
Open-vocabulary object detection promises something every vision engineer wants: the ability to detect new things without retraining a model. But that phrase gets overloaded fast: Is it the same as promptable segmentation? Is it just a vision-language model with boxes? Is it “zero-shot everything”?
Not quite. In this guide, I'll detail what open-vocabulary detection actually is, where CLIP-style models fit, and how it differs from both promptable segmentation and VLMs, so you know exactly what problem each tool is meant to solve.
Why Go Beyond a Fixed Label List?
Traditional object detectors are trained on a fixed set of object classes. After deployment, they can only detect those predefined categories. As a result, they ignore everything else, even if new or relevant objects appear in the scene.
In real-world applications, object categories often change. New objects, variations, or task-specific concepts appear over time. Supporting these changes usually requires collecting new bounding box annotations, retraining the model, and redeploying the system. This process can be expensive, slow, and difficult to scale.
Open-vocabulary object detection removes this rigidity. Instead of relying on a fixed label list, it allows object names to be provided as text at inference time. This makes detection systems more flexible and reusable, especially for long-tail and evolving real-world scenarios.
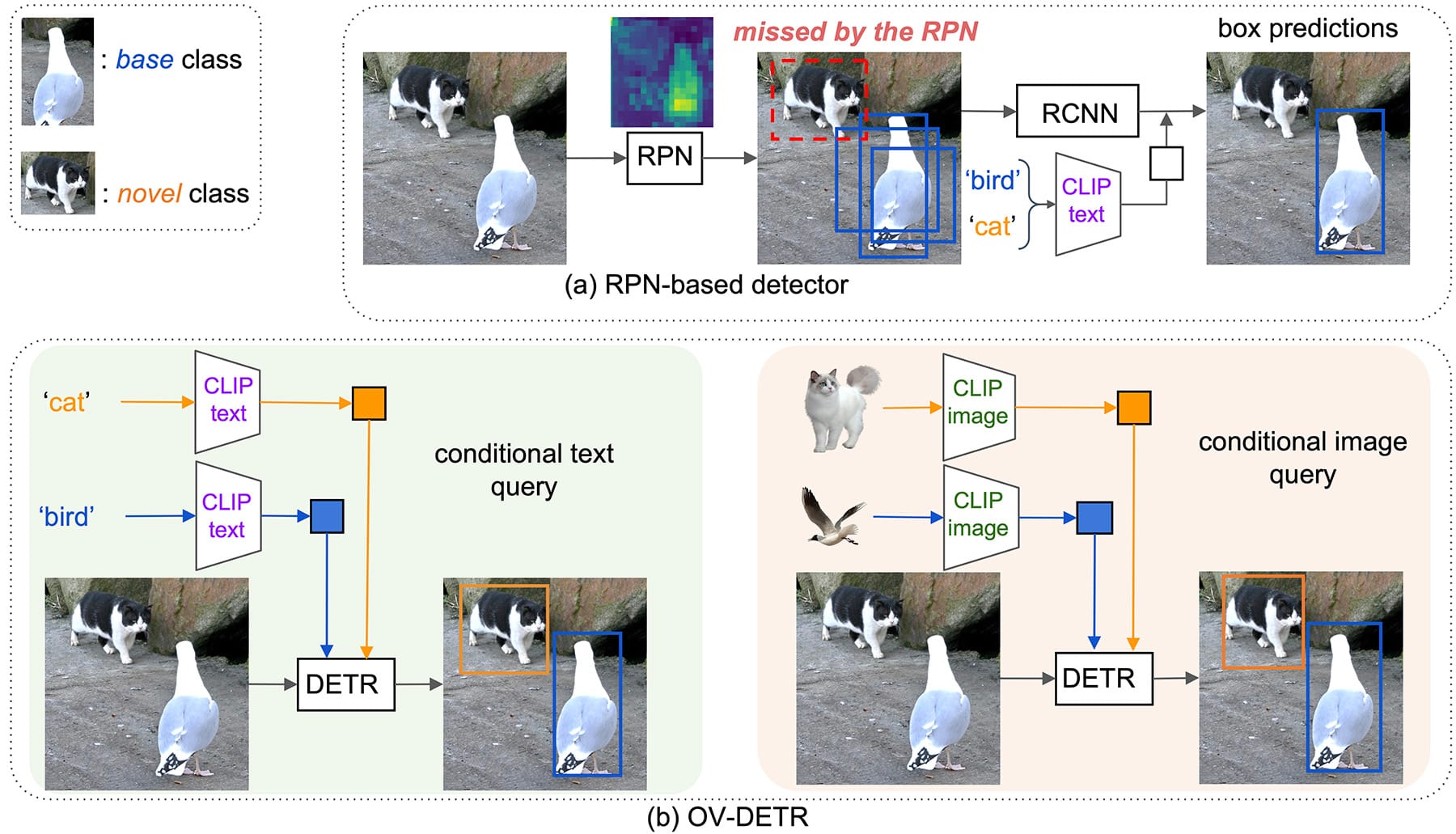
What Is Open-Vocabulary Object Detection?
Open-vocabulary object detection reframes detection as a region-text alignment problem.
Traditional detectors assign a class from a fixed list to each bounding box. In contrast, open-vocabulary detectors compare visual features from each bounding box with text embeddings of class names provided by the user.
This is possible because vision language models are pretrained on large image-text datasets and learn a shared embedding space for visual and textual information. Using this shared space, open-vocabulary detectors can identify objects using arbitrary text prompts at inference time.
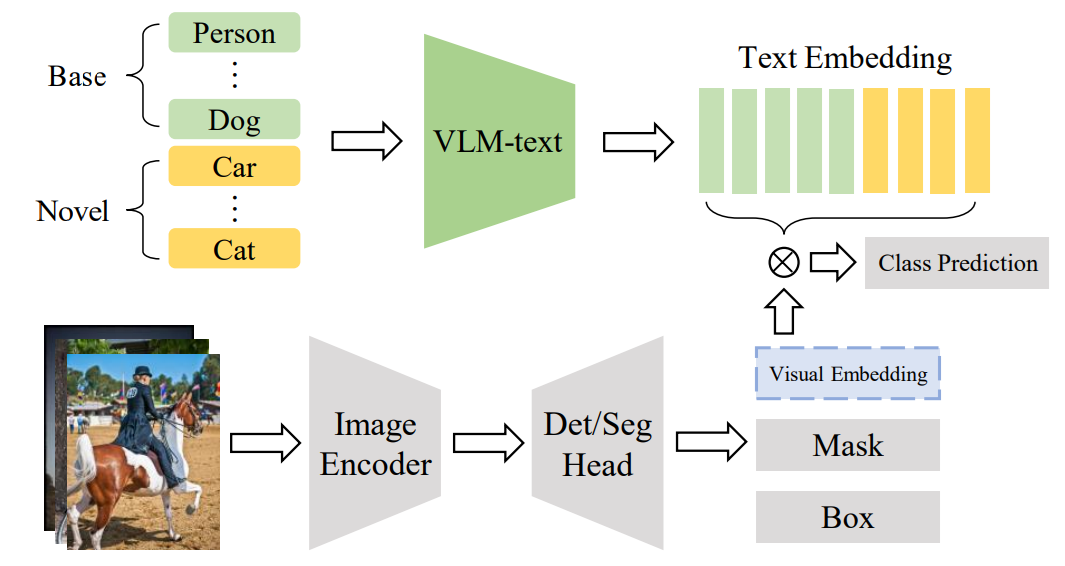
The process can be summarized as follows:
- Region Proposal: An object detection backbone (e.g., a convolutional network or transformer) generates candidate bounding boxes or object queries. This stage may follow a two‑stage design (e.g., Faster R‑CNN) or an end‑to‑end design like DETR.
- Visual Encoding: Each region or object query is encoded into a feature vector using a visual encoder such as a ResNet or vision transformer. Modern OVDs often reuse CLIP’s image encoder or a similar backbone.
- Text Encoding: The detector encodes the names of the classes of interest using a text encoder (often CLIP’s text encoder or a BERT style model). Because the vocabulary is not fixed, users can provide new class names at inference time.
- Similarity Scoring: The model computes similarity scores between region features and text embeddings and assigns each region the label with the highest similarity.
Most open-vocabulary object detectors start from a standard detector trained on a fixed set of object classes. They then use vision language models to extend detection beyond this closed set. There are various types of VLM based OVD methods such as:
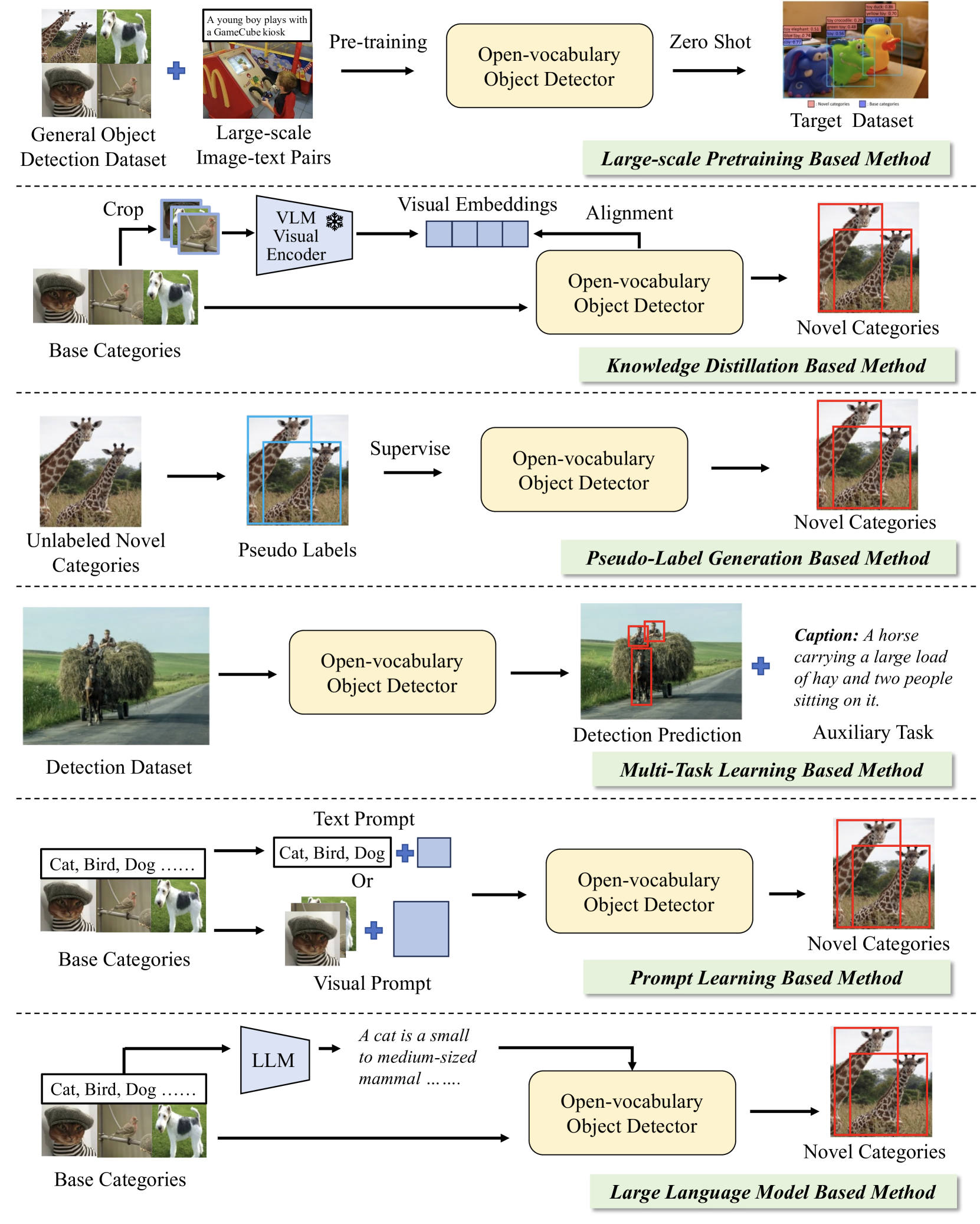
Large-Scale Pretraining Based Methods: These methods train the detection model on very large image-text datasets so it can learn to match visual regions with text descriptions across many concepts. They rely on large amounts of multimodal data to boost zero-shot capability.
Examples:
- GLIP jointly pre-trains vision and language features with region-level supervision.
- RegionCLIP extend CLIP style training to region-level alignment between image regions and text.
- OWL-ViT / OWLv2 adapts vision transformers for open-vocabulary.
- YOLO-World / OV-DINO bring open-vocabulary capabilities into efficient detector backbones pre-trained on large multimodal collections.
Learning Strategy Based Methods: These methods do not rely just on massive pretraining. Instead, they use smart training strategies to inject vision-language knowledge into a detector that starts with a smaller, labeled dataset (often a base set of annotated object boxes). The main strategies include:
- Knowledge Distillation: The detector learns from a pretrained vision-language model by aligning its region features to text features. Example: ViLD.
- Pseudo-Label Generation: A vision-language model generates labels for unlabeled image regions, which are then used to train the detector. Example: VL-PLM.
- Multi-Task Learning: Combining detection with other tasks so that language supervision helps generalize to new categories.
- Prompt Learning: Learning text prompts that help the model adapt better to novel category names. Example: PromptDet.
- Large Language Model Based Methods: Some recent approaches use language models to generate or refine class descriptions or prompts, helping the detector interpret complex category semantics more flexibly.
What Is Promptable Segmentation?
Segmentation is the task of identifying the exact pixels that belong to an object. Traditional segmentation methods include semantic segmentation (labeling every pixel by class), instance segmentation (separating individual objects), and panoptic segmentation (combining both). All of these approaches rely on a fixed set of classes defined during training.
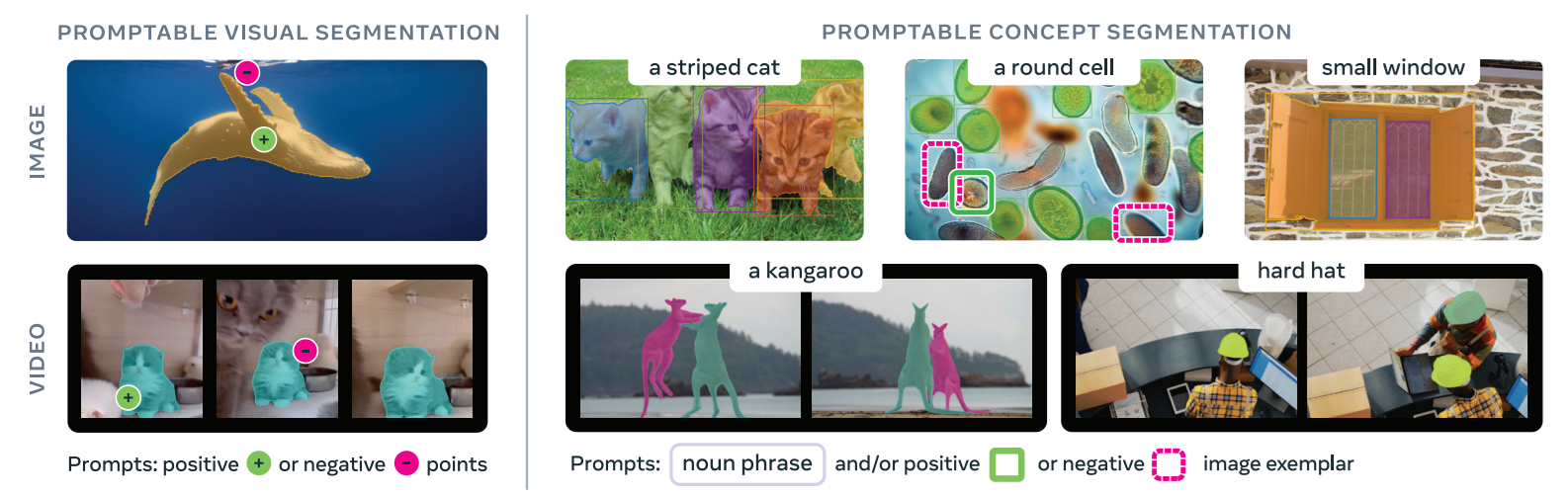
Promptable segmentation removes this restriction by allowing segmentation to be driven by prompts instead of fixed labels. Models such as the Segment Anything Model (SAM) and its successor SAM 3 enable this behavior by accepting inputs like text phrases, points, boxes, or example images. Instead of selecting from predefined categories, the model segments all objects that match the given prompt, such as “red apple” or “striped cat.”
SAM 3 extends this idea further by supporting promptable concept segmentation and tracking across images and videos. Given a text description, image examples, or a combination of both, the model can detect, segment, and track all instances of the specified visual concept while maintaining object identities across frames.
Promptable segmentation is especially useful when object categories are unknown in advance or when precise pixel-level masks are needed for flexible, interactive workflows.
The Foundation: Vision Language Models
At the core of both open‑vocabulary detection and promptable segmentation lies the vision language model. A VLM learns to align visual and textual representations. By training on pairs of images and captions, VLMs map images and their corresponding descriptions to nearby points in a joint embedding space. When you encode an image and a sentence through the model, the similarity of their embeddings reflects how well the sentence describes the image.
CLIP and Contrastive Learning
CLIP is one of the most widely used multimodal vision and language model. It has two parts, an image encoder and a text encoder. During training, CLIP learns to pull matching image-text pairs closer together and push non-matching pairs apart. This contrastive training allows the model to learn many visual concepts using natural language instead of fixed class labels. Open-vocabulary detectors use CLIP or CLIP style models to match object regions with text prompts, allowing them to recognize many concepts learned from large-scale image–text data.
Where Do CLIP‑Style Models Fit in OVD and Segmentation?
CLIP and similar vision language models play a supporting role in both open-vocabulary detection and promptable segmentation. Their role can be understood in three simple ways:
- Foundation for cross‑modal alignment: OVD models uses pre‑trained VLMs like CLIP to encode class names and visual regions. It uses a visual encoder (often CLIP’s image tower) to embed cropped proposals and a text encoder to embed class names. The detector then computes similarity scores and assigns labels.
- Teacher for knowledge distillation: Many OVD methods distill knowledge from CLIP into their detection backbones.
- Prompt encoder in segmentation: Promptable segmentation models also use CLIP style encoders to process text or image prompts. SAM 3 encodes text descriptions and visual examples to detect, segment, and track all instances of a requested visual concept across images or videos.
Despite their central role, CLIP‑style models do not detect or segment objects by itself. These models must be integrated into task‑specific architectures. Using CLIP alone will return a global similarity score for an image and a text prompt, but it cannot localize the object. OVD and promptable segmentation models provide the localization component by generating proposals or mask queries.
Why Open‑Vocabulary ≠ Zero‑Shot Everything
The phrase “open-vocabulary” does not mean a model can recognize every concept without guidance. There are important distinctions between open-vocabulary, zero‑shot and open‑set/ open‑world detection.
Zero‑Shot vs. Open‑Vocabulary
Zero-Shot detection detects objects from classes that were not seen during training by learning to map visual features to semantic embeddings (like word vectors or attributes).
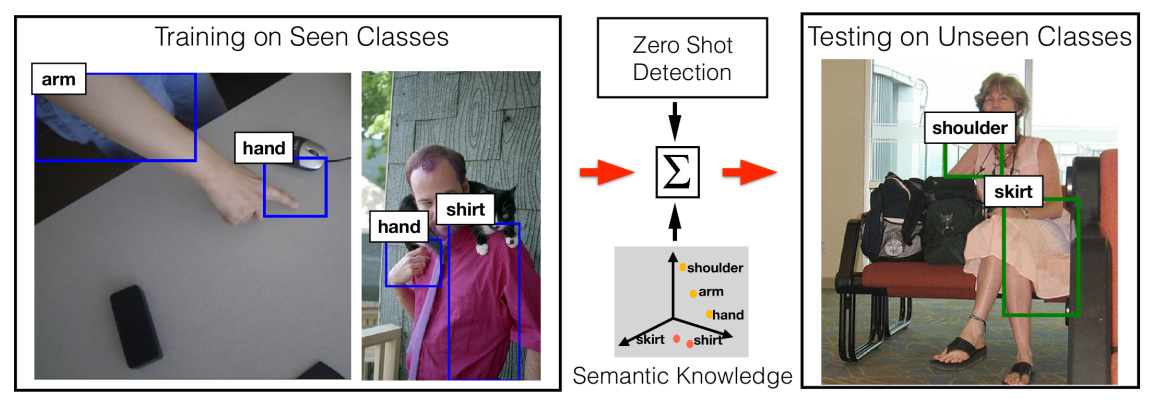
Open-Vocabulary detection detects objects using arbitrary class names provided at inference time by aligning region features with text embeddings from a vision-language model (like CLIP).
Open-vocabulary detection uses large-scale vision language models pretrained on image-text pairs, enabling more flexible and scalable detection across broader vocabularies compared to earlier zero-shot approaches.
So, in simple terms, zero-shot detection emphasizes the ability to detect classes not seen during training, while open-vocabulary detection emphasizes flexibility in accepting arbitrary class names at runtime. In practice, both can handle combinations of seen and unseen classes (see figure below).
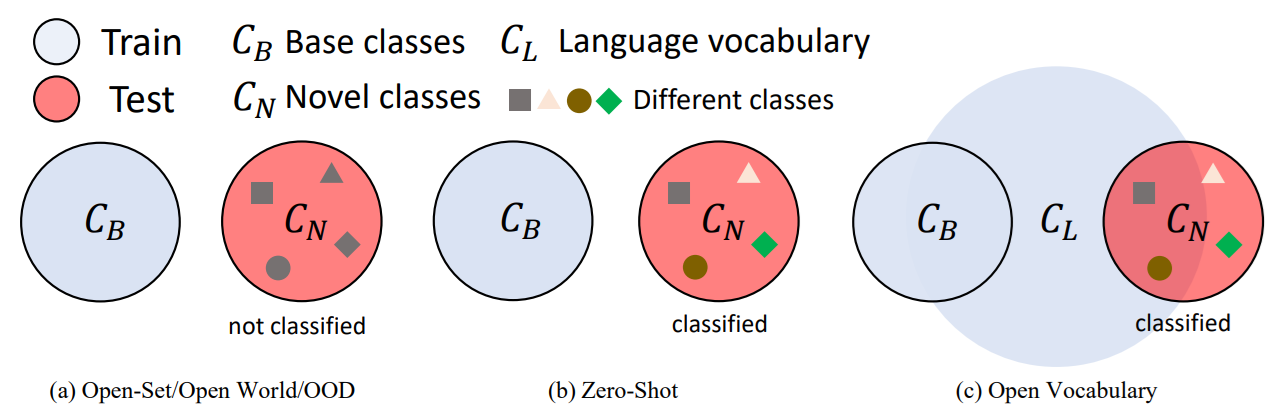
Open-Vocabulary vs. Open-Set and Open-World
These are also the other terms that need to be understood. Open-set detection focuses on rejecting unknown objects. The model detects known classes and labels everything else as "unknown" without trying to classify it further.
Open-world detection goes one step further by allowing the model to gradually learn and discover new classes over time.
Open-vocabulary detection is different from both. It does not simply reject unknown objects, nor does it automatically discover new categories. Instead, it can classify objects from any class if the user provides the class name as a text prompt.
Open-Vocabulary Example using Roboflow
You can build open-vocabulary object detection applications using Roboflow easily. Within your Roboflow workflow, you can use open-vocabulary object detection models such as Florence-2. We have prepared a detailed guide on how you can use Florence-2 model in Roboflow workflows.
Alternatively you can use Roboflow Autodistill and use the OWL-ViT (a Simple Open-Vocabulary Object Detection with Vision Transformers), to build the application. In this section I’ll guide you how to do this.
The OWL-ViT model aligns image regions with text prompts, so new object types can be queried at inference time without retraining.
Step 1: Install required libraries
Install Roboflow, Autodistill, OWL-ViT, and Supervision to run open-vocabulary detection.
pip install roboflow autodistill autodistill-owl-vit supervisionStep 2: Define the vocabulary (ontology) and load the OWL-ViT model
Specify object names as text prompts and map them to class labels (for example, egg, tomato in our case). Initialize the model with your ontology. No training is required.
from autodistill_owl_vit import OWLViT
from autodistill.detection import CaptionOntology
base_model = OWLViT(
ontology=CaptionOntology(
{
"egg": "egg",
"tomato":"tomato"
}
)
)Step 3: Run inference on an image
Pass an image path to the model to get bounding boxes, class IDs, and confidence scores.
result = base_model.predict("breakfast.jpg")Step 4: Visualize the detections
Draw bounding boxes and labels on the image using Supervision for easy inspection.
import cv2
import supervision as sv
image_path = "breakfast.jpg"
image = cv2.imread(image_path)
detections = result
id2label = {0: "egg", 1: "tomato"}
labels = [
f"{id2label.get(int(cid), 'unknown')}"
for cid in detections.class_id
]
box_annotator = sv.BoxAnnotator(thickness=2)
label_annotator = sv.LabelAnnotator(text_thickness=2, text_scale=0.6)
annotated = box_annotator.annotate(scene=image.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections, labels=labels)
cv2.imwrite("annotated.jpg", annotated)When you run the code on the following input image:

You will see output similar to the following:

Open-Vocabulary Object Detection Conclusion
Open-vocabulary object detection changes the shape of a vision system. Instead of hard-coding the world into a fixed label list, you get a detector that can adapt at runtime - asking for new things in plain language without collecting boxes and retraining every time requirements shift. They work best as a new layer in your toolbox: ideal for long-tail concepts, rapid iteration, bootstrapping datasets, and building systems that can evolve.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jan 16, 2026). Open-Vocabulary Object Detection Explained. Roboflow Blog: https://blog.roboflow.com/open-vocabulary-object-detection/