
Pose estimation, the computer vision task of detecting key body joints in images and video, has progressed from hand-crafted geometric methods in the 1990s through graphical models in the 2000s to convolutional neural network approaches that now dominate the field. This overview traces that arc, covering traditional methods, model-based and feature-based techniques, and modern deep learning models including YOLOv7 Pose, YOLOv8 Pose, and MediaPipe Pose. Benchmark datasets like COCO, MPII Human Pose, and Human3.6M remain central to evaluating progress across all these approaches.
This article was contributed to the Roboflow blog by Abirami Vina.
What is Pose Estimation?
Pose estimation, also called keypoint detection, is a computer vision technique that pinpoints the key body joints of a human in images and videos to understand their pose. While pose estimation can also be applied to various objects, there is a particular interest in human pose estimation due to its wide range of practical applications and societal impact.

In this article, we’ll take a look back at history and see how modern-day pose estimation algorithms have evolved from traditional computer vision methods to deep learning models. Let’s get started.
Why and Where Did Pose Estimation Research Begin?
Research on pose estimation began with the emergence of computer vision as a field in the late 1960s and early 1970s. Initially, researchers focused on foundational problems such as image understanding, object recognition, and shape analysis. As computer vision evolved, pose estimation emerged as a distinct research area.
Pose estimation captured the interest of researchers due to its wide range of applications across various domains. Accurate pose estimation enables object localization and tracking, and that, in turn, leads to many applications.
An example of pose tracking (the task of estimating poses in videos and assigning unique instance IDs for each key point across frames). Source
For instance, in human-computer interaction, pose estimation allows computers to interpret and respond to human gestures, enabling intuitive and natural interaction between humans and machines. It also finds application in sports and fitness, aiding in analyzing body movements and posture to improve performance and prevent injuries.
An example of pose estimation being used to animate a 3D model. Source
Moreover, pose estimation contributes to realistic animation and gaming experiences by capturing and replicating human poses. In the healthcare and rehabilitation realm, it assists in assessing movement disorders, tracking progress during therapy, and designing personalized treatment plans.
Pose Estimation Methods Over the Years
Now that we’ve gone over the importance and applications of pose estimation let’s dive right into the evolution of pose estimation methods.
Traditional Computer Vision Methods (1990s-2000s)
Traditional computer vision methods focused on geometric calculations and feature-based approaches to estimate the pose of objects or human subjects. Both of the algorithms discussed below are able to estimate the pose of objects in images based on first calculating the camera position and pose.
Direct Linear Transform (DLT) Algorithm
To use the DLT algorithm, you need to know some things beforehand. First, you need to know the 3D positions of a few points in the real world. For example, you could measure the coordinates of some objects or markers in the scene. Second, you need to know where those points appear in the 2D image taken by the camera. So, you mark those points on the image.
Now, the DLT algorithm takes these known 3D-2D correspondences and uses them to estimate the camera's pose. It does this by solving a set of mathematical equations that relate the 3D world points to their corresponding 2D image points. By solving these equations, the DLT algorithm can figure out the camera's position and orientation.
Once the camera's pose is estimated, you can use this information to understand where other objects or people are located in the scene.
Perspective-n-Point (PnP) Algorithm
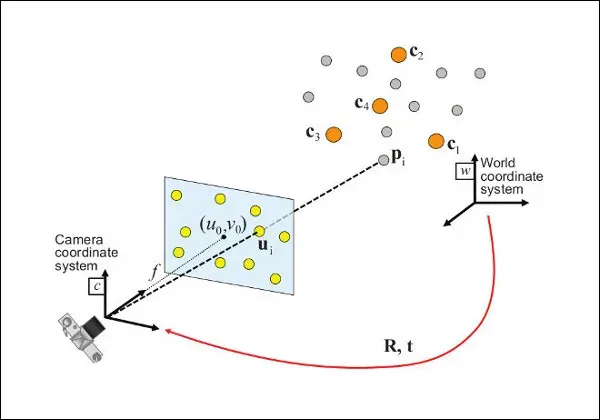
The PnP algorithm is quite similar to the DLT algorithm. The difference is that the PnP algorithm is specifically designed for estimating the camera pose using a minimal set of 2D-3D correspondences. It assumes that the camera's internal parameters, like the focal length, are known or can be estimated separately. The PnP algorithm aims to determine the camera's pose by solving a nonlinear optimization problem that finds the best match between the 3D points and their corresponding 2D projections.
Model-based Approaches (2000s-2010s)
While traditional computer vision methods provided valuable insights and paved the way for subsequent advancements, they had limitations. They were often sensitive to noise, outliers, occlusions, and they relied heavily on known camera parameters. As a result, model-based approaches started to gain traction. Model-based approaches utilize predefined models of objects or body parts to estimate their poses.
Iterative Closest Point (ICP) Algorithm
Imagine you have two sets of points: one set represents the 3D coordinates of an object or a scene, and the other set represents the 3D coordinates of the same object or scene from a different perspective. The ICP algorithm helps you align these two sets of points to estimate the pose, which includes the position and orientation of the object or scene. Other than pose estimation, this algorithm is also commonly used for registration and mapping.
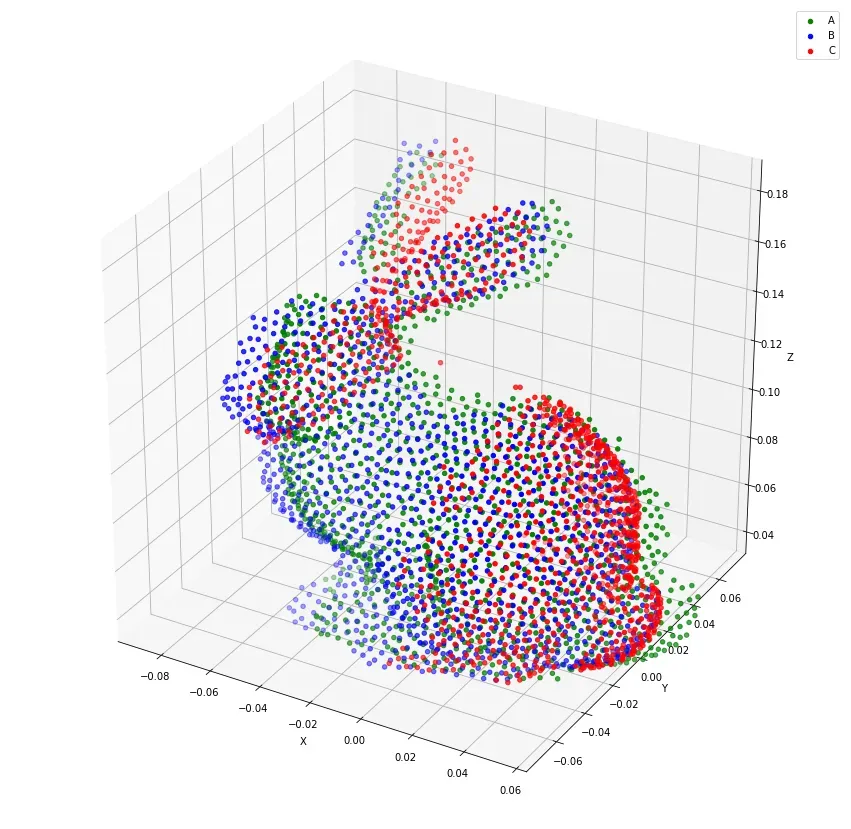
The ICP algorithm is particularly useful when aligning 3D point clouds, such as those obtained from laser scanners or depth sensors. It can be employed in various applications, including robotics, 3D reconstruction, and augmented reality, to estimate the pose of objects or align multiple scans to create a complete 3D model.
Active Shape Models (ASM)

ASM is a statistical model that combines shape and appearance information to estimate the pose or shape of an object in an image. To estimate the pose, the ASM algorithm starts with an initial guess of the object's shape in the image. It then adjusts the shape to find the best match between the model and the object in the image. During this adjustment process, the algorithm considers both the statistical shape model and the information from the image. It iteratively modifies the shape by analyzing the image's features.
Feature-based Methods (2010s)
Feature-based methods focused on identifying and matching distinctive image features to estimate the pose of objects or human subjects. They leveraged advanced feature descriptors and matching techniques to achieve accurate and robust pose estimation.
Speeded Up Robust Features (SURF)
SURF is a feature extraction algorithm commonly used in computer vision tasks, including pose estimation. While SURF itself is not specifically designed for pose estimation, it can be utilized as part of a pose estimation pipeline for feature detection and matching.
While SURF can contribute to the feature detection and matching stage of a pose estimation pipeline, it is often combined with other techniques, such as geometric models, optimization algorithms, or machine learning approaches, to estimate the precise pose of an object or person.
Scale-Invariant Feature Transform (SIFT)

SIFT is similar in its nature to SURF but has some key differences. SIFT detects key points based on scale-space extrema and provides robustness to scale and rotation changes. SURF uses a blob-like structure and approximates scale and rotation invariance using Haar wavelet responses.
SIFT is more computationally intensive but offers greater robustness, while SURF is faster but slightly less robust. Both algorithms calculate descriptors to describe key points and use different matching approaches. The choice between SIFT and SURF depends on the specific application's requirements and the trade-off between accuracy and efficiency.
Deep Learning-based Methods (2010s-present)
Deep learning methods leverage the power of deep neural networks to directly learn the mapping between image data and pose estimation, enabling highly accurate and robust results. Deep learning-based pose estimation methods have had a transformative impact, providing state-of-the-art performance in various domains. They continue to be an active area of research, pushing the boundaries of what is possible in pose estimation.
DeepPose
DeepPose was one of the pioneering deep learning-based pose estimation methods. It introduced the use of convolutional neural networks (CNNs) to directly regress the joint positions of human subjects from input images.
It's worth noting that DeepPose was an influential model at the time of its introduction. DeepPose paved the way for subsequent research on deep learning-based pose estimation, leading to the development of more advanced and accurate models.
OpenPose
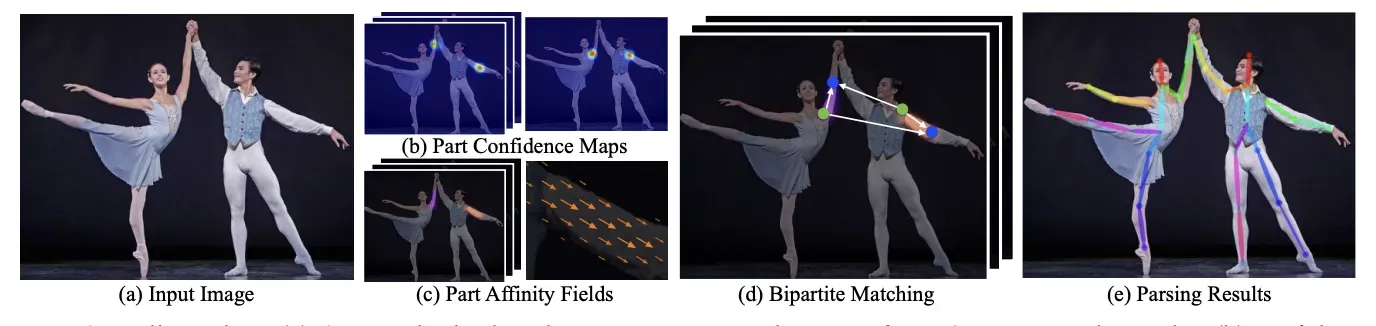
OpenPose introduced a multi-person pose estimation framework that simultaneously detects and localizes human body key points in images or videos. It employs a multi-stage CNN architecture to estimate human poses from images or videos.
The framework simultaneously predicts heatmaps, which indicate the likelihood of joint presence, and Part Affinity Fields (PAFs), which encode the connections between body parts. With its accuracy, real-time capabilities, and open-source nature, OpenPose has become a popular tool and benchmark in the field of pose estimation, driving further research and advancements.
Latest Models
YOLOv7 Pose
YOLOv7 Pose is a single-stage multi-person keypoint detector. It identifies the key points of all the persons in an image at once, then proceeds to group them into individual persons. A heat map-free approach is used to do this. The model is trained on the COCO datasete and implemented in PyTorch. YOLOv7 Pose offers a modular architecture, allowing users to customize and optimize the model according to their specific requirements.
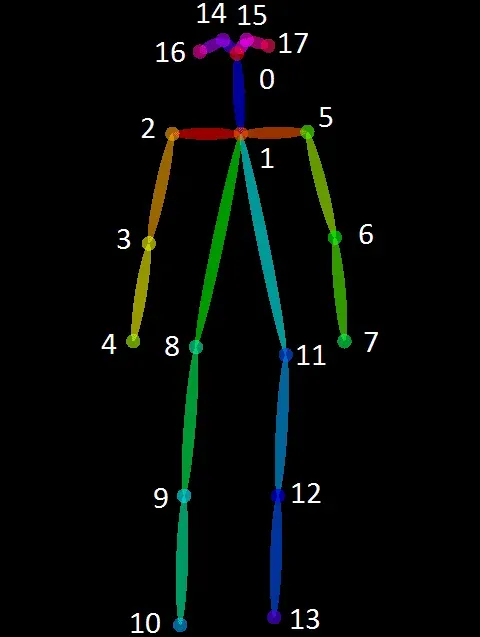
The model has demonstrated impressive performance on benchmarks like COCO and MPII, indicating its effectiveness in object detection and pose estimation tasks. While it provides the flexibility to handle various use cases, it may face challenges in estimating poses for complex scenarios or specific poses.
YOLOv8 Pose
YOLOv8 represents the latest advancement in the YOLO series, incorporating state-of-the-art techniques and advancements to deliver superior performance, flexibility, and efficiency. YOLOv8 supports a wide range of vision AI tasks, including pose estimation. See our guide on training a YOLOv8 pose estimation model using custom data.
The YOLOv8 Pose model is pretrained on the COCO dataset, and there are six different pretrained versions of the model available to download.
Try It Yourself
You can try the YOLOv8 Pose model on a picture of yourself in less than 5 minutes. All you need to do is install the package using pip and run the following piece of code:
from ultralytics import yOLO
import cv2
# Load a model
model = YOLO("yolov8n-pose.pt")
source = "path/to/image.jpg"
results = model(source)
plotted_results = results[0].plot()
# save a image with the plotted results
cv2.imwrite("result.jpg", plotted_results)
MediaPipe Pose
MediaPipe Pose is a framework specifically designed for single-person pose estimation. It uses a series of models. The first model detects the presence of human bodies within an image frame, and the second model locates key points on the bodies. The framework operates in two stages, namely detection and tracking. The detection stage is not performed on every frame, allowing the framework to perform inference more rapidly and efficiently.
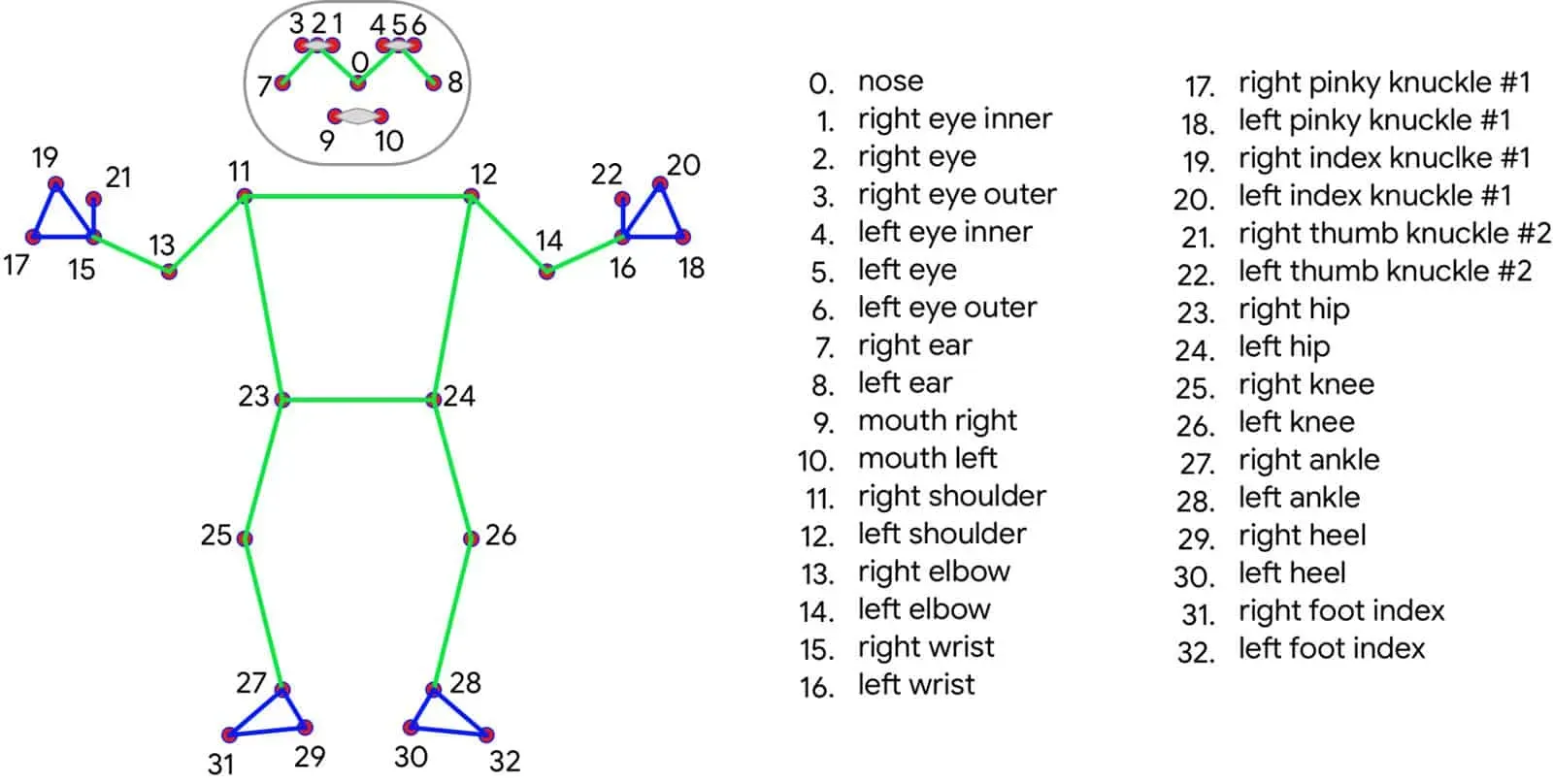
The model accurately tracks and identifies 33 landmark locations on the body. This topology includes the COCO keypoints, Blaze Palm, and Blaze Face topology, making it a comprehensive representation.
Popular Pose Estimation Datasets
Popular pose estimation datasets that are widely used for training and evaluating pose estimation models include COCO, MPII Human Pose, and Human3.6M. These datasets provide standardized evaluation metrics and ground truth annotations, enabling researchers and developers to train and validate pose estimation algorithms for improved accuracy and robustness.
How To Get Started
Here’s some great tutorials to help you get started with pose estimation:
- Deep Learning based Human Pose Estimation using OpenCV
- Deep Learning based Human Pose Estimation using OpenCV and MediaPipe
Conclusion
Pose estimation has evolved significantly over the years, driven by advancements in computer vision and machine learning. From early approaches that relied on hand-crafted features and graphical models, the field has transitioned to deep learning-based methods that leverage convolutional neural networks (CNNs) and large-scale datasets. This shift has brought remarkable improvements in accuracy and robustness.
Ongoing research continues to push the boundaries of pose estimation, aiming to address challenges such as occlusions, complex poses, and real-time performance in diverse scenarios.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Jul 19, 2023). Pose Estimation Algorithms: History and Evolution. Roboflow Blog: https://blog.roboflow.com/pose-estimation-algorithms-history/