
Large-scale datasets have become the bedrock for training accurate and robust models in machine learning. However, as datasets grow in size and complexity, training on the entire dataset can be computationally expensive and time-consuming. This is where dataset distillation comes into play, offering a solution to reduce the computational requirements of the training process while preserving crucial information.
Dataset distillation refers to the process of selecting a subset of data samples that encapsulate the most vital and representative characteristics of the original dataset. By distilling the dataset, we aim to create a smaller, refined version that retains the statistical properties and generalization capabilities of its larger counterpart.
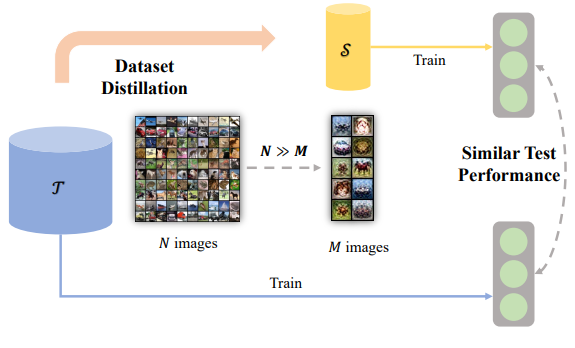
In this blog post, we will delve into dataset distillation, exploring its purpose, methodologies, and applications. We will discuss some of the recent methods that have emerged as effective techniques for dataset distillation, such as performance matching, distribution matching, and parameter matching.
Additionally, we will explore the wide range of applications where dataset distillation proves invaluable. From resource-constrained environments to scenarios with colossal datasets, dataset distillation empowers us to train models more efficiently without sacrificing performance.
Let’s get started!
What is Dataset Distillation?
Dataset distillation is a technique in machine learning that concerns selecting a representative subset of data samples from a larger dataset while retaining the essential information and statistical properties of the original dataset. The goal of dataset distillation is to create a more compact and manageable version of the dataset that still captures the key characteristics necessary for training machine learning models.
By distilling a dataset, the computational requirements (i.e. cost) for training machine learning models can be reduced while maintaining or even improving performance. This can be particularly valuable in resource-constrained environments, projects with large-scale datasets, or when faster iterations and experimentation are required.
The process of dataset distillation involves several steps:
- Data Analysis: The first step in dataset distillation is to analyze the original dataset. This analysis includes understanding the data distribution, identifying important features, and determining the key characteristics that need to be preserved in the distilled dataset.
- Sample Selection: Once the data analysis is complete, the next step is to select a subset of samples that represent the original dataset. Various selection techniques can be employed, such as instance selection, prototype selection, or representative sample selection. These techniques aim to choose samples that capture the diversity, representativeness, and relevance of the original data.
- Selection Criteria: The selection of samples for the distilled dataset is guided by specific criteria. These criteria can vary depending on the goals of the dataset distillation process. For instance, diversity criteria aim to ensure that the selected samples cover different regions of the data space. Representativeness criteria ensure that the selected samples reflect the distribution of the original dataset. Relevance criteria focus on selecting samples that are relevant to the problem at hand.
- Distilling Knowledge: Dataset distillation techniques can employ various approaches to select representative samples, discussed below.
- Evaluation and Validation: After the distilled dataset is created, it is important to evaluate the effectiveness of the dataset in achieving a robust model. This evaluation involves assessing whether the distilled dataset retains the important statistical properties, generalization capabilities, and performance characteristics of the original dataset. The distilled dataset should be validated through appropriate evaluation measures and compared to the performance of models trained on the full dataset.
The effectiveness of dataset distillation depends on the specific task, the quality of the original dataset, the selection criteria, and the chosen distillation techniques. It is essential to carefully analyze the dataset, choose appropriate selection methods, and evaluate the performance of models trained on the distilled dataset to ensure its usefulness and reliability.
In the next section, we will delve into recent methodologies for dataset distillation: Performance Matching, Distribution Matching, and Parameter Matching. We will explore each approach and examine their effectiveness in creating distilled datasets.
Methodologies for Dataset Distillation
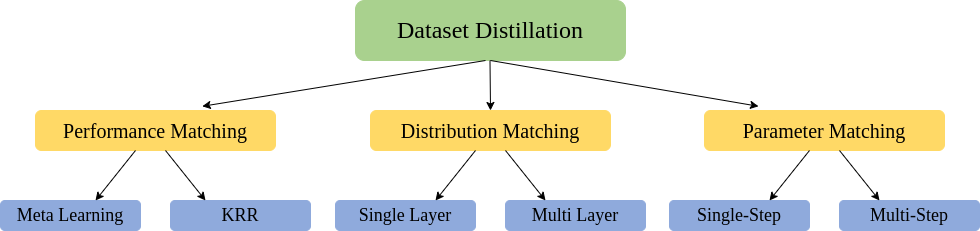
There are three main categories of data distillation methodologies, classified based on various optimization objectives: performance matching, parameter matching, and distribution matching.
Each category encompasses several methods. We will provide a description of two methods for each category. The categorization of data distillation can be observed in the accompanying figure.
Performance Matching
Performance matching refers to a category of methodologies that aim to train a smaller, distilled model to match the performance of a larger, more complex model. The objective is to transfer the knowledge and capabilities of the larger model to the smaller one while maintaining similar levels of performance on a given task.
In performance matching, the distilled model is trained using a dataset that is typically generated from the predictions of the larger model. The larger model is used to make predictions on a large dataset. These predictions are then used to create a distilled dataset. The distilled dataset contains the input samples along with the corresponding labels or targets generated by the larger model.
A “distilled model” is then trained on this distilled dataset, using techniques such as knowledge distillation or teacher-student learning. The goal is to train the distilled model to produce similar predictions to the larger model on the same dataset, thereby matching its performance.
By achieving performance matching through dataset distillation, it becomes possible to deploy smaller and more efficient models that can still achieve comparable performance to their larger counterparts. This can be particularly beneficial in resource-constrained environments, such as mobile devices or edge computing scenarios, where reducing the model size and computational requirements is desirable.
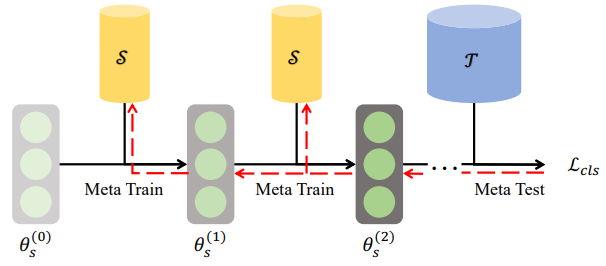
Meta-Learning
Meta-Learning, which falls under the category of Performance Matching, aims to train a smaller model to match the performance of a larger model by leveraging the principles of meta-learning.
The goal is to enable a model to learn how to learn or adapt quickly to new tasks or datasets. This is achieved by exposing the model to a diverse set of tasks during the training phase, where each task is treated as a separate learning problem.
In the context of dataset distillation and performance matching, meta-learning based methods involve training a meta-model or meta-learner on a collection of tasks. Each task consists of a dataset and a corresponding target or label. The meta-learner is trained to generate a smaller, distilled model that can quickly adapt to new datasets and achieve similar performance to the larger model.
During the training process, the meta-learner learns to optimize the parameters or initial conditions of the distilled model such that it can effectively generalize across different tasks. This involves finding the optimal initialization, architecture, or hyperparameters for the distilled model, enabling it to efficiently learn from limited amounts of data.
Once the meta-learning process is complete, the distilled model can be deployed and used to make predictions on new datasets or tasks.
Kernel Ridge Regression
The Kernel ridge regression falls under the category of Performance Matching in dataset distillation. It involves utilizing the principles of kernel ridge regression to train a smaller model that matches the performance of a larger model.
Kernel ridge regression combines the concepts of ridge regression and kernel methods. It is commonly used for regression tasks where the goal is to predict a continuous target variable. In the context of dataset distillation, kernel ridge regression can be applied to transfer knowledge from a larger model to a smaller one.
The process starts by training the larger model on a dataset, which serves as the source of knowledge. The larger model is used to make predictions on the dataset, generating a set of intermediate representations or features. These intermediate representations capture important patterns or information in the data.
Next, the intermediate representations, along with the corresponding target labels, are used to train a kernel ridge regression model. The kernel function in ridge regression allows for capturing non-linear relationships between the input features and the target variable. The smaller model, represented by the kernel ridge regression model, learns to generalize from the intermediate representations and produces predictions that match the performance of the larger model.
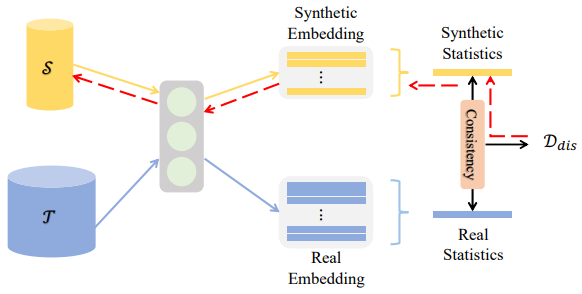
Distribution Matching
Distribution matching in dataset distillation refers to a methodology that aims to align the data distribution between a larger, source dataset and a smaller, target dataset. The goal is to ensure that the target dataset captures the same statistical properties and characteristics as the source dataset.
In dataset distillation, distribution matching is crucial because the performance of a machine learning model depends on the data it is trained on. If the target dataset does not adequately represent the distribution of the source dataset, the model may struggle to generalize well and perform accurately on unseen data. By aligning the data distribution, the distilled model trained on the target dataset can better generalize and achieve similar performance to the larger model on the same task or problem domain.
Distribution matching techniques are particularly useful when transferring knowledge from a large, labeled dataset to a smaller, unlabeled dataset, enabling the distilled model to benefit from the wealth of information present in the source dataset while being more computationally efficient and resource-friendly.
Single Layer
Single Layer Distribution Matching involves matching the data distribution at a single layer of a neural network. Ensuring that the representations of the two datasets are similar helps in capturing the underlying statistical properties and characteristics of the source dataset in the target dataset.
To achieve Single Layer distribution matching, several techniques can be employed. One common approach is to introduce an additional loss term during the training process, which encourages the representations of the source and target datasets to be similar at the designated layer.
This additional loss term can be formulated in different ways. One common method is to use a discrepancy metric, such as the maximum mean discrepancy (MMD) or the Kullback-Leibler (KL) divergence, to measure the dissimilarity between the distributions of the source and target representations at the chosen layer. The network is then trained to minimize this discrepancy, aligning the distributions of data.
Another approach is to use adversarial learning, where a separate discriminator network is introduced to distinguish between the representations of the source and target datasets at the specific layer. The network is trained to “fool” the discriminator by generating representations that cannot be easily distinguished as either source or target. This adversarial training helps in aligning the distributions of the two datasets.
Multi Layer
Multi Layer Distribution Matching aims to match the data distribution at multiple layers of a neural network architecture. The Multi Layer method focuses on aligning the representations of the source and target datasets at multiple layers, rather than just a single layer, of the neural network.
Various techniques can be employed to achieve Multi Layer distribution matching. One common approach is to use domain adaptation methods that operate at multiple layers simultaneously. These methods aim to learn transformations or mappings that minimize the distribution discrepancy between the source and target datasets across multiple network layers.
One popular technique used in Multi Layer distribution matching is domain adversarial training. In this approach, an additional domain classifier or discriminator is introduced, which aims to distinguish between the representations of the source and target datasets at multiple layers. The neural network is then trained to minimize the discrepancy between the representations while simultaneously fooling the domain discriminator.
Another approach is to use gradient reversal layers, where the gradients flowing back from the domain discriminator are reversed during training. This reversal aligns the distributions by encouraging the network to generate representations that are indistinguishable between the source and target datasets.
It's important to note that both Single Layer and Multi Layer distribution matching approaches have their advantages and may be more suitable depending on the specific dataset, task, and network architecture. The choice between the two approaches depends on factors such as the complexity of the dataset, the depth of the neural network, and the desired level of distribution alignment needed for effective knowledge transfer.
Parameter Matching
Parameter Matching is methodology that focuses on aligning the parameters or model weights between a larger, source model and a smaller, target model. The goal is to ensure that the smaller model captures the same or similar parameter values as the larger model, thereby transferring the knowledge and capabilities of the larger model to the smaller one.
Different methods can be utilized to attain parameter matching. One common approach is known as knowledge distillation. In knowledge distillation, the larger model, often referred to as the teacher model, is trained on a labeled dataset, and its predictions are used as soft targets for training the smaller model, known as the student model.
During the training process, the student model is optimized to mimic the predictions of the teacher model by minimizing a distillation loss. This loss function compares the predicted probabilities or logits of the teacher model with those of the student model. By aligning the outputs of the two models, the student model learns to capture the knowledge and decision-making process of the teacher model, even with a smaller number of parameters.
Another technique used for parameter matching is parameter initialization. In this approach, the smaller model is initialized with the parameter values of the larger model. The training process then fine-tunes these parameters on the target dataset, allowing the smaller model to converge to a similar solution as the larger model.
Parameter matching is particularly useful in scenarios where computational resources are limited, such as deploying models on edge devices or mobile platforms.
Single-Step
Single-Step Parameter Matching aims to match the parameters of a smaller target model to those of a larger source model in a single step or stage.
The Single-Step method focuses on directly aligning the parameters between the source and target models without involving intermediate steps or iterations. The goal is to transfer the knowledge and capabilities captured by the larger model to the smaller model efficiently.
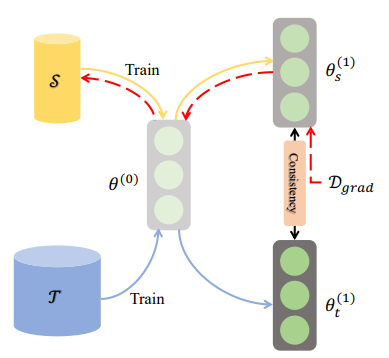
In order to accomplish Single-Step parameter matching, multiple techniques can be utilized. A frequently used strategy involves initializing the parameters of the smaller model using the parameter values from the larger model. This initialization allows the smaller model to start with similar parameter values as the larger model, providing a strong starting point for training.
Once the parameters are initialized, the smaller model is trained on the target dataset using standard optimization algorithms, such as gradient descent. During training, the parameters of the smaller model are updated to minimize a task-specific loss function, based on the desired task or objective.
Alignment of parameters between the source and target models is accomplished in a single training stage. The goal is to ensure that the smaller model captures similar knowledge and decision-making capabilities as the larger model, even though it may have a reduced number of parameters.
Single-Step parameter matching can be effective in scenarios where a quick transfer of knowledge is desired, and there is limited computational budget or training resources. It provides an efficient way to match the parameters and achieve performance improvement in the smaller model.
However, the effectiveness of Single-Step parameter matching depends on factors such as the complexity of the task, the similarity between the source and target datasets, and the size difference between the models. In some cases, more sophisticated techniques, such as Multi-Step parameter matching, may be necessary to achieve better alignment and performance in the distilled model.
Multi-Step
Multi-Step Parameter Matching aims to match the parameters of a smaller target model to those of a larger source model through multiple iterative steps or stages.
The Multi-Step method focuses on gradually aligning the parameters between the source and target models by iteratively updating the target model's parameters based on the information from the source model. This iterative process allows for a more fine-grained transfer of knowledge and enhances the alignment of the two models.
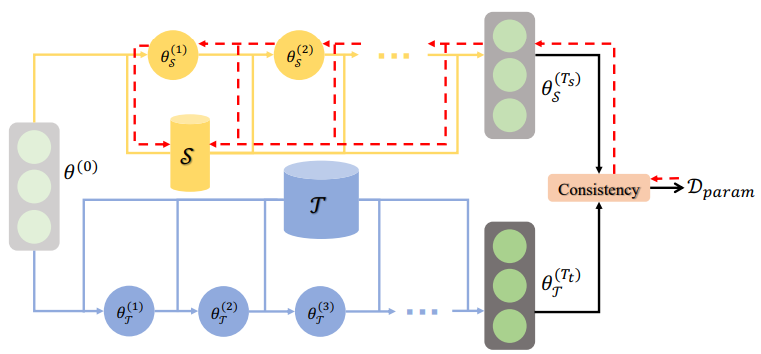
Multiple techniques can be utilized to accomplish Multi-Step Parameter Matching. Fine-tuning is a prevalent method in which the smaller target model undergoes initial training on the target dataset, employing either random or pre-trained initial parameter values. After the initial training, the parameters of the target model are iteratively updated in subsequent steps, incorporating information from the larger source model.
As opposed to Single-Step, Multi-Step matching involves a more iterative process. Instead of a single initialization step, multiple steps are taken to gradually adjust and align the parameters of the smaller model with those of the larger model. This iterative process may involve techniques such as fine-tuning, transfer learning, or other optimization methods to progressively refine the parameter values of the smaller model until they closely match those of the larger model.
By employing Multi-Step parameter matching in dataset distillation, the smaller target model can progressively acquire the knowledge and decision-making capabilities of the larger source model. This approach enables a more transfer of knowledge, resulting in improved performance on the target task.
Dataset Distillation Applications
Now that we have discussed dataset distillation and common approaches for distilling datasets, we’re ready to talk about applications of dataset distillation.
In this section, we will explore the successful and innovative applications of dataset distillation in diverse fields, including Computer Vision, Neural Architecture Search (NAS), and Knowledge Distillation (KD). Leveraging its high compression rate capabilities, dataset distillation research has led to remarkable advancements in these areas.
Computer Vision
Dataset distillation can be useful for object detection, semantic segmentation, and image classification. Let's explore the benefits of dataset distillation in each of these areas:
- Object Detection: Dataset distillation can improve object detection models by transferring knowledge from a larger object detection dataset to a smaller one. By distilling the knowledge, the smaller dataset can benefit from the rich representations, diverse object instances, and contextual information learned by the larger model. This can lead to improved object detection accuracy, robustness, and the ability to handle a wider range of object categories and variations.
- Semantic Segmentation: Dataset distillation can enhance semantic segmentation models by transferring knowledge from a larger dataset containing labeled segmentation masks. The distilled dataset can capture the spatial context, object boundaries, and semantic information present in the larger dataset. By training on this distilled dataset, the segmentation model can improve its ability to accurately classify and segment different objects and regions in images.
- Image Classification: Dataset distillation can benefit image classification models by transferring knowledge from a larger dataset containing diverse image categories. The distilled dataset can capture the discriminative features, visual patterns, and decision boundaries learned by the larger model. By training on this distilled dataset, the image classification model can improve its accuracy, generalization capabilities, and efficiency.
In all three cases, dataset distillation allows for the extraction and transfer of useful knowledge from a larger dataset to a smaller one. This process enables the smaller models to leverage the learned representations, patterns, and contextual information, resulting in improved performance, generalization, and efficiency.
Additionally, dataset distillation can address challenges such as limited labeled data, class imbalance, or noisy samples, by creating a more focused and representative training dataset.
Neural Architecture Search
Neural Architecture Search (NAS) involves automating the process of discovering optimal neural network architectures for a given task. Dataset distillation can be applied in NAS to improve the efficiency and effectiveness of the search process.
In NAS, a large amount of computational resources is often required to evaluate and compare different neural network architectures. Dataset distillation can help reduce this computational burden by distilling the knowledge from a large dataset into a smaller, representative dataset. This smaller dataset can be used during the architecture search process, enabling faster evaluation and iteration of different architectures.
By distilling the knowledge from a larger dataset, the smaller distilled dataset captures the essential patterns, statistical properties, and diversity of the original dataset. This allows the NAS algorithm to explore and evaluate a diverse range of network architectures using a reduced computational budget. Furthermore, dataset distillation can improve the generalization and transferability of the discovered architectures.
Knowledge Distillation
Dataset distillation can be employed as a part of the knowledge distillation process to improve the effectiveness of knowledge distillation. Instead of training the student model on the original dataset, the student model can be trained on a distilled dataset that captures the essential patterns, relationships, and characteristics of the original dataset. This distilled dataset can be generated using techniques such as density matching, distribution matching, or other approaches that aim to represent the knowledge embedded in the teacher model.
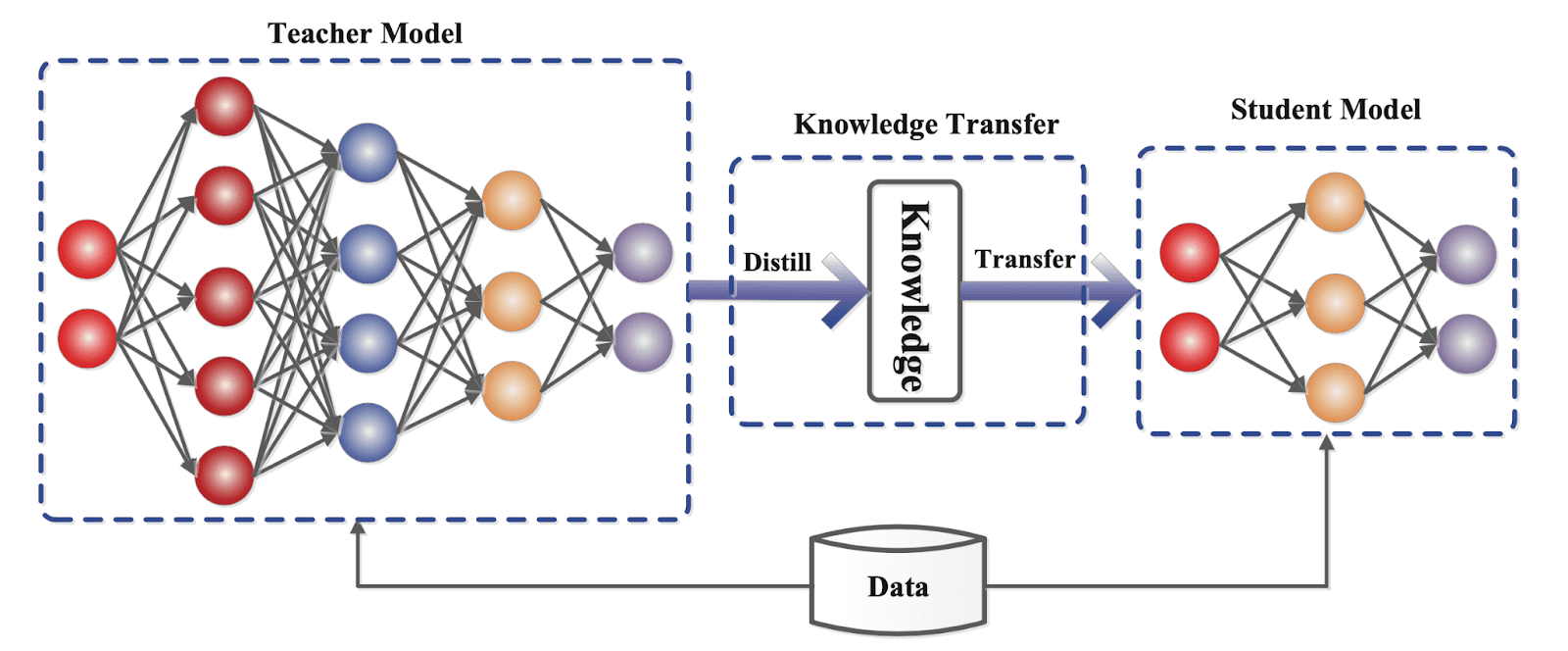
By training the student model on the distilled dataset, the student model can benefit from the knowledge transferred from the teacher model while being trained on a more compact and focused set of samples. This can lead to improved generalization, reduce overfitting, and faster training convergence of the student model.
Moreover, using a distilled dataset can reduce the computational requirements and memory constraints associated with training on large-scale datasets. It allows the student model to capture the essential information from the original dataset without the need to process and store the entire dataset.
Conclusion
In this blog post, we explored the concept of dataset distillation and its working principles. Dataset distillation involves transferring knowledge from a larger dataset to a smaller one, enabling models to benefit from the valuable insights and patterns captured in the larger dataset while overcoming computational and memory constraints.
We discussed three main methodologies of dataset distillation: Performance Matching, Distribution Matching, and Parameter Matching.
Performance Matching includes methods like Meta-Learning and Kernel Ridge Regression (KRR), which focus on matching the performance of the distilled model with the larger model. Distribution Matching encompasses techniques such as Single Layer and Multi Layer, where the goal is to match the data distribution between the distilled and original datasets. Parameter Matching involves methods like Single-Step and Multi-Step, which aim to match the model parameters between the distilled and larger models.
Furthermore, we explored the diverse applications of dataset distillation across various fields. In computer vision, dataset distillation can be employed for tasks such as object detection, semantic segmentation, and image classification, enhancing model performance, efficiency, and generalization.
Dataset distillation offers a powerful approach to enhance model performance, efficiency, and generalization by leveraging the knowledge embedded in larger datasets. It holds significant potential in various domains and tasks, enabling models to achieve state-of-the-art results with reduced computational costs.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (May 24, 2023). What is Dataset Distillation? A Deep Dive.. Roboflow Blog: https://blog.roboflow.com/what-is-dataset-distillation/