
Introduction to Contrastive Learning
Contrastive learning, a powerful technique in machine learning, has gained widespread attention in recent years, addressing the challenge of learning effective representations from data. This approach, which focuses on learning by comparing data points, is essential for improving model performance across various tasks, even when labeled data is scarce.
By encouraging models to recognize similarities between related examples and distinguish unrelated ones, contrastive learning enables the extraction of meaningful features from complex datasets. This technique plays a key role in applications such as image recognition, natural language understanding, and recommendation systems, where learning robust representations is crucial.
In this blog post, we will explore the fundamentals of contrastive learning, delve into its core methods, and discuss how it is transforming modern machine learning practices.
What is Contrastive Learning?
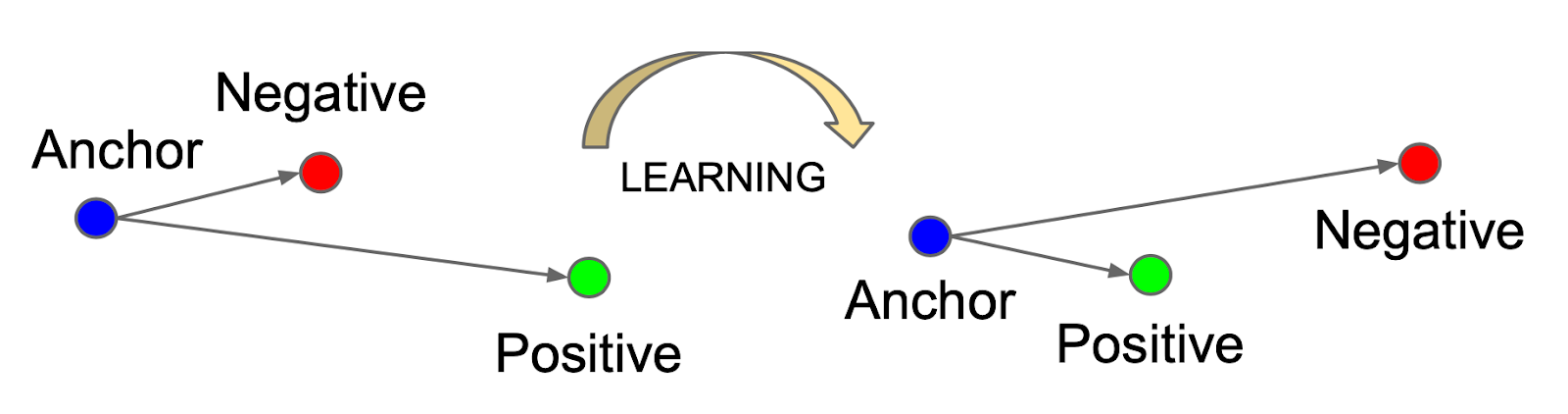
Contrastive learning is an approach aimed at learning meaningful representations by contrasting pairs of data points that are either similar (positive pairs) or dissimilar (negative pairs).
The main idea is to ensure that similar instances are closer together in the learned representation space, while dissimilar instances are pushed farther apart. By framing the learning process as a task of distinguishing between positive and negative pairs, contrastive learning enables models to effectively capture the relevant features and relationships within the data.
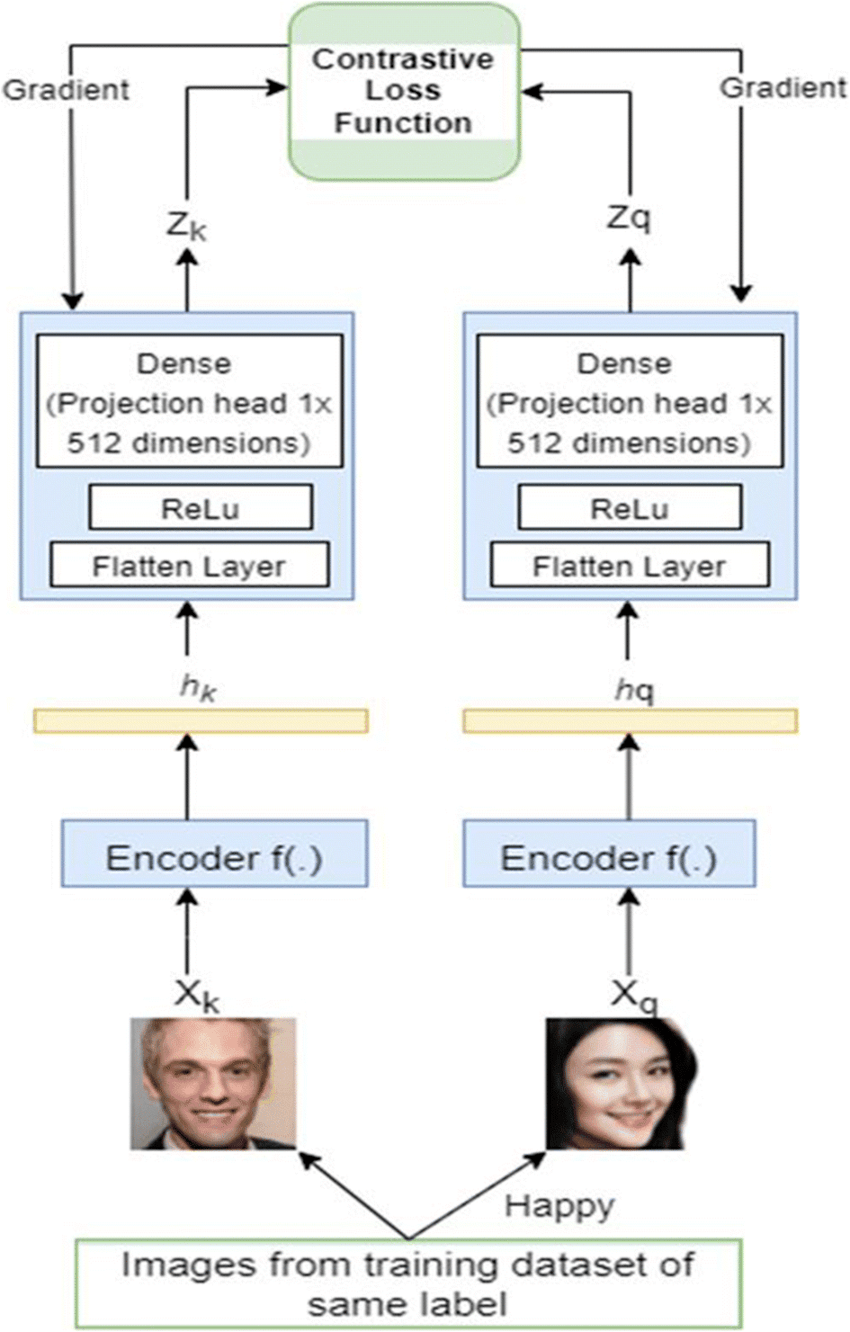
Supervised Contrastive Learning (SCL)
Supervised contrastive learning (SCL) uses labeled data to explicitly train models to differentiate between similar and dissimilar instances. In SCL, each pair of data points is accompanied by labels indicating whether they are similar or not.
The model is then trained to organize the learned representation space so that similar instances are grouped, while dissimilar ones are pushed apart. By optimizing this objective, SCL helps the model distinguish between similar and dissimilar instances, leading to improved performance in various tasks. CLIP (Contrastive Language-Image Pre-Processing) is a popular contrastive learning model.
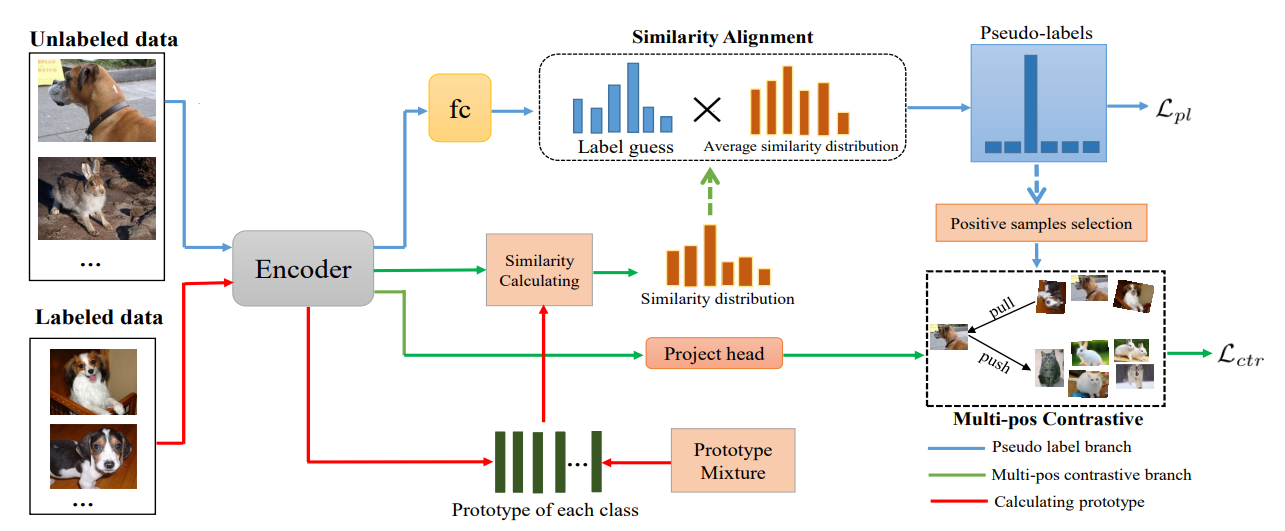
Self-Supervised Contrastive Learning (SSCL)
Self-supervised contrastive learning (SSCL) takes a different route by learning from unlabeled data, relying on pretext tasks to create positive and negative pairs. In SSCL, the goal is to develop representations without using explicit labels. Pretext tasks are carefully designed to generate positive pairs by creating different augmented versions of the same data instance and treating them as similar, while other instances are treated as dissimilar. By training the model to distinguish between these pairs, it learns to capture higher-level semantic features that generalize well to downstream tasks.
SSCL has achieved impressive results in multiple domains. In computer vision, it has been applied successfully to tasks such as image classification, object detection, and image generation. Similarly, in natural language processing, SSCL has shown great promise in tasks like sentence representation learning, text classification, and machine translation.
How Does Contrastive Learning Work?
Contrastive learning has emerged as a highly effective technique, enabling models to utilize large volumes of unlabeled data while enhancing performance, even when labeled data is scarce. The core concept of contrastive learning is to bring similar instances closer in the learned embedding space while separating dissimilar ones. By treating learning as a task of distinguishing between instances, contrastive learning helps models capture key features and similarities in the data.
Now, let's explore the key steps of the contrastive learning process to gain a deeper understanding of how it functions.
Data Augmentation
A key step in contrastive learning is data augmentation, where various transformations or alterations are applied to unlabeled data to create different versions or views of the same instance.
The goal of data augmentation is to increase the diversity of the data and expose the model to multiple perspectives of a single instance. Common techniques used in this process include cropping, flipping, rotation, random cropping, and color adjustments. By generating these varied instances, contrastive learning helps the model focus on capturing important features while remaining robust to changes in the input data.

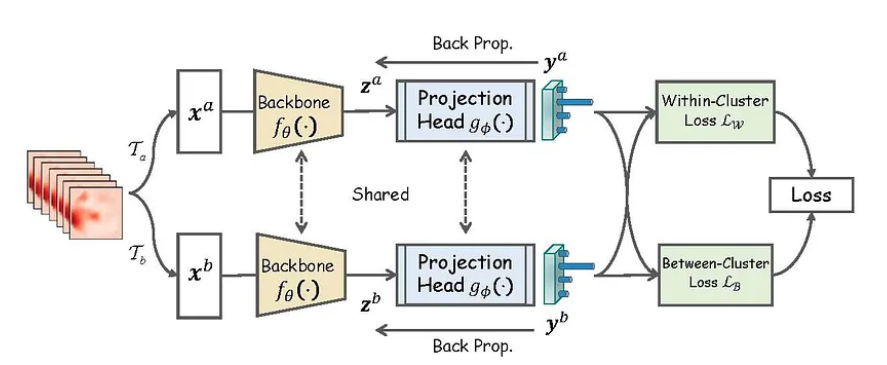
Encoder and Projection Networks
In contrastive learning, two key components - an encoder network and a projection network - work together to learn meaningful representations from the data.
The process begins with training an encoder network, which takes the augmented data instances as input and maps them into a latent representation space. This network, often a deep neural architecture such as a convolutional neural network (CNN) for image data or a recurrent neural network (RNN) for sequential data, extracts high-level features and captures important similarities between instances. By encoding these augmented inputs, the network aids in the subsequent task of distinguishing between similar and dissimilar data points.
Once the encoder network has generated these representations, a projection network is used to further refine them. This network takes the encoder's output and maps it into a lower-dimensional space, known as the projection or embedding space.
This additional projection step enhances the discriminative power of the learned representations by reducing data complexity and redundancy, allowing for a clearer separation between similar and dissimilar instances. Together, the encoder and projection networks play a crucial role in contrastive learning by enabling models to generate more effective and robust representations.
Contrastive Learning Objective
After the augmented instances are encoded and projected into the embedding space, the core contrastive learning objective is applied. The goal is to maximize the similarity between positive pairs (instances derived from the same sample) while minimizing the similarity between negative pairs (instances from different samples).
This objective encourages the model to draw similar instances closer together in the embedding space and push dissimilar ones farther apart. The similarity between instances is typically measured using distance metrics like Euclidean distance or cosine similarity. Through training, the model minimizes the distance between positive pairs and maximizes the distance between negative pairs, resulting in more effective and discriminative representations.
Loss Function and Training Optimization
Contrastive learning employs various loss functions to define the objectives of the learning process, playing a critical role in guiding the model to capture meaningful representations and distinguish between similar and dissimilar instances.
The choice of an appropriate loss function is determined by the specific requirements of the task and the characteristics of the data. Each loss function is designed to facilitate the learning of representations that effectively highlight significant similarities and differences within the dataset. We will explore these loss functions in more detail in a later section.
Once the loss function is established, the model is trained using a large unlabeled dataset. This training process involves iteratively updating the model's parameters to minimize the defined loss function. Common optimization algorithms, such as SGD, ADAM and its variants, are used to fine-tune the model's hyperparameters. The training typically consists of batch-wise updates, where a subset of augmented instances is processed together.
Throughout this training, the model learns to capture relevant features and similarities in the data. This iterative optimization gradually refines the learned representations, enhancing the model's ability to discriminate and separate similar and dissimilar instances effectively.
Loss Functions in Contrastive Learning
In contrastive learning, the choice of loss function is crucial. Different loss functions are utilized to establish the objectives of the learning process, directing the model to capture meaningful representations and distinguish between similar and dissimilar instances.
By examining the various loss functions used in contrastive learning, we can better understand how they influence the learning process and improve the model's capacity to identify relevant features and similarities in the data.
Let's explore the most commonly used loss in contrastive learning.
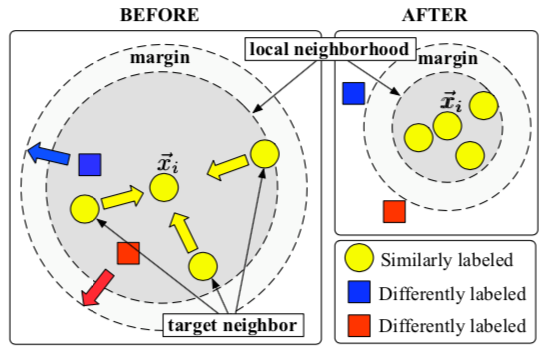
Contrastive Loss
Contrastive loss is a key loss function used in contrastive learning. Its primary objective is to maximize the similarity between positive pairs (instances from the same sample) while minimizing the similarity between negative pairs (instances from different samples) in the learned embedding space.
This encourages similar instances to be drawn closer together and dissimilar instances to be pushed farther apart. The contrastive loss function is usually defined as a margin-based loss, with instance similarity measured using a distance metric such as Euclidean distance or cosine similarity. It penalizes positive samples for being too far apart and negative samples for being too close in the embedding space.
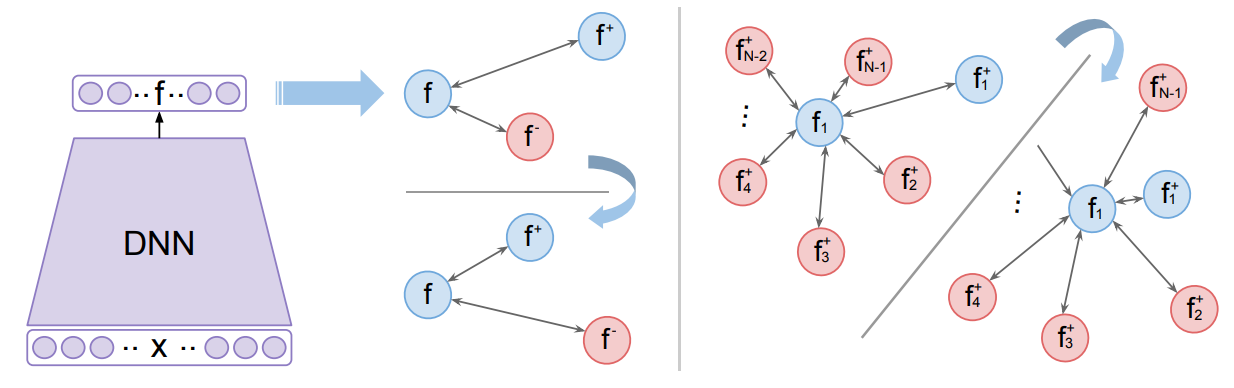
Triplet Loss
Triplet loss is another widely used loss function in contrastive learning, designed to maintain the relative distances between instances in the learned representation space. It works by creating triplets consisting of an anchor instance, a positive sample (similar to the anchor), and a negative sample (dissimilar to the anchor). The goal is to ensure that the distance between the anchor and the positive sample is less than the distance between the anchor and the negative sample by a certain margin.
The idea behind triplet loss is to enforce a "triplet constraint," where the anchor is drawn closer to the positive instance while being pushed away from the negative one. This encourages the model to learn representations that effectively distinguish between similar and dissimilar instances.
Triplet loss is commonly used in computer vision tasks like face recognition and image retrieval, where fine-grained similarities need to be captured. However, it can be sensitive to the selection of triplets, as finding informative and challenging triplets from large datasets can be computationally intensive.
N-Pair Loss
N-pair loss is an extension of triplet loss that incorporates multiple positive and negative samples for a given anchor instance. Instead of comparing the anchor to just one positive and one negative sample, N-pair loss seeks to maximize the similarity between the anchor and all positive instances while minimizing the similarity between the anchor and all negative instances.
This approach helps the model capture more nuanced relationships among multiple instances, offering more comprehensive supervision during training. By considering several instances at once, N-pair loss is better equipped to identify complex patterns and enhance the discriminative power of the learned representations.
N-pair loss has been effectively applied in tasks like fine-grained image recognition, where it's important to capture subtle differences between similar instances. It addresses some of the limitations of triplet loss by utilizing multiple positive and negative examples, though it can still be computationally intensive when working with large datasets.
Contrastive Learning Use Cases
Contrastive learning has gained significant traction in various real-world applications, particularly in domains where distinguishing between similar and dissimilar instances is essential.
Face Verification and Identification
Contrastive learning is widely used in face verification and identification systems. In these tasks, the goal is to verify whether two face images belong to the same person (verification) or identify a face from a database of known faces (identification).
By training models to minimize the distance between images of the same person and maximize the distance between images of different people, contrastive learning helps create discriminative face embeddings. These embeddings are robust to variations in lighting, pose, and expression, which is crucial for reliable face recognition systems, such as those used in security or authentication applications.
Image Retrieval and Similarity Search
Another common use case is image retrieval, where the task is to find visually similar images given a query image. Contrastive learning helps create embeddings that capture the visual features of images, allowing for efficient similarity searches.
For example, if a user provides a picture of a specific product, the system can retrieve similar products from a catalog or database by comparing the embeddings of the query image with those in the database. This technique is valuable in e-commerce, visual search engines, and content recommendation systems.
Self-Supervised Learning for Unlabeled Data
In scenarios where labeled data is scarce, contrastive learning enables self-supervised learning, where the model can learn useful representations from unlabeled data.
This is particularly useful in fields like computer vision and natural language processing, where manually labeling data is costly and time-consuming. By creating positive and negative pairs through data augmentation, contrastive learning allows models to learn without explicit supervision, making it highly valuable for pretraining models on large, unlabeled datasets.
Text Representation Learning
In natural language processing (NLP), contrastive learning can be used to learn meaningful text embeddings. For example, given two sentences, the model can be trained to determine whether they convey the same meaning or are contextually similar. This has applications in tasks like sentence similarity, text classification, and semantic search, where capturing the nuances of language is essential for effective performance.
Conclusion
Contrastive learning has proven to be effective at tackling challenges related to high-dimensional data and limited labeled examples. By focusing on the relationships between instances, it enables models to learn rich, discriminative representations.
Its versatility has led to successful applications in various domains, including face verification, image retrieval, self-supervised learning, and medical image analysis. As research progresses, contrastive learning will likely continue to evolve, providing robust solutions for complex tasks in a data-driven world. By exploiting its principles, practitioners can enhance model performance and broaden applicability across multiple fields.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Oct 7, 2024). What is Contrastive Learning? A guide.. Roboflow Blog: https://blog.roboflow.com/contrastive-learning-machine-learning/