
Meta has introduced SAM 3D, a groundbreaking release alongside Segment Anything Model 3 that brings common sense 3D understanding to natural images. SAM 3D is a new generative model designed to reconstruct full 3D objects including their shape, texture, and spatial layout from just a single 2D image.
What makes it especially powerful is its ability to handle real-world photos, where objects may be partly hidden, surrounded by clutter, or viewed in messy environments. Instead of breaking down in these conditions, SAM 3D uses visual cues from the surrounding scene to make intelligent predictions about the hidden or unclear parts of the object. This release comprises two specialized models:
- SAM 3D Objects: Designed for robust object and scene reconstruction in everyday environments.
- SAM 3D Body: Which focuses on accurate human body pose and shape estimation even in challenging conditions.
With the combination of synthetic training, real-world alignment, massive datasets, and transformer based architectures, SAM 3D pushes single-image 3D reconstruction far beyond traditional limits. It brings high-quality, common-sense 3D understanding to natural images thus opening the door to new possibilities in AR, robotics, gaming, and creative applications.
SAM 3D Models
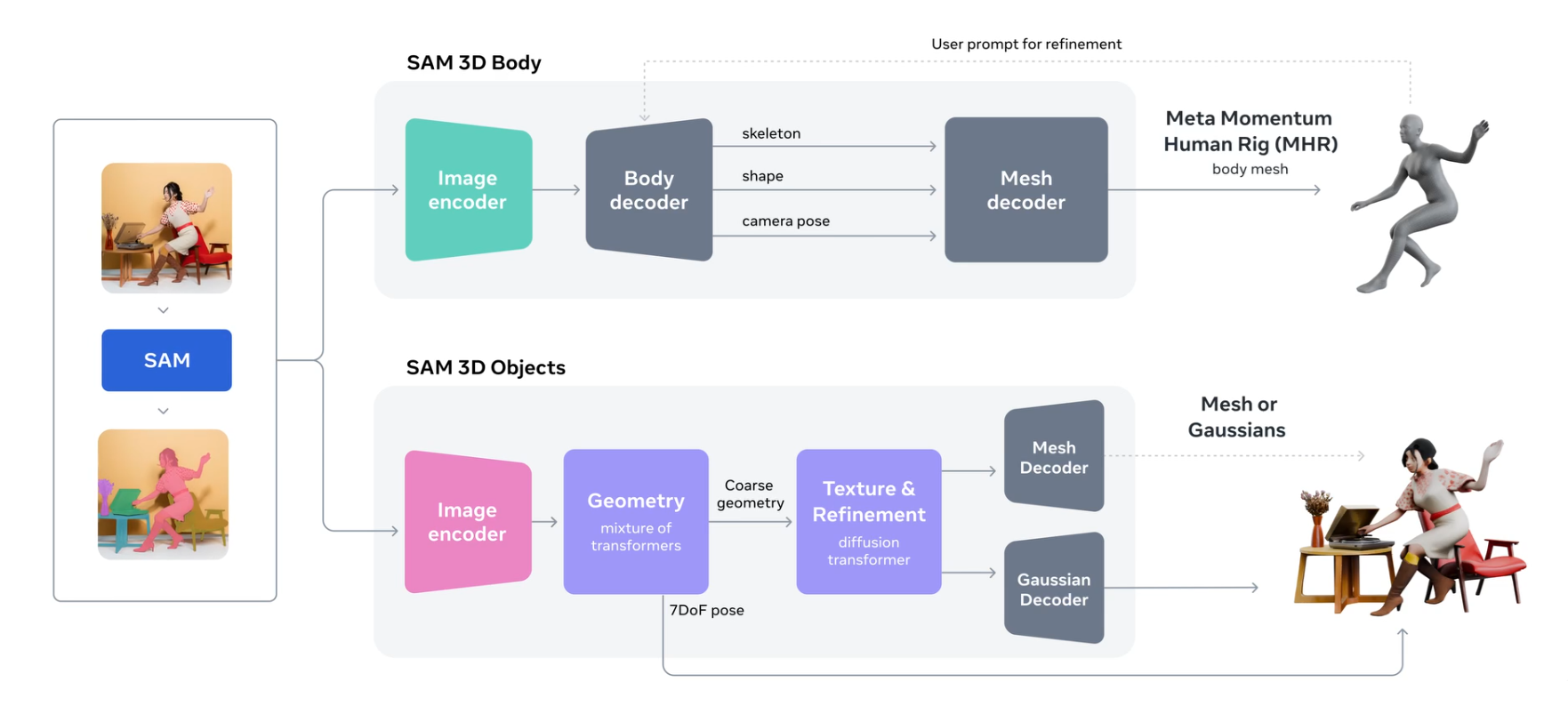
SAM 3D is a generative neural network that performs full 3D reconstruction from a single image. It can recover the complete 3D structure of an object, even in the complex scenes where the object is partially visible. Because it predicts the full 3D geometry, not just the visible 2.5D surface, the reconstructed object can be re-rendered from any viewpoint. The system consists of two foundation models, SAM 3D Objects and SAM 3D Body, that can work independently or together to reconstruct complete 3D scenes containing both objects and humans.
SAM 3D-Objects
SAM3D-Objects is a foundation model designed for visually grounded 3D object reconstruction from a single image. It predicts full 3D shape geometry, texture, and camera-relative layout, and it performs reliably even in natural scenes with strong occlusion and clutter.
The model is trained using a human- and model-in-the-loop data engine that annotates object shape, texture, and pose at large scale, combined with a multi-stage training pipeline that blends synthetic pretraining with real-world alignment. This approach helps overcome the traditional 3D “data barrier” and leads to major improvements over previous 3D generation methods.

SAM 3D Object Architecture
SAM 3D follows a two-stage architecture that transforms a single image and its mask into a detailed 3D object. The system first predicts coarse 3D shape and object layout, then refines that shape and adds realistic texture. The following figure shows this flow clearly.
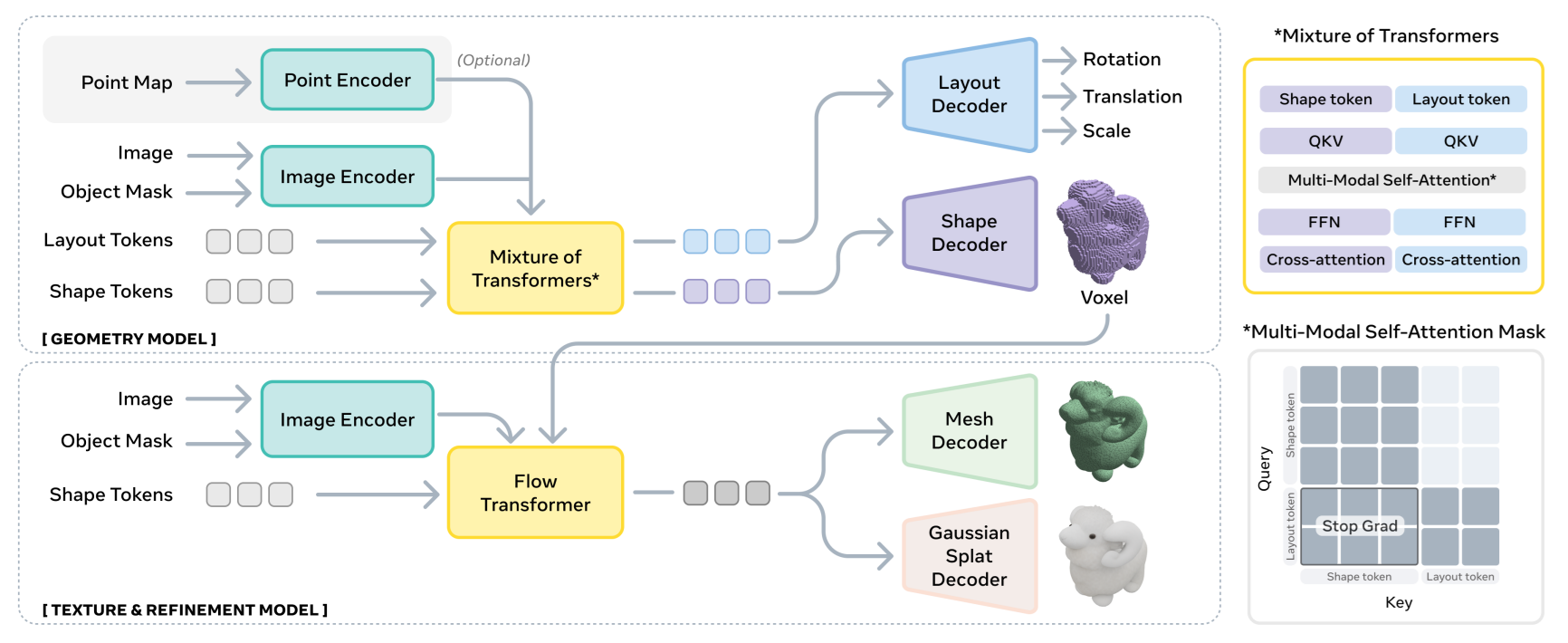
The top part is coarse prediction, the bottom part is refinement, and the right side shows the Mixture-of-Transformers (MoT) module that enables information sharing across different processing streams.
1. Input Encoding
The pipeline starts with input encoding. SAM 3D uses DINOv2 to extract features from two views of the input image, resulting in four sets of conditioning tokens:
- Cropped-object view (cropped RGB + cropped mask) for high-resolution local detail
- Full-image view (full RGB + full-image mask) for global context and scene understanding
These four encoded inputs become conditioning tokens that guide the rest of the model. SAM 3D can also accept an optional scene point map obtained via hardware sensors such as LiDAR or monocular depth estimation which helps in estimating layout more accurately.
2. Geometry Model (Stage 1)
The first major block is the Geometry Model, which predicts a coarse 3D voxel representation of the object and its layout in the scene (rotation, position, and scale). A coarse 3D voxel representation in SAM 3D is simply a rough, low-resolution 3D grid that describes the basic shape of the object before any fine details or textures are added. This Geometry model is a 1.2B-parameter flow transformer built using the Mixture-of-Transformers (MoT) architecture.
The MoT uses a two-stream approach:
- One transformer handles shape tokens (4,096 tokens from the 64³ voxel representation in the latent space of a coarser 16³ × 8 representation)
- A second transformer, with shared parameters across rotation (R), translation (t), and scale (s), handles layout tokens (1 token each for R, t, s)
- Both streams share information through multi-modal self-attention layers
This design ensures that the predicted shape and the predicted pose remain consistent with each other. The structured attention mask allows independent training of some modalities while maintaining performance on others, which is particularly useful when datasets contain labels for only one modality.
3. Texture & Refinement Model (Stage 2)
Once the coarse voxels are produced, they move into the Texture & Refinement Model. This stage uses a 600M-parameter sparse latent flow transformer. It examines only the active voxels (the parts of the shape that actually matter) and adds higher-resolution geometry along with realistic texture.
The refinement stage uses an improved Depth-VAE, which back-projects image features only to visible voxels (those not occluded from the current viewpoint). This approach leads to sharper details and avoids texture blur on occluded regions. The depth information is used to construct a visibility mask, filtering out occluded points during feature aggregation.
4. 3D Decoders (Output)
Finally, the refined 3D representation is passed through the 3D decoders. SAM 3D supports two output formats:
- Mesh decoder (Dm) for polygon meshes
- Gaussian-splat decoder (Dg) for point-based neural rendering (up to 32 splats per occupied voxel)
Both decoders share the same VAE encoder, so their outputs stay consistent and exist in the same latent space. This shared encoding ensures compatibility between the two output representations.
Key Architectural Features
- The MoT architecture enables structured attention that allows for modality-specific processing while maintaining cross-modal consistency
- The sparse latent representation focuses computational resources only on occupied voxels, improving efficiency
- The Depth-VAE improvement addresses a key limitation of previous approaches by preventing feature bleeding into occluded regions
- The dual-decoder design provides flexibility in output format while maintaining consistency through shared latent space
SAM 3D Training Framework
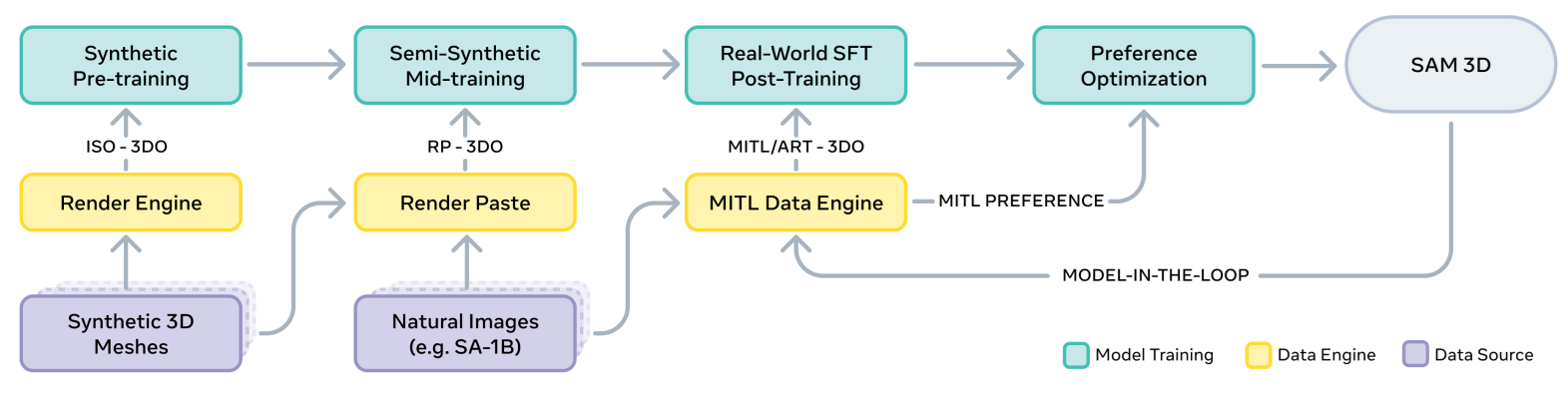
SAM 3D is trained using a multi-stage pipeline that gradually teaches the model harder skills. Starting with simple synthetic objects and ending with realistic, human-aligned 3D reconstructions. This strategy is similar to how LLMs or robotics models learn i.e. first build basic capabilities, then expose the model to more complex data, and finally align it with human preferences.
1. Pretraining
Training begins with large-scale synthetic pretraining, where the model learns essential skills like shape generation and texture prediction. It is trained on isolated 3D assets from datasets such as Objaverse-XL, rendered from many viewpoints. At this stage the model learns what objects look like in 3D, but only in clean, simple conditions.
2. Mid-Training
Mid-training adds more challenging, semi-synthetic data. Here the model learns:
- mask-following (using a binary mask to focus on one object)
- occlusion robustness (objects partly hidden by others)
- layout estimation (position and scale in camera coordinates)
The team creates a large “render-paste” dataset where synthetic objects are composited into natural images with realistic lighting, occludes, and background clutter. This teaches SAM 3D to handle scenes that are closer to the real world.

3. Post-Training
Once the model understands shapes, masks, and occlusion, it is adapted to real images through a data engine. This engine iteratively:
- generates 3D candidates using the current model
- asks human annotators to pick the best ones
- uses those preferred examples to update the model
This process is repeated multiple times, forming a human-in-the-loop feedback loop that steadily improves quality.
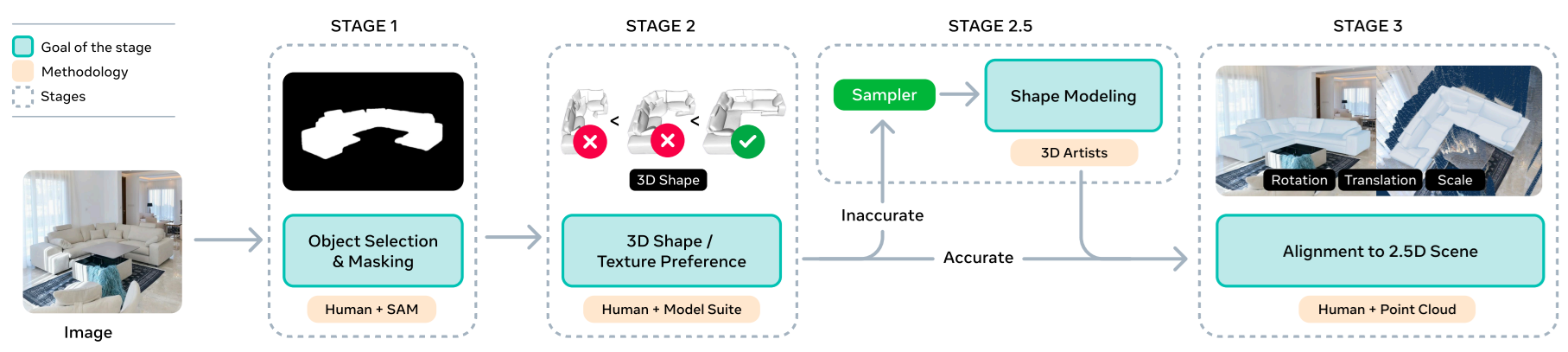
Post-training includes three major steps:
3.1 Supervised Fine-Tuning (SFT)
The model is fine-tuned on real data collected through the annotation pipeline:
- non-expert annotations (MITL-3DO)
- high-quality 3D artist annotations (Art-3DO)
This helps the model follow real-world cues and learn aesthetic properties like symmetry and closure.

3.2 Direct Preference Optimization (DPO)
After SFT, the model is further aligned to human judgments. Annotators compare multiple 3D outputs and select the best one; these preferred vs. non-preferred pairs are used for preference optimization, improving realism and removing common errors.
3.2 Distillation
Finally, the model is distilled to run faster. The number of flow-matching steps is reduced from 25 -> 4 to enable sub-second shape and layout prediction during inference.
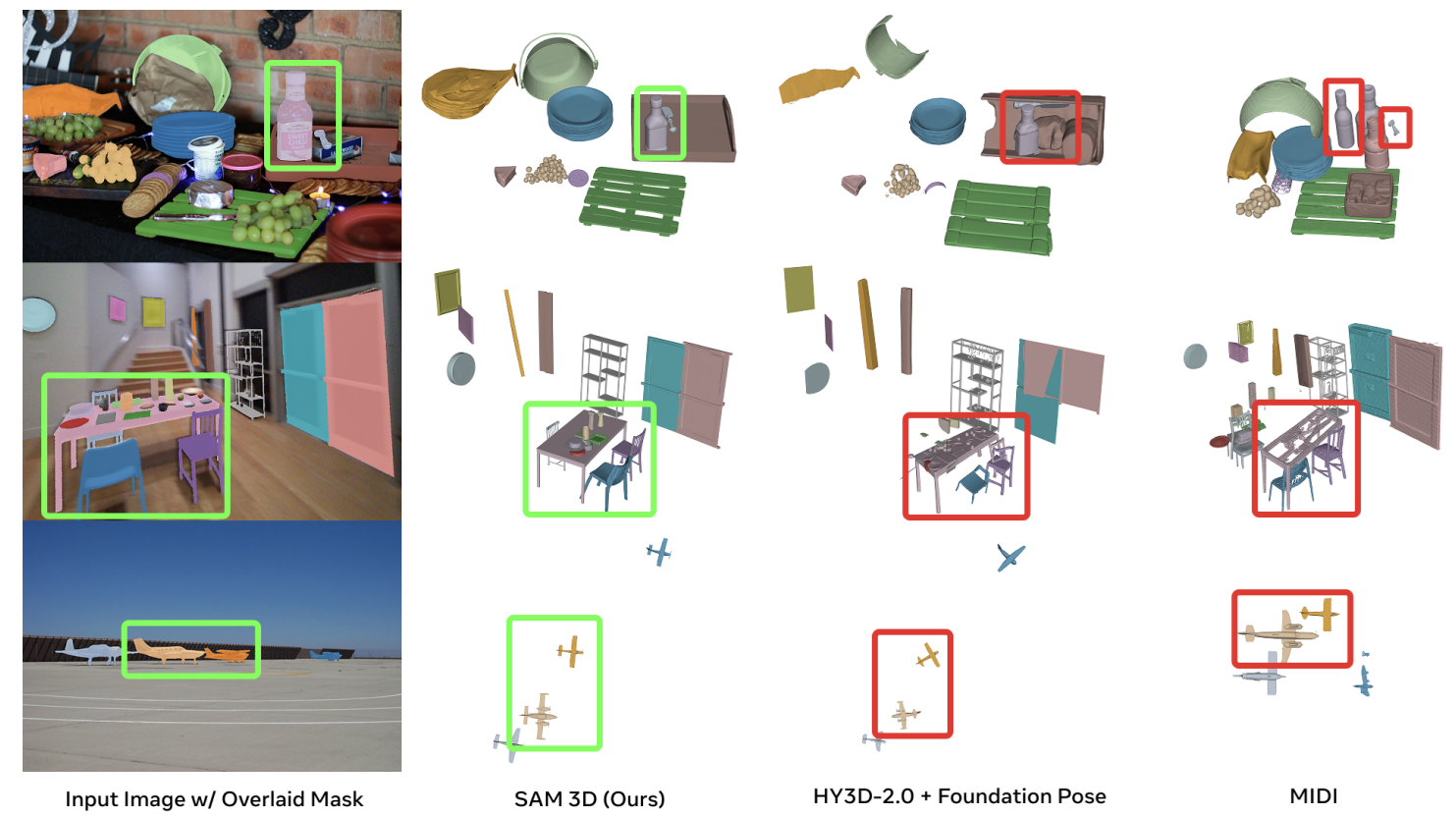
In human preference tests, SAM 3D Objects achieves at least a 5:1 win rate over other leading 3D reconstruction models. The model can return full textured reconstructions within seconds through optimization techniques including diffusion shortcuts and engineering optimizations, enabling near real-time applications.
SAM 3D Body
SAM 3D Body (3DB) is a promptable model that recovers a full 3D human body mesh from just a single image. It delivers state-of-the-art human mesh recovery (HMR) and works reliably across a wide range of real-world scenes, poses, and camera conditions.
A key feature of 3DB is that it estimates the complete human body including the pose of the body, feet, and hands, as well as body shape which make it a unified full-body reconstruction system. It is also the first model to use the new Momentum Human Rig (MHR), a parametric mesh representation that decouples skeletal structure from surface shape. This decoupling provides richer control and interpretability for full-body reconstruction.

Both SAM 3D Body and the Momentum Human Rig are fully open-source, making them accessible for research and real-world applications.
SAM3D Body Architecture
AM 3D Body (3DB) is designed to recover a full 3D human body mesh from a single image in a flexible, controllable way. The model supports interactive inputs, meaning it can incorporate extra hints such as 2D keypoints or segmentation masks to refine the reconstruction. This promptable design gives the system more context when handling difficult poses, occlusions, or unusual viewpoints, and allows users or downstream applications to guide the prediction process when needed.
To achieve this, 3DB uses a promptable encoder–decoder architecture, inspired by the SAM family. The architecture has three main components:
- Image Encoder
- Decoder Tokens
- MHR Decoder (Body + Hands)
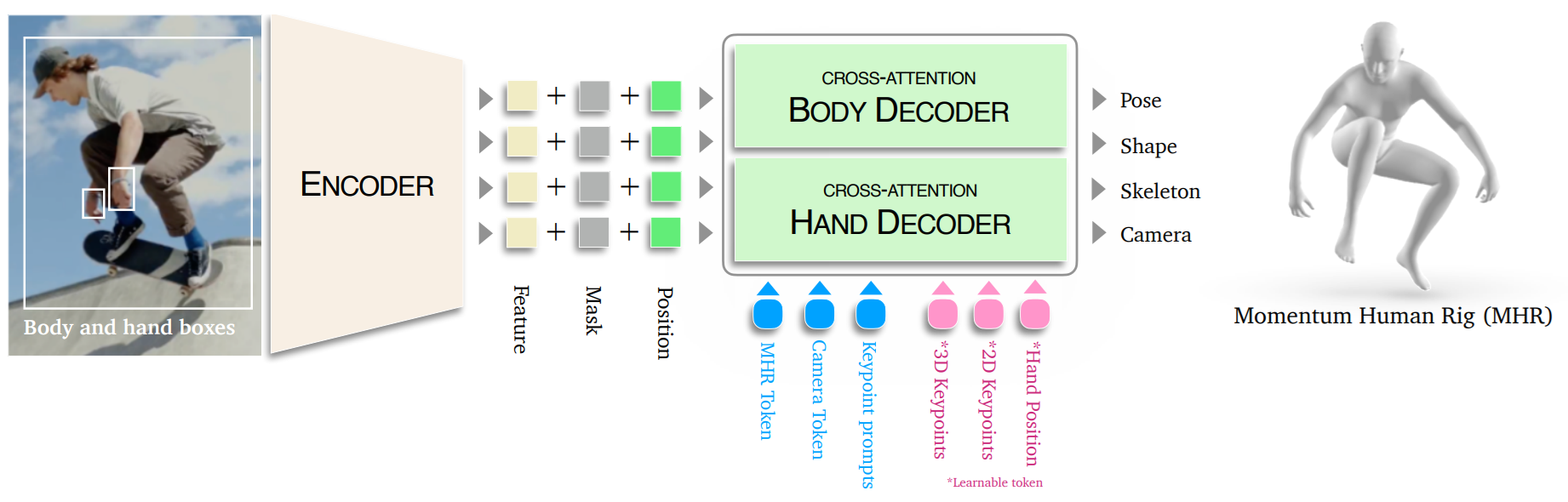
Let’s understand each components:
1. Image Encoder
The image encoder forms the visual backbone of SAM 3D Body. It receives a human-cropped image and converts it into a dense feature map (F) using a transformer-based vision backbone. If hand-focused crops are provided (optional), they are processed separately to produce hand-specific feature maps (Fhand), which supply the model with the fine detail needed for accurate finger and palm reconstruction. The encoder also handles optional prompts:
- 2D keypoint prompts which are transformed into tokens using positional encodings combined with learned embeddings.
- Mask prompts which are embedded with convolution layers and added directly to the image features.
Together, the encoder outputs the main image features (F), optional hand features (Fhand), and the encoded prompt information that will guide later stages of the model.
2. Decoder Tokens
Decoder tokens act as the model’s internal “queries”. Each token tells the decoder what information to retrieve or refine. SAM 3D Body uses several categories of tokens:
- MHR + Camera Token: A learnable token that encodes an initial estimate of the human’s pose, shape, camera parameters, and skeleton. This token serves as the starting point for predicting the final Momentum Human Rig parameters.
- 2D Keypoint Prompt Tokens: Tokens created when external or user-provided 2D keypoints (x, y, label) are available. These tokens help the model resolve ambiguous areas, particularly when joints are occluded or partially visible.
- Auxiliary 2D/3D Keypoint Tokens: Learnable tokens that represent every 2D and 3D joint. They strengthen the model’s ability to reason about body articulation and support tasks such as joint prediction and uncertainty estimation.
- Hand Position Tokens: Two optional tokens, one for each hand, that guide the model in locating the hands within the image. These tokens enhance hand estimation but are not mandatory for producing a full-body mesh.
All tokens are combined into a single set:
T = [Tpose, Tprompt, Tkeypoint2D, Tkeypoint3D, Thand]
This unified token design enables 3DB to operate in both fully automatic and prompt-guided configurations.
3. MHR Decoder (Body Decoder + Optional Hand Decoder)
The MHR decoder converts visual and prompt information into the final 3D mesh.
The body decoder receives the full set of query tokens (T) along with the full-body image features (F). Through cross-attention, it fuses what the tokens represent with what the image contains, producing a refined set of output tokens:
O = Decoder(T, F)
The first output token, O₀, is passed through an MLP to regress the Momentum Human Rig parameters, including:
- P - Pose
- S - Shape
- C - Camera pose
- Sₖ - Skeleton parameters
This produces the complete full-body 3D human mesh.
An additional hand decoder can be used when hand crops are available. It processes the same prompt tokens but attends to hand-specific features (Fhand) to generate more precise hand predictions. During inference, predictions from the body decoder and hand decoder can be aligned using wrist and elbow keypoints as prompts, and then merged according to the kinematic structure of the MHR model.
SAM 3D Training and Inference
SAM 3D Body is trained using a multi-task framework that simultaneously supervises 2D keypoints, 3D keypoints, MHR parameters, camera pose, and hand locations. The model learns from a mix of real-world, multi-view, and synthetic datasets, and uses prompt-aware training strategies so it can operate with or without guidance such as 2D keypoints or masks.
Loss functions for pose, shape, camera, and keypoints combined with anatomical priors and warm-up schedules, help the model learn stable and realistic 3D human meshes. During inference, the body decoder produces the full MHR mesh from a single cropped image, and the hand decoder can optionally refine finger and palm details when hand crops are available. The final output integrates all predictions into a consistent full-body 3D mesh, with prompt tokens enabling user-guided refinement when needed.
Cross-Model Integration in SAM 3D
One of SAM 3D's most powerful features is the ability to combine both models to create unified 3D scenes. Meta provides an example notebook demonstrating how to:
- Use SAM 3D Body to generate human meshes with focal length metadata
- Use SAM 3D Objects to reconstruct object Gaussian splats
- Align and scale the meshes to match coordinate systems
- Compose aligned meshes and object splats into coherent 3D scenes
This integration enables comprehensive scene reconstruction from single photographs containing both people and objects, opening new possibilities for mixed-reality applications, virtual production, and spatial computing.
Getting Started with SAM 3D
Meta has made SAM 3D widely accessible. You can use it in the browser to experiment or set up a local environment for research.
Accessing Models and Code
The SAM 3D Objects code and checkpoints are available on GitHub under the facebookresearch/sam‑3d‑objects repository. Similarly, SAM 3D Body resides in the facebookresearch/sam‑3d‑body repository. The code is licensed under the SAM License (a permissive license similar to Apache 2.0) and is free for commercial use
Installation and Environment Setup
To use SAM 3D Objects locally, you need a GPU‑enabled Python environment. The project provides a setup script that creates a sam3d-objects conda environment and installs dependencies including PyTorch, Pytorch3D and hydra. After activating the environment, you download the model checkpoints. Meta distributes the checkpoints via Hugging Face (facebook/sam-3d-objects). You must request access and authenticate with the Hugging Face CLI to download them.
The installation steps can be summarized as follows:
Step #1: Create and activate environment
mamba env create -f environments/default.yml
mamba activate sam3d-objects
Step #2: Install dependencies (including Pytorch3D and other inference libraries):
# for pytorch/cuda dependencies
export PIP_EXTRA_INDEX_URL="https://pypi.ngc.nvidia.com https://download.pytorch.org/whl/cu121"
# install sam3d-objects and core dependencies
pip install -e '.[dev]'
pip install -e '.[p3d]' # pytorch3d dependency on pytorch is broken, this 2-step approach solves it
# for inference
export PIP_FIND_LINKS="https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-2.5.1_cu121.html"
pip install -e '.[inference]'
# patch things that aren't yet in official pip packages
./patching/hydra # https://github.com/facebookresearch/hydra/pull/2863Step #3: Download checkpoints
pip install 'huggingface-hub[cli]<1.0'
TAG=hf
hf download \
--repo-type model \
--local-dir checkpoints/${TAG}-download \
--max-workers 1 \
facebook/sam-3d-objects
mv checkpoints/${TAG}-download/checkpoints checkpoints/${TAG}
rm -rf checkpoints/${TAG}-downloadSAM 3D Body also requires a setup. The README notes that there are two available models on Hugging Face, facebook/sam-3d-body-dinov3 and facebook/sam-3d-body-vith, and you must request access before downloading. After setting up the environment, you can load the model via the provided Python API.
Running Inference with SAM 3D
Once installed, running inference with SAM 3D Objects is straightforward. The repository includes a demo.py script that loads a model, reads an image and a segmentation mask, and produces a 3D reconstruction:
import sys
# import inference code
sys.path.append("notebook")
from inference import Inference, load_image, load_single_mask
# load model
tag = "hf"
config_path = f"checkpoints/{tag}/pipeline.yaml"
inference = Inference(config_path, compile=False)
# load image and mask
image = load_image("notebook/images/shutterstock_stylish_kidsroom_1640806567/image.png")
mask = load_single_mask("notebook/images/shutterstock_stylish_kidsroom_1640806567", index=14)
# run model
output = inference(image, mask, seed=42)
# export gaussian splat
output["gs"].save_ply(f"splat.ply")The output includes both a Gaussian splat and a full textured mesh. You can export the mesh in formats such as .obj, .ply or .glb and open it in software like Unity.
The above example uses a single segmentation mask to isolate an object. In practice, you might first run a 2D segmentation model such as SAM 3 (Segment Anything 3) or DeepLab to obtain masks for all objects in the scene. You can then feed each mask to SAM 3D Objects individually. If you wish to tweak the reconstruction, you can adjust the diffusion seed (seed=42 in the example) or the noise schedule to explore alternative shapes and textures. The inference code also supports batched processing by passing a list of (image, mask) pairs and the model will return a list of reconstructions.
For SAM 3D Body, the demo.py script loads an image and returns a 3D mesh. You can optionally supply 2D keypoints or a segmentation mask to guide the reconstruction. The output mesh is compatible with the Momentum Human Rig, allowing for animation and pose editing.
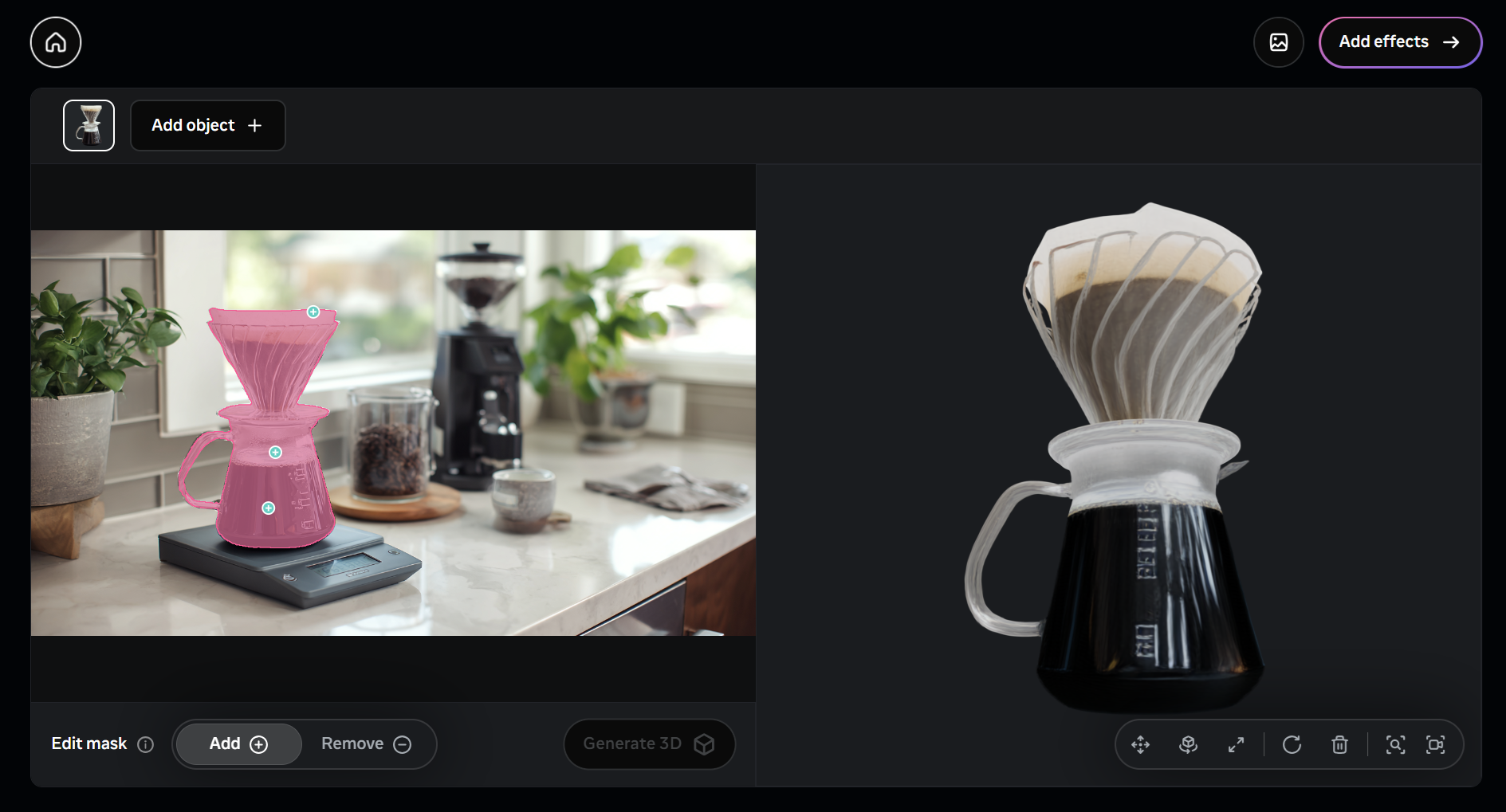
SAM 3D Playground
For users who want to experiment without setting up a local environment, Meta provides the Segment Anything Playground. The Playground lets you upload your own images, select objects or people with clicks, and generate 3D reconstructions in the browser.
The interface also integrates other Segment Anything models, such as SAM 3, enabling users to segment objects or track them through videos. The Playground is an excellent way to quickly explore the capabilities of SAM 3D and to visualize the results before downloading the full models.

Conclusion
Meta’s SAM 3D represents a significant leap in 3D reconstruction. By introducing two complementary models, SAM 3D Objects and SAM 3D Body, the research team has shown that it is possible to reconstruct detailed 3D shapes, textures and poses from a single image, even in cluttered and occluded scenes.
The key innovations lie in the human‑in‑the‑loop data engine, the multi‑stage training strategy that blends synthetic pre‑training with real‑world alignment, and the use of diffusion transformers and a novel Momentum Human Rig. These advances allow SAM 3D to outperform previous methods, achieving at least a 5:1 win rate in preference tests and delivering high‑quality results within seconds.
Learn about SAM 3 and how to fine-tune SAM 3.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Nov 25, 2025). Meta SAM 3D: Introduction. Roboflow Blog: https://blog.roboflow.com/sam-3d/