
Suppose you have a problem you want to solve with computer vision but few images on which you can base your new model. What can you do? You could wait to collect more data, but this may be untenable if the features you want to capture are hard to find (i.e. rare animals in the wild, product defects).
This is where transfer learning comes in. In this article, we're going to discuss:
- What is transfer learning?
- How does transfer learning work?
- When you should use transfer learning
What Is Transfer Learning?
Transfer learning is a computer vision technique where a new model is built upon an existing model. The purpose of this is to encourage the new model to learn features from the old one so that the new model can be trained to its purpose faster and with less data.
The name "transfer learning" is telling as to what this technique means: you transfer the knowledge one model has acquired to a new model that can benefit from that knowledge. This is similar to how you might transfer your knowledge of painting into drawing – color theory, your aesthetic – even though the two tasks are different.
Let's talk through an example of transfer learning in action.
Teaching Friends to Skateboard
Imagine you have two friends that you're trying to teach how to skateboard. Both have never skateboarded previously. Friend A, call them Anna, has snowboarded in the past and even tried a little surfing. Friend B, call them Brian, has never tried any kind of board sport. Which friend do you expect would pick up skateboarding more quickly?
Knowing nothing else about Brian and Anna, we would likely pick Anna. While Anna has never tried skateboarding, specifically, she has participated in other board sports – related domains like snowboarding. We may expect that the balance she learned in snowboarding would enable her to pick up skateboarding more quickly. What's more – perhaps Anna doesn't only learn faster, but perhaps she is destined to be a more talented skateboarded than Brian altogether.
In other words, we bet on Anna because we think she will transfer her learnings from snowboarding into becoming a successful skateboarder.
Learn more on our YouTube channel.
Transfer Learning in Machine Learning
In machine learning, transfer learning isn't so different. At its core, transfer learning is using what a given model has learned about one domain and applying those learnings to attempt to learn a related problem.
Imagine we're attempting to teach a model to recognize specific dog species: labradors, pugs, corgies, etc. If we already have a machine learning model that knows how to recognize dogs in a photo (but not specific species) and a machine learning model that knows nothing. We would expect that the model which already knows what a dog looks like to more quickly learn what a specific species looks like – and we'd likely be correct.
Remember, in machine learning, we're fine-tuning a model's weights. Those weights can either start with completely randomly initiated values or they could start from some prior set of values. When we train a model from scratch – that is, with no prior images in mind – the weights are randomly initiated.
When we use transfer learning, those weights have values that have been learned from the prior domain problem. For this reason, the model may require less adjustment in its weights to learn a new domain. It may even have some embedded knowledge that the model that started from scratch would never learn.
Explore a Transfer Learning in Machine Learning Example
Imagine having images of animals collected on a safari in Africa. The dataset consists of images of giraffes and elephants. Now suppose you want to build a model that can distinguish giraffes from elephants given those images as inputs to part of a model that counts wildlife in a particular area.
The first thing that might come to your mind is to build an image recognition model from scratch that will do this. Unfortunately, you only took few photos, so it is unlikely that you will be able to achieve high accuracy.
So, you decide to look for new images to enlarge your dataset and label the new images and then train a model from scratch. This would be doable. However, assuming you find the new images suitable for your domain, it is very time-consuming.
But suppose you have a model that has been trained on, for example, millions of images that can distinguish dogs from cats.
What we can do is take this already-trained model and leverage what the model has already learned to teach it to distinguish other kinds of animals (giraffes and elephants, in our case) without having to train a model from scratch that might require more than just a lot of amount of data that in this case, we do not have, but also a lot of computational complexity.
Exploiting the knowledge of an already trained model to create a new model specialized on another task is transfer learning.
How to Use Transfer Learning in Computer Vision
Note that the key to transfer learning is ensuring that two problems we're working on are similar enough for what a model learned in one setting to apply to the second setting. Now, what defines "similar enough" is an imperfect science. In general, it depends on how fine-tuned the original model was to the first domain problem.
If the new problem we're trying to learn is a subdomain of the first problem, transfer learning is a good candidate. Like the dog example above: if we're aiming to learn one specific species and we already have a model that knows what dog looks like, there's a good chance transfer learning will help significantly.
If two problems have images that are in similar contexts, transfer learning is likely helpful. For example, if we're aiming to learn what a given object looks like from real world photographs and we already have a model trained on the COCO dataset, we could use the weights from the COCO dataset to learn the new domain problem.
If the new problem is an extension of the second problem, transfer learning will help. For example, if you trained a model on a context with 5,000 images and collected an additional 3,000 images, we could use the weights from the first model (5,000 images) on the second model (3,000 images). We would expect the model would continue to make marginal improvements.
How Transfer Learning in Computer Vision Works
How is it possible that a model that can recognize cats and dogs can be used to recognize giraffes and elephants? Great question.
Convolutional networks extract features from high-level images. The first layers of a CNN learn to recognize general features such as vertical edges, the subsequent layers, the horizontal edges, and then maybe these features are combined to recognize the corners, circles, etc.
These high-level features are independent of the type of entity we need to recognize. Computer vision models don't just "learn" exactly what, for example, cats look like. Instead, models break down images into small components and learn how those small components combine to make features associated with a particular concept.
Recognition in the entity (animals in this case) happens at the linear layers that take as input the features extracted from the convolutional layers and learn to categorize in the final class (giraffe or elephant).
To apply transfer learning, we remove the linear layers of the already trained model (since they are layers that have been trained to recognize other classes) and add new ones. We retrain the new layers in such a way that they specialize in recognizing our classes of interest.
How to Apply Transfer Learning
To apply transfer learning, first choose a model that was trained on a large dataset to solve a similar problem. A common practice is to grab models from computer vision literature such as VGG, ResNet, and MobileNet.
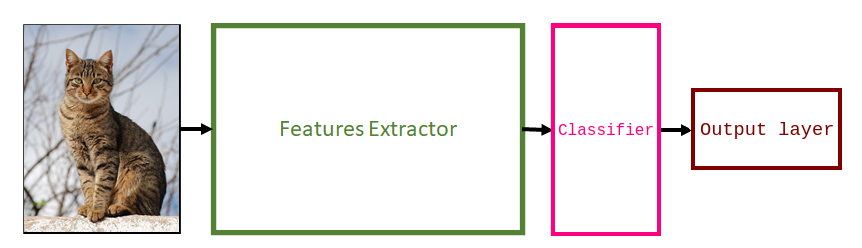
Next, remove the old classifier and output layer.
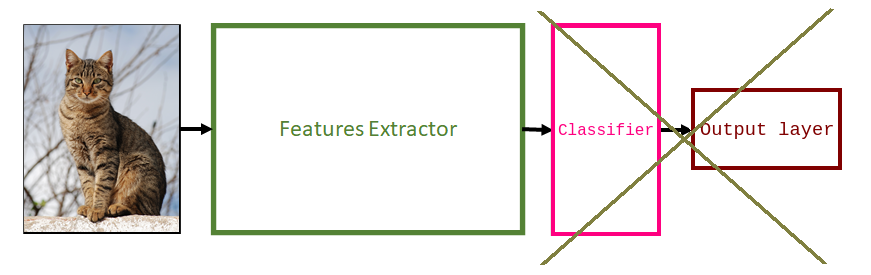
Next, add a new classifier. This involves adapting the architecture to solve the new task. Usually, this stage means adding a new randomly initialized linear layer (represented by the blue block below) and another one with several units that is equal to the number of classes you have in your dataset (represented by the pink block).
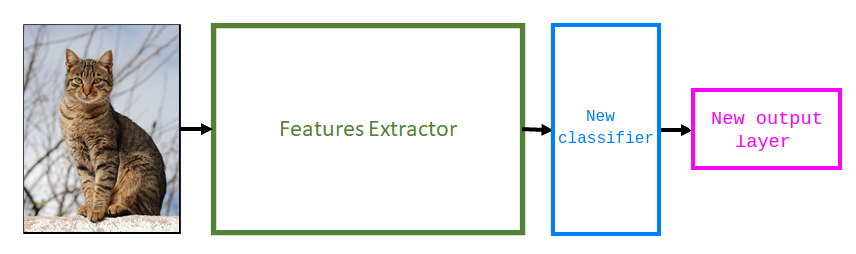
Next, we need to freeze the Feature Extractor layers from the pre-trained model. This is an important step. If you don't freeze the feature extractor layers, your model will re-initialize them. If this happens, you will lose all the learning that has already taken place. This will be no different from training the model from scratch.
The final step is to train the new layers. You only need to train the new classifier on the new dataset.
Once you have done the previous step, you will have a model that can make predictions on your dataset. Optionally, you can improve its performance through fine-tuning. Fine-tuning consists of unfreezing parts of the pre-trained model and continuing to train it on the new dataset to adapt the pre-trained features to the new data. To avoid overfitting, run this step only if the new dataset is large and with a lower learning rate.
When to Use Transfer Learning and Benefits
Let's discuss in which scenarios it is convenient to use transfer learning as well as where it is not convenient to do so.
It is worth using Transfer Learning when you have:
- A low quantity of data: Working with too little data will result in poor model performance. The use of a pre-trained model helps create more accurate models. It will take less time to get a model up and running because you don't need to spend time collecting more data.
- A limited amount of time: Training a machine learning model can take a long time. When you don't have much time – for example, to create a prototype to validate an idea – it is worth considering whether transfer learning is appropriate.
- Limited computation capabilities: Training a machine learning model with millions of images requires a lot of computation. Someone has already done the hard work for you, giving you a good set of weights you could use for your task. This reduces the amount of computation – and therefore equipment – required to train your model.
When You Shouldn't Use Transfer Learning
On the other hand, transfer learning is not appropriate when:
- There is a mismatch in domain: most of the time, transfer learning does not work if the data with which the pre-trained model has been trained is very different from the data that we will use to do transfer learning. It is necessary for the two datasets to be similar in what they predict (i.e. training a defect classifier based on a dataset with similar products that show annotated scratches and dents).
- You need to use a large dataset: Transfer learning may not have the expected effect on tasks that require larger datasets. As we add more data, the performance of the pre-trained model gets worse. The reason is that as we increase the size of the fine-tuned dataset, we are adding more noise to the model. Since the pre-trained model performs well on the pre-trained dataset, it may be stuck in the local minimum point, and it cannot adapt to the new noise at all. In case we have a large dataset, we should consider training the model from scratch so our model can learn key features from our dataset.
How Important Is Subject Similarity for Transfer Learning?
Using transfer learning to initialize your computer vision model from pre-trained weights rather than starting from scratch (initializing randomly) has been shown to increase performance and decrease training time. It makes sense, by giving your model prior knowledge about basic concepts like lines, curves, textures, and "things" it should be able to more quickly learn about the specific objects of interest in a custom dataset.
But, I've always been curious: does transfer learning always produce better results than a randomly initialized training run? What if the base domain is from an entirely different domain? Is it more important that my starting checkpoint was trained on similar images or that it was trained on a huge number of images?
I decided to run an experiment to find out.
A video summary of this post.
The Task
I decided to use a Mask Wearing dataset as my test subject and observe the results of using different starting checkpoints on model performance for object detection models.

The Setup
I decided to use YOLOv5 as the model architecture for these tests. It has been shown to generalize well and has support for transfer learning. But most importantly, it's easy to use so I was able to train all the models I needed for this test in a single day. I followed this tutorial to train YOLOv5 on a custom dataset to train both the starting points and the final models.
I used the YOLOv5s model size with the default settings, including a 640x640 input size and the built-in augmentations. The models were set to train until the loss on the validation set did not improve for 50 consecutive epochs (in practice this turned out to be about 1 hour on a V100 GPU and there was little variance between the training runs).
The Transfer Learning Starting Points
I decided to train four models from four different checkpoints on the Mask Wearing dataset and compare their performance. The starting points I chose were:
- Randomly Initialized Weights - to get a baseline without using transfer learning. This is the default if you don't pass any weights to use as a starting checkpoint.
- Microsoft COCO - this is the industry standard for transfer learning; it's trained on millions of photos containing a wide variety of common objects. Notably, faces is not one of the classes in COCO so, while it has broad prior knowledge of general concepts, it does not have any knowledge particularly relevant for our mask detection task.
- WIDER FACE - a dataset of 16,000 images with faces labeled. I specifically chose this dataset because it seemed very similar to the mask wearing task. Our model will first need to find faces to determine if they're wearing masks. I was particularly interested in whether the better specificity of prior knowledge outweighed the fact that it has seen 100x less images than the COCO trained model.
- BCCD - a dataset of blood cell images from a microscope. This dataset was chosen as a particularly perverse example: it is about as far away from face mask detection as possible. By including it, I wanted to see if transfer learning was always helpful (or at the very least neutral) or if it could sometimes degrade performance by locking a model with its prior biases.
The Results
The results on the held-back test set are as follows:
| Starting Point | Starting mAP | mAP | Precision | Recall |
|---|---|---|---|---|
| Random | N/A | 76.9% | 33.1% | 84.7% |
| COCO | 55.8% | 83.6% | 50.8% | 90.0% |
| WIDER Face | 65.6% | 87.5% | 64.3% | 88.3% |
| BCCD | 90.9% | 75.9% | 41.6% | 83.0% |
It can be hard to visualize what this means in practice, so here is an example prediction from each trained model on two images from the testing set (visualized at 50% confidence):
In these examples, you can see that the "from scratch", "bccd", and "coco" starting-point models missed some masks completely (the profiled person facing to the right in the first photo and the bccd model missed the person completely in the second photo) while the WIDER Face starting-point model did better.
Interestingly, there are some examples where the COCO model performed better; notably, the COCO based model identifies a mask in this photo where a man is wearing a mask that covers his entire face and the WIDER Face based model does not:
The checkpoint you choose to start from for transfer learning does affect the quality of your final model. Choosing a more closely aligned starting point to your problem produces better results (even if it has learned from fewer example images), and choosing a poor starting point can be worse than using randomly initialized weights (but probably not by much).
Luckily, Roboflow Train makes it easy to experiment with different starting checkpoints for your models. You can use a number of models pre-trained on datasets like COCO or previous versions of your own models as a starting point. Try it out today.
Key Transfer Learning in Computer Vision Takeaways
Transfer learning models focus on storing knowledge gained while solving one problem and applying it to a different but related problem. Instead of training a neural network from scratch, many pre-trained models can serve as the starting point for training. These pre-trained models give a more reliable architecture and save time and resources.
You may want to consider using transfer learning when you either have a limited amount of data, lack of time, or limited computation capabilities.
You should not use transfer learning when the data you have is different from the data that the pre-trained model has been trained with, or if you have a large dataset. In these two cases, it will be better to train a model from scratch.
Now you have the information you need to understand the basics of transfer learning and when it is and is not useful. Happy model building!
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (May 23, 2025). What Is Transfer Learning?. Roboflow Blog: https://blog.roboflow.com/what-is-transfer-learning/