
Data scientist Alaa Senjab built a real-time gun detection model for security camera footage using a 2,973-image handgun dataset from the University of Grenada, and reported that Roboflow cut roughly half of his project code by handling annotation validation, preprocessing, augmentation, and format conversion automatically. Roboflow flagged error-prone labels including out-of-frame bounding boxes and cartoon images that degraded model performance, and automated generation of TFRecords and TensorFlow Object Detection CSV files made it straightforward to run head-to-head comparisons between MobileNetSSDv2 and YOLOv3 without maintaining separate preprocessing pipelines for each architecture.
By using Roboflow, data scientist Alaa Senjab reduced his time to train a custom object detection model detecting guns in security camera footage while increasing machine learning model accuracy.

Highlights:
- Validating image annotation quality, and automated correction of error-inducing improper labels
- Preprocessing and augmentation techniques improving model generalizability
- Automated generation of TFRecords and TensorFlow Object Detection CSV
- Ease of experimentation between various deep learning frameworks
“Using Roboflow eliminated half of my project’s code!”
Problem Overview
Alaa Senjab is a data scientist with a background in cybersecurity and speciality focus in computer vision. With his unique experience, Alaa sought to build a model that would identify the presence of a gun in security footage in real-time. Such a tool is valuable to assist the monitoring of security footage and the potential automated alert of authorities, if appropriate.
Dataset Validation
Alaa leveraged a dataset of 3000 handguns and bounding boxes, originally published by the University of Grenada. A de-duplicated version of 2973 images is available on Roboflow.
While having a freely available and labeled dataset is helpful, quality complications arise. Is the dataset representative of the problem to be solved? Can the labels be trusted? Are there problems with the images (e.g. duplicates)?
In using Roboflow's computer vision workflow tool to validate the quality of his images and labels, Alaa discovered error-prone labels reducing his model performance.
Image quality spot checks
Roboflow’s upload UI individually displays each image and its annotation(s), providing an easy interface for spot checking glaring errors. In Alaa’s case, this quickly exposed images that may not be opportune for his problem like cartoon images and hand drawn photos.
Improper annotations
As Roboflow processes individual images and annotations, automated bounding box quality checks are performed. Annotations are prone to error: they can be illogical (e.g. a negative width), completely out of frame, or partially out of frame.
In Alaa’s case, one image had a difficult to catch error: a bounding box was completely out of frame. In these cases, Roboflow drops the annotation to automatically fix the issue. (If the annotation is partially out of frame, Roboflow crops the edge of the bounding box to be in-line with the edge of the image.)
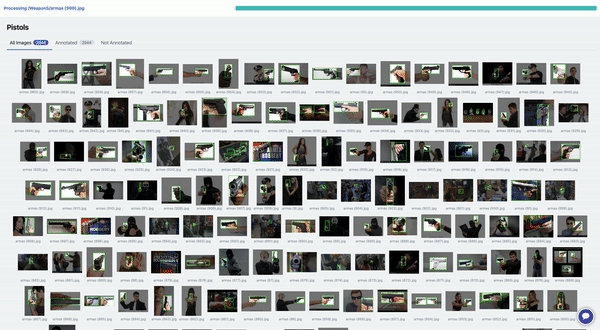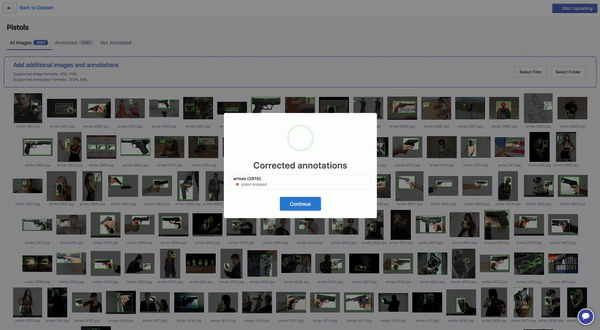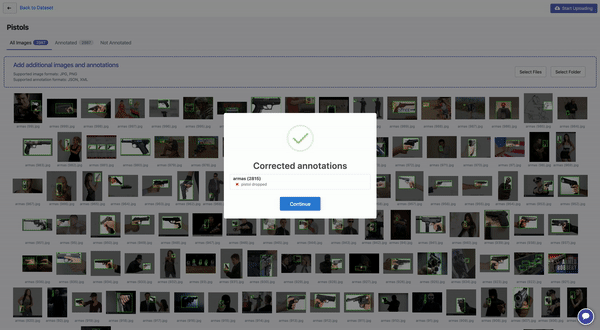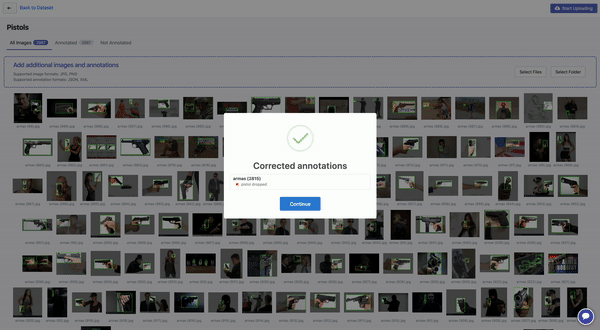
“Automatically dropping an out-of-frame annotation was key for me. Before Roboflow, I couldn’t figure out why my TFRecord generation failed on that image, and I was simply dropping that whole image from my dataset.”
Removing duplicate images
Another common problem, especially in large image datasets, is duplicate images. In Alaa’s case, Roboflow automatically removed 27 duplicates that would have otherwise skewed his model towards these examples and could have led to test set bleed.
Preprocessing and Augmentation
Image preprocessing and augmentation is critical to improving model performance. Some model architectures make it easy to pass preprocessing (e.g. image_resizer in TensorFlow) and augmentations (e.g. crop in FastAI) in model configuration files, but if one is experimenting between frameworks or with custom models, it requires re-writing each desired step before training. Moreover, performing augmentation at the time of training can make debugging difficult as reproducing which types of images a model performs well on is more opaque (does the model need more bright images? More higher contrast?).
Thus, creating a preprocessing pipeline separate from training simplifies training. Conducting augmentation in advance not only saves precious GPU compute for training but increases model reproducibility.
“Roboflow made it seamless to apply the same preprocessing and state-of-the-art augmentation options on my images so I could focus on model performance. Doing augmentations ahead of training also allowed me to take full advantage of GPU, decreasing my training time.”
Ease of Experimentation Between Model Frameworks
Alaa sought to experiment with multiple model architectures with an emphasis on inference speed given his problem required real-time processing of video feeds. He took particular interest in comparing the performance of MobileNetSSDv2 to YOLOv3.
The TensorFlow Object Detection API provides a ready-built implementation of MobileNet, but setting up a model requires meticulous file management, conversion of one annotation format to a TensorFlow Object Detection CSV, and using that CSV to create TFRecord files. Fortunately, Roboflow enables doing this in a matter of clicks. (We even have a tutorial of using Roboflow with the TensorFlow Object Detection API.)
Similarly, open source YOLOv3 implementations require their own annotation formats, and there are fewer ready-made implementations. (This also complicates keeping the same preprocessing and augmentation pipeline.)
“I was able to experiment with different architectures and create true head-to-head tests with ease.”
All-in-all, Roboflow eliminates the sprawling one-off util scripts data scientists are writing to preprocess, augment, and convert files — so they’re focusing on the important work assessing model performance.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Feb 12, 2020). Eliminating Boilerplate Code with Roboflow to Monitor Security Camera Footage. Roboflow Blog: https://blog.roboflow.com/eliminating-boilerplate-code-with-roboflow-to-monitor-security-footage/