
Today, we’re excited to release a preview of RF-DETR Keypoint, a real-time, end-to-end keypoint detection model. On COCO Keypoints, the preview checkpoint beats YOLO26x-pose (the largest model in the newest YOLO pose family) on both accuracy and speed. Scaled up, the same weights come within 0.6 AP of GroupPose Swin-L at less than a tenth of the latency. The preview checkpoint is pinned at one NAS-chosen operating point: 576×576, where it leads the field. But because RF-DETR Keypoint is NAS-trained like the rest of the RF-DETR family, the same weights keep working as you scale the input resolution down for speed or up for accuracy. Train once, get a family of options.

But SOTA on COCO is the demo, not the design. Like the rest of the RF-DETR family, this model is built to be fine-tuned: best-in-class accuracy without a COCO-tuned loss function. Train it on your dataset, and NAS finds your architecture while the probabilistic loss calibrates itself to your keypoints - no hand-measured tolerances required. That probabilistic treatment, predicting a full distribution over each keypoint’s location rather than a bare (x, y), turns out to solve several problems at once, including a quiet, decade-old hyperparameter problem that makes most state-of-the-art keypoint models awkward to train on your own data. More on that below.
Since launching RF-DETR in March 2025, we’ve grown it into a family of state-of-the-art real-time detection models, added instance segmentation, and published the RF-DETR paper (published at ICLR 2026), describing how we use weight-sharing neural architecture search to find the best accuracy-latency tradeoff for any dataset. Keypoints are the next step.
As with our segmentation preview, we’re releasing this model early, before the final family of checkpoints and the accompanying paper, because we want real-world feedback to shape the final models. You can start using it today.
Introducing RF-DETR Keypoint Preview
RF-DETR Keypoint extends the RF-DETR architecture with a keypoint head built directly into the detection transformer. For every object the model detects, it also predicts a structured set of keypoints, in a single forward pass: no NMS, no heatmaps, no post-hoc grouping of keypoints into people.
The preview checkpoint is trained on COCO Keypoints (people, 17 keypoints). But the COCO checkpoint is just the starting point. The architecture supports arbitrary skeletons: any number of keypoints, on any object class, with multiple keypointed classes in a single model. People are the benchmark; license-plate corners, surgical instrument tips, robot-arm joints, and gauge needles are the point.
Here’s what makes it different from the keypoint models most people use today.
No hand-tuned keypoint bandwidths: the model learns them
There’s a hyperparameter hiding inside nearly every state-of-the-art keypoint model, and almost nobody talks about it.
COCO evaluates keypoints using OKS (Object Keypoint Similarity), which needs to know how much localization slop to tolerate for each keypoint: a hip can reasonably be annotated over a wider region than the corner of an eye. So the COCO team measured per-keypoint tolerances (“bandwidths,” the OKS sigmas) empirically: they had 5,000 validation images redundantly annotated and, for each keypoint type, measured how widely the annotators’ placements spread relative to object scale. Those 17 hand-measured constants didn’t stay in the evaluator: they migrated into the training losses of most modern keypoint models. YOLO11-pose bakes them into its keypoint loss; YOLO26-pose inherits that same sigma-based loss and adds a second set of hand-chosen per-keypoint weights on top of it. GroupPose hardcodes them into both its training loss and its Hungarian matching cost. ED-Pose and PETR do the same and, as released, refuse to run if your skeleton doesn’t have exactly 17 (COCO) or 14 (CrowdPose) keypoints.
That’s fine on COCO. But what happens on your dataset? Nobody redundantly annotates their own dataset just to measure per-keypoint variance. So the models quietly fall back: Ultralytics’ pose models, for instance, substitute a uniform constant for every keypoint the moment your skeleton isn’t COCO’s. The carefully tuned loss that produced the benchmark numbers is no longer the loss you’re training with.
RF-DETR Keypoint doesn’t need to be told these bandwidths, because it learns them. Each keypoint’s predicted distribution has a learned spread (a full 2D covariance: scale, shape, and orientation), and the model is trained by maximizing the likelihood of the ground truth under its own predictions. Keypoints that are inherently ambiguous learn wide distributions; precisely-defined ones learn tight distributions. The loss self-calibrates, per keypoint, per class, from your data: the same mechanism on COCO people as on your custom skeleton. The loss that produces the benchmark numbers is exactly the loss you fine-tune with.
Uncertainty you can actually use downstream
Probabilistic keypoint training isn’t new: Residual Log-likelihood Estimation (RLE) popularized it, and the newest YOLO generation, YOLO26, adopts an RLE-style loss with a normalizing flow to model the keypoint error distribution during training (alongside, not replacing, the sigma-based loss above). We think this is the right direction, and RF-DETR Keypoint shares the same core insight.
But there’s a catch with a normalizing flow: the learned distribution has no closed form. Estimating the likelihood of any given point requires evaluating a neural network, which is why these models typically use the flow only during training and discard it at inference, keeping just the (x, y) estimate. The uncertainty is used to train the model, then thrown away.
RF-DETR Keypoint instead parameterizes each keypoint’s distribution as a full-covariance 2D Gaussian — slightly less expressive than a flow, but with a closed-form density. That means the uncertainty survives all the way to your code, in a form that’s standard and directly usable:
- A drop-in observation model. A Gaussian is exactly what a Kalman filter, a tracker, a weighted least-squares skeleton fit, or a camera-calibration pipeline expects as input. If you feed keypoints into a tracker today, you’re probably hand-tuning a constant measurement noise for each one; RF-DETR Keypoint hands you a per-frame, per-keypoint covariance instead, with no extra network evaluations.
- A confidence ellipse for every keypoint. A motion-blurred wrist comes back with a visibly larger ellipse than a nose in plain view. Downstream logic (rep counting, ergonomic checks, sports analytics) can weight or discard keypoints accordingly, instead of treating a wild guess and a confident lock the same.
- Better accuracy, for (almost) free. At inference, we use each detection’s average keypoint uncertainty to modulate its confidence score, so detections with sloppy keypoints rank below detections with precise ones. In our COCO evaluations this uncertainty-aware rescoring adds about a point of AP for trivial extra compute: a few arithmetic operations per detection, far below the noise floor of any latency measurement. It’s included in every RF-DETR accuracy number we report.
And these uncertainties are calibrated, not just directionally correct. On COCO val2017, measured over detections matched to ground truth, 41% of keypoints fall inside the model’s predicted 1σ ellipse and 84% inside 2σ; for a perfectly calibrated 2D Gaussian, those numbers would be 39% and 86%. The ellipse means what it says.
On top of the location distribution, the model predicts two separate signals per keypoint that most models collapse into one: whether the keypoint is findable (is it present in the image at all? An ankle cropped out of frame isn’t) and whether it’s visible (present, but directly seen rather than occluded). If you’ve ever tried to build logic on a single keypoint confidence that conflates “occluded,” “out of frame,” and “model isn’t sure,” you know why we split these. Here’s all of it working together:

On the left, every keypoint looks equally authoritative. On the right, the model tells you what kind of estimate each one is. The batter’s joints in plain view get tight, solid ellipses; the crouching catcher’s ambiguous hips get wide ones. Occluded joints — the catcher’s far arm behind his body, the batter’s right elbow behind the umpire’s head — are drawn dashed: localized, but flagged as probably not directly visible. And the umpire’s left arm gets no location at all: the model predicts it isn’t findable. As far as the model is concerned, that arm is outside the frame.
One checkpoint, every speed
RF-DETR Keypoint is trained with the same weight-sharing neural architecture search as RF-DETR detection and segmentation: at every training step, the model sees a randomly sampled sub-architecture (resolution, patch size, decoder depth, query count, attention window count), so a single set of weights learns to run well across thousands of configurations. The preview release pins the configuration that won at its latency target, and because the weights are NAS-trained, you can slide it from 4.5 ms to ~26 ms just by changing the input resolution, with no retraining (each resolution compiles to its own engine from the same weights).
This matters beyond deployment flexibility. When you fine-tune RF-DETR Keypoint on your own dataset, NAS can find the architecture configuration that’s optimal for your data and your latency budget, not just for COCO. That’s what NAS-enabled training on the Roboflow platform will automate. Keypoint configuration is unusually dataset-dependent (two keypoints on a glue stick is a very different problem from 17 on a person in a crowd), which makes per-dataset architecture optimization especially valuable here.
How It Works
We’ll save the full details for the paper, but here’s the sketch.
RF-DETR Keypoint represents keypoints as queries inside the transformer decoder, alongside the instance queries that handle detection, in the spirit of GroupPose. There are no heatmaps anywhere: keypoints are regressed directly as continuous coordinates, and they participate in the Hungarian matching that trains every DETR. A query is assigned to a ground-truth object based on how well its box, class, and keypoints agree, so detection and pose are learned jointly rather than as separate stages. Each instance query carries one keypoint query per keypoint in its class’s skeleton, initialized by conditioning a learned set of embeddings on the instance’s features. The conditioning is AdaLN-Zero-style, borrowed from diffusion transformers, and lets keypoint learning ramp up gradually without destabilizing detection training. The keypoint queries are refined through the decoder layers along with everything else: they attend to image features and to each other within their instance, so the skeleton stays coherent. And because the query budget is fixed, keypoint compute doesn’t grow with the number of people in the frame.
One detail we like: keypoints feed back into detection. Each keypoint query contributes a small additive term to its object’s classification logit, so an instance whose keypoints form a coherent skeleton scores higher as a detection than one whose keypoints land in noise. Pose stops being a passenger on top of detection and starts helping it.
Every prediction — boxes, classes, keypoints, and their distributions — is supervised at every decoder layer, which is what makes the architecture compatible with NAS-style decoder-layer dropping at inference time.
Model Performance
All numbers are COCO val2017 Keypoint AP, with latency measured end-to-end (time to usable predictions) on an NVIDIA T4 GPU with TensorRT FP16, for both RF-DETR and YOLO26-pose. End-to-end is the number that matters when you deploy.
We re-benchmarked every model in this comparison ourselves, under one protocol: standard COCO evaluation on the full 5,000-image val2017 set, in the same harness for every model. (For GroupPose we report its published accuracy; see the note below the table.) As we discussed in the RF-DETR paper, published numbers are often not comparable across model families: latency may or may not include postprocessing, and AP protocols quietly differ. Ultralytics, for example, evaluates its pose models on only the 2,346 val2017 images that contain keypoint-labeled people, excluding more than half of the val set, which means its models are never penalized for predicting a person where none exists. That’s why the YOLO26-pose numbers in this post are slightly lower than the ones Ultralytics publishes: under the standard protocol, false positives count.
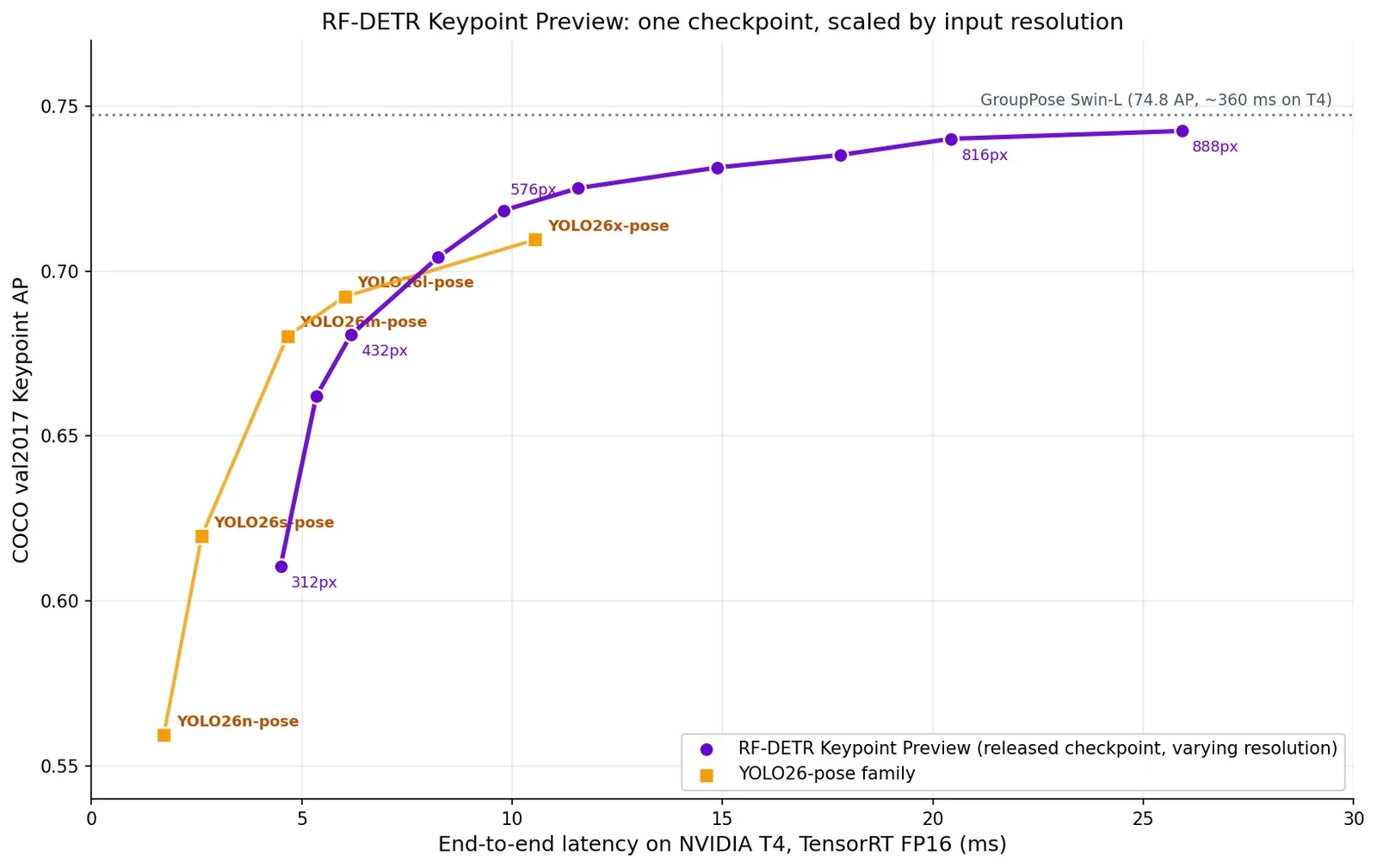
A few operating points of the single preview checkpoint:
| Input resolution | Keypoint AP | Latency (ms) |
|---|---|---|
| 312×312 | 61.1 | 4.5 |
| 432×432 | 68.1 | 6.2 |
| 576×576 | 71.8 | 9.8 |
| 816×816 | 74.0 | 20.4 |
| 888×888 | 74.2 | 25.9 |
Every row is the same released checkpoint in the same configuration (only the input resolution changes), and all numbers include the uncertainty-aware rescoring described above.
For reference: YOLO26x-pose, the largest YOLO26-pose model, achieves 71.0 AP at 10.6 ms; the preview checkpoint at 576×576 beats it on both accuracy and latency. At the high end, the same checkpoint reaches 74.2 AP — 0.6 behind GroupPose Swin-L, a state-of-the-art end-to-end pose model from academia that is far from real-time: in the same T4 harness, GroupPose runs at roughly 360 ms per frame, about 13× slower than the 888×888 operating point that nearly matches its accuracy.
Since the GroupPose paper reports no speed for its Swin-L model, the 360 ms is our own measurement, and it comes with assumptions worth stating. GroupPose’s published accuracy relies on per-image dynamic input shapes, and we found it challenging to make its shifted-window attention pattern resolution-dynamic in TensorRT. In the spirit of steelmanning, we pair its published 74.8 AP with the latency of the best fixed-shape TensorRT engine we could build, even though that engine reaches 73.8 AP and we couldn’t reproduce the published accuracy with any TensorRT-compatible engine. The author-provided PyTorch implementation, which does reproduce it, is significantly slower: roughly 630 ms per frame in the same T4 harness.
One caveat, and it’s worth being precise about: every YOLO26-pose size is a separately trained model, while every point on the RF-DETR curve is the same checkpoint, scaled away from the 576×576 configuration NAS selected for it. At and above its native operating point, it leads the field. Stretched below it, it currently trails the YOLO26-pose sizes that are purpose-built for those latency targets; we haven’t pinned low-latency checkpoints yet.
That’s a deliberate choice. Where our segmentation preview targeted the fast end of the curve, we aimed this preview at slower-but-higher accuracy, responding to a consistent piece of feedback: once a model runs faster than real time, many users would rather spend the headroom on accuracy. The full, non-preview release will cover the whole curve with a family of checkpoints. That’s part of why this is a preview: we’d rather gather real-world feedback on the approach now and fold it into the optimization of the full family than polish every operating point first.
Apache 2.0 - Use It Anywhere
RF-DETR Keypoint Preview is released under the Apache 2.0 license: code and weights, free for commercial use, no copyleft obligations, deployable inside closed-source products. We think this matters as much as the benchmark numbers. The most widely used pose models today, Ultralytics’ YOLO family, are AGPL-3.0, code and weights alike. In practice that means open-sourcing your derivative work, including the application built around it, or buying an enterprise license — even for many internal commercial uses. If licensing has been the thing standing between your team and shipping a pose model, it isn’t anymore.
Using RF-DETR Keypoint Preview
The preview is available in the open-source RF-DETR repository:
from rfdetr import RFDETRKeypointPreview
model = RFDETRKeypointPreview()
key_points = model.predict("image.jpg", threshold=0.5)
# each prediction includes: box, class, score, and per-keypoint (x, y),
# findable/visible confidences, and a 2x2 covarianceFine-tuning on your own skeletons works the same way as it does for detection and segmentation. You can use this notebook to get started.
To be clear about where things will live: running and fine-tuning the preview model will be supported both in the open-source repository and on the Roboflow platform. NAS-enabled training, the per-dataset architecture search described above, will be available through the platform.
Beyond COCO
Everything in this post is benchmarked on COCO, because that’s the comparison everyone can check. But “custom-fit everywhere else” is the half of the promise we care most about — and we intend to prove it.
The combination of a self-calibrating loss and per-dataset NAS makes RF-DETR Keypoint more than a model: it’s a tool for generating models. Point it at a dataset: the loss calibrates itself to the keypoints, and NAS finds the architecture that best trades accuracy against latency there. We’re going to run that pipeline, using the Roboflow platform, on popular non-COCO keypoint datasets, and release the resulting NAS-optimized models.
This Is a Preview: Tell Us What You Find
We’re releasing RF-DETR Keypoint as a preview deliberately: a snapshot of how far we’ve come, in your hands while we’re still building. The architecture and training recipe described here are working well in our evaluations, but real-world usage always surfaces things benchmarks don’t: failure modes, domains where the uncertainty estimates drift out of calibration, skeletons we haven’t thought about. Feedback from teams inside and outside Roboflow will shape what comes next:
- Improved checkpoints across the full accuracy-latency curve, particularly at the low-latency end
- Fine-tuning and NAS-enabled training on the Roboflow platform, so the architecture is optimized for your dataset and latency budget
- NAS-optimized releases for popular keypoint datasets
- The RF-DETR Keypoint paper, with full training details, ablations, and benchmarks
If you hit a bug or have feedback, open an issue on the RF-DETR GitHub repository or leave a comment below. If there’s a public keypoint dataset you want a purpose-built model for, tell us there; requests directly set our priority order. And if you build something with it, tag [@Roboflow](https://x.com/roboflow) — we’d love to see it.
Cite This Post
If you use RF-DETR Keypoint in your research before the paper is available, please cite this post:
@misc{rfdetr-keypoint-preview,
title = {Real-Time Keypoint Detection with RF-DETR},
author = {Robinson, Isaac},
howpublished = {\url{https://blog.roboflow.com/rf-detr-keypoint-preview/}},
year = {2026},
month = jun,
note = {Accessed: [date]}
}For the RF-DETR architecture itself, please cite the RF-DETR paper.
Cite this Post
Use the following entry to cite this post in your research:
Isaac Robinson. (Jun 17, 2026). Real-Time Keypoint Detection with RF-DETR. Roboflow Blog: https://blog.roboflow.com/real-time-keypoint-detection-with-rf-detr/