
Claude Opus 4.7 ships with a higher-resolution image encoder (up to 2,576 pixels on the long edge, more than 3x prior Claude models), meaningful benchmark gains on MMMU, DocVQA, and ChartQA, and a new tokenizer. For computer vision teams, the practical wins concentrate in text-dense, high-resolution imagery: invoices, shipping labels, schematics, and scanned forms where a vision-language model needs to reason about content, not just classify regions. Inside Roboflow Workflows, Opus 4.7 fits as an auto-labeling step to bootstrap datasets or a quality-control reviewer over the output of a faster downstream model like RF-DETR.
Released on April 16, 2026, Claude Opus 4.7 is Anthropic's most capable model to date and a notable step forward for multimodal vision tasks. Opus 4.7 ships with a higher-resolution image encoder, large gains on text-dense document and chart benchmarks, and a new tokenizer - alongside meaningful improvements to coding and agentic workflows.
While most of the launch coverage has focused on Opus 4.7's coding gains, the upgrade for computer vision practitioners is just as significant. The model now accepts images up to 2,576 pixels on the long edge, roughly 3.75 megapixels, more than 3x the resolution prior Claude models supported, and posts large jumps on MMMU, MathVista, DocVQA, and ChartQA.
In this guide, we'll walk through what's new in Claude Opus 4.7, look at the vision benchmark improvements, and show you how to use Opus 4.7 inside a Roboflow Workflow to caption images, parse documents, and bootstrap labels for downstream models.
Just looking for links? Explore the most important Claude Opus 4.7 links here:
Without further ado, let's get started.
What Is Claude Opus 4.7?
Claude Opus 4.7 is the latest Opus-tier model in Anthropic's Claude family and the successor to Claude Opus 4.6. It's a general-purpose multimodal foundation model that accepts text and images as input and produces text as output.
Unlike a specialized vision model like SAM 3 or RF-DETR, Opus 4.7 doesn't return bounding boxes or segmentation masks directly. Instead, it reads images the way a human reader would: it can describe what it sees, transcribe text, read charts, interpret diagrams, and answer questions grounded in visual content. That makes it a different kind of tool than a detector, but a complementary one.
For computer vision teams, Opus 4.7 is most useful as a vision-language step inside an agentic pipeline, a document and chart parser, an auto-labeling tool to bootstrap datasets, or a quality-control reviewer over the output of a smaller, faster downstream model.
What's New in Claude Opus 4.7's Vision
Three changes matter most for vision workloads.
- Higher-resolution input. Opus 4.7 accepts images up to 2,576 pixels on the long edge - about 3.75 megapixels, more than 3x the resolution Claude previously supported. For text-dense images like shipping labels, schematics, scanned forms, and dashboards, that means small text and fine detail survive the encoder instead of getting downsampled into mush.
- A new tokenizer. Anthropic shipped a new tokenizer with Opus 4.7 that more efficiently encodes image patches and structured text. In practice, that means fewer tokens spent on the same input.
- Stronger visual reasoning. Across the standard multimodal benchmarks, Opus 4.7 is a meaningful step up from 4.6, with the largest gains on tasks closest to real-world computer vision work.
Claude Opus 4.7 Vision Benchmarks
According to Roboflow's Vision Evals, Claude Opus 4.7 demonstrates strong foundational visual capabilities, ranking 9th out of 63 models with an overall score of 73.13%.
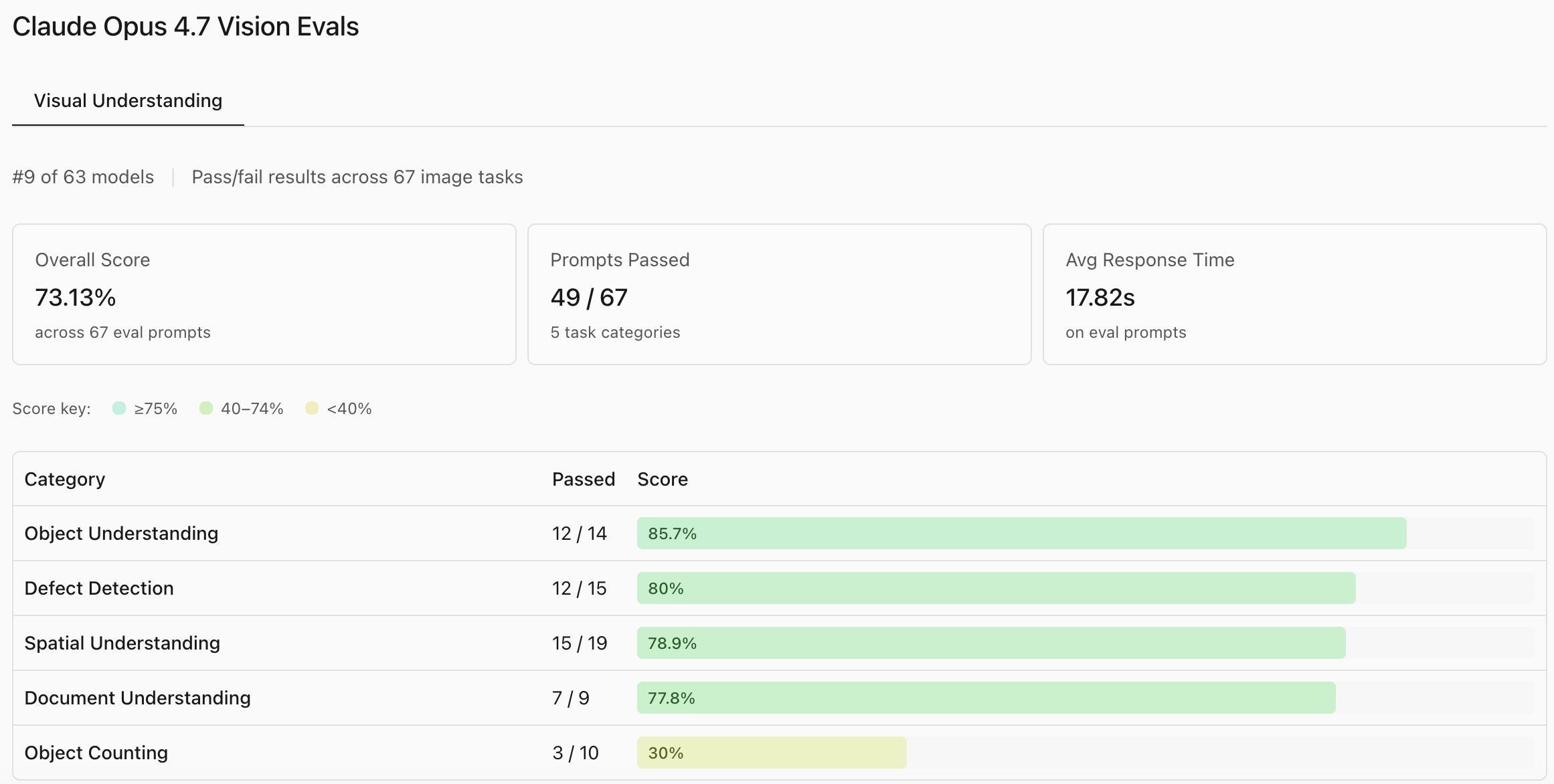
It performs exceptionally well in qualitative tasks like Object Understanding (85.7%) and Defect Detection (80%), making it a highly capable candidate for visual inspection and classification workflows.
However, the results highlight a significant blind spot in Object Counting, where it passed only 30% of the prompts. Coupled with a relatively slow average response time of 17.82 seconds, the data suggests that while Opus 4.7 is excellent for deep, asynchronous image analysis, it is not optimized for real-time edge deployments or tasks requiring precise, dense quantification.
Use Claude Opus 4.7 to Label Data for a Smaller Model
Like SAM 3, Claude Opus 4.7 is a server-scale model. You're not going to run it on the edge, and you probably don't want to call a frontier VLM on every frame in a 30 fps video stream - even at Opus 4.7's pricing, the unit economics get expensive fast. Learn more about how to calculate costs when using frontier models for vision tasks.
What Opus 4.7 is excellent at is labeling. The higher input resolution and stronger document understanding make it a good fit for auto-labeling tasks where small text and fine detail used to trip up smaller VLMs. You can use Opus 4.7 to generate captions, bounding box hints, or class labels on a small batch of images, refine the labels in the Roboflow annotation interface, and then train a smaller, supervised model, such as RF-DETR, for production deployment.
The result is a pipeline that combines Opus 4.7's visual generality at training time with a fast, cheap, specialized model at inference time.
How to Use Claude Opus 4.7 in Roboflow Workflows
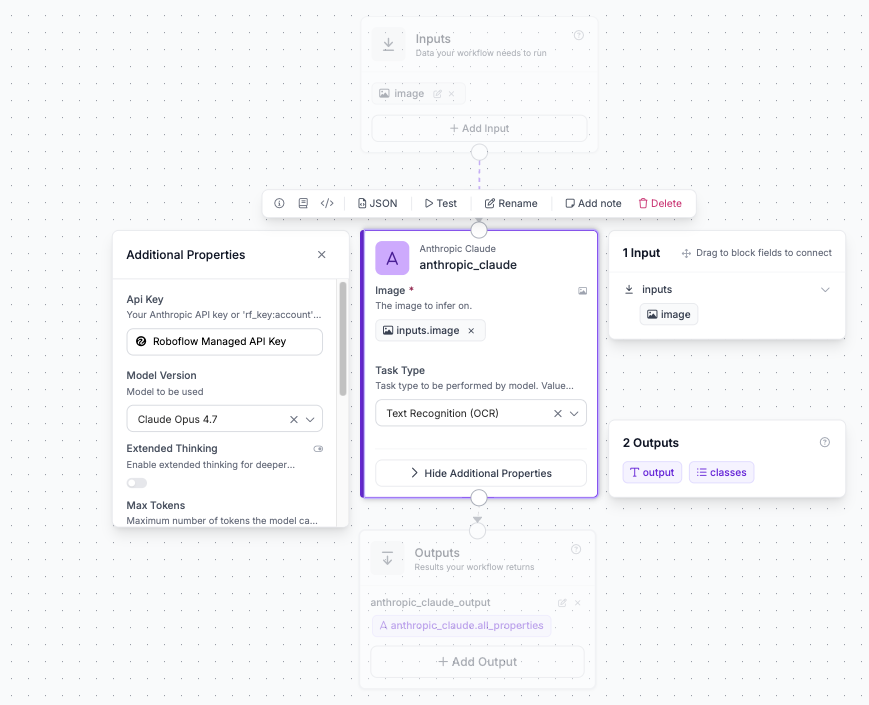
You can use Claude Opus 4.7 inside Roboflow Workflows by using the Anthropic Claude block and selecting the Opus 4.7 under Model Version.
Claude Opus 4.7 Pricing and Availability
Opus 4.7 is generally available as of April 16, 2026, at the same pricing as Opus 4.6:
- $5 per million input tokens
- $25 per million output tokens
Get Started With Claude Opus 4.7
Claude Opus 4.7 is the strongest general-purpose vision-language model Anthropic has shipped, with the biggest practical wins concentrated in document and chart understanding. For computer vision teams, the value is clearest when you're working with text-dense, high-resolution imagery - invoices, shipping labels, schematics, dashboards, scanned forms - and when you want a single VLM that can reason about visuals, not just classify or segment them.
To get started with Claude Opus 4.7, try it today in Roboflow playground.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (May 6, 2026). Claude Opus 4.7: Vision Benchmarks & Use Cases. Roboflow Blog: https://blog.roboflow.com/claude-opus-4-7/