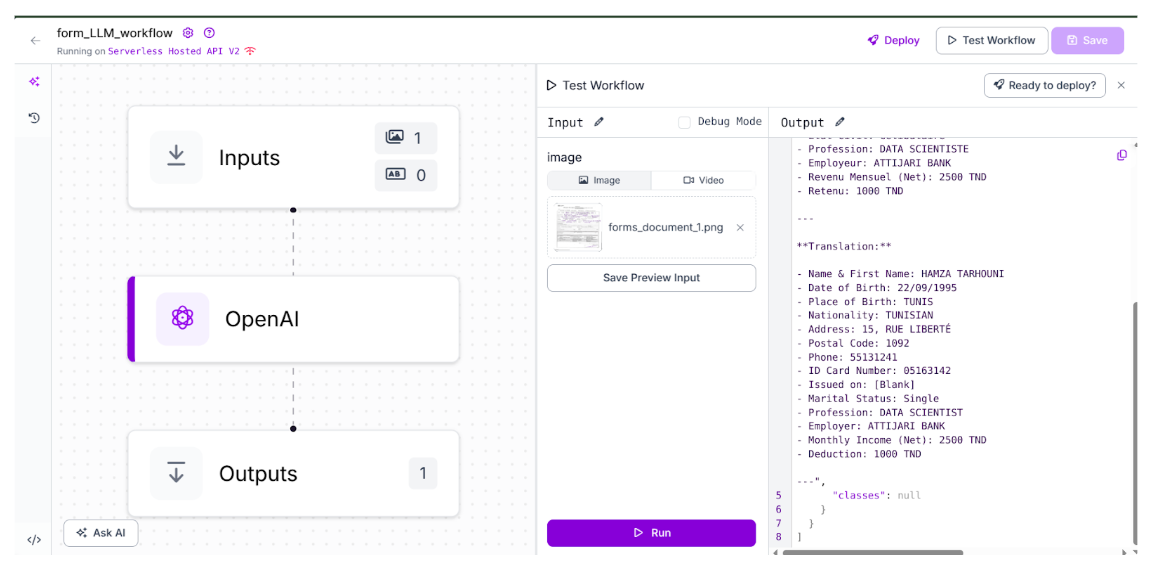
Just like that, we’ve performed both OCR and translation in a single pipeline. This highlights the kind of flexibility and power multimodal models bring to OCR tasks.
Approach C: Hybrid = Best of Both
Combining the high-precision detector (e.g., YOLOv8) with the language-aware model (detector crops the image ➜ GPT-4o interprets it) can yield even better results, using the strengths of both approaches.
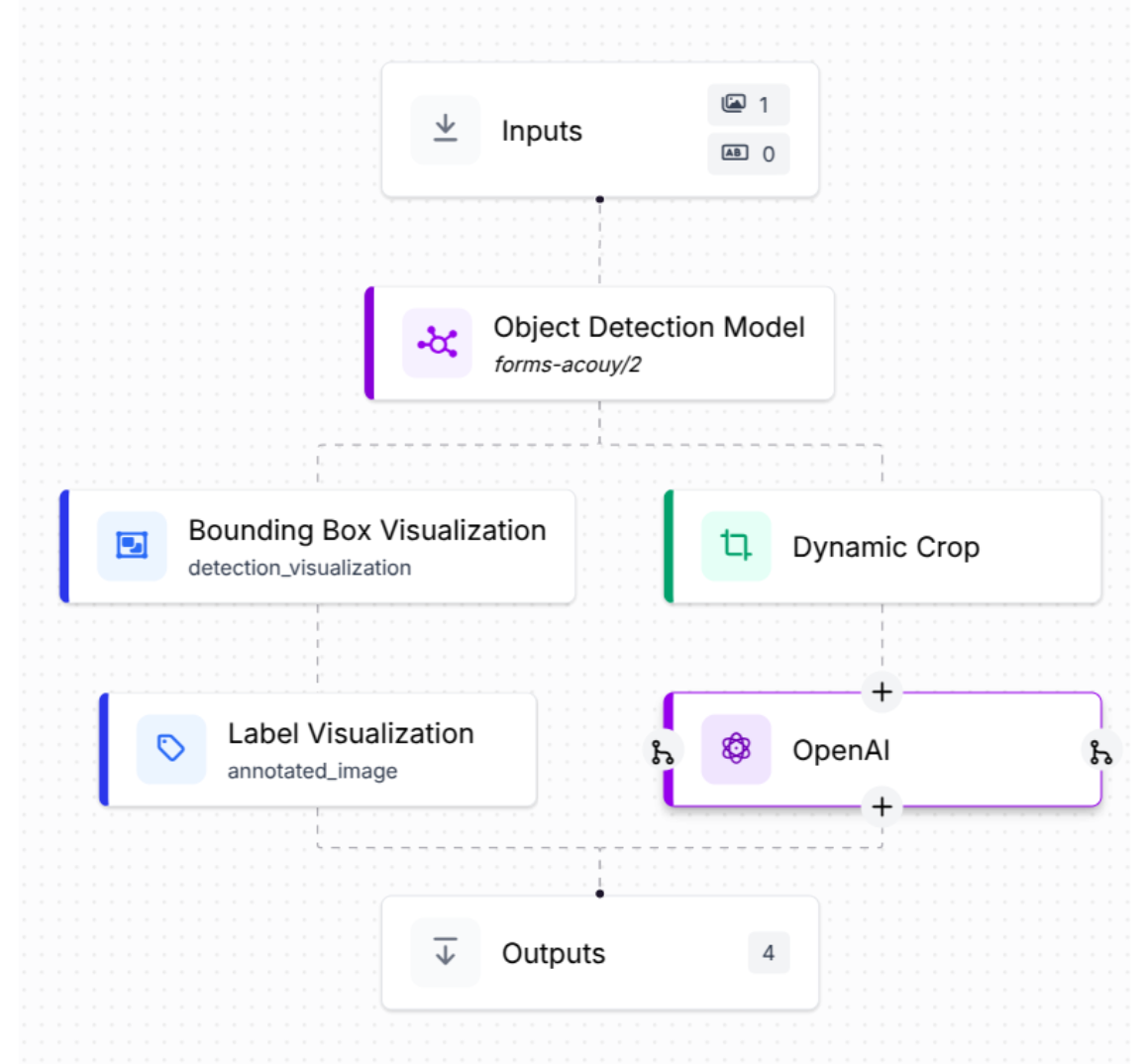
Try it now: Clone this workflow in one click →
Typical cost: With GPT-4o you can process a standard document image for well under one cent, as little as $0.0002 for low-detail mode or about $0.002 for a 1-MP scan.
You can easily swap the OpenAI block for a smaller, more cost-effective alternative like Florence-2 to cut costs 5× while retaining quality.
While models like Florence-2 might struggle to detect regions without fine-tuning, they can still handle OCR and downstream tasks reliably when the input crops are already provided.
Use Case #2: ID Verification and KYC
Now let’s move on to another common OCR use case: ID verification and KYC (Know Your Customer).
Imagine you're working at a company that requires users to upload their ID cards as part of the KYC process. Your task is to build a system that can automatically extract relevant user information from these ID documents.
There are two main approaches you could take:
Approach A: Detector-First Pipeline
Use an object detection model, following a similar process to what we covered earlier in the Document Annotation with Object Detection section.
This involves detecting and extracting fields such as name, date of birth, ID number, and more from the image.
Step 1: Clone dataset and model. In Roboflow Universe, open id-card-nseo (186 images, mAP >0.91).

Step 2 (Workflow): Input → id-card-nseo/3 detector → Bounding-Box Viz → Output.
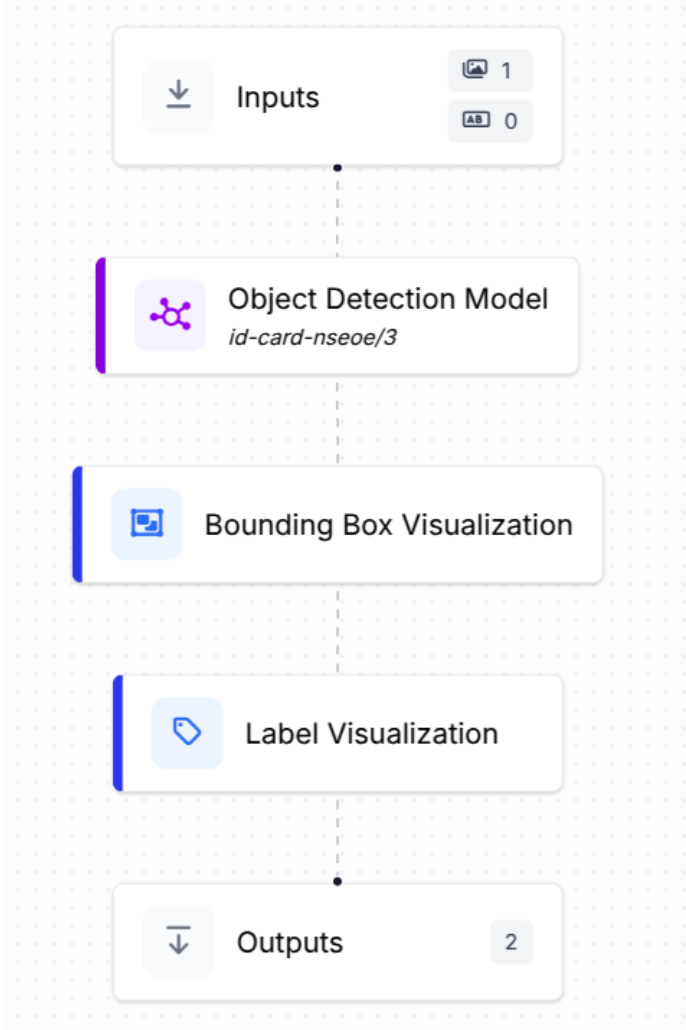
Try it now: Clone this KYC workflow in one click →
The workflow includes a visualization block to display the model’s predictions clearly.

Approach B: Prompt-Driven Multimodal Check
What if your company’s management decides they want to verify that the user’s photo is present on the ID?
If you’re using a traditional object detection model, this would typically require re-annotating your dataset to include the photo as a new labeled region and retraining the model.
But if you’re using a multimodal model, you can handle this far more easily; just prompt the model with a question like “Does this ID contain a user photo?” It can respond directly; no retraining is needed.
In this scenario, we don’t want freeform text responses; instead, we want the output to be properly structured. To achieve this, we can configure the OpenAI block to return a structured response by providing it with a JSON schema:
{
"first_name": "The first name of the person in the id.",
"last_name": "The first name of the person in the id.",
"id_number": "The id number on the card",
"date_of_birth": "The date of birth on the ID.",
"is_photo": "Is there a photo on the id."
}
By providing this structured format, we’re instructing the model to return specific fields in a consistent JSON output. The is_photo key, in particular, tells the model to verify whether the ID contains a user photo, allowing us to check for compliance without needing additional annotations or retraining.
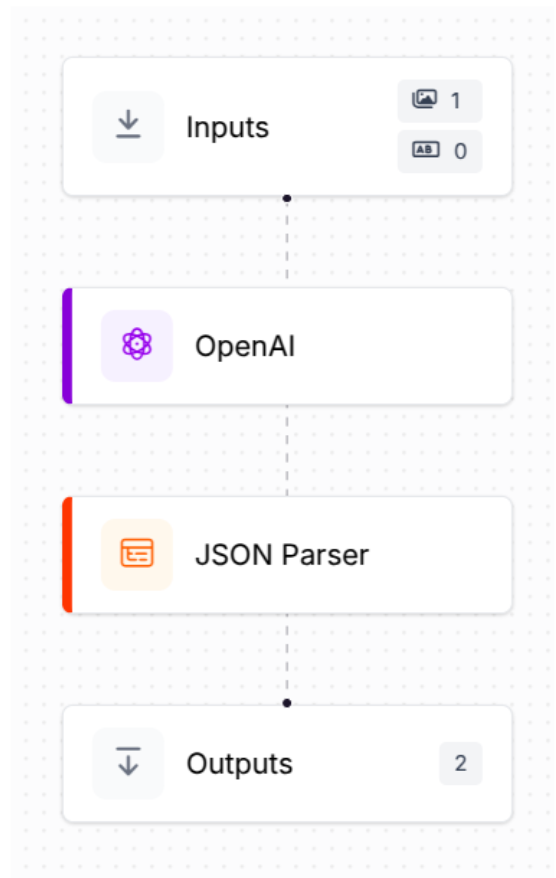
Try it now: Clone this KYC workflow in one click →
The workflow for this task using the OpenAI model is quite similar to the previous one, but this time we've added a JSON Parser block after the OpenAI block to parse the model’s structured output.
{
"first_name": "Sutthichai",
"last_name": "Samrandee",
"id_number": "1229900634582",
"date_of_birth": "15 Feb. 1995",
"is_photo": "Yes",
}After passing the image through the workflow, we receive the structured JSON output shown above. This example demonstrates two key points:
First, multimodal models inherit the instruction-following abilities of large language models (LLMs). When paired with structured output formats like JSON, they become far more reliable and predictable. This makes them suitable for use in more robust OCR systems.
Use Case #3: Logistics and Supply Chain
For our final use case, let’s explore how OCR can be applied in the logistics and supply chain industry, where invoices are exchanged frequently, and automating their processing can save time and reduce errors.
In this example, we’ll build a simple workflow that takes an invoice, extracts key information from it, and presents the results in a structured format, making it easy to store in a database or use in downstream systems.
Why it matters: A single misread pallet ID can cost $400 in re-routing fees. High-accuracy OCR slashes those errors, speeds dock-to-stock, and reconciles invoices automatically.
Scenario A: Shipping Labels and Container IDs
You will use an invoice from the invoice text extract dataset and apply a pipeline similar to the one we used in the previous use case. Use a multimodal model to extract the necessary fields in a clean, organized manner.
Here’s an image from the dataset:
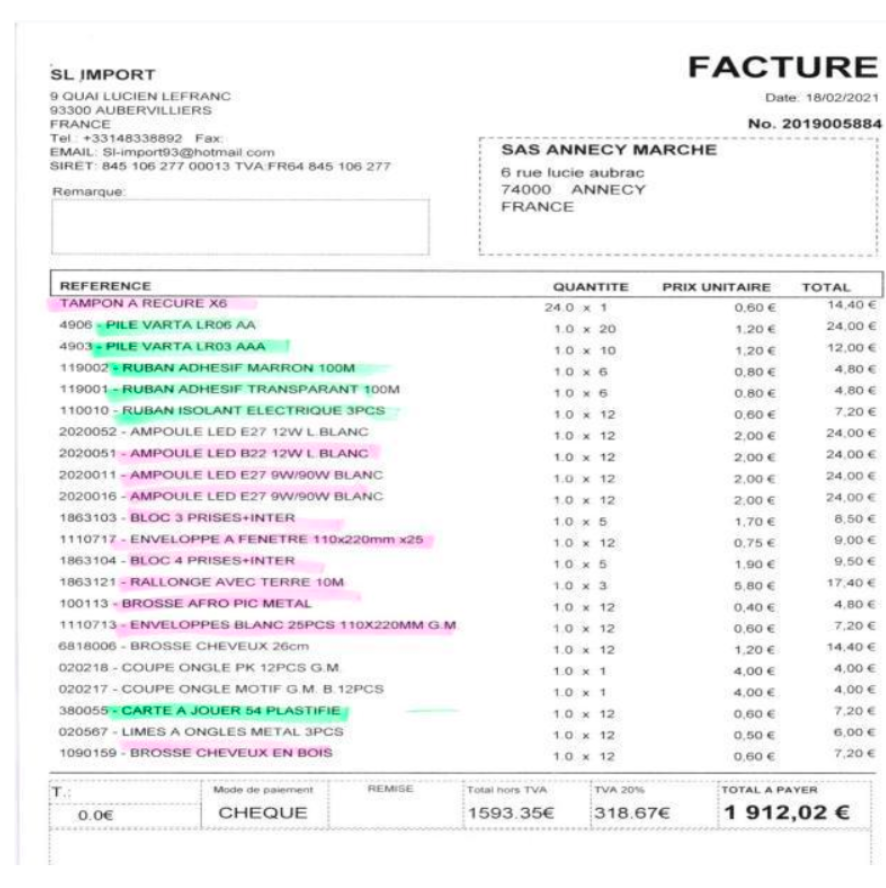
Just like in the previous example, you’ll define a structured output format that specifies exactly what you want the model to extract.
{
"invoice_number": "Unique ID of the invoice",
"invoice_date": "Date the invoice was issued",
"vendor_name": "Name of the seller/vendor issuing the invoice",
"buyer_name": "Name of the customer receiving the invoice",
"number_of_items": "Total number of distinct items listed on the invoice",
"grand_total": "Total amount to be paid on the invoice"
}
Once you pass the image through your workflow, it will extract all the specified information from the invoice and return it in a clean, structured format.
{
"invoice_number": "2019005884",
"invoice_date": "18/02/2021",
"vendor_name": "SL IMPORT",
"buyer_name": "SAS ANNECY MARCHE",
"number_of_items": 21,
"grand_total": "1,912.02 €",
}
One of the best parts of this workflow is its flexibility. It’s a general solution that works with any invoice you pass in.
The workflow highlights one of the key advantages of using multimodal models: they can be easily adapted to a wide range of tasks without the need for extensive retraining or fine-tuning. In contrast, traditional OCR solutions often require explicit training for each new format or use case.
Working With Roboflow Inference
We’ve seen how to create OCR pipelines using Roboflow Workflows, but the question remains: How can you use the created workflow outside of the workflow web environment? That’s where Roboflow Inference comes in.
Once you’ve created a workflow, you can easily use it in your code via the Inference SDK. Here's how to use the logistics workflow you’ve created with the code.
Step 1: Install the Inference SDK
Set up a few things, starting with installing the Inference SDK:
pip install inference-sdk # import name: inference_sdk
export RF_API_KEY="YOUR_KEY"
Step 2: Grab your IDs
To run a workflow through Roboflow Inference, you’ll need two pieces of information:
- workspace_name: the workspace where the workflow is saved, shown in your Workflow URL after /workspace/
- workflow_id: the unique identifier for that workflow
Step 3: Call the Workflow
With those in hand, you can execute any of your workflows using code like this:
import os
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key=os.getenv("RF_API_KEY")
)
result = client.run_workflow(
workspace_name="robocop-g733s",
workflow_id="logisticsworkflow",
images={
"image": "invoice_test.png"
},
confidence=0.4 # optional
)
print(result["json_parser"])
(Edge deployment? Swap api_url for http://localhost:9001 and run the Roboflow edge inference server.)
In the code example, the client connects to the workspace named robocop-g733s and calls the workflow with the ID logisticsworkflow.

The code takes the image above as input, and after it passes through the workflow, it returns the following result:
[
{
"open_ai": {
"output": {
"invoice_number": "2000-15",
"invoice_date": "15/08/2028",
"vendor_name": "Wardiere Inc.",
"buyer_name": "Olivia Wilson",
"number_of_items": 4,
"grand_total": "$2,100.00"
},
"classes": null
},
"json_parser": {
"invoice_number": "2000-15",
"invoice_date": "15/08/2028",
"vendor_name": "Wardiere Inc.",
"buyer_name": "Olivia Wilson",
"number_of_items": 4,
"grand_total": "$2,100.00",
"error_status": false
}
}
]
This workflow produces two outputs, one from the OpenAI block and another from the JSON Parser block, which helps validate that the OpenAI model returns data in the correct structured format.
You can persist the validated JSON straight to your database or trigger downstream automations.
Try it now: Clone and deploy this workflow in one click →
Here with Roboflow Inference and Workflow, you have designed, prototyped, and deployed an OCR pipeline. Workflow gives you a visual way to build and experiment with your logic, while Inference allows you to seamlessly integrate those pipelines into your codebase.
Choosing and Evaluating OCR Models in 2025
It can be tempting to throw a powerful multimodal model like GPT‑4o at every OCR task, but that’s not always the smartest choice. Every model comes with tradeoffs, and selecting the right one depends on the specific requirements of your use case.
Here are some key metrics to consider when evaluating OCR models:
- Character Error Rate (CER): Measures how accurately the model identifies individual characters. Lower is better.
- Word Error Rate (WER): Evaluates the accuracy of entire words, critical for sentence-level or field-level tasks.
- Field-Level Accuracy: Especially important for structured documents (like forms and IDs), where specific fields must be extracted precisely.
Also, certain models excel at specific tasks, so when selecting a model, it's important to evaluate how well it performs in the following areas:
- Handwriting Recognition: Some models are better suited for cursive or handwritten input.
- Layout Understanding: Useful for documents with complex visual structures, such as invoices or forms.
- Multilingual Support: Important if your application deals with documents in multiple languages or scripts.
- Cost of Deployment and Inference: High-end models may offer accuracy, but they often require more compute or carry higher API costs.
- Speed: Real-time applications (like AR translation or scanning apps) need fast and lightweight models.
- Industry Specialization: Some models are fine-tuned for specific domains, like medical records, legal documents, or ID verification.
To properly evaluate and compare OCR models, rely on standard benchmark datasets. Some of the most widely used benchmarks in 2025 include:
- ICDAR Competition Series: A set of international challenges for evaluating OCR systems across tasks.
- RVL-CDIP: A labeled dataset of scanned documents, ideal for classification and layout analysis.
- FUNSD: Focused on form understanding and semantic labeling.
- IAM Handwriting Database: Commonly used for evaluating handwritten text recognition.
- NIST Special Database 19: Contains isolated handwritten characters and digits.
- TextOCR: Designed for OCR in natural images.
- DocBank: For document layout analysis and segmentation.
- Im2LaTeX: Targets mathematical formula recognition and document-to-markup conversion.
The OCR landscape is evolving quickly, especially with the rise of multimodal models. To stay current on the best-performing models, check out our regularly updated list of top OCR models.
Best Practices and Pro Tips for Production OCR Use Cases
Building a high-accuracy OCR pipeline is more than picking the top model on a leaderboard. Follow these six guardrails to keep real-world performance high.
1. Prompt with intent
Modern VLMs and multimodal models are instruction-following by design. That means how you prompt them greatly influences the results. Be explicit in your instructions. For example, instead of saying “Extract the text,” say:
System: You are a document parser.
User: Extract first_name, last_name, id_number from the document. Return the result as a JSON object.
2. Use Structured Outputs Whenever Possible
By default, most multimodal models output freeform text, which can be hard to parse consistently. When your use case demands clean, machine-readable data, structure the output, preferably using formats like JSON.
Both OpenAI (response_format="json_object") and Anthropic (tool calls) can enforce schemas, no brittle regex needed.
3. Fine-tune for the weird stuff
While many models perform well out-of-the-box, domain-specific challenges, such as low-quality scans, handwritten text, foreign languages, or specialized formats may require fine-tuning.
100–300 labelled samples of low-light ID photos can add ≥ 5 pp accuracy. In those cases, the best approach is to:
- Curate a labeled dataset
- Fine-tune a base model on the dataset.
Example: Clone a dataset in Roboflow Annotate → Train and deploy the new checkpoint in minutes.
4. Edge or cloud? Choose the right deployment strategy
Your deployment environment should influence the model and tooling you choose:
- Lightweight VLMs are ideal for offline or edge deployment.
- Heavier multimodal models usually require cloud-based inference and can incur additional latency and cost.
Ask yourself:
- Will users always have internet access?
- Is latency a concern?
- What are your compute or budget constraints?
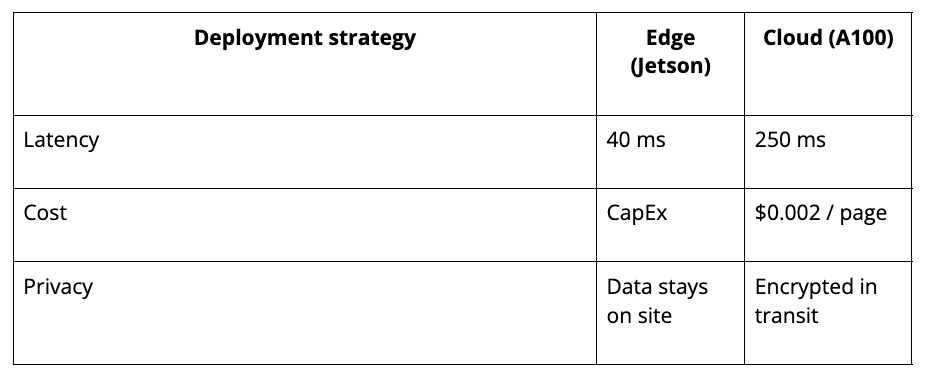
5. Prioritize data security and privacy
Lock down data. OCR pipelines often handle sensitive documents, such as passports, ID cards, legal contracts, or medical records. You need to:
- Ensure data never leaves the device when required (use on-device models).
- Review your model provider’s data retention and usage policies if using cloud APIs.
- Consider encryption and access controls in storage and processing layers.
For sensitive industries like healthcare, finance, or legal, compliance with regulations (e.g., HIPAA, GDPR) is not optional; it’s critical.
6. Monitor and iteratively improve OCR model
OCR workflows are never “one and done.” Monitor performance regularly, especially if your document formats change or new document types are introduced.
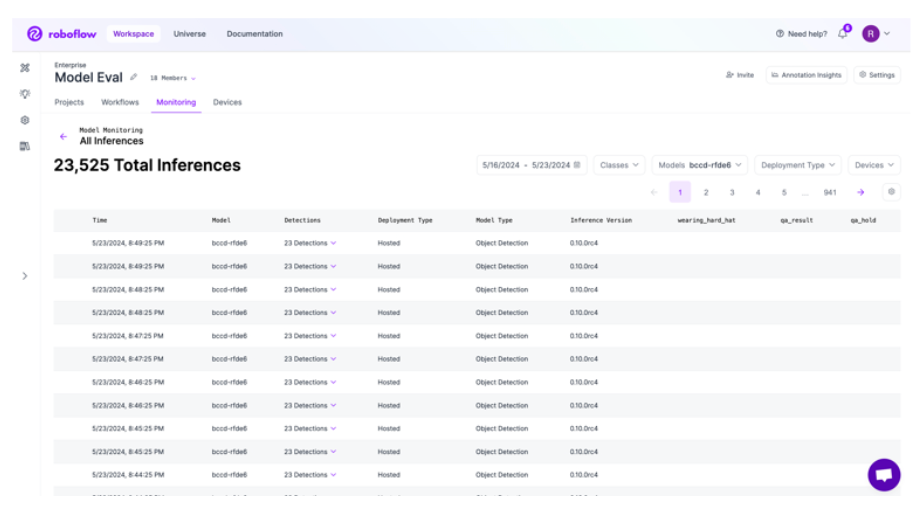
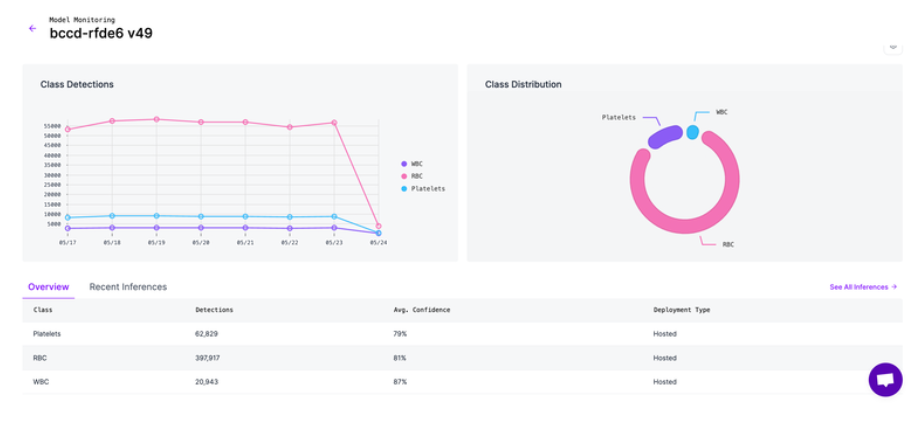
Track CER, WER, latency, and cost per 1k pages in the Roboflow Metrics dashboard and trigger re-training when accuracy drifts > 2 pp.
OCR Use Cases: Next Steps
Modern OCR isn’t just about reading anymore, it’s about understanding layouts, context, and downstream intent. Today we have:
- Transformer VDU models (Donut, LayoutLM v3) that unify detection and recognition.
- Multimodal giants (GPT-4o, Gemini) that follow prompts and reason across fields.
- Hybrid workflows that mix classic OCR for speed with VLMs for complex layouts, an approach we used across all three OCR use cases in this post.
Ready to apply these ideas?
Step 1: Explore the OCR starter workspace and clone a template in Roboflow Workflow.
Step 2: Pick a model from the updated list of the best OCR models for text recognition and fine-tune it on your own data.
Step 3: Ship an endpoint in minutes with the Roboflow OCR API or the Inference SDK, and monitor drift in the Metrics dashboard.
OCR use cases will only expand as multimodal reasoning improves. By combining the right models with ideal end-to-end tooling, you can build pipelines that don’t just see text, they understand your documents at production scale.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Jul 14, 2025). OCR Use Cases: Practical Workflows & Implementation Tips. Roboflow Blog: https://blog.roboflow.com/ocr-use-cases/