
Pose estimation has become essential across industries, from fitness tracking and sports analytics to healthcare rehabilitation. With rapid advancements in transformer architectures and vision language models, the landscape of pose estimation has evolved dramatically. Modern models such as YOLO11 Pose, MediaPipe Pose, and specialized architectures deliver unprecedented accuracy while maintaining real-time performance on edge devices.
In this guide, we explore the best pose estimation models available today, from established frameworks to cutting-edge innovations, and show how to deploy them efficiently. Whether you're building a fitness app, analyzing athletic performance, or enabling human-computer interaction, we'll help you choose the right model for your application.
What Is Pose Estimation?
Pose estimation, also called keypoint detection, is a computer vision technique that identifies specific anatomical landmarks (keypoints) on human bodies in images and videos to understand their poses. While pose estimation can be applied to animals or other objects, human pose estimation dominates due to its wide range of practical applications.
The process involves:
- Keypoint Detection: Identifying the locations of joints (e.g., elbows, knees, wrists, shoulders) in pixel coordinates
- Skeleton Formation: Connecting keypoints to form a skeletal representation of the body
- Pose Analysis: Interpreting body orientation and movement patterns
Modern pose estimation models can detect multiple people simultaneously, handle occlusions where body parts are hidden, and work in real time on consumer hardware.
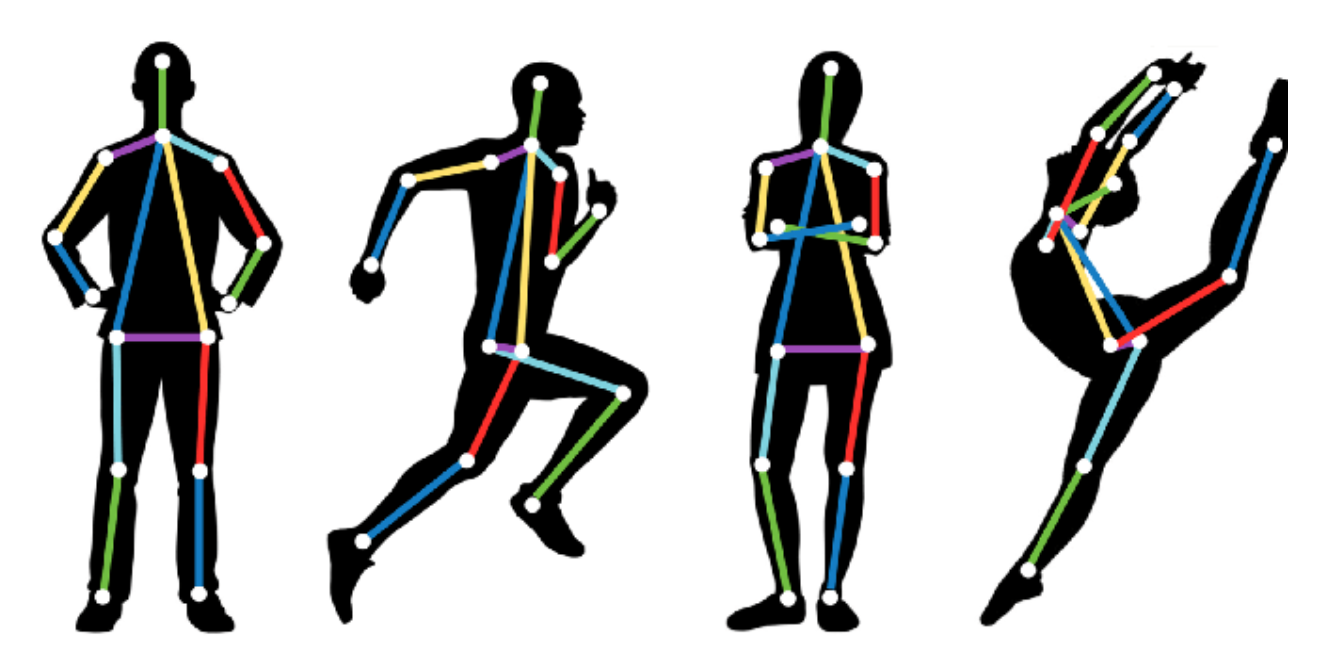
Methods of Pose Estimation
Pose estimation approaches have evolved significantly over the decades. For a comprehensive history of these advancements, see our detailed article on pose estimation algorithms and their evolution.
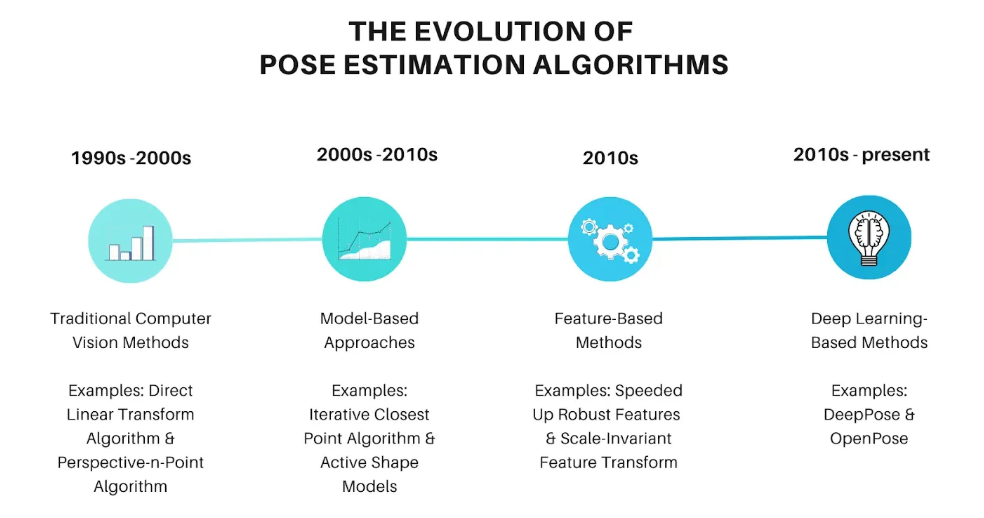
Traditional Computer Vision Methods (1990s-2000s)
Early approaches relied on geometric calculations and feature-based methods. The Direct Linear Transform (DLT) and Perspective-n-Point (PnP) algorithms estimated camera pose using known 3D-2D correspondences. While effective with manual calibration, these methods required extensive preprocessing and struggled with occlusions.
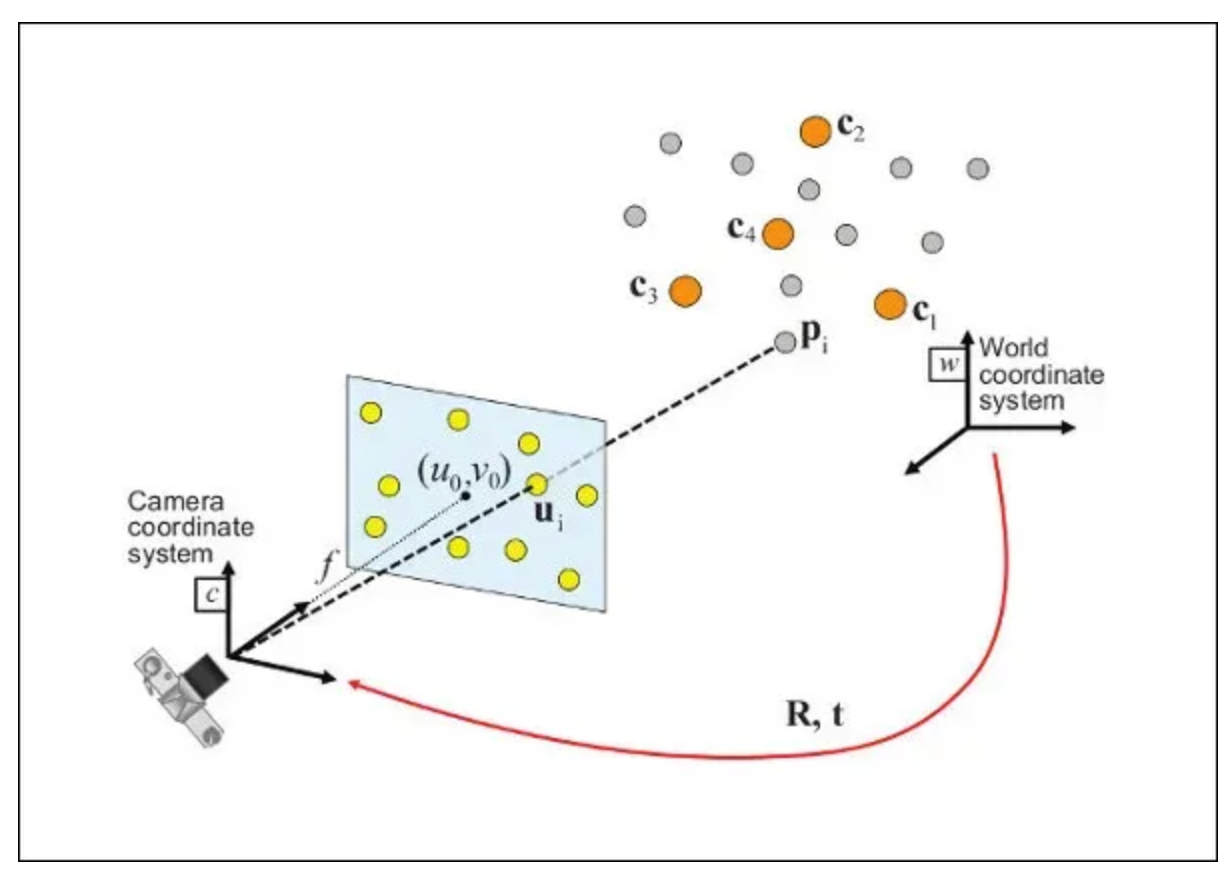
Model-based Approaches (2000s-2010s)
Model-based methods used predefined skeletal models and iterative alignment. The Iterative Closest Point (ICP) algorithm aligned point clouds.
While Active Shape Models (ASM) combined statistical shape information with image features. These approaches improved robustness but remained computationally expensive.

Feature-Based Methods (2010s)
Feature extraction algorithms such as SIFT (Scale-Invariant Feature Transform) and SURF (Speeded Up Robust Features) identify distinctive key points and their descriptors. While fast, these methods often missed complex body structures and struggled in crowded scenes.

Deep Learning-Based Methods (2010s-Present)
Deep learning revolutionized pose estimation. Early pioneers like DeepPose introduced CNNs for direct joint regression. OpenPose pioneered multi-person detection using Part Affinity Fields (PAFs), while modern transformer-based architectures capture fine-grained spatial relationships with unprecedented accuracy.
Today's state-of-the-art models leverage:
- Convolutional Neural Networks (CNNs): Efficient feature extraction from images
- Transformer Architectures: Capturing long-range dependencies between keypoints
- Attention Mechanisms: Focusing on relevant features and handling occlusions
- Heatmap Regression: Predicting confidence maps for each keypoint location
- Vision Transformers (ViT): End-to-end spatial reasoning without convolutions
Best Pose Estimation Models Criteria
Here are the criteria we used to select these pose estimation models:
1. Accuracy on Standard Benchmarks
Models should demonstrate strong performance on industry-standard benchmarks like COCO Keypoints and MPII Human Pose. We prioritize models achieving high Object Keypoint Similarity (OKS) scores, indicating reliable detection across different body sizes and visibility conditions.
2. Real-time Performance
The model should achieve inference speeds suitable for live applications, typically processing images at 20+ FPS on standard hardware (NVIDIA T4, edge devices). This ensures viability for interactive applications and video processing.
3. Multi-person Detection
Modern applications require detecting multiple people simultaneously in complex scenes. We favor architectures that handle crowded environments, occlusions, and overlapping subjects without performance degradation.
4. Deployment Flexibility
Models should support diverse deployment targets, from cloud GPUs to edge devices like Raspberry Pi and NVIDIA Jetson. Lightweight variants enable mobile and embedded applications.
5. Ease of Integration
Support for popular frameworks (PyTorch, TensorFlow, ONNX) and production-ready tools ensures practitioners can move from research to deployment smoothly.
6. Customization Capabilities
The ability to train on custom datasets and adapt to domain-specific poses (sports, medical, industrial) is essential for specialized applications.
The Best Pose Estimation Models
Here's our list of the best pose estimation models.
1. YOLO11 Pose
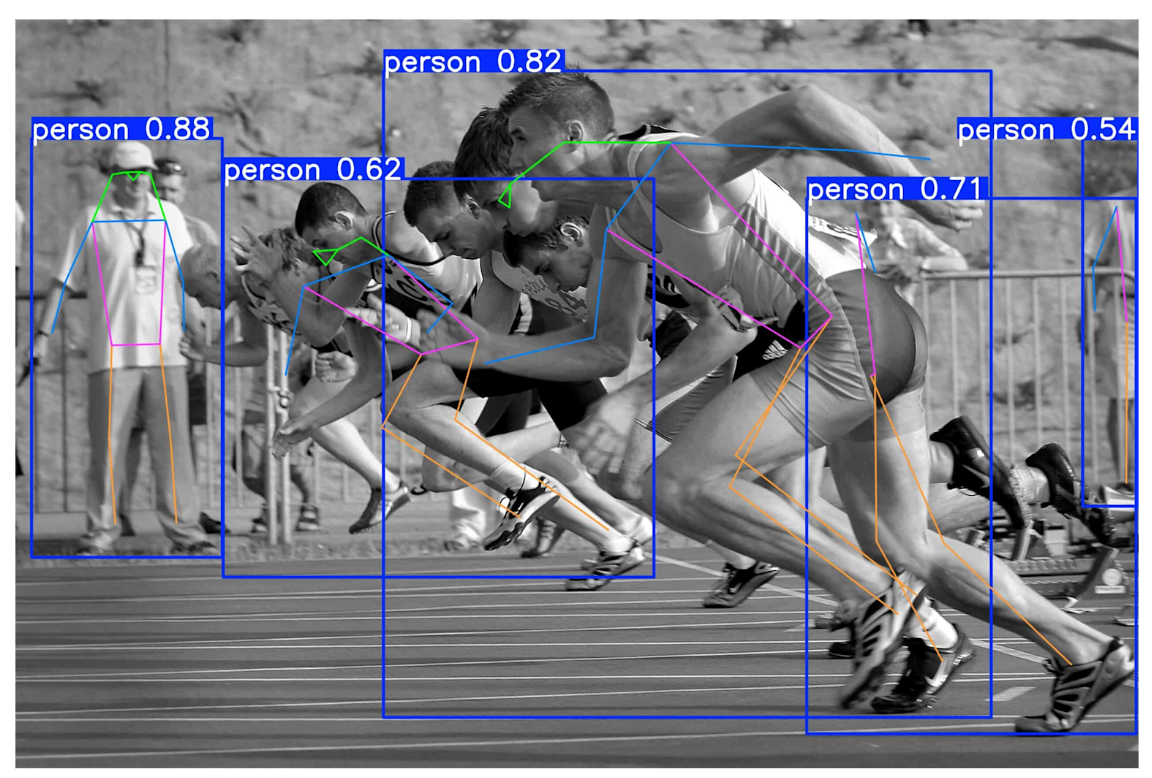
YOLO11 Pose is the latest and most advanced pose estimation variant of Ultralytics' widely-adopted YOLO framework, released in late 2024 and now the production standard for 2025. Representing the latest generation of single-stage pose estimation, YOLO11 Pose simultaneously detects people and estimates their keypoint positions in one forward pass, offering significant improvements over its predecessors.
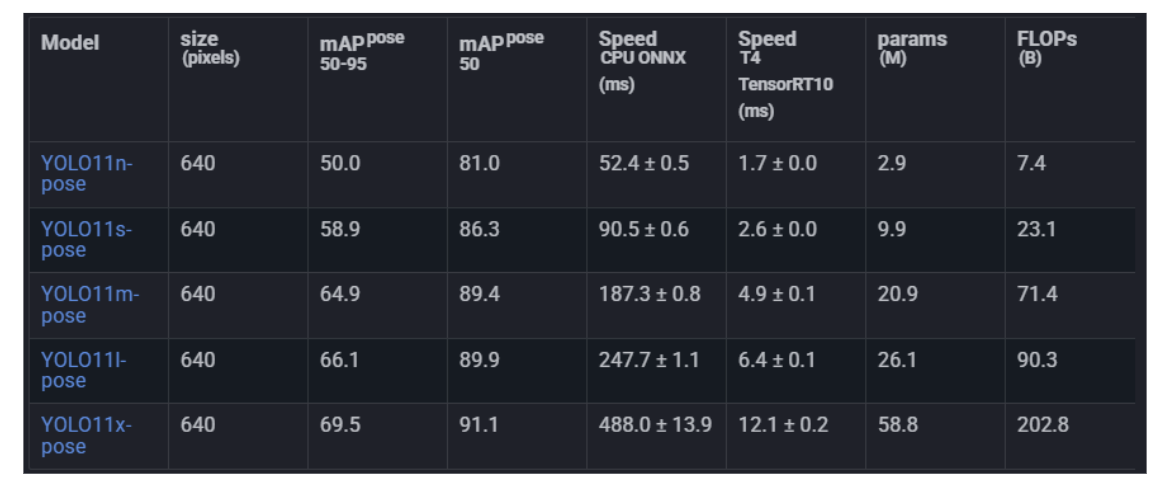
The model leverages YOLO11's proven architecture: an anchor-free, single-stage detector with a CNN backbone optimized for both speed and accuracy. For pose estimation specifically, YOLO11 Pose predicts 17 keypoints following the COCO format (nose, eyes, ears, shoulders, elbows, wrists, hips, knees, ankles), enabling comprehensive human pose analysis.
Key strengths:
- Real-time Performance: Achieves 30+ FPS on NVIDIA T4 GPUs for high-resolution images.
- Multi-size Variants: Available in Nano (n), Small (s), Medium (m), Large (l), and Extra-Large (x) versions to fit different computational budgets.
- Proven Accuracy: Reaches 89.4% mAP@0.5 on the COCO Keypoints dataset (YOLOv11m).
- Easy Training: Supports seamless fine-tuning on custom datasets using Ultralytics' Python API.
Broad Deployment Support: Runs efficiently on desktop, mobile, edge devices, and cloud infrastructure.
Getting started with YOLO11 Pose requires minimal setup. Install the Ultralytics package and run inference in under 5 minutes:
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO("yolov11m-pose.pt")
source = "path/to/image.jpg"
results = model(source)
# Visualize results
plotted_results = results[0].plot()
cv2.imwrite("result.jpg", plotted_results)
The model's flexibility makes it ideal for fitness tracking, sports analysis, rehabilitation monitoring, and interactive applications where customization is valuable. YOLO11 Pose represents a significant leap from previous versions, with architectural refinements that improve both accuracy and efficiency compared to YOLOv8 Pose.
2. MediaPipe Pose
MediaPipe Pose is Google's optimized framework specifically designed for single-person pose estimation with exceptional performance on resource-constrained devices. Using a two-stage pipeline, person detection followed by keypoint localization, MediaPipe Pose achieves remarkable accuracy while maintaining blazing-fast inference speeds.
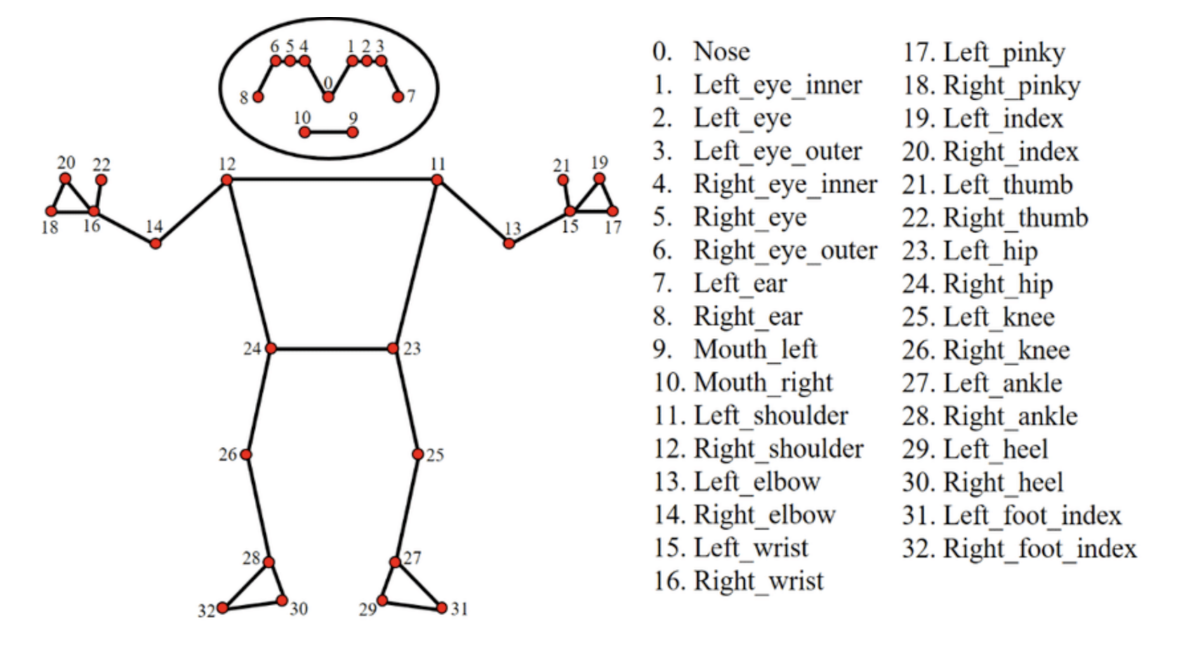
What distinguishes MediaPipe Pose is its comprehensive keypoint topology. Rather than limiting itself to the standard 17 COCO keypoints, MediaPipe Pose identifies 33 landmark locations across the entire body, including:
- Full-body joints (i.e., shoulders, hips, elbows, knees, ankles)
- Hand keypoints (e.g., finger landmarks)
- Foot keypoints (detailed ankle and toe positions)
- Face-related landmarks (for a more complete body context)
This extended keypoint set enables sophisticated pose-analysis tasks like detailed hand-gesture recognition and fine-grained movement tracking.
Key strengths:
- Lightning-Fast Inference: Capable of processing images at 30+ FPS on CPU alone, without requiring GPU acceleration.
- Mobile-Optimized: Achieves excellent real-time performance on Android and iOS devices.
- Robust Tracking: Includes temporal smoothing across frames for stable video-based pose analysis.
- Efficient Model Size: Enables edge‐deployment with very small model footprints.
- Cross-Platform Support: Runs seamlessly across desktop, mobile, and web platforms.

Deployment options:
Python via MediaPipe Python package, Web via MediaPipe JavaScript/Web solutions, Mobile via native Android and iOS SDKs, Self-hosted via Docker containers.
MediaPipe Pose particularly excels in the following areas:
- Fitness applications - real-time workout form analysis and exercise tracking
- Rehabilitation / physical therapy - movement monitoring, feedback, and recovery tracking
- Gaming - motion-controlled interactive experiences
- Live streaming & AR - real-time pose effects and augmented reality overlays
- Accessibility - sign-language recognition and assistive technologies
The framework's two-stage approach prevents unnecessary keypoint detection when no person is present, improving efficiency in sparse scenes. Recent integrations with Google's ML Kit bring on-device machine learning capabilities directly to mobile applications, making it an excellent choice for privacy-conscious deployments.
3. HRNet (High-Resolution Network)
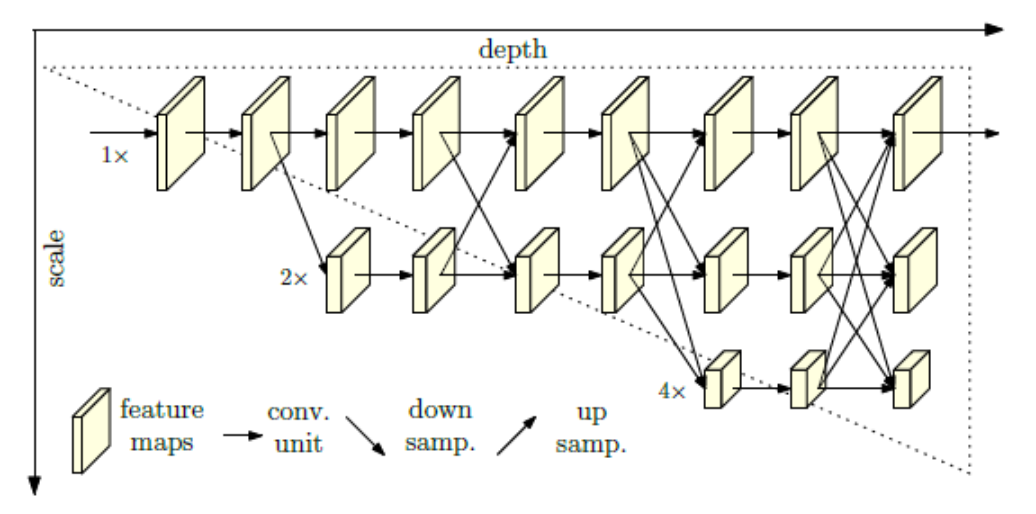
HRNet introduces a significant shift in pose-estimation architecture: instead of following the conventional path of progressively down-sampling feature maps (losing spatial resolution) and then up-sampling, it maintains high-resolution representations throughout the network while also incorporating multi-scale context through parallel branches.
- It starts with a high-resolution sub-network as the first stage.
- It then gradually adds lower-resolution branches in parallel, rather than serially chaining high-to-low resolution only.
- Frequently, the multiple parallel branches exchange information (multi-scale fusion) so that high-resolution streams benefit from contextual cues and low-resolution streams benefit from fine spatial detail.
Traditional CNN-based pose estimation models often lose fine spatial detail due to repeated down-sampling, which impairs the localization of small body parts (e.g., fingers, toes) and reduces the precision of keypoint localization. HRNet addresses this limitation by preserving high-resolution data throughout the network, resulting in improved spatial precision and better keypoint heatmap prediction.
Key strengths:
- Superior Accuracy: Achieves 89.0% mAP@0.5 on COCO Keypoints; among the highest-performing models at release.
- Precise Localization: Excels at detecting small joints (e.g., fingers, toes) with pixel-level accuracy.
- Efficient Design: Maintains competitive inference speeds despite its high accuracy.
- Proven Robustness: Effectively handles occlusions and complex body configurations.
- Transfer Learning: Pre-trained weights adapt well to domain-specific pose estimation tasks.
Architectural variants:
- HRNet-W32: A “lighter” width variant suitable for scenarios with more constrained resources.
- HRNet-W48: The standard version that balances accuracy and speed.
- HRNet-W64: A higher-capacity variant aimed at maximum accuracy, usually for offline or batch processing rather than real-time edge inference.
HRNet shines in applications requiring precise key point localization, such as detailed movement analysis for sports biomechanics and technique evaluation, medical assessment for gait analysis and rehabilitation evaluation, and industrial ergonomics for workplace posture monitoring and injury prevention. It also provides fine-grained gesture recognition for capturing subtle hand and finger movements.
More recent work builds on HRNet’s high-resolution concept: for example, the “Detail-Enhanced HRNet” (DE-HRNet) introduces modules to recover low-level features and improve scale-variation handling. Also, lightweight variants (e.g., Lite-HRNet) aim to bring HRNet-level accuracy into resource-constrained environments.
4. MoveNet
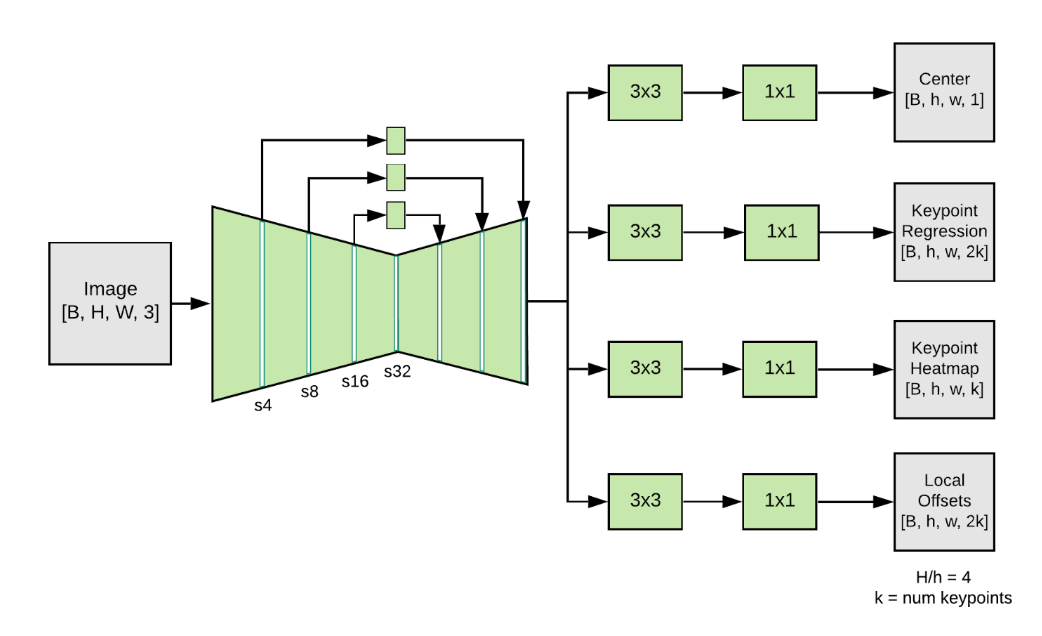
MoveNet, developed by Google and trained on the PoseTrack dataset, represents a lightweight yet highly accurate approach to human pose estimation. Optimized for edge deployment, MoveNet demonstrates that efficient models don't require sacrificing accuracy.
The model offers two variants for different deployment scenarios:
Lightning is an ultra-lightweight variant achieving 192×256 resolution inference in under 7ms on mobile devices. Thunder is a higher-accuracy variant that processes 256×256 resolution images in approximately 20ms on devices.

Key strengths:
Extreme Efficiency runs on mobile phones, Raspberry Pi, and embedded devices without GPU acceleration. High Accuracy remains competitive with much larger models despite minimal model size. Fast Inference sub-10ms latency enables real-time interactive applications. Single-Person Focus optimizes for primary subject detection with a clean background. Browser Support via TensorFlow.js enables web-based deployment.
Performance characteristics:
- Lightning variant: ~7ms inference on mobile CPU
- Thunder variant: ~25-35ms inference on mobile CPU
- Achieves 65%+ accuracy on PoseTrack dataset across both variants
MoveNet excels in mobile-first applications such as fitness apps for workout form correction with minimal battery drain, web applications for browser-based pose detection without server costs, IoT devices for edge computing scenarios with minimal computational resources. It also provides real-time feedback for interactive pose coaching with sub-100ms latency.
The framework integrates seamlessly with TensorFlow and TensorFlow.js, enabling deployment from cloud to browser in minutes. Recent developments show strong integration with on-device ML systems, particularly for real-time rep counting and exercise classification on Android devices using TensorFlow Lite quantization.
5. ViTPose
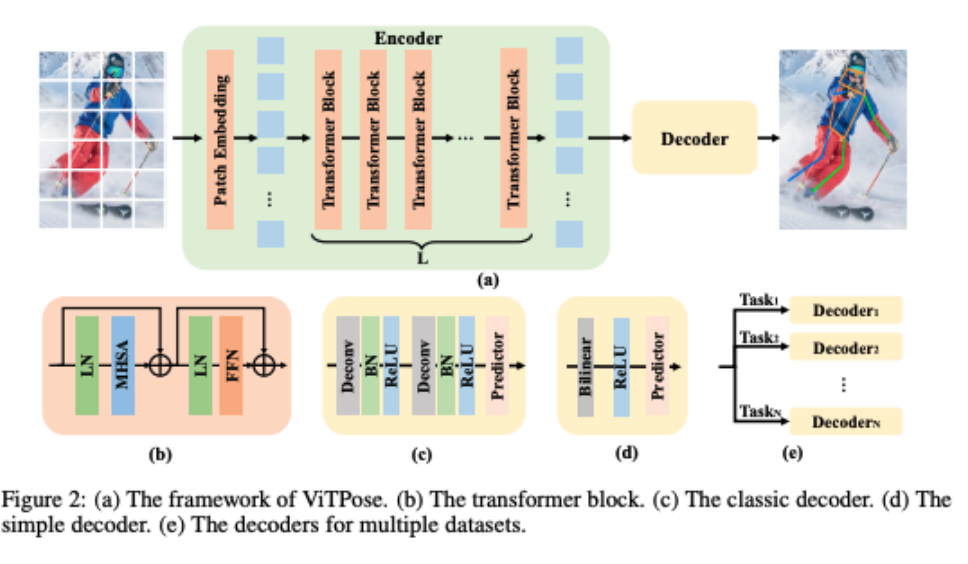
ViTPose represents the cutting edge of transformer-based pose estimation architectures, demonstrating that plain vision transformers can achieve state-of-the-art performance for human pose estimation. Unlike CNN-based approaches that progressively downsample features, ViTPose uses self-attention mechanisms to capture global relationships between joints with unprecedented flexibility.
ViTPose employs plain, non-hierarchical vision transformers as backbones to extract features for a given person instance and a lightweight decoder for pose estimation. It can be scaled from 100M to 1B parameters by taking advantage of the transformers' scalable model capacity and high parallelism.
Key strengths:
- State-of-the-art accuracy: ViTPose achieves competitive COCO results (single-model top rows: 80.9 AP with ViTAE-G; ensemble 81.1 AP).
- Scalability: model sizes span small → huge (e.g., ViTPose-B ≈ 86M params up to ViTPose-H ≈ 632M params), so you can pick a variant to match compute limits.
- Flexibility: works with different attention types, input resolutions, pre-training strategies (ImageNet/MAE/downstream pretraining), and multi-dataset fine-tuning. Performance improves at higher input resolutions.Transferability: large→small knowledge transfer is supported via a simple knowledge token (token-based distillation) to boost smaller models with little extra memory.
- Practical trade-offs: larger backbones give higher AP but reduce throughput; ViTPose aims for a good throughput/accuracy tradeoff on modern GPUs.
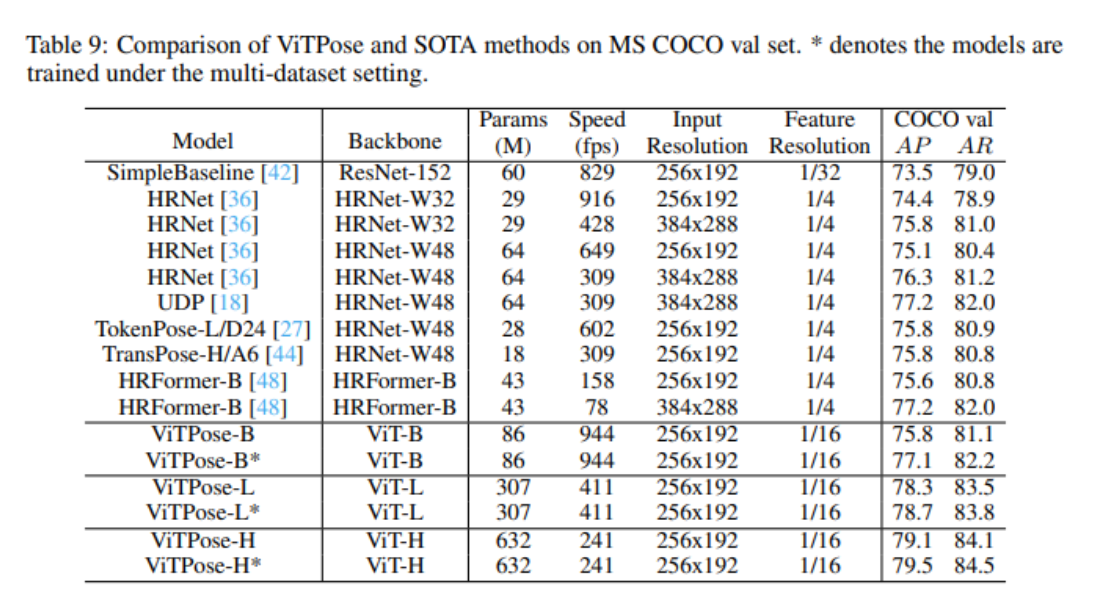
Model variants:
- ViTPose-B (Base): 86M parameters with balanced performance
- ViTPose-L (Large): 307M parameters with enhanced accuracy
- ViTPose-H (Huge): 632M parameters with maximum performance
ViTPose particularly excels in research applications where maximum accuracy justifies computational cost, complex scenario testing for validating approaches in extreme conditions with occlusions and unusual poses, advanced research exploring novel loss functions and architectural innovations, and high-precision applications where accuracy is paramount over speed.
Recent advancements include efficient attention mechanisms like window attention and pooling-window attention that reduce computational overhead while maintaining accuracy, making ViTPose-derived models viable for practical deployments.
6. DETRPose
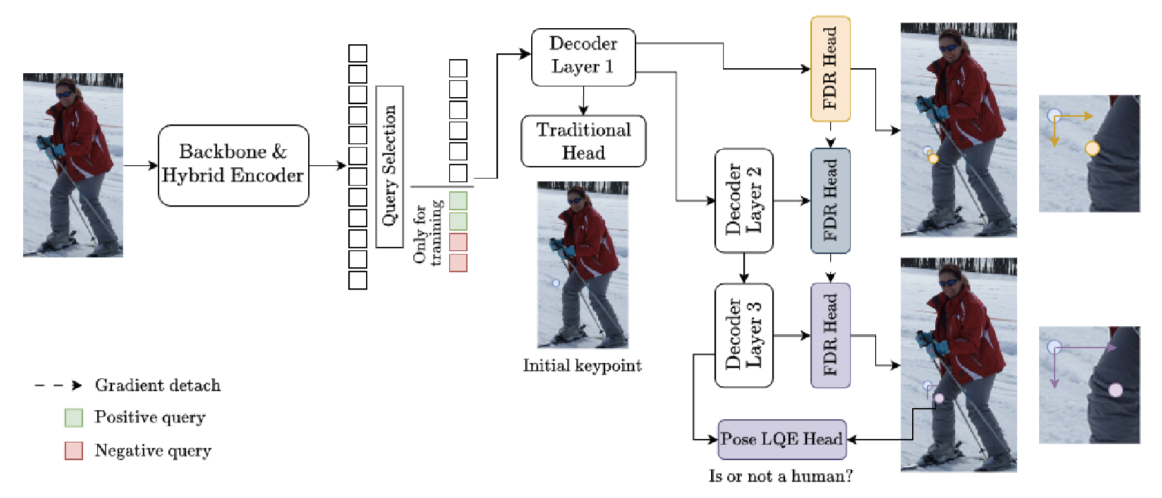
DETRPose represents the first real-time transformer-based model specifically designed for multi-person pose estimation, released in 2025 as a breakthrough addressing previous limitations of transformer-based approaches. Unlike CNN-based single-stage methods, DETRPose achieves real-time performance without quantization libraries while maintaining competitive accuracy.
The key innovation is Pose Denoising, a novel technique adapted from object detection but tailored for keypoint estimation. This approach generates both positive and negative query samples during training, improving model robustness and accelerating convergence.
Key strengths:
- Real-time detection: Processes full images in real-time without quantization.
- High accuracy: Outperforms YOLO11-X and YOLOv8-X on COCO test-dev and CrowdPose.
- Efficient parameters: Matches or exceeds larger models with fewer parameters.
- Fast training: Requires 5–10x fewer epochs than comparable transformer models.
Performance highlights:
- Outperforms YOLO11-X on benchmark datasets
- Fewer parameters than competing XL-variant models
- Faster inference speed than previous transformer approaches
- Achieves state-of-the-art results on CrowdPose for occlusion handling
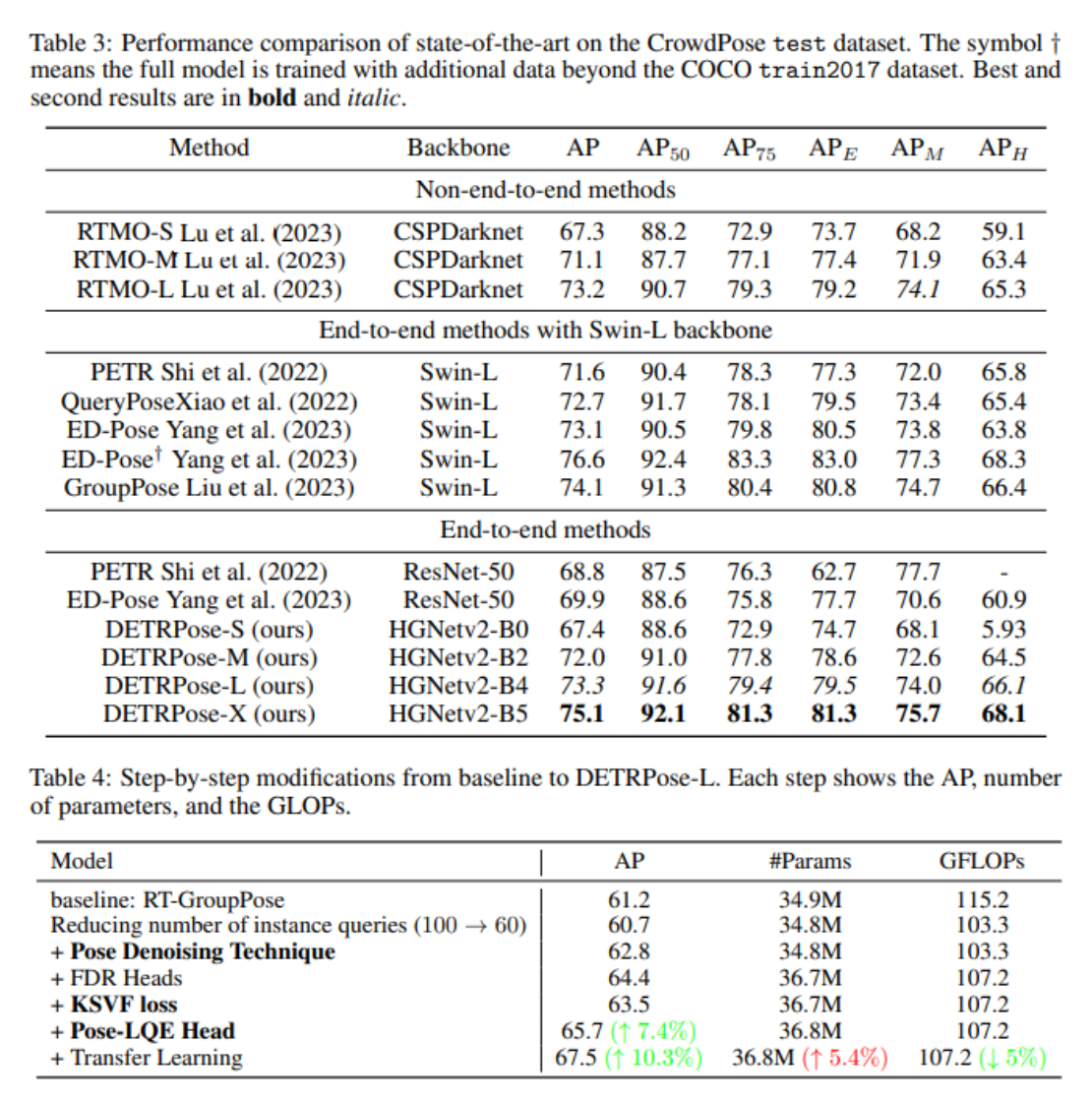
DETRPose excels in crowd analysis for detecting poses in stadiums and public events, research applications where cutting-edge transformer approaches are valuable, and complex scene understanding, where end-to-end training provides advantages over traditional bottom-up approaches.
Train Custom Keypoint Models on Roboflow
Beyond deploying pre-trained pose estimation models, you can train custom pose estimation models tailored to your specific application using Roboflow's keypoint detection capabilities. This enables pose estimation for domain-specific scenarios like industrial settings with custom body-part poses for ergonomic analysis, sports analysis with sport-specific body configurations and movements, medical assessment with clinical gait patterns and therapeutic exercises, and animal pose with tracking of animal movements for wildlife or veterinary applications.
Roboflow provides end-to-end support for keypoint detection model training:
Define Custom Skeletons: Create keypoint taxonomies specific to your domain (not limited to standard body keypoints)
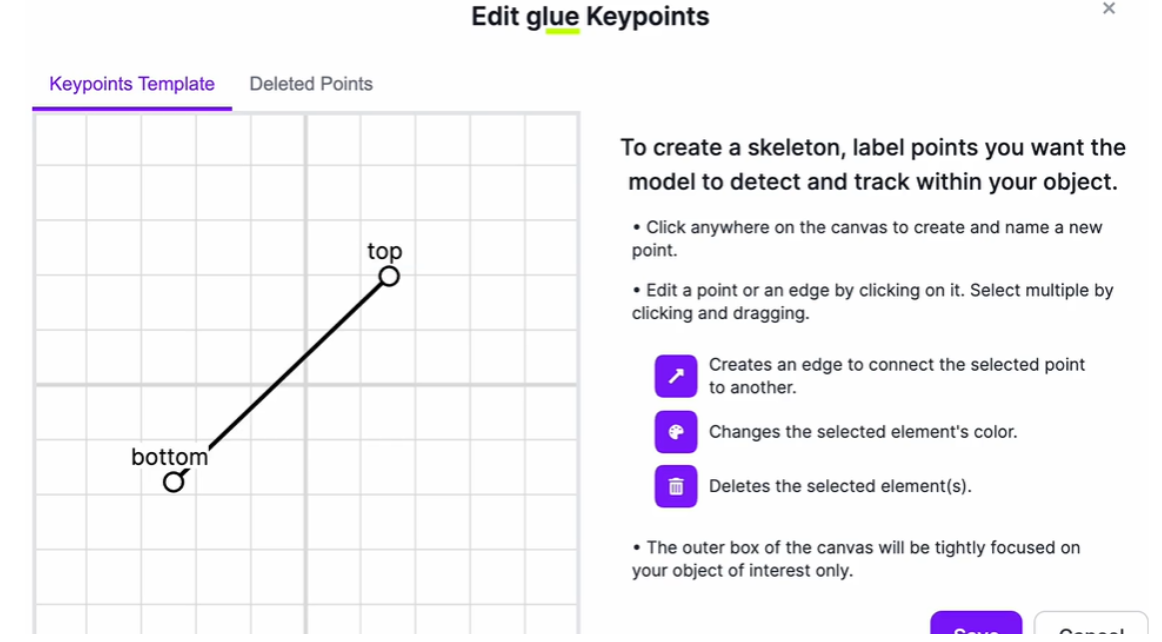
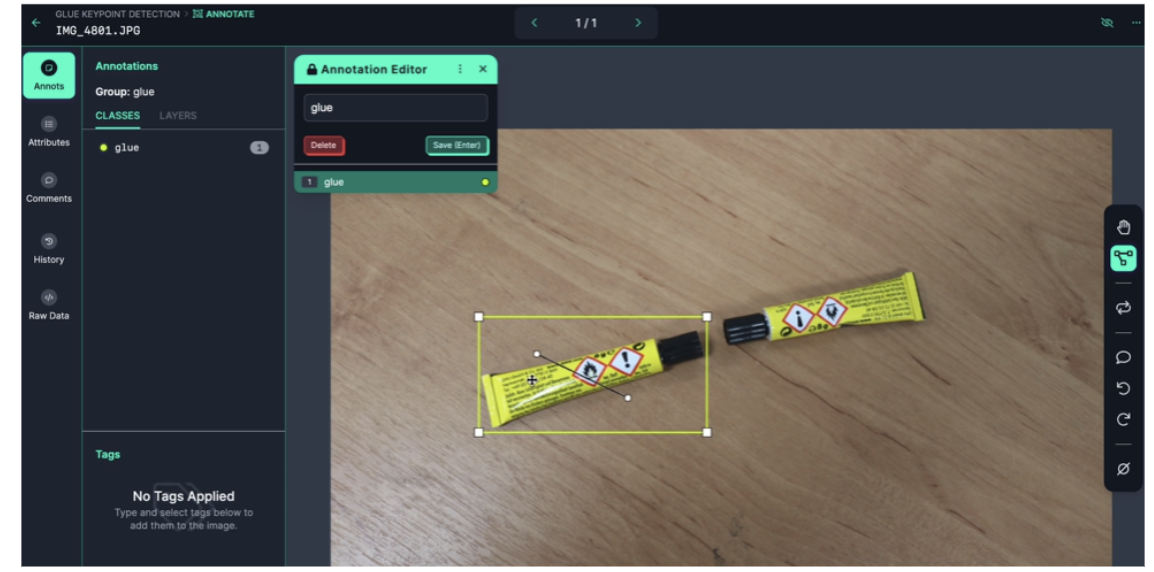
Intuitive Annotation Tools: Mark keypoint locations on images with smart suggestions
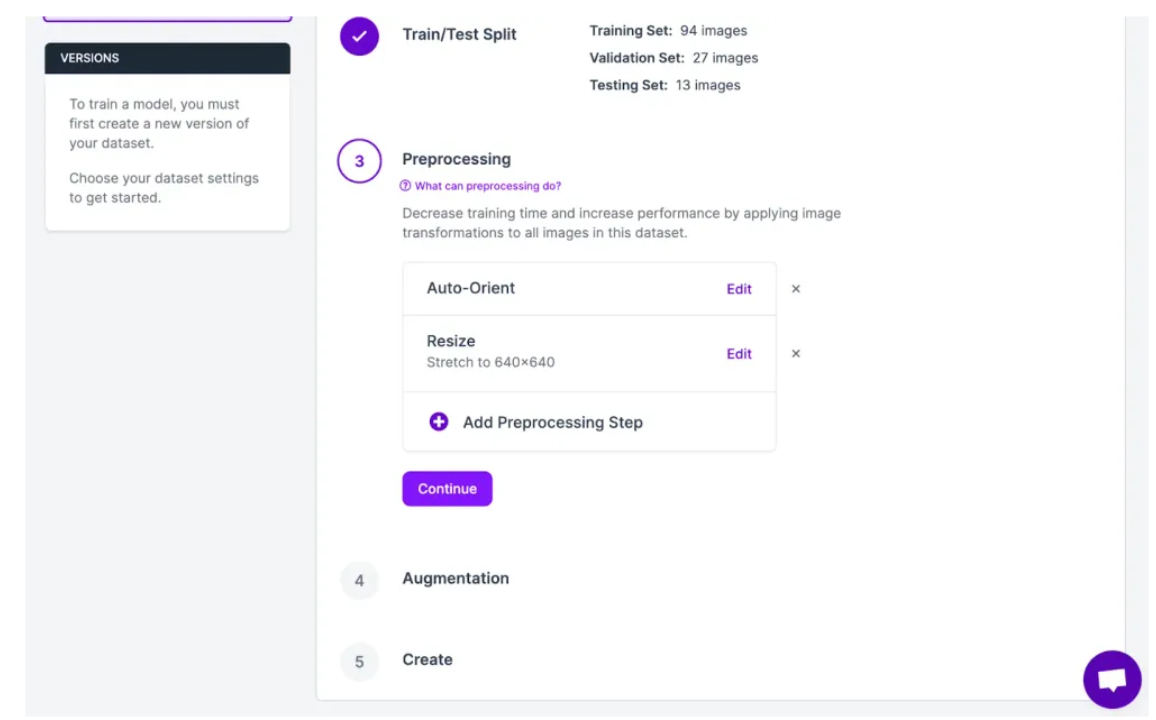
Preprocessing & Augmentation: Apply optimizations to improve model generalization
Cloud Training: Train models on Roboflow's managed GPUs without infrastructure setup
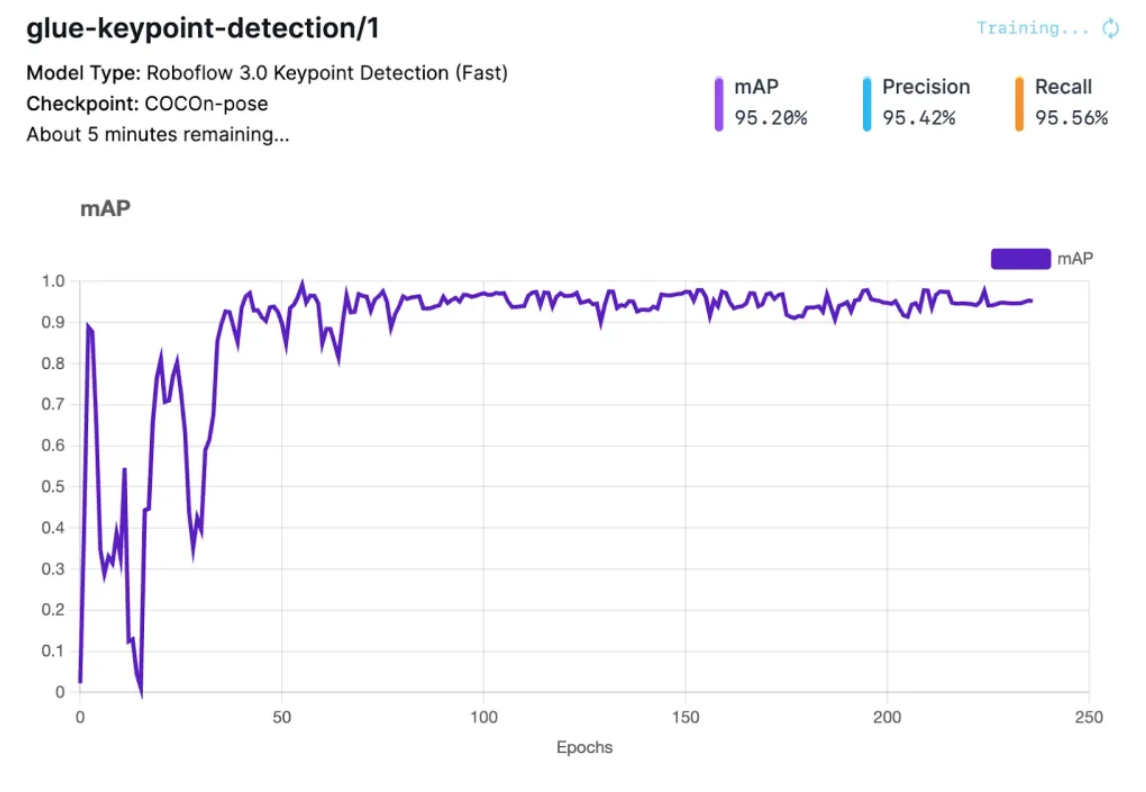
Easy Deployment: Deploy trained models via Roboflow Inference for immediate inference
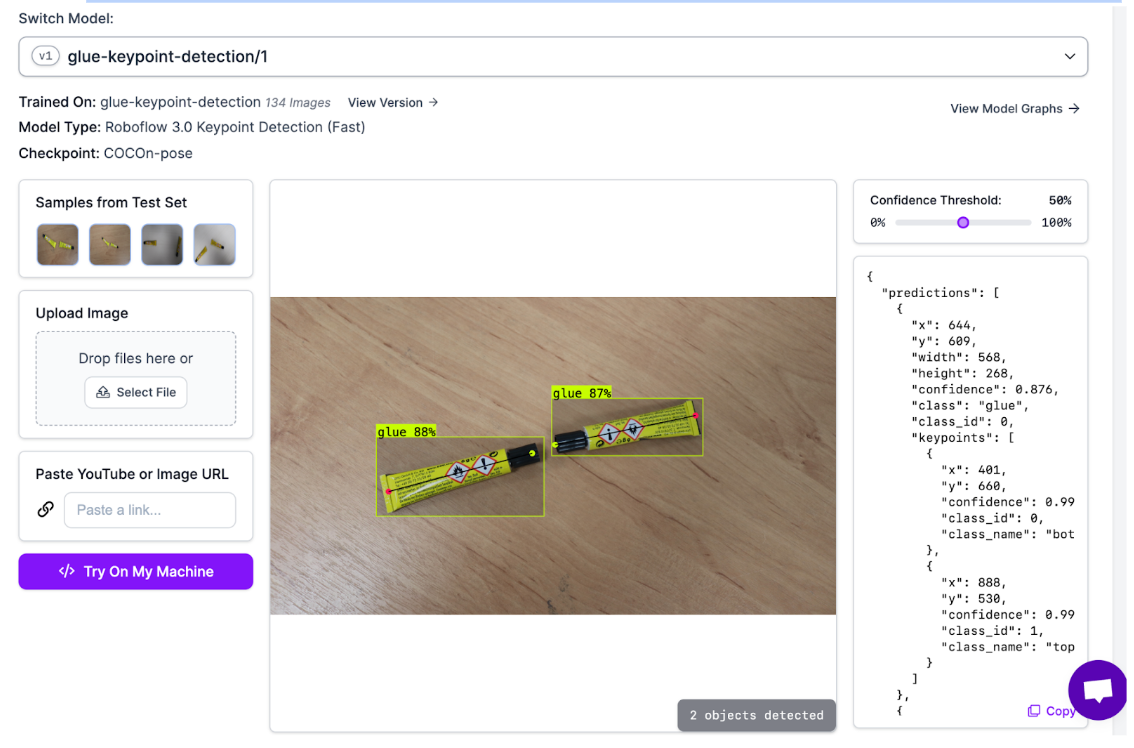
For detailed instructions on labeling, training, and deploying keypoint detection models on Roboflow, see the complete guide on keypoint detection.
Real-World Pose Estimation Applications
Modern pose estimation models enable transformative applications across industries:
- Fitness & Wellness: Provides real-time form correction during workouts, personalized exercise coaching, and injury prevention through posture monitoring.
- Sports Analytics: Enables biomechanical analysis for technique improvement, instant replay analysis for referees, and athlete performance metrics.
- Healthcare: Supports rehabilitation progress tracking, movement disorder assessment, gait analysis for physical therapy, and surgical training simulations.
- Entertainment: Includes motion capture for animation and gaming, interactive fitness experiences, and virtual reality integration.
- Industrial: Enables workplace safety monitoring, ergonomic assessment, worker fatigue detection, and accident prevention.
- Accessibility: Includes sign language recognition, gesture-based interfaces, and assistive technology for individuals with disabilities.
- Surveillance: Supports anomaly detection, activity recognition, crowd behavior analysis, and public safety applications.
Choose the Right Pose Estimation Model
Pose estimation model recommendations:
- For real-time mobile applications: Use MediaPipe Pose for its exceptional efficiency on CPU-only devices, or MoveNet Lightning for browser-based deployment.
- For production systems balancing speed and accuracy: Deploy YOLO11 Pose, which offers multiple size variants to match your computational budget while maintaining competitive accuracy.
- For maximum accuracy on high-end hardware: Use ViTPose when computational resources are available and precision is paramount.
- For complex multi-person scenarios: Choose DETRPose for cutting-edge transformer-based accuracy, or YOLO11 for proven real-time performance.
Which Pose Estimation Model Is Most Usable?
YOLO11 Pose strikes the best balance for most practitioners. It achieves 89.4% mAP@0.5 on COCO Keypoints while maintaining real-time inference speeds of 200+ FPS on standard GPU hardware like the NVIDIA T4. Its multi-size variant architecture (Nano through XLarge) allows you to match your computational budget, whether deploying on edge devices or cloud infrastructure.
Compared to alternatives, YOLO11 Pose offers several advantages. It delivers a better speed-accuracy tradeoff, outperforming MediaPipe Pose in accuracy while remaining competitive in speed for multi-person scenarios. It also supports easier training, with seamless fine-tuning on custom datasets using the Ultralytics Python API. Additionally, it provides production readiness through a mature ecosystem with extensive deployment support and flexibility, handling both single and multi-person detection effectively.
Conclusion: Best Pose Estimation Models
The current pose‑estimation landscape offers models optimized for a variety of use cases. For most applications, YOLO11 Pose presents an appealing balance of accuracy, inference speed, and ease of training. Meanwhile, lightweight models such as MediaPipe Pose and MoveNet Lightning are particularly well‑suited for mobile and edge devices with limited compute.
For domain‑specific pose estimation that departs from standard human keypoint sets, platforms such as Roboflow enable custom model training without building from scratch.
Whether you are building fitness apps, sports analytics systems, or healthcare motion-tracking tools, these state-of-the-art models offer the accuracy and efficiency needed for production deployment.
Written by Aarnav Shah
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Nov 6, 2025). Best Pose Estimation Models. Roboflow Blog: https://blog.roboflow.com/best-pose-estimation-models/