
Object detection research is white hot! In the last year alone, we've seen the state of the art reached by YOLOv4, YOLOv5, PP-YOLO, and Scaled-YOLOv4. And now Baidu releases PP-YOLOv2, setting new heights in the object detection space.
State of the art object detection architectures are designed with practical application in mind - that is, researchers must weigh the tradeoffs of inference speed with prediction accuracy. The faster and more accurate you can infer the better.
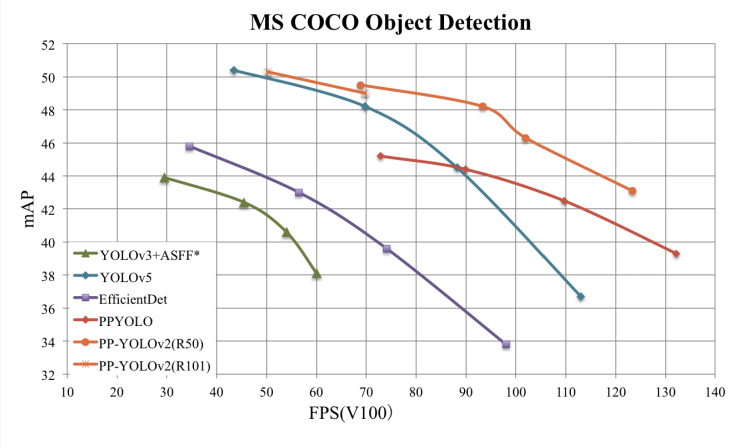
In terms of speed and accuracy, PP-YOLOv2 is the new best model for object detection.
A Brief History of YOLO
YOLO (You Only Look Once) is a family of object detection models, so named because they predict an object's bounding box and the object's class in a single forward pass through the network. YOLO models have absolutely dominated the object detection scene because of the accuracy they produce for relatively low compute requirements during training and inference.

YOLO was originally written in the Darknet framework by Joseph Redmon (github moniker pjreddie). He took YOLO to YOLOv2 and YOLOv3, eventually leaving the game due to ethical concerns.
Joseph Redmon passed the baton to AlexeyAB who leveled the Darknet network up to YOLOv4 and YOLOv4-tiny.
To the benefit of many ML practitioners, Glenn Jocher (github moniker glenn-jocher) ported YOLOv3 out of Darknet and into PyTorch, and while doing so, released the fastest training and very accurate YOLOv5.
The YOLOv5 framework was scaled up by WonKinYiu to produce the most accurate object detector in the game, Scaled YOLOv4.
Meanwhile, in the Baidu world, Baidu researchers have been working on their own version of YOLO in the Paddle Paddle deep learning farmework.
Enter PP-YOLO and enter PP-YOLOv2.
What Does PP Stand For?
PP is short for PaddlePaddle, a deep learning framework written by Baidu.

If PaddlePaddle is news to you, then we are in the same boat.
PP-YOLOv2 Research Contributions
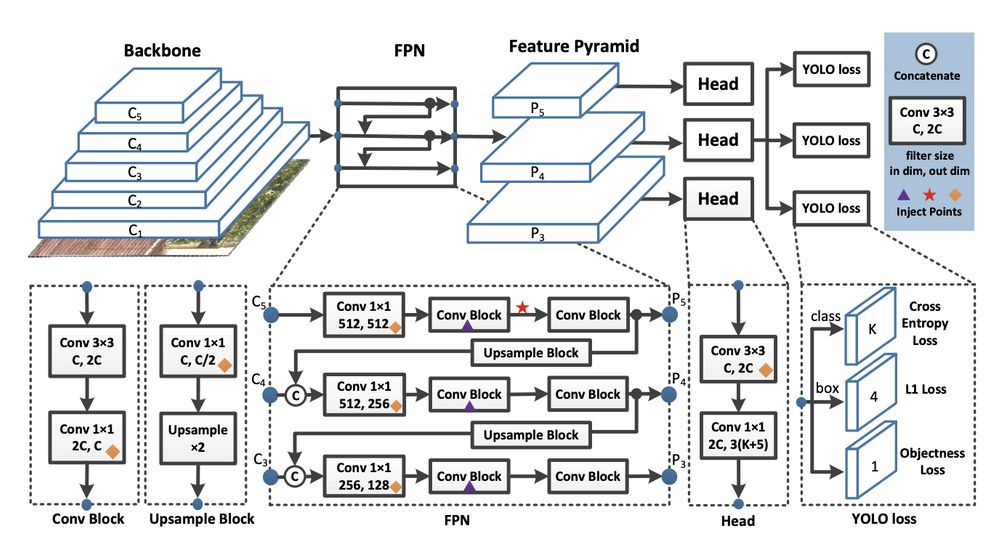
PP-YOLOv2 builds on the research advancements made by PP-YOLO. PP-YOLO took the YOLOv3 network and made iterative improvements in training and and architecture by adding a Resnet backbone, DropBlock regularization, IoU loss, Grid Sensitivity, Matrix NMS, CoordConv, SPP layers, and a better ImageNet pretraining checkpoint.

To build on this progress, PP-YOLOv2 adds a few known techniques to the object detector, carefully experimenting with what changes work well together on the COCO dataset.
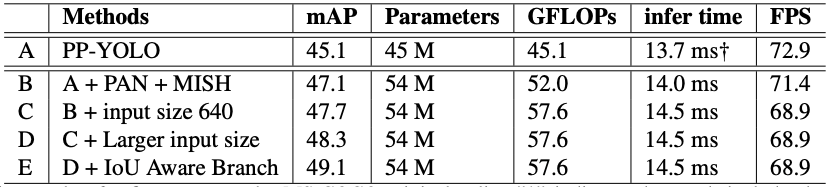
The PP-YOLOv2 authors first add the Path Aggregation Network to the neck of their object detector. Then they add the mish activation function to the neck of their object detector (but not to the backbone, preferring to use the ImageNet pretrained backbone). Next, they increase image input size, drawing uniformly across different input sizes [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]. Finally, the authors tune YOLO's loss function to make it more aware of the overlap between bounding boxes (IoU Aware).
Using these techniques, the authors compare their newly forged PP-YOLOv2 against other similar object detection models in deployment conditions.
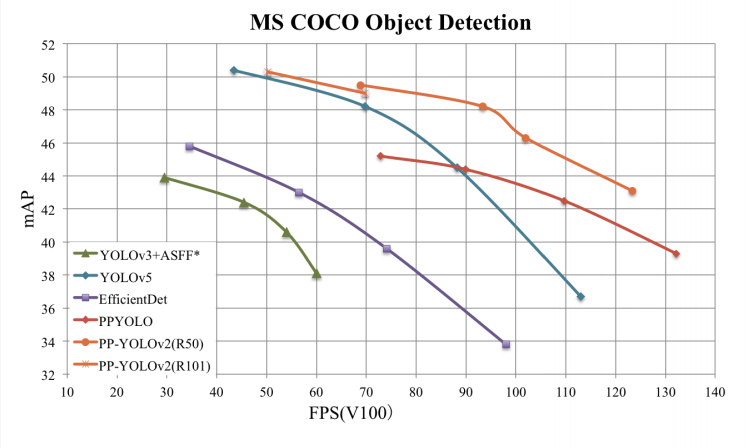
For the evaluation they evaluate on the well-known Microsoft Common Objects in Context dataset. Inference time is measured as the time it takes to infer against a single frame on a Tesla V100 GPU. Inference speeds are measured both with and without TensorRT acceleration.
PP-YOLOv2 Take the Plunge?
You may be wondering (as am I) if its time to take the plunge into the Paddle Paddle framework to train PP-YOLOv2. If you decide to give it a whirl, the code and training routines are all open source in the PaddleDetection repository.
Before you train PP-YOLOv2 on your own custom data, you should first gather images, label them, and export to the Pascal VOC dataset format.
Stay tuned by subscribing in the top right for future updates on how to train PP-YOLOv2!
You can also consider abstracting the training with Roboflow's one-click training solution.
Happy training - and most importantly, happy inferencing!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (May 11, 2021). PP-YOLO Strikes Again - Record Object Detection at 68.9FPS. Roboflow Blog: https://blog.roboflow.com/pp-yolo-strikes-again/