
Phrase grounding, also known as visual grounding or referring expressions, is a task at the intersection of computer vision and natural language processing (NLP). It involves associating specific phrases or expressions within a textual description to their corresponding regions in an image.
In this guide, we are going to talk about what phrase grounding is and how it works, with reference to several state-of-the-art models in the field.
What is Phrase Grounding?
Phrase grounding is a process in natural language processing and computer vision where specific words or phrases within a sentence are associated with corresponding regions in an image. This task involves identifying the spatial location or bounding box within an image that aligns with the meaning of a given phrase, enabling models to connect visual and textual data.
Phrase grounding enables machines to understand and link language to visual content at a fine-grained level, facilitating a deeper integration of vision and language modalities. The goal of phrase grounding is to understand and map out which parts of an image are being referred to by specific phrases in a textual description.
Phrase grounding is useful for many image understanding and multimodal tasks such as Visual Question Answering (VQA), Image Captioning, Human-Computer Interaction (HCI), Visual Search, Referential Expression Recognition and many more.
For example, in the image below, the phrase “a dog playing with a ball” would be grounded by associating "a dog" with the region where the dog appears in the image and "a ball" with the location of the ball.
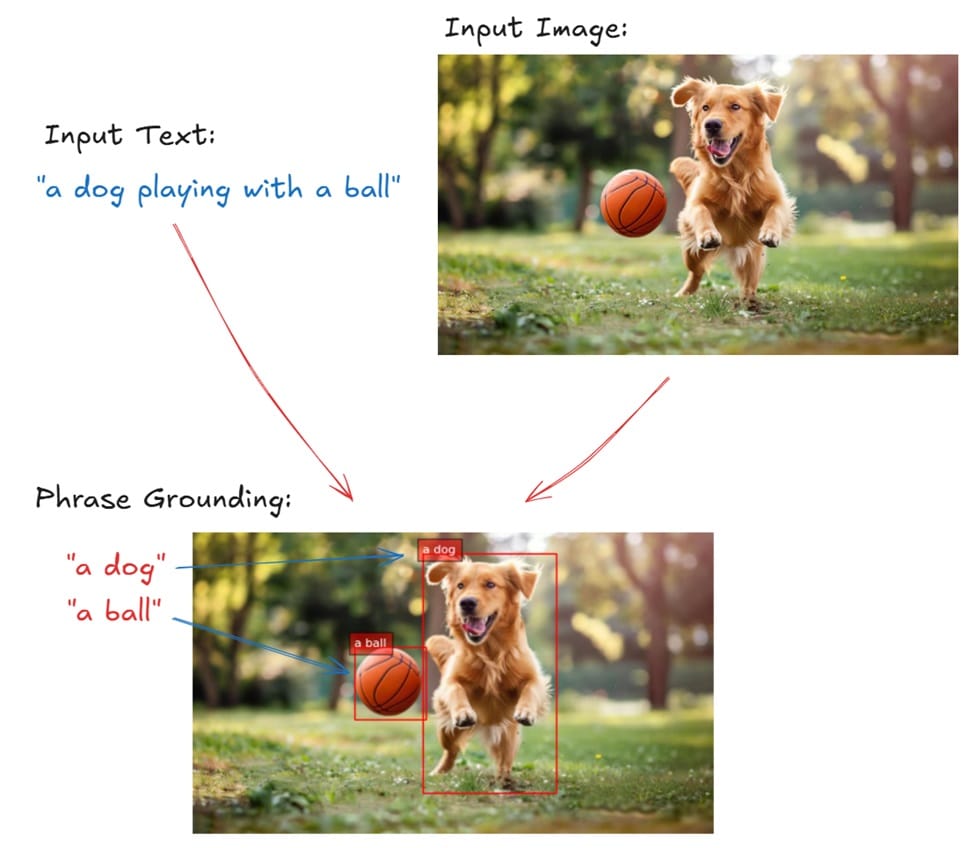
How Phrase Grounding Works
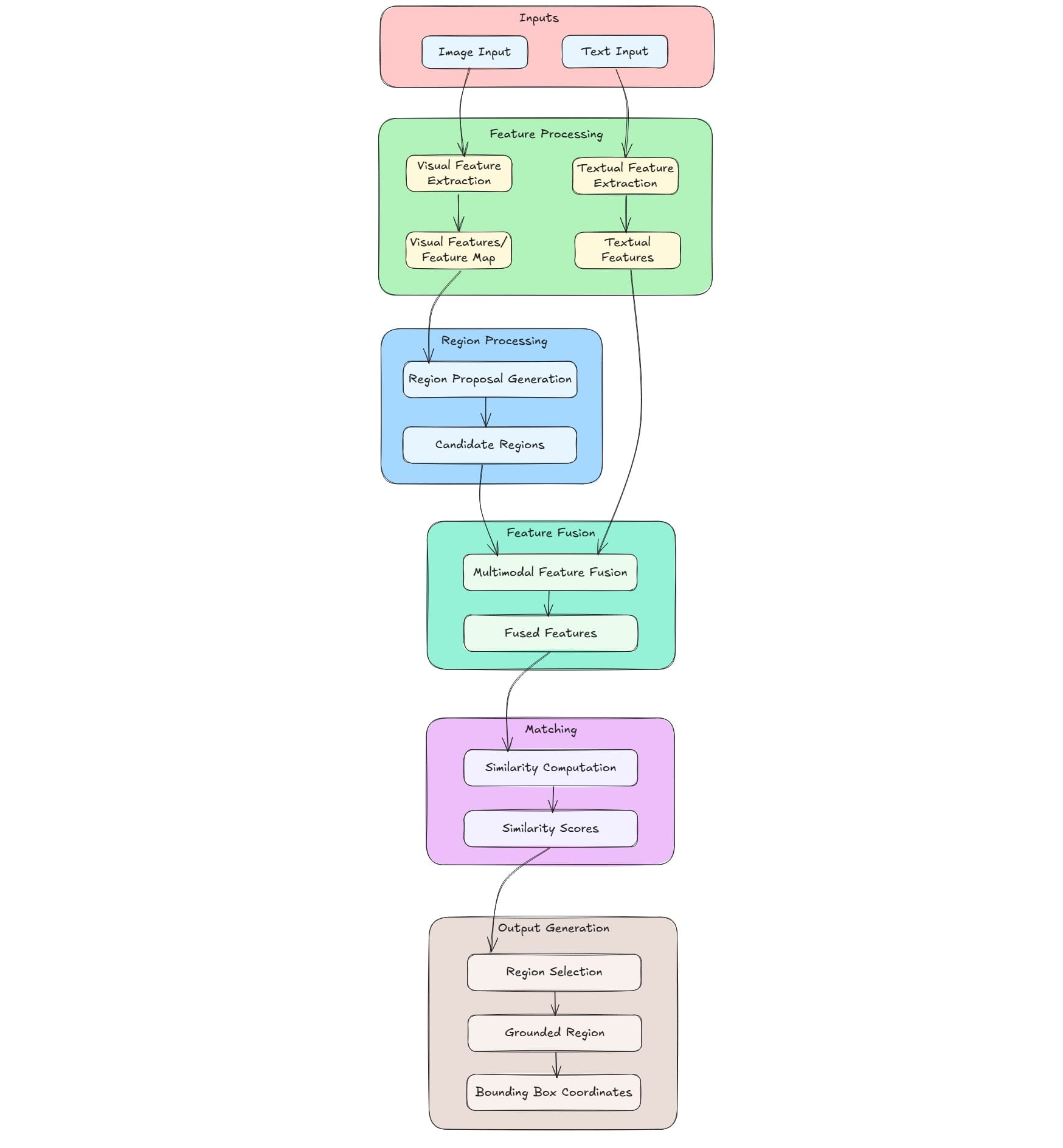
Phrase grounding is the task of aligning textual phrases with corresponding regions in an image. This involves several key stages, each responsible for specific tasks to achieve accurate alignment. While specific implementations may vary, the general workflow across most models involves the following steps:
Input
- Image Input: An image is provided as input. It serves as the visual context for grounding the textual description.
- Text Input: The phrase or sentence that needs to be grounded in the image. It provides semantic information to identify relevant regions in the image.
Feature Processing
Both inputs follow separate initial processing paths to extract relevant features.
- Visual Feature Extraction: Utilizes Convolutional Neural Networks (CNNs) to process the image. Feature map is generated that captures spatial and visual information from different regions of the image. These features are essential for identifying potential areas that correspond to the textual description.
- Textual Feature Extraction: Employs models like Long Short-Term Memory (LSTM) networks or Transformers to process the text input. The text is converted into semantic feature vectors that encapsulate the meaning and context of the input phrase. These vectors are crucial for matching the text with relevant visual features.
Region Processing
- Region Proposal Generation: Takes the visual features from the CNN and generates multiple potential bounding boxes. In this step the areas that might contain objects or relevant image regions are identified. This step narrows down the search space to specific candidate regions that are likely to correspond to the text description.
- Candidate Regions: It is a collection of proposed regions that might match the text description. Each candidate region is associated with visual features extracted from the corresponding part of the image.
Feature Fusion
- Multimodal Feature Fusion: Combines visual features from candidate regions with textual features to create a joint representation. This fusion captures both visual and textual information, facilitating effective comparison between text and image regions. Techniques such as attention mechanisms is used to weigh the importance of different features during fusion.
- Fused Features: These are the unified representation resulting from the fusion process. It enables the model to assess the relevance of each candidate region concerning the input text.
Matching
- Similarity Computation: It involves computing how well each candidate region aligns with the textual description. Employs similarity metrics or attention mechanisms to quantify the alignment between fused features and the text. This step produces similarity scores that indicate the strength of the match for each region.
- Similarity Scores: It is numerical values representing the degree of correspondence between each candidate region and the text. Higher scores suggest a stronger match, guiding the selection of the most relevant region(s).
Output Generation
- Region Selection: Here the best matching region(s) based on similarity scores is chosen. Multiple regions may be selected if the phrase describes multiple objects. This step finalizes the grounding process by identifying the image regions that correspond to the textual input.
- Grounded Region: It is the final selected region(s) that best match the text description. These regions are highlighted or annotated to indicate their correspondence with the input phrase.
- Bounding Box Coordinates: The output as x, y coordinates defining the boundaries of the grounded region(s). These coordinates can be used for visualization or further processing tasks.
This workflow is common across various phrase grounding models, with differences primarily in the specific architectures and methods used for feature extraction, fusion, and similarity computation.
Phrase Grounding Models
Here are some prominent models and approaches used for phrase grounding:
Florence-2
Florence-2 is a vision foundation model developed by Microsoft, designed to handle a variety of computer vision and vision-language tasks through a unified, prompt-based approach.
In the context of phrase grounding, Florence-2 excels by interpreting text prompts to identify and localize specific phrases within images. Trained on the extensive FLD-5B dataset, which comprises 5.4 billion annotations across 126 million images, the model effectively associates textual phrases with corresponding image regions.
Florence-2 supports tasks like caption-to-phrase grounding, where it aligns segments of a generated caption with specific regions in the image. Its sequence-to-sequence architecture enables it to perform tasks like object detection, segmentation, and visual grounding by generating text outputs that describe or pinpoint elements within an image. This capability allows Florence-2 to accurately map phrases to their visual counterparts, enhancing applications that require precise alignment between text and imagery.
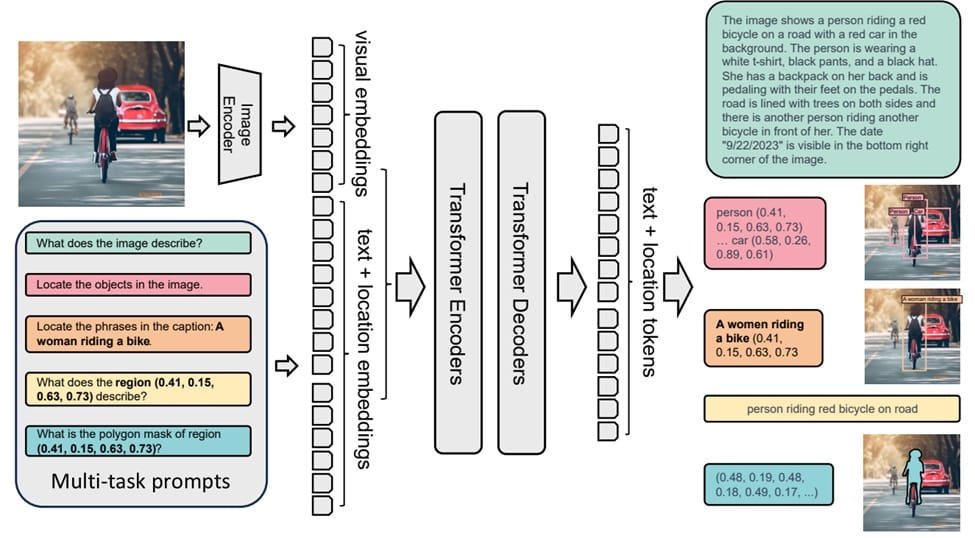
Florence-2 includes an image encoder and a standard multi-modality encoder-decoder, trained using the FLD-5B dataset in a unified multitask learning setup. This approach produces a versatile vision foundation model capable of handling various vision tasks.
Grounding DINO
Grounding DINO is an advanced open-set object detection model that integrates language inputs, such as category names or referring expressions, into the detection process, effectively aligning textual phrases with corresponding image regions. By incorporating a text encoder into the Transformer-based DINO architecture, Grounding DINO enables the detection of arbitrary objects specified by human inputs, thereby enhancing phrase grounding capabilities.
This integration allows the model to comprehend and localize objects based on descriptive phrases, facilitating tasks like referring expression comprehension and open-vocabulary detection. The model's architecture includes a feature enhancer, language-guided query selection, and a cross-modality decoder, all contributing to its proficiency in associating textual descriptions with visual elements. Grounding DINO has demonstrated remarkable performance across various benchmarks, including COCO, LVIS, and RefCOCO datasets, underscoring its effectiveness in phrase grounding applications.
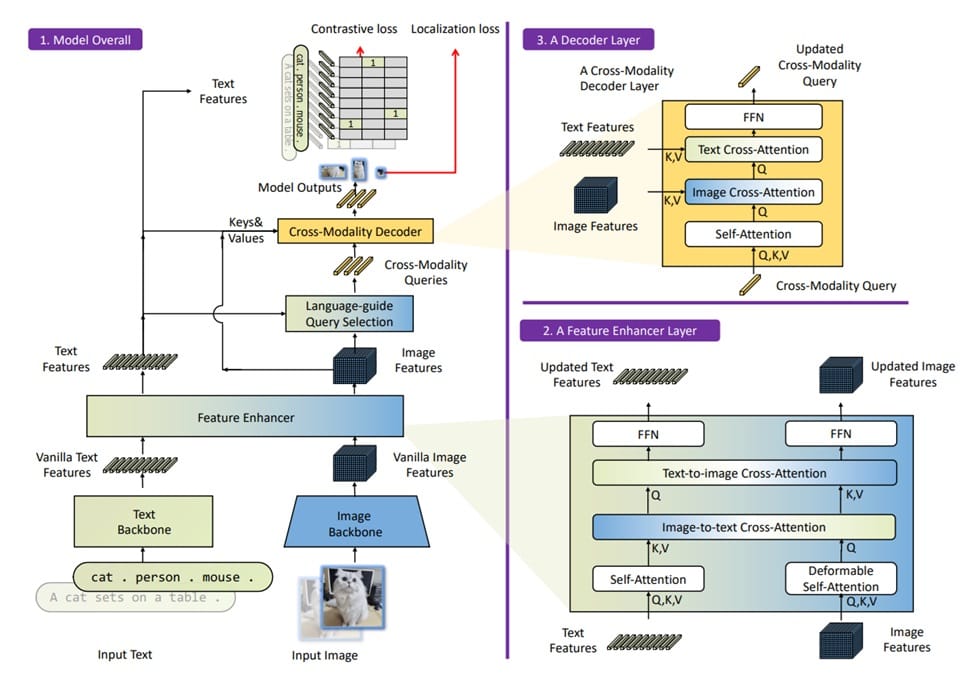
The Grounding DINO framework consists of three main blocks: block 1 for the overall framework, block 2 for the feature enhancer layer, and block 3 for the decoder layer.
MM-Grounding-DINO
MM-Grounding-DINO is an open-source framework designed to enhance phrase grounding by integrating language inputs into object detection models. Built upon the Grounding DINO architecture, it utilizes the MMDetection toolbox to create a comprehensive and user-friendly pipeline. The framework leverages extensive vision datasets for pre-training and fine-tuning, enabling it to effectively associate textual phrases with corresponding image regions.
By incorporating modules such as a feature enhancer, language-guided query selection, and a cross-modality decoder, MM-Grounding-DINO improves the alignment between textual descriptions and visual elements. Evaluations on benchmarks like COCO, LVIS, and RefCOCO demonstrate its proficiency in phrase grounding tasks, highlighting its potential for applications requiring precise text-image correspondence.
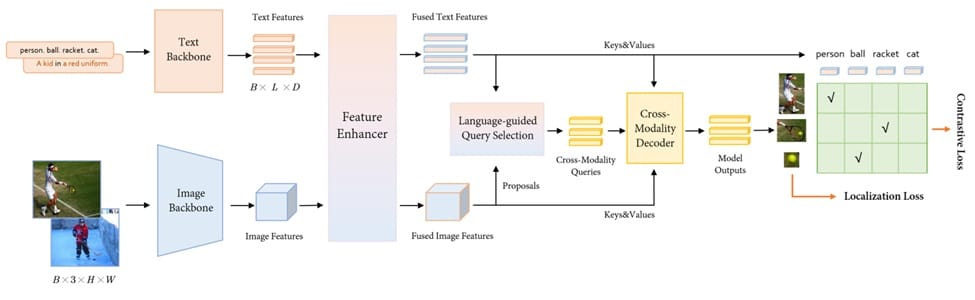
MM-Grounding-DINO extracts text and image features using respective backbones and fuses them through a feature enhancer module. A language-guided query selection extracts cross-modality queries, which the decoder uses to predict object boxes and corresponding phrases.
GLaMM
GLaMM (Grounding Large Multimodal Model) model enables phrase grounding by integrating natural language processing with detailed visual understanding. It generates natural language responses intertwined with corresponding object segmentation masks, enabling precise alignment between textual phrases and specific image regions. GLaMM accepts both textual and optional visual prompts, allowing users to interact at various levels of granularity in both textual and visual domains. To support its capabilities, the authors introduced the Grounding-anything Dataset (GranD), a densely annotated dataset encompassing 7.5 million unique concepts grounded in 810 million regions with segmentation masks. This extensive dataset provides a robust foundation for training and evaluating phrase grounding models. By offering pixel-level alignment between text and images, flexible input handling, and introducing new tasks and datasets, GLaMM significantly advances the field of phrase grounding.
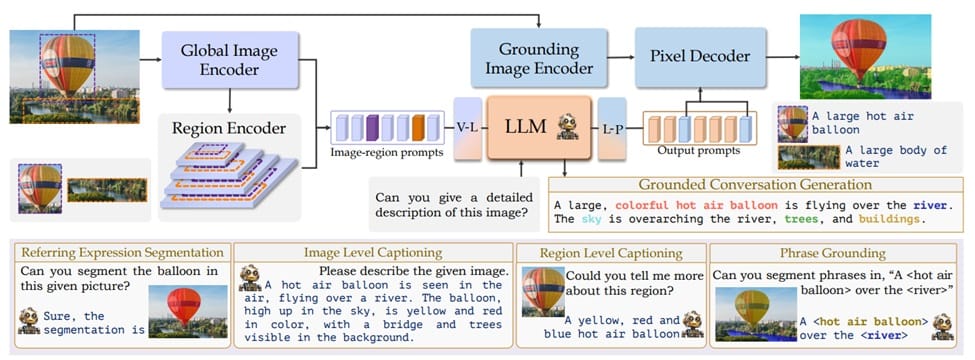
GLaMM's architecture provides scene, region, and pixel-level understanding for vision-language tasks. It uses image and language encoders, a pixel decoder, and projection layers for feature mapping and segmentation. GLaMM supports tasks like grounded conversation generation, phrase grounding, and various captioning applications.
KOSMOS-2
KOSMOS-2 is a multimodal large language model (MLLM) enables phrase grounding by integrating visual and textual information. It represents referring expressions as Markdown-style links, associating text spans with bounding boxes, which enables the model to effectively map textual phrases to specific image regions. Trained on the GrIT dataset, a large-scale collection of grounded image-text pairs, KOSMOS-2 demonstrates improved performance in tasks such as referring expression comprehension and phrase grounding. Its unified representation and comprehensive training data contribute to its proficiency in aligning textual phrases with visual content, advancing the field of multimodal understanding.
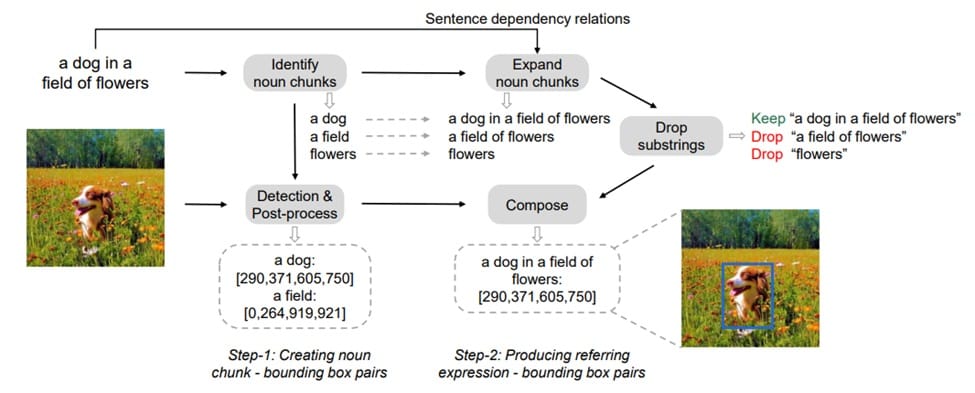
KOSMOS-2 pipeline consists of main two steps. In step 1, noun chunks are extracted from image captions and matched with image regions using a pretrained detector. Abstract phrases are filtered out, and a grounding model generates bounding boxes for the chunks. High-overlap boxes are removed, and only confident noun-chunk-bounding-box pairs are kept. In step 2, noun chunks are expanded into referring expressions by traversing dependency relations in the sentence. Unique expressions are retained, and bounding boxes from noun chunks are assigned to these expanded expressions.
GLIP
GLIP (Grounded Language-Image Pre-training) is a model that unifies object detection and phrase grounding to enhance the alignment between textual phrases and corresponding image regions. By reformulating object detection as a phrase grounding task, GLIP processes images alongside textual prompts describing candidate categories, enabling it to effectively associate visual regions with specific phrases. Trained on a substantial dataset of 27 million grounding data, including 3 million human-annotated and 24 million web-crawled image-text pairs, GLIP demonstrates strong zero-shot and few-shot transferability to various object-level recognition tasks. Notably, it achieves 49.8 AP on COCO and 26.9 AP on LVIS without prior exposure to these datasets during pre-training, surpassing many supervised baselines. This unified approach allows GLIP to leverage both detection and grounding data, resulting in semantic-rich visual representations that improve performance across multiple tasks.
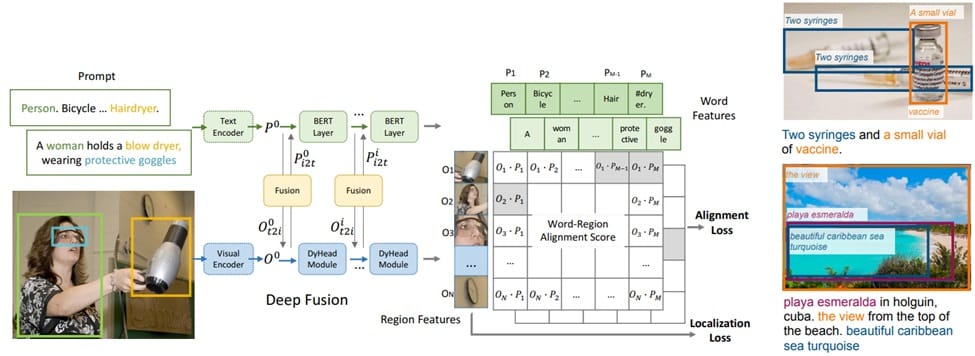
GLIP is a unified framework that reformulates object detection as a grounding task, aligning image regions to phrases in a text prompt. It trains image and language encoders together with cross-modality fusion for language-aware visual representation, enabling detection of rare entities and abstract phrases.
MDETR
MDETR (Modulated Detection for End-to-End Multi-Modal Understanding) is a model designed to enhance phrase grounding by integrating object detection with natural language understanding. Unlike traditional systems that rely on pre-trained object detectors with fixed vocabularies, MDETR employs a transformer-based architecture to process images and textual queries jointly. This end-to-end approach allows the model to detect objects in images conditioned on free-form text inputs, such as captions or questions, enabling it to capture a wide range of visual concepts expressed in natural language. Trained on a large dataset of 1.3 million text-image pairs with explicit alignments between phrases and objects, MDETR achieves state-of-the-art performance on benchmarks like Flickr30k for phrase grounding and RefCOCO/+/g for referring expression comprehension. Its ability to generalize to novel combinations of object categories and attributes makes it a significant advancement in the field of multi-modal understanding.
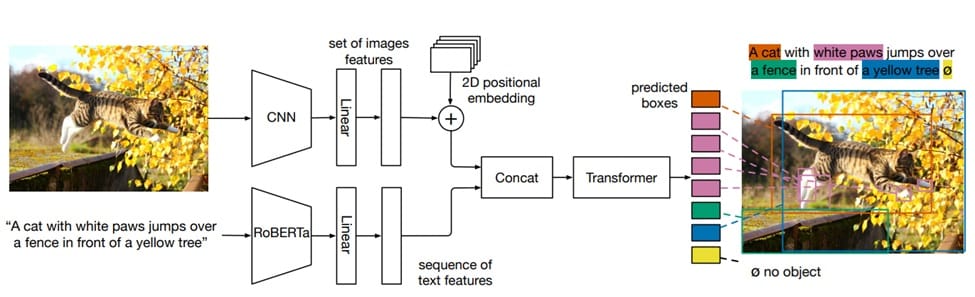
MDETR uses a convolutional backbone for visual features and a language model like RoBERTa for text features, projecting both to a shared space. These combined features are processed by a transformer encoder-decoder to predict object bounding boxes and their text grounding.
ZSGNet
Zero-Shot Grounding of Objects from Natural Language Queries (ZSGNet) is a model designed to address the challenge of phrase grounding, particularly in zero-shot scenarios where the object categories are not present in the training data.
Traditional phrase grounding systems often rely on pre-trained object detectors limited to specific categories, which restricts their ability to generalize to unseen objects. ZSGNet overcomes this limitation by employing a single-stage network that integrates object detection and grounding tasks.
It processes dense proposals and predicts classification scores and regression parameters, enabling the localization of objects described by novel nouns not encountered during training. The model is trained end-to-end on grounding datasets without relying on external object detectors, allowing it to generalize to new object categories effectively. Evaluations on datasets like Flickr30k Entities and Visual Genome demonstrate that ZSGNet achieves state-of-the-art performance in traditional phrase grounding tasks and shows significant improvements in zero-shot grounding scenarios, highlighting its robustness and adaptability.
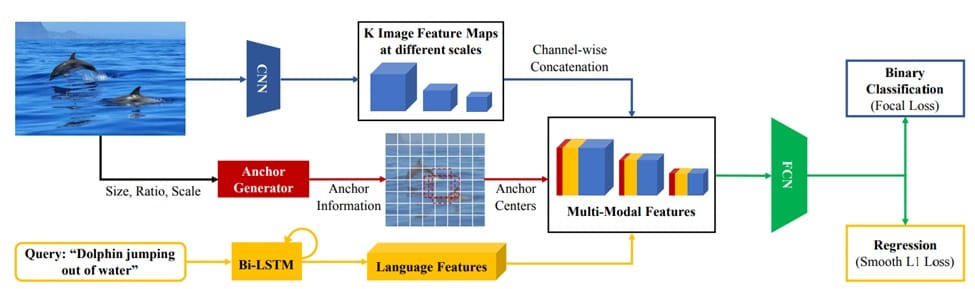
ZSGNet architecture takes an image-query pair as input, generates multi-scale image feature maps, and appends anchor centers and encoded query features. These multi-modal maps are processed by an FCN to predict scores and regression parameters, trained with focal and SmoothL1 loss.
SeqGROUND
SeqGROUND (Neural Sequential Phrase Grounding) model enables phrase grounding by treating it as a sequential and contextual process.
Unlike traditional methods that independently ground each phrase, SeqGROUND utilizes two stacks of Long Short-Term Memory (LSTM) cells to encode region proposals and phrases, along with previously grounded phrase-region pairs.
This architecture captures contextual information, allowing the model to use prior grounding decisions to inform subsequent ones. Notably, SeqGROUND supports many-to-many matching, enabling an image region to correspond to multiple phrases and vice versa. Evaluations on the Flickr30K benchmark dataset demonstrate its competitive performance, validating the effectiveness of its sequential grounding approach and architectural design choices.
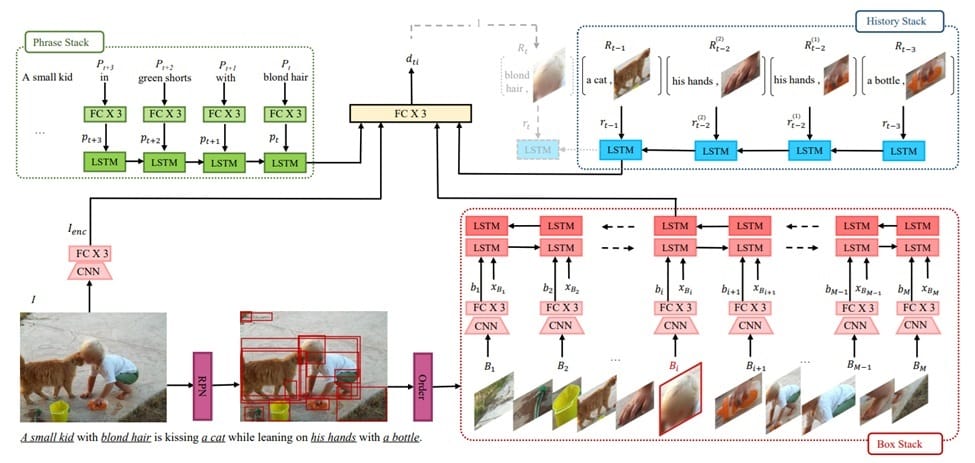
SeqGROUND architecture processes phrases sequentially, using LSTM stacks to encode linguistic dependencies and image-bound box sequences. Grounding decisions consider current stack states and full image representation, updating the history stack with newly grounded phrase-box pairs.
Align2Ground
Align2Ground model involves associating textual phrases with corresponding regions in images for phrase grounding. It operates under weak supervision, utilizing image-caption pairs without explicit region-phrase annotations.
The model employs a two-stage process: first, it infers latent correspondences between regions of interest (RoIs) in images and phrases in captions, creating a discriminative image representation based on these matched RoIs. This learned representation is aligned with the entire caption, facilitating effective image-caption matching.
A key innovation of Align2Ground is its "caption-conditioned" image encoding, which tightly couples the tasks of phrase localization and image-caption alignment, allowing weak supervision to effectively guide visual grounding. Empirical evaluations have demonstrated that Align2Ground achieves significant improvements in phrase localization, outperforming prior state-of-the-art methods on datasets like VisualGenome and Flickr30k Entities.
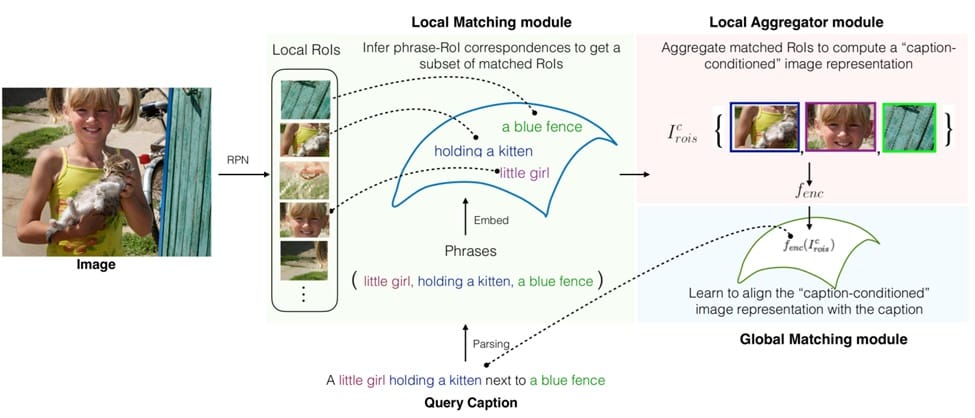
This figure outlines Align2Ground architecture. Region Proposal Network (RoIs) outputs and parsed phrases are processed by the Local Matching module to infer phrase-RoI correspondences. The Local Aggregator module refines these matched RoIs to build a caption-conditioned visual representation, which is then aligned with image-caption pairs in the Global Matching module.
MultiGrounding
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding introduces a model designed for phrase grounding task by learning a shared semantic space between textual and visual modalities.
The approach utilizes multiple levels of feature maps from a deep convolutional neural network to capture various visual concepts and patterns. Simultaneously, it employs contextualized word and sentence embeddings from a character-based language model to represent textual information.
By applying dedicated non-linear mappings to both visual features at each level and textual embeddings, the model creates multiple instances of a common semantic space. Within this space, comparisons between text and visual content are performed using cosine similarity. A multi-level multimodal attention mechanism guides the model to focus on relevant visual features corresponding to specific phrases.
Experiments on publicly available datasets demonstrate significant performance gains over previous state-of-the-art methods in phrase localization, highlighting the effectiveness of this multi-level, multimodal approach to phrase grounding.
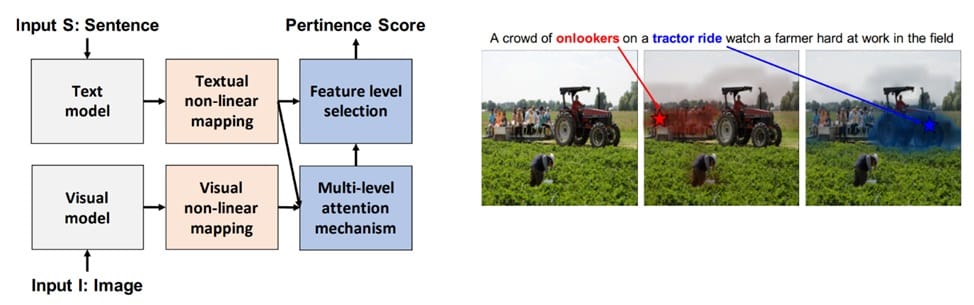
This method processes text and images using pre-trained models, maps them to a shared semantic space, and applies multi-level attention to compute the pertinence score between them. The model is trained using weak supervision from image-sentence pairs.
GroundeR
GroundeR, introduces a novel approach to phrase grounding, employs an attention mechanism that enables the model to focus on specific image regions relevant to a given phrase. During training, GroundeR learns to reconstruct input phrases by attending to appropriate image regions, effectively aligning textual and visual information. This approach allows the model to operate under varying levels of supervision, including unsupervised, semi-supervised, and fully supervised settings. Evaluations on datasets such as Flickr30k Entities and ReferItGame have demonstrated that GroundeR outperforms prior methods, highlighting its effectiveness in accurately grounding phrases within images.
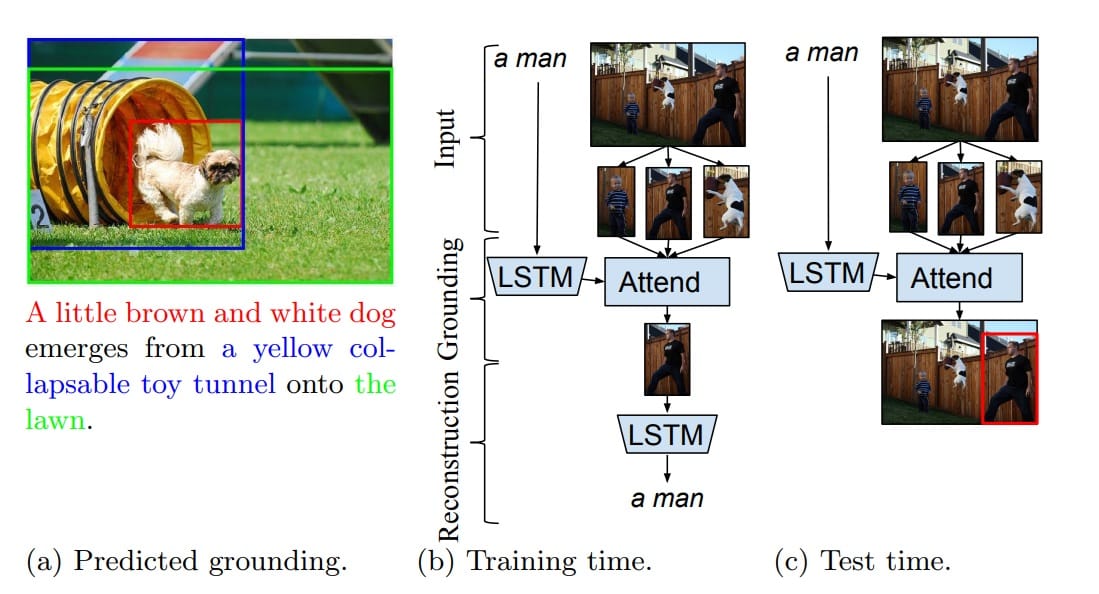
GroundeR is a model that can associate natural language phrases with specific regions in images without requiring bounding box annotations during training. It achieves this by learning to focus on the correct image regions to accurately reconstruct the given phrases.
Phrase Grounding Examples
Now we will see how to perform phrase grounding using Grounding DINO and Florence-2.
Phrase Grounding using Grounding DINO
Here is the code to perform phrase grounding using Grounding DINO. For the example we use following input image:

The steps to implement phrase grounding using Grounding DINO are following:
Step#1: Load the image
image_path = "/content/dog.jpg" # Replace with your image path
image_source, image = load_image(image_path)
Step#2: Load the model
model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth")
Step#3: Define the text prompt
text_prompt = "a dog with ball."
Step#4: Set the threshold
box_threshold = 0.35
text_threshold = 0.25
Step#5: Perform prediction
boxes, logits, phrases = predict(
model=model,
image=image,
caption=text_prompt,
box_threshold=box_threshold,
text_threshold=text_threshold
)
Step#6: Annotate image
annotated_image = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
The code generates following output where only a dog with ball is grounded as given in the phrase.

Phrase Grounding using Florence-2
Phrase grounding can also be performed using Florence-2. This is achieved using the <CAPTION_TO_PHRASE_GROUNDING> prompt. This prompt directs the model to locate and highlight regions in an image corresponding to specific phrases within a provided caption. The input consists of the prompt followed by a descriptive caption of the image. The model outputs bounding boxes and labels indicating the positions of the mentioned phrases. Consider the image below.

Using the <CAPTION_TO_PHRASE_GROUNDING> prompt, Florence-2 processes the image and caption to identify and localize the given phrases within the image. The model outputs bounding boxes or segmentation masks highlighting the regions corresponding to each identified phrase. Here’s are the implementation steps:
Step#1: Load the Image
image_path = "livingroom.jpg"
image = Image.open(image_path)
Step#2: Initialize the processor and model
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True).eval()
Step#3: Define the Prompt and Caption
prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
caption = "A serene living space showcasing a modern armchair, a leafy potted plant, and a standing lamp casting a warm glow."
Step#4: Prepare Inputs
inputs = processor(text=prompt + " " + caption, images=image, return_tensors="pt").to(device)
Step#5: Generate Outputs
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=512,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
Step#6: Post-process the output
result = processor.post_process_generation(
generated_text,
task=prompt,
image_size=(image.width, image.height)
)
Step#7: Extract bounding boxes and labels
bboxes = result[prompt]['bboxes']
labels = result[prompt]['labels']
Step#8: Visualize the Results
# Create a figure and axis
fig, ax = plt.subplots(1, figsize=(12, 8))
# Display the image
ax.imshow(image)
# Add bounding boxes and labels
for bbox, label in zip(bboxes, labels):
# Unpack the bounding box coordinates
x1, y1, x2, y2 = bbox
# Calculate width and height
width = x2 - x1
height = y2 - y1
# Get the color for the current label
color = label_colors[label]
# Create a rectangle patch
rect = patches.Rectangle((x1, y1), width, height, linewidth=2, edgecolor=color, facecolor='none')
# Add the rectangle to the plot
ax.add_patch(rect)
# Add the label with a matching background color
plt.text(x1, y1 - 10, label, color='white', fontsize=12,
bbox=dict(facecolor=color, edgecolor='none', alpha=0.7))
# Remove axis
plt.axis('off')
# Show the plot
plt.show()
The following output will be generated.

In Florence-2, instead of specifying the caption explicitly we can also use any of the prompts (e.g. <CAPTION>, <DETAILED_CAPTION>, <MORE_DETAILED_CAPTION>) to generate textual descriptions of images at varying levels of detail and then use phrase grounding prompt <CAPTION_TO_PHRASE_GROUNDING> for the phrase grounding task.
Here,
<CAPTION>prompt instructs the model to produce a concise, general description of the image, capturing its primary content without extensive specifics.
Example: “A living room with a chair and a lamp”<DETAILED_CAPTION>prompt instruct the model to generate a more comprehensive description, including additional details about the scene, objects, and their relationships.
Example: “The image shows a living room with a chair, houseplants, a carpet on the floor, a lamp, and a wall in the background. The room is illuminated by the lamp, creating a warm and inviting atmosphere.”<MORE_DETAILED_CAPTION>prompt directs the model to provide an even more elaborate description, encompassing finer details and nuanced aspects of the image.
Example: “The image shows a corner of a room with a wooden floor and a beige wall. On the left side of the image, there is a large potted plant with green leaves and a white pot with a small plant in it. Next to the plant, there are two small side tables with a plant on them. In the center of the room is a white armchair with a beaded backrest and armrests. The floor is made of light-colored wood planks and the walls are painted a light beige color. A floor lamp with a white shade is placed next to the armchair. A gray area rug is placed on the floor in front of the chair. The overall style of the space is modern and minimalistic.”
First, use the <CAPTION> prompt to obtain a descriptive caption of the image.
# Define the captioning prompt
caption_prompt = "<CAPTION>"
# Prepare inputs for captioning
inputs = processor(text=caption_prompt, images=image, return_tensors="pt").to(device)
# Generate the caption
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=500,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Extract the generated caption
caption = generated_text.split(caption_prompt)[-1].strip()
print("Generated Caption:", caption)
It will generate following output.

Then apply Phrase Grounding by utilizing the <CAPTION_TO_PHRASE_GROUNDING> prompt with the generated caption to identify and localize specific phrases within the image.
# Define the phrase grounding prompt
grounding_prompt = "<CAPTION_TO_PHRASE_GROUNDING>"
# Prepare inputs for phrase grounding
inputs = processor(text=grounding_prompt + " " + caption, images=image, return_tensors="pt").to(device)
# Generate phrase grounding output
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=512,
num_beams=3,
do_sample=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
# Post-process the output
result = processor.post_process_generation(
generated_text,
task=grounding_prompt,
image_size=(image.width, image.height)
)
# Extract bounding boxes and labels
bboxes = result[grounding_prompt]['bboxes']
labels = result[grounding_prompt]['labels']
The following is the output after visualizing the result.

Conclusion
In this blog, we learned what phrase grounding is, how it works, and looked at some key models and methods used for it. We also saw how to do phrase grounding using Grounding DINO and Florence-2.
Phrase grounding is important because it helps link language to images. This ability is useful in many areas, like image search, human-computer interaction, autonomous systems, and analyzing images based on their content. By allowing machines to understand and match language with visual content, phrase grounding makes AI systems more accurate and better at understanding context, bringing machine perception closer to human communication.
With the Roboflow workflow, you can now use Florence-2 to build a phrase grounding application without needing to write any code. To get started with Florence-2 in the Roboflow workflow, I recommend reading the post Launch: Use Florence-2 in Roboflow Workflows.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Nov 13, 2024). What is Phrase Grounding?. Roboflow Blog: https://blog.roboflow.com/what-is-phrase-grounding/