
We are leaving this page only for reference.
We encourage you to try fully-supported Visual Language Models supported by inference, including Qwen2.5-VL.
CogVLM, a powerful open-source Large Multimodal Model (LMM), offers robust capabilities for tasks like Visual Question Answering (VQA), Optical Character Recognition (OCR), and Zero-shot Object Detection.
In this guide, I'll walk you through deploying a CogVLM Inference Server with 4-bit quantization on Amazon Web Services (AWS). Let's get started.
Setup EC2 Instance
This section is crucial even for those experienced with EC2. It will help you understand the hardware and software requirements for a CogVLM Inference Server.
To start the process search for EC2, then under 'Instances' click the 'Launch Instances' button and fill out the form according to the specifications below.
- GPU Memory: The 4-bit quantized CogVLM model requires 11 GB of memory. Opt for an NVIDIA T4 GPU, typically available in AWS g4dn instances. You might need to request an increase in your AWS quota to access these instances.
- CUDA and Software Requirements: Ensure your machine has at least CUDA 11.7 and Docker supporting NVIDIA. Choosing an OS Image like 'Deep Learning AMI GPU Pytorch' simplifies the process.
- Network: For this setup, allow all incoming SSH and HTTP traffic for secure access and web connections.
- Keys: Create and securely store an SSH key for accessing your machine.
- Storage: Allocate around 50 GB for the Docker image and CogVLM model weights, with a little extra space as a buffer.
Setup Inference Server
Once logged in via SSH using your locally saved key, proceed with the following steps:
- Check CUDA Version, GPU Accessibility, and Verify Docker and Python Installations.
# verify GPU accessibility and CUDA version
nvidia-smi
# verify Docker installation
docker --version
nvidia-docker --version
# verify Python installation
python --version- Install Python packages and start the Inference Server.
# install required python packages
pip install inference==0.9.7rc2 inference-cli==0.9.7rc2
# start inference server
inference server startThis step involves downloading a large Docker image (11GB) to run CogVLM, which might take a few minutes.
- Run
docker psto make sure the server is running. You should see aroboflow/roboflow-inference-server-gpu:latestcontainer running in the background.
Run Inference
To test the CogVLM inference, use a client script available on GitHub:
- Clone the repository and set up the environment.
# clone cog-vlm-client repository
git clone https://github.com/roboflow/cog-vlm-client.git
cd cog-vlm-client
# setup python environment and activate it [optional]
python3 -m venv venv
source venv/bin/activate
# install required dependencies
pip install -r requirements.txt
# download example data [optional]
./setup.sh- Acquire your Roboflow API key and export it as an environment variable to authenticate to the Inference Server.
export ROBOFLOW_API_KEY="xSI558nrSshjby8Y4WMb"- Run the Gradio app and query images.
python app.pyThe Gradio app will generate for you a unique link that you can use to query your CogVLM model from any computer or phone.
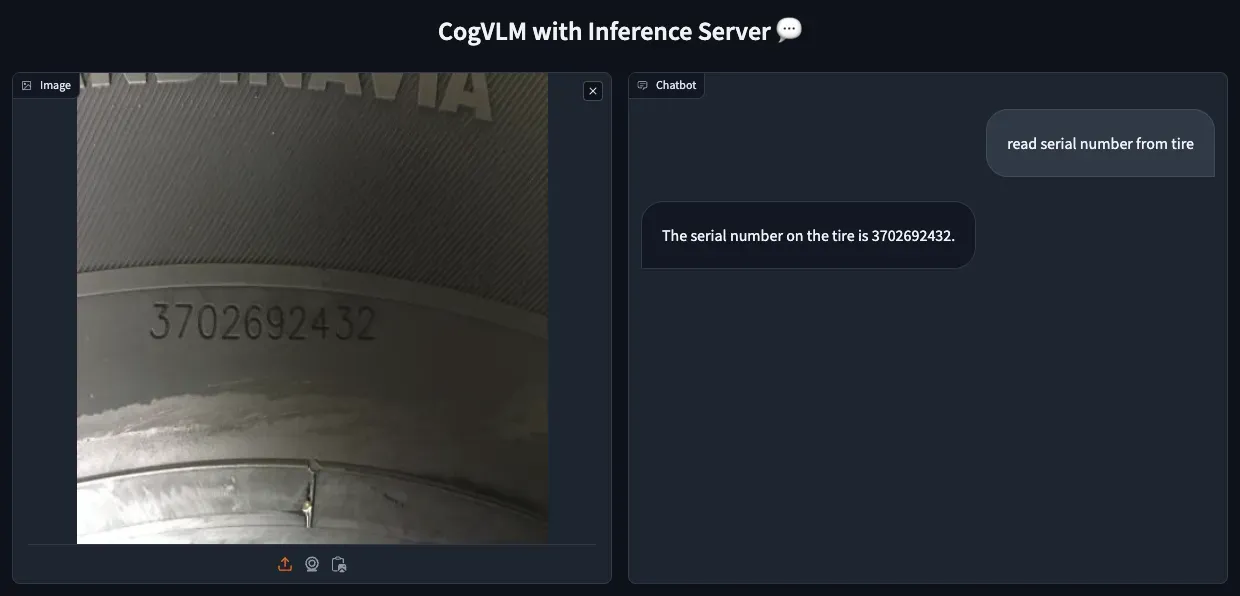
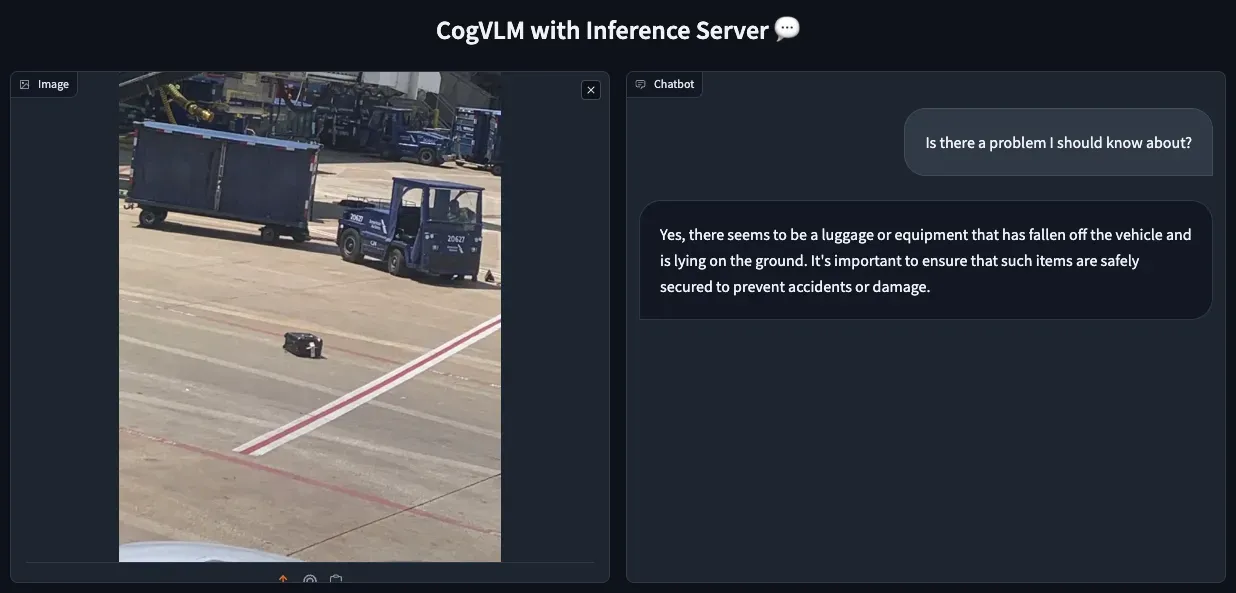
Note: The first request to the server might take several minutes as it loads model weights into the GPU memory. Monitor this process using docker system df and nvidia-smi. Subsequent requests shouldn’t take longer than a dozen seconds.
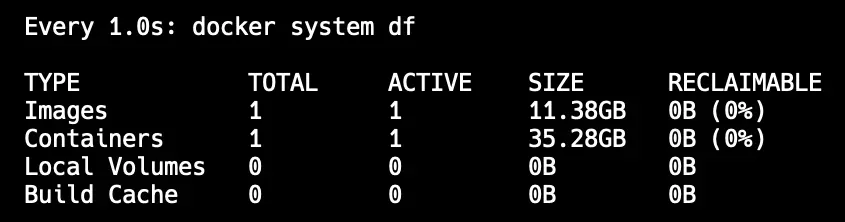
docker system df output after loading the Inference Server image and CogVLM weights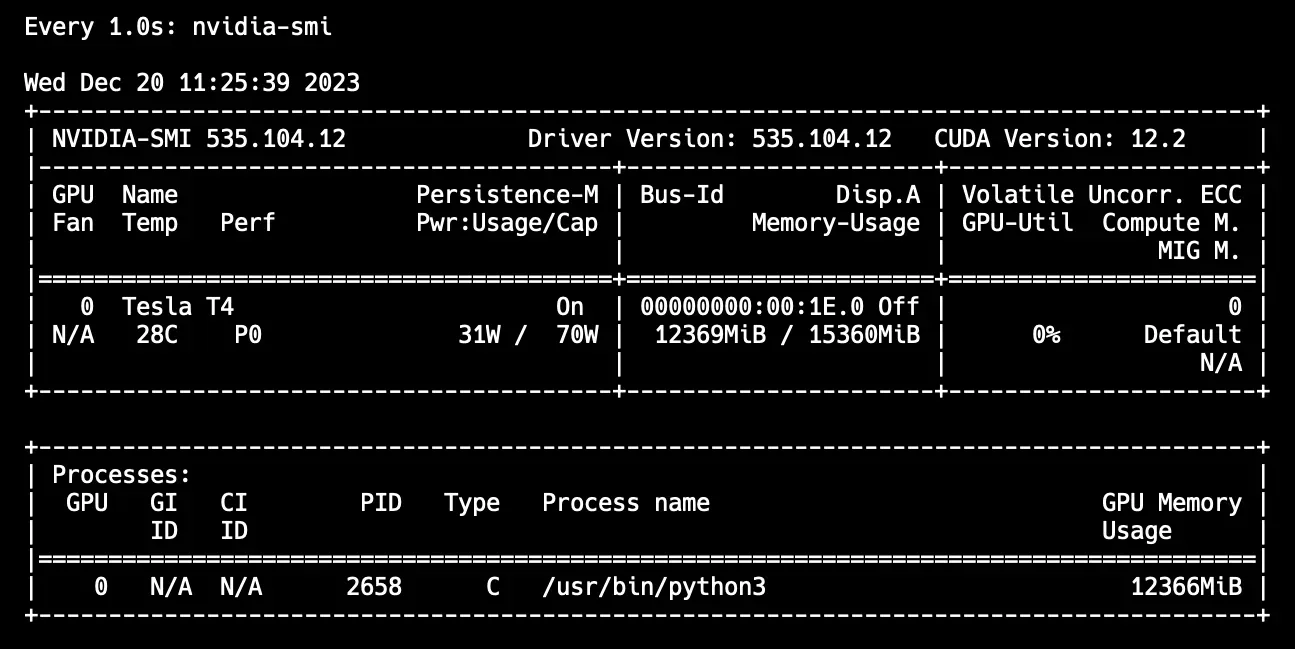
nvidia-smi output after loading CogVLM weights into memory Conclusions
CogVLM is a versatile and powerful LMM, adept at handling a range of computer vision tasks. In many cases, it can successfully replace GPT-4V and give you more control. Visit the Inference documentation to learn how to deploy CogVLM as well as other computer vision models.
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Dec 20, 2023). How to Deploy CogVLM on AWS. Roboflow Blog: https://blog.roboflow.com/how-to-deploy-cogvlm-in-aws/