
This tutorial walks through building a custom object detection model end to end, using the BCCD blood cell dataset as the worked example. You collect and label images, generate a dataset version, train a model in the cloud, evaluate it, and deploy it, all inside Roboflow.
If you came here to train a detector with the TensorFlow Object Detection API, training RF-DETR, Roboflow's real-time detection architecture, is the faster path to the same outcome, a custom model that runs in production. It fine-tunes quickly on a custom dataset, reaches high accuracy with only a few hundred images, and ships with commercial-safe licensing.
What is the TensorFlow Object Detection API?
The TensorFlow Object Detection API is a framework for training and running object detection models. It ships with a model zoo of architectures pre-trained on the COCO dataset, so you can fine-tune one of them on your own objects rather than train from scratch.
MobileNet SSD, and what to use today
MobileNet SSD v2 is the popular lightweight choice in this API. SSD (Single Shot Detector) predicts boxes in one pass for speed, and the MobileNet backbone is small enough to run on phones and embedded devices. That combination made it a default for on-device detection.
It comes with friction. The traditional TensorFlow workflow depends on a specific TensorFlow version, hand-generated TFRecords, and a notebook environment, a stack that is fragile and slow to fine-tune.
Transformer-based detectors like RF-DETR now match or beat the real-time speed of these convolutional detectors while delivering higher accuracy, train from a plain image-and-annotation export with no TFRecords, and avoid restrictive licensing.
That is why this tutorial trains RF-DETR. The workflow you learn is the same one production teams use no matter which architecture they pick.
How to think about the problem
Our worked example is medical imaging. The BCCD dataset is 364 microscope images of blood cells with 4,888 labels across three classes: red blood cells, white blood cells, and platelets. The task is to detect and count each cell type in a slide, which is a useful stand-in for any counting or inspection problem where the objects are small, crowded, and easy to confuse.

For your own problem, constrain the scope and decide the minimum acceptable performance up front. Counting tasks like this one care a lot about recall, since a missed platelet is a missed count, so it is worth deciding early how good is good enough. We come back to that in the evaluation step.
What you need
- A free Roboflow account.
- A set of images of whatever you want to detect. For the blood cell example, you can fork our public dataset and skip collection entirely.
- A web browser. That is all you need to label, train, and deploy.
- Optional: Python, if you want to call your trained model from your own code at the end.
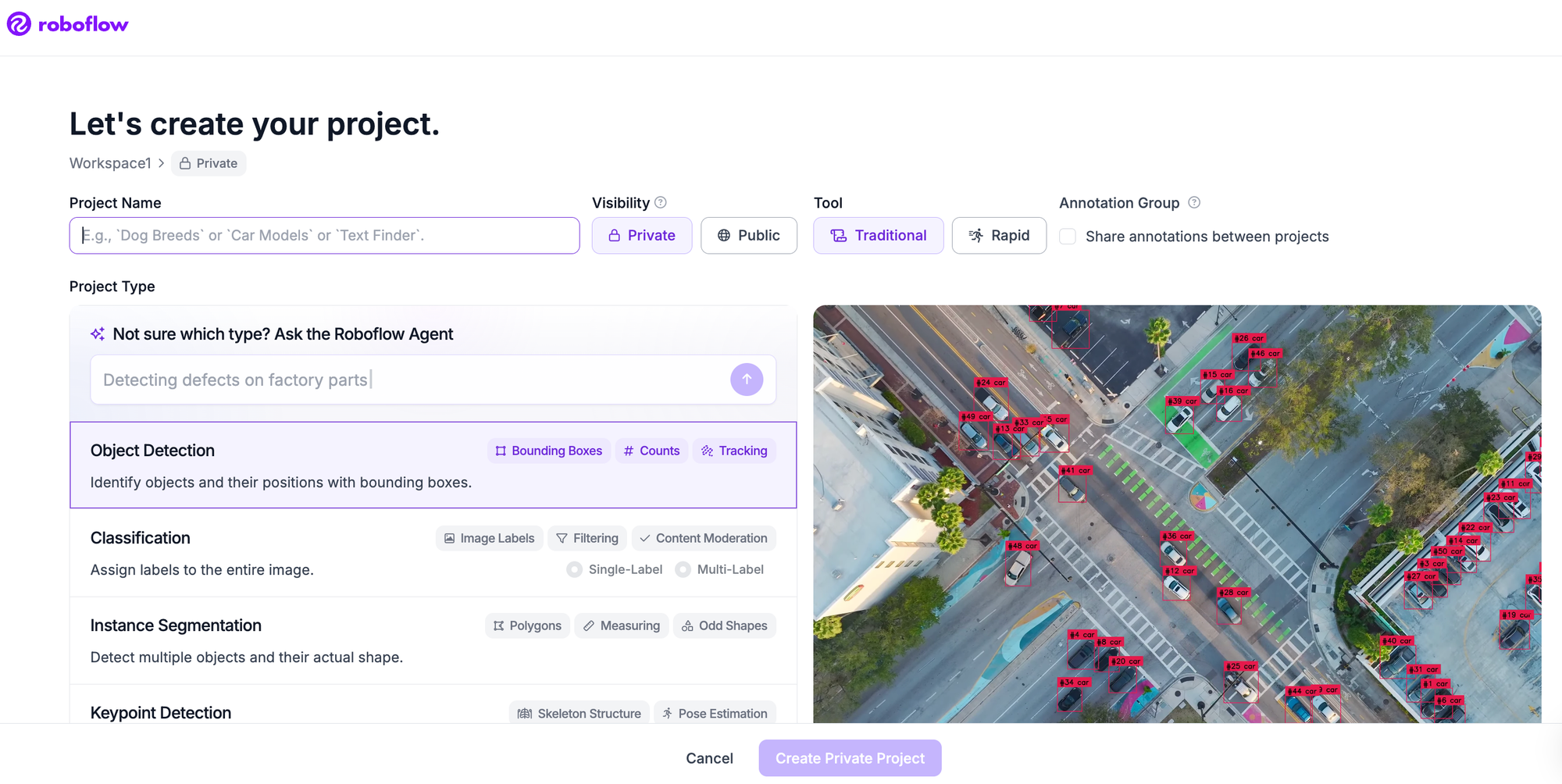
Step 1: Create a project
Sign in to Roboflow and create a new Project. Choose Object Detection as the project type, give it a name like blood-cell-detection, and set the annotation group to the thing you are labeling (for example, cell). You now have an empty project ready for images.
Step 2: Get your images
To follow along exactly, open the BCCD dataset on Roboflow Universe and fork it into your workspace. It is already labeled, so you can move straight to generating a version.
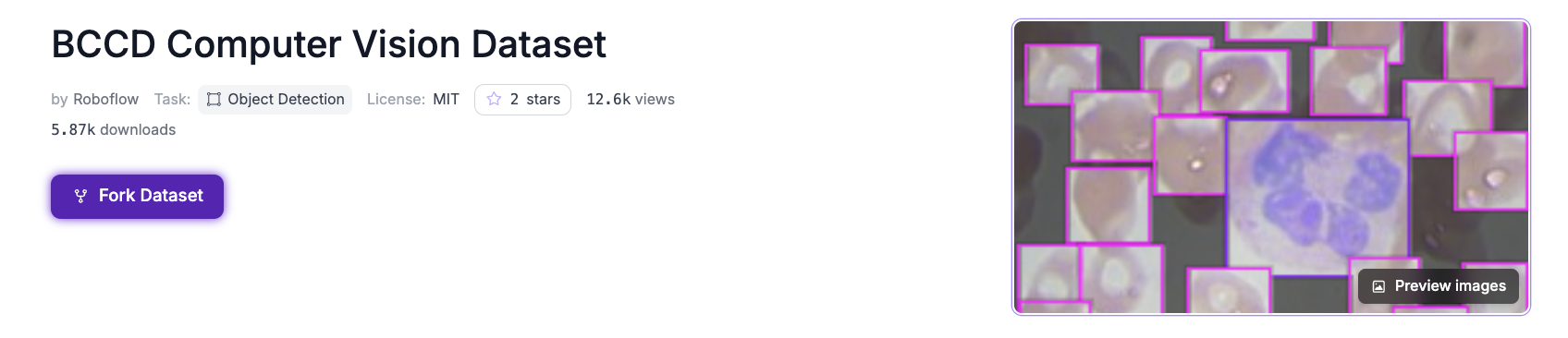
To use your own data, drag your images into the Upload tab. If you want a head start on a different problem, Roboflow Universe hosts more than 200,000 open datasets and pre-trained models you can build on. When you collect your own images, capture them in the conditions where the model will run: similar lighting, magnification, angle, and image quality. The closer your training images are to production, the better the model performs.
Step 3: Annotate your images
The blood cell dataset is pre-labeled, so you can skip ahead. For your own data, open the Annotate tab and draw boxes. Roboflow Annotate includes Auto Label and Label Assist, which use foundation models to draw the first set of boxes for you so your team only reviews and corrects them. On a dense dataset like blood cells, that can save hours.
A few labeling rules that matter:
- Draw boxes around the entire object, even if there is a little space between the object and the box. Do not clip it.
- When cells touch or overlap, label each one as if you could see it whole.
- Be consistent across the whole dataset. Inconsistent labels hurt accuracy more than almost anything else.
See our guide to labeling best practices for more. When you approve your first batch of annotations, Roboflow trains a Roboflow Instant Model in the background that you can use right away to auto label the rest of your images.
Step 4: Generate a dataset version
Once your images are labeled, go to the Versions tab and generate a dataset version. A version is a frozen snapshot of your data plus the preprocessing and augmentation you choose. Roboflow handles data formatting for you, so there are no TFRecord or label_map files to generate by hand.
Preprocessing to apply:
- Auto-Orient. This strips EXIF orientation data so images train in the orientation you see them. Leaving it off is a common cause of silent failures. Keep it on.
- Resize. Resize to a square so training is fast and consistent. The model handles the rest.
Augmentation to consider:
- Augmentation creates new training images by varying your existing ones, which expands a small dataset and reduces overfitting. With only 364 images, this matters. Useful options for microscopy include small rotations, brightness and exposure shifts, and flips, since a blood smear has no inherent up or down. Apply only the variations your model will realistically encounter.
Roboflow also splits your data into training, validation, and test sets for you, typically around 70/20/10, and keeps that split consistent across every export format. The training set is what the model learns from, the validation set tunes the model and watches for overfitting during training, and the test set is held out until the end to measure real performance. No image appears in more than one set.
Step 5: Train your model
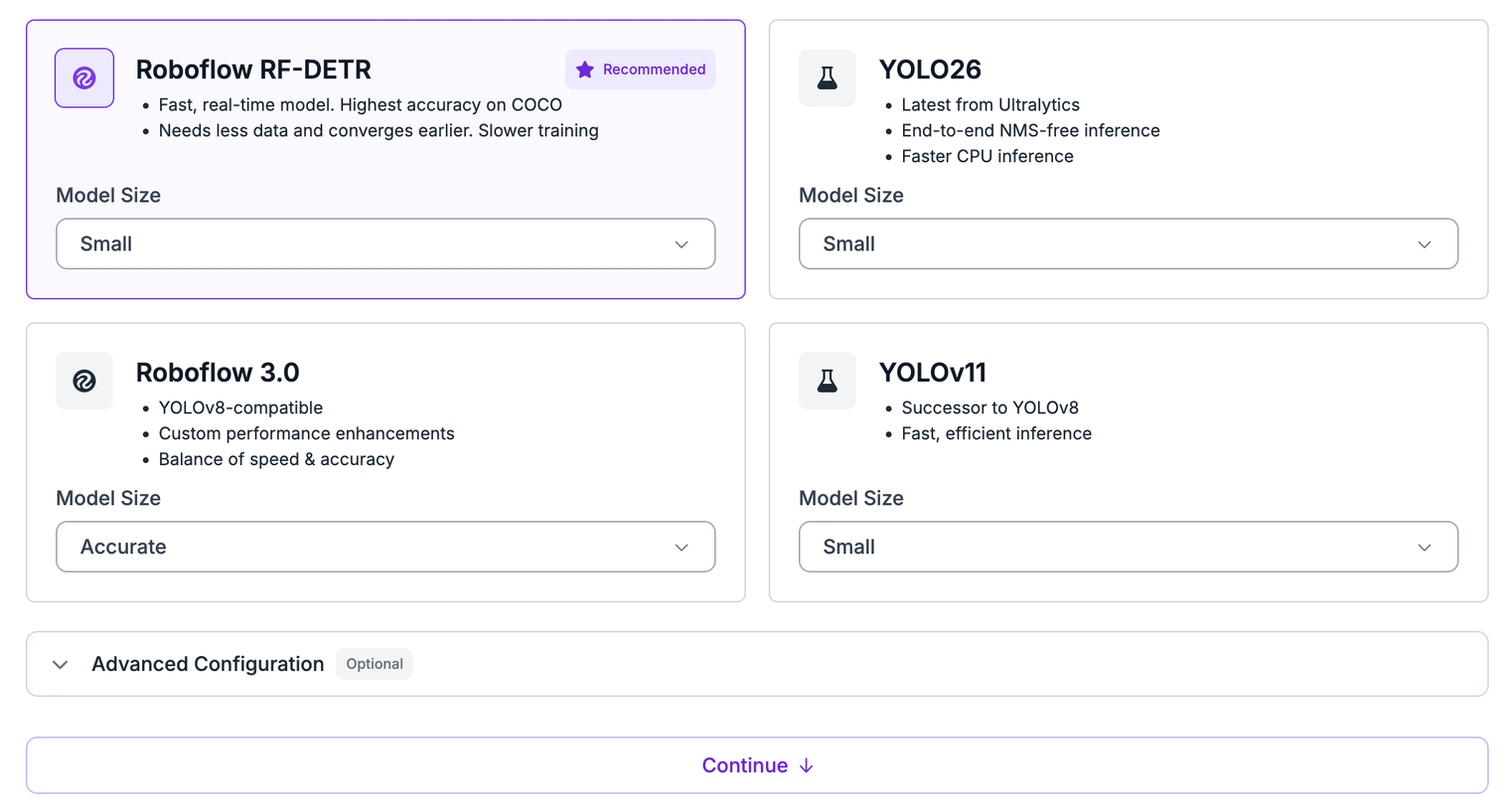
From the project, open Train and click Custom Training to configure the job.
- Select an architecture. For object detection, choose RF-DETR. It offers the best accuracy of the supported object detection models. RF-DETR comes in several sizes (Nano, Small, Medium, Base, and larger sizes on paid plans). Start with a smaller size for faster training and step up if you need more accuracy. If you would rather not choose, select Neural Architecture Search, which trains and evaluates several configurations and recommends the best one for your accuracy and latency needs (it requires at least 15 validation images).
- Select a checkpoint. For your first model, choose Train from Public Checkpoint, which starts from a model pre-trained on Microsoft COCO. This is transfer learning: instead of starting from scratch, you begin from a model that already understands general visual features, which trains faster and scores higher. Once you have a working model, you can train future versions from your previous checkpoint to improve it.
- Start training. Roboflow shows the estimated duration and credit cost before you commit, then trains your model in the cloud. You will get an email when it finishes, usually in under 24 hours. Training is priced by job length; see the credits page for details, and students and researchers can apply for additional credits.
There is no GPU to provision, no environment to install, and no notebook to keep open.
Step 6: Evaluate your model
When training finishes, Roboflow shows your results: mean average precision (mAP), precision, and recall, computed on the held-out test set. You do not write any evaluation code.
How to read the numbers:
- mAP (mean average precision) is the standard object detection metric. It summarizes how well predicted boxes match ground truth across all classes. Higher is better.
- IoU (intersection over union) measures the overlap between a predicted box and the true box. mAP is computed at one or more IoU thresholds, commonly 0.5.
- Precision tells you how many of the model's predictions were correct. Recall tells you how many of the real objects the model found. For a counting task like blood cells, recall is often the number to watch.
Use the per-class breakdown and confusion matrix to find weak spots. Platelets are small and easy to miss, so if that class scores low, the usual fix is more or better labeled examples of platelets, not a different model. Add images, re-label, generate a new version, and train again. This loop is the real work of building a good model, and Roboflow is built around it.
Step 7: Run inference
Your trained model is immediately available through the Roboflow Serverless Hosted API, so you can test it without deploying anything. Try it in the browser on the Deploy tab, or call it from Python.
Install the SDK:
pip install inference-sdk supervision
Run your model on an image and visualize the result:
import os
import cv2
import supervision as sv
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=os.getenv("ROBOFLOW_API_KEY"),
)
# Replace with your model ID, in the form "project-name/version"
result = client.infer("blood-smear.jpg", model_id="blood-cell-detection/1")
image = cv2.imread("blood-smear.jpg")
detections = sv.Detections.from_inference(result)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated = box_annotator.annotate(scene=image.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections)
cv2.imwrite("blood-smear-annotated.png", annotated)
Pass your API key through the ROBOFLOW_API_KEY environment variable rather than pasting it into the code, and never share it publicly. The model_id is your project name and version number. The same call works against a COCO-pretrained RF-DETR checkpoint if you pass model_id="rfdetr-base", which is a quick sanity check before your custom model finishes training.
Step 8: Deploy to production
A detector is rarely the whole application, and Roboflow takes you the rest of the way without converting weights by hand.
- Roboflow Workflows is a low-code, visual builder for chaining models and logic into one pipeline. For blood cells, you might run detection, count each class, flag slides outside a normal range, and write the result to a record, all without stitching libraries together. You build the pipeline once and run it the same way in the cloud or on the edge.
- Roboflow Inference is the open source engine that runs your model and your Workflows in production. It exposes a simple API and runs on cloud GPUs, on-prem servers, or edge devices like NVIDIA Jetson and Raspberry Pi. It is the same runtime behind 55 billion-plus model inferences a year across Roboflow customers, and your data and models stay yours with no lock-in.
- The Roboflow MCP server connects your workspace to AI agents. The Model Context Protocol is an open standard that lets agents call external tools the way developers call APIs. The Roboflow MCP server exposes your workspace as roughly 30 callable tools, so a coding agent like Claude Code, Codex, or Cursor can create a project, upload images, auto-label, train, and run inference from a single chat session. It is hosted at mcp.roboflow.com, authenticates with your API key, and is free and open source under Apache-2.0.
Going further: vision AI agents
Beyond running a fixed pipeline, you can build a vision AI agent: a system that perceives visual data, reasons about it with a multimodal model, takes an action, and repeats. For a lab workflow, an agent could detect and count cells, compare the counts against reference ranges, and draft a flag for a technician to review. Roboflow Workflows is a practical way to assemble these perception-plus-reasoning loops without building the infrastructure from scratch.
Why RF-DETR for custom object detection
If you want to understand the TensorFlow Object Detection API, the concepts carry over to any detector. If your goal is a model you will actually ship, RF-DETR is the better choice, and it is what Roboflow trains for you:
- Faster to fine-tune, higher accuracy. RF-DETR fine-tunes quickly on a custom dataset and reaches higher accuracy than a traditional MobileNet SSD workflow.
- No TFRecords, no version pinning. RF-DETR trains directly from your Roboflow dataset. There are no TFRecord or label_map files to generate and no fragile framework environment to maintain.
- Commercial-safe licensing. RF-DETR ships under a permissive license you can use commercially.
- One path to production. The same Annotate, Versions, Train, Inference, and Workflows tooling you used above works with RF-DETR out of the box.
You followed the exact workflow that production teams use: collect and label data, generate a version, train, evaluate, and deploy. The only thing that changes for a harder problem is the data you bring.
Frequently asked questions
Can I train a TensorFlow or TFLite object detection model in Roboflow?
Roboflow's hosted training trains its own model families, with RF-DETR recommended for object detection. If you specifically need a TensorFlow or TFLite model, you can export your data from Roboflow in TFRecord or many other formats and train it yourself. For almost all use cases, training RF-DETR in Roboflow gives you a more accurate model with far less setup.
Do I need to create TFRecords and a label map?
No. Generating TFRecords and a label_map is the most tedious part of the traditional TensorFlow workflow. Roboflow's dataset versions handle data formatting for you, so there is nothing to convert by hand.
How much data do I need?
There is no fixed minimum. The blood cell example trains a usable model from 364 images. A few hundred well-labeled images per class is a reasonable starting point for a simple detector. Image quality, variety, and accurate labels matter more than raw count, and augmentation can stretch a small dataset further.
What is MobileNet SSD?
MobileNet SSD is a lightweight object detection architecture: a Single Shot Detector that predicts boxes in one pass, paired with a small MobileNet backbone built to run on phones and embedded devices. RF-DETR now offers a better speed-and-accuracy tradeoff for most custom detection work.
Do I need a GPU?
No. Training runs in the Roboflow cloud and inference runs through the hosted API. You only need your own hardware if you choose to self-host with Roboflow Inference on the edge.
Get Started Training a TensorFlow MobileNet Object Detection Model
To build your own detector, create a free Roboflow account, bring or fork a dataset, generate a version, and train.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Feb 9, 2026). Training a TensorFlow MobileNet Object Detection Model with a Custom Dataset. Roboflow Blog: https://blog.roboflow.com/training-a-tensorflow-object-detection-model-with-a-custom-dataset/