
Over the past decade, machine learning (ML) has gone from being an academic interest to a top priority for companies across the globe. Instead of writing brittle if-else rules, engineers now feed examples to algorithms that learn patterns automatically. Done well, machine learning shrinks costs and unlocks new revenue streams.
What Is Machine Learning?
Imagine teaching a child to recognize a cat. You probably wouldn't start by writing a rule like “if animal = 4 legs AND tail AND whiskers → cat.” Instead, you show them many cat photos. Over time the child would see patterns and generalize their learnings to identify new cats.
Machine learning works the same way. It’s software that learns from examples to make predictions or decisions without being explicitly programmed for every scenario. In short, while rule-based systems rely on rigid if-else logic, ML systems adapt. They refine their internal parameters as they encounter more data.
You might be surprised to realize you likely encounter machine learning in your every day life already, for example your inbox catching spam or Netflix recommending a series to watch are both examples of machine learning in action.
Types of Machine Learning
Different problems call for applying varying types of machine learning strategies. Choosing an approach that aligns with your data availability, budget, and timeline is important. Here are relevant types of ML strategies to consider.
Supervised Learning
Supervised learning is what most people think of when they hear “machine learning.” Models learn directly from labeled examples, mapping inputs (x) to known outcomes (y). With a dataset that pairs images or data with ground-truth labels, supervised approaches excel at tasks like classification and object detection. Think of approving or denying a credit application, classifying invoices as paid or unpaid, flagging fraud, or spotting a missing screw on a production line.
Unsupervised Learning
Unsupervised learning takes a different approach. Instead of requiring labels, it looks for structure hidden in unlabeled data. The inputs might be customer transactions, images, or sensor logs. From there, the model clusters or groups data to uncover patterns. It’s particularly useful for segmenting customers by behavior or surfacing anomalies—like when odd shipments stand out in logistics data.
Semi-Supervised Learning
Semi-supervised learning combines the best of both worlds. With a small pool of labeled data and a much larger pool of unlabeled data, models can achieve higher accuracy without the cost of labeling everything. A practical example might be labeling just 5% of video frames while letting the model learn from the backlog of unlabeled frames, dramatically reducing labeling time while still improving performance.
Self-Supervised Learning
Self-supervised learning has become a cornerstone of modern AI. Instead of relying on labels, models train on pretext tasks designed to teach useful representations. This is especially powerful when working with massive unlabeled datasets, like archives of images or video. Contrastive learning, for instance, helps pre-train backbones that can later be fine-tuned for downstream tasks with much less labeled data.
Transfer Learning and Foundation Models
Transfer learning and foundation models speed up development by starting with pretrained checkpoints and adapting them to new domains. Engineers can fine-tune models or use lightweight adapters like LoRA to specialize them for their environment. This approach makes training faster, cheaper, and more accurate—especially when labeled data is limited. For example, you might adapt RF-DETR to your warehouse cameras with just a modest dataset.
Reinforcement Learning
Reinforcement learning is about learning through feedback. Instead of labels, models receive rewards for actions that move them closer to a goal. This setup is particularly well suited for control and robotics problems. Picture a robot arm refining its movements to minimize dropped parts, an autonomous vehicle improving its driving policy, or an agent mastering a game through trial and error.
How to Choose a Machine Learning Strategy
Start with the data you already have. If you have well-labeled images of defects vs. non-defects, Supervised learning shines. If you have piles of raw camera footage but no labels, use Unsupervised to surface clusters and outliers, then label strategically. If labels are expensive, consider semi-/self-supervised learning to cut annotation costs; if speed matters, transfer from a foundation model and fine-tune. For dynamic tasks requiring sequential decisions (e.g., robotic pick-and-place), consider Reinforcement learning to maximize reward over time.

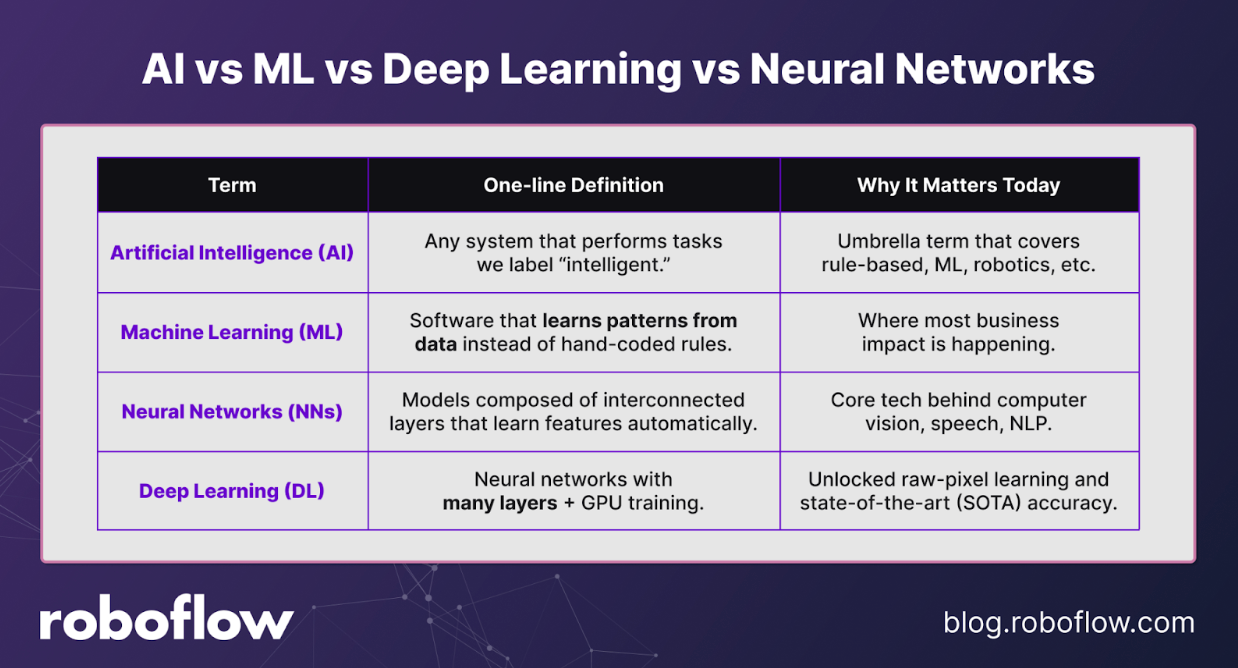
How Machine Learning Differs from Artificial Intelligence (AI), Deep Learning, and Neural Networks
Artificial Intelligence (AI) is the umbrella term for systems that perform tasks we call “intelligent.” Machine learning (ML) is a subset of AI, which is any software that learns rules from data rather than using hand-coded logic.
Inside ML, Neural Networks (NNs) are models built from layers of weighted connections that learn representations automatically. Deep Learning (DL) refers to NNs with many layers, enabling end-to-end learning from raw inputs (pixels, audio, text) and displacing most hand-crafted feature engineering.
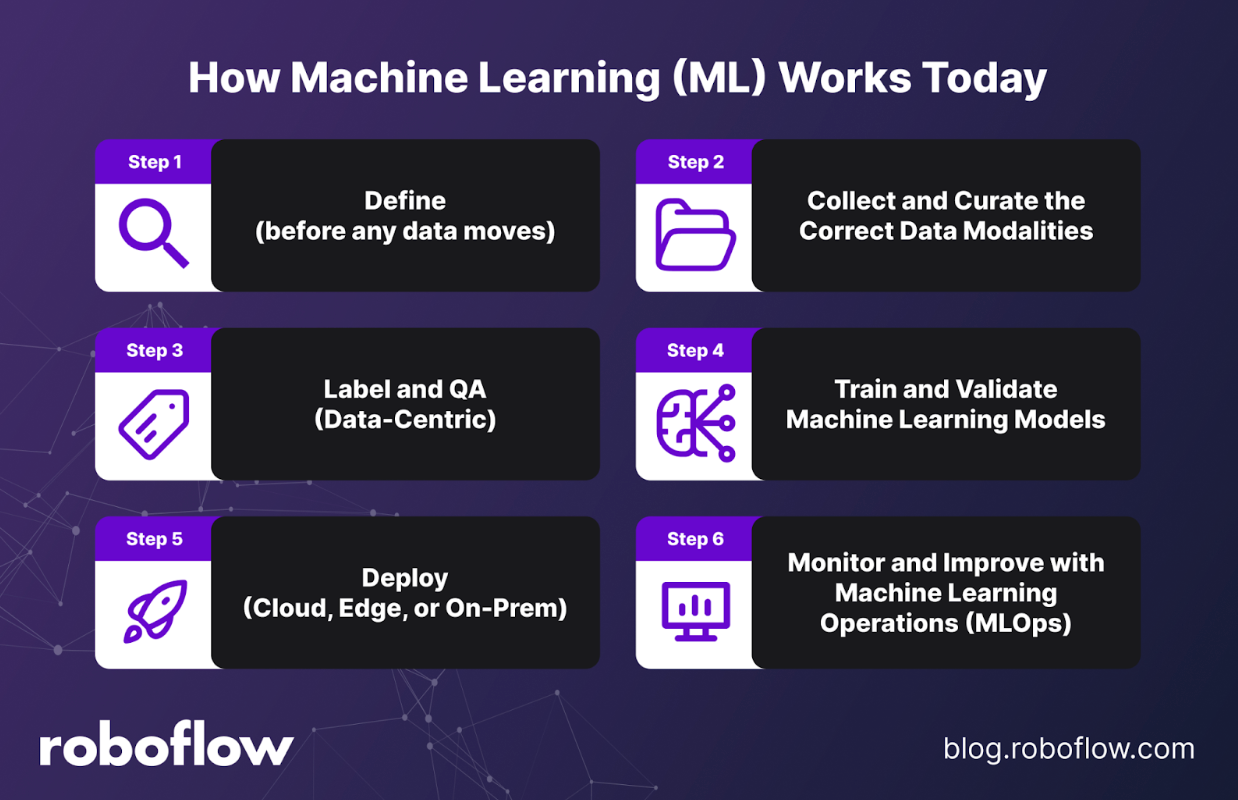
How Machine Learning Works Today
Getting value from machine learning isn’t about building a single model once and calling it done. It’s a process discipline. Modern teams start with the business goal, establish clear data standards, and then move through cycles of training, evaluation, deployment, and monitoring with reproducibility built in.
Two big shifts define today’s ML lifecycle. First is the move to data-centric ML: the quality and coverage of your data now matter more than the complexity of your model. Second is the rise of pre-trained and foundation models, which speed up training and reduce costs but still depend on clean, well-labeled data and solid operational practices.
At a practical level, the lifecycle starts with clearly defining the problem in business terms. For example, are you trying to reduce defect rates or improve throughput? From there, you collect the right data, label it consistently, and ensure quality checks are in place. That labeled data feeds into training, where models learn from examples and are validated on held-out data to make sure they’ll generalize to real-world conditions—not just look good in the lab.
Once a model is performing well, the focus shifts to deployment: packaging it for the cloud, edge, or on-prem depending on your privacy, latency, and hardware needs. But deployment is not the end. Teams must invest in monitoring and continuous improvement - tracking performance over time, identifying where models struggle, and updating them as conditions, data, and business needs change.
The key takeaway: shipping ML isn’t about chasing the fanciest algorithm. It’s about building a repeatable process that ties model performance back to business outcomes and ensures reliability in the real world.
Common Machine Learning Model Families
There isn’t a single “best” machine learning model. The right choice depends on your data, constraints, and goals. In practice, you’ll want to start with simple models for tabular problems, reach for deep networks when your inputs are unstructured or when you’ve hit an accuracy ceiling, and always weigh tradeoffs like interpretability, latency, and the volume of data available. Here are the common model families.
Linear and Logistic Regression
Linear and logistic regression are the simplest baselines to start with, particularly for tabular datasets. They are fast, highly interpretable, and easy to implement, making them excellent first steps in a modeling project. Their limitation is capacity - they can only capture relatively simple relationships - so while they set a strong baseline, they’re rarely the final solution.
Tree Ensembles
Tree-based methods like decision trees, random forests, and XGBoost are often the next step up. They handle mixed feature types well and deliver strong off-the-shelf accuracy without extensive feature engineering. The main drawback is deployment - tree ensembles can be more challenging to optimize for low-latency environments, especially when running on edge devices.
Support Vector Machines
Support Vector Machines (SVMs) and kernel methods shine on smaller tabular datasets, where they can draw strong decision boundaries with good generalization. Their limitations show up as the data scales: training and inference become slow, and interpretability suffers. As a result, SVMs are best suited for smaller, contained problems rather than large-scale systems.
Probabilistic and Graphical Models
Probabilistic and graphical models are powerful when the problem involves structured uncertainty. They offer a high degree of explainability and can model relationships that are difficult to capture otherwise. The tradeoff is complexity - these models are often harder to train and require careful mathematical and computational treatment, which can slow down practical adoption.
Neural Networks
Neural networks have become the go-to family for unstructured inputs like images, audio, text, and even multimodal data. They excel by learning features end-to-end, removing the need for manual feature engineering. Their weaknesses lie in the cost of training: they require large amounts of labeled data and careful tuning to achieve state-of-the-art results.
A practical rule of thumb is to stick with simpler methods for structured tabular problems, and shift to deep models once your data is unstructured or your baseline approaches have plateaued.
What Is Deep Learning?
Deep learning is the branch of machine learning that relies on multi-layer neural networks to learn features directly from raw data - whether pixels, audio waveforms, or text tokens - rather than depending on hand-engineered rules. It rose to prominence in the late 2000s and early 2010s as three forces converged: the availability of large labeled datasets, the rise of GPU and accelerator compute, and architectural advances that made it practical to train deep networks stably and fast enough for production systems.
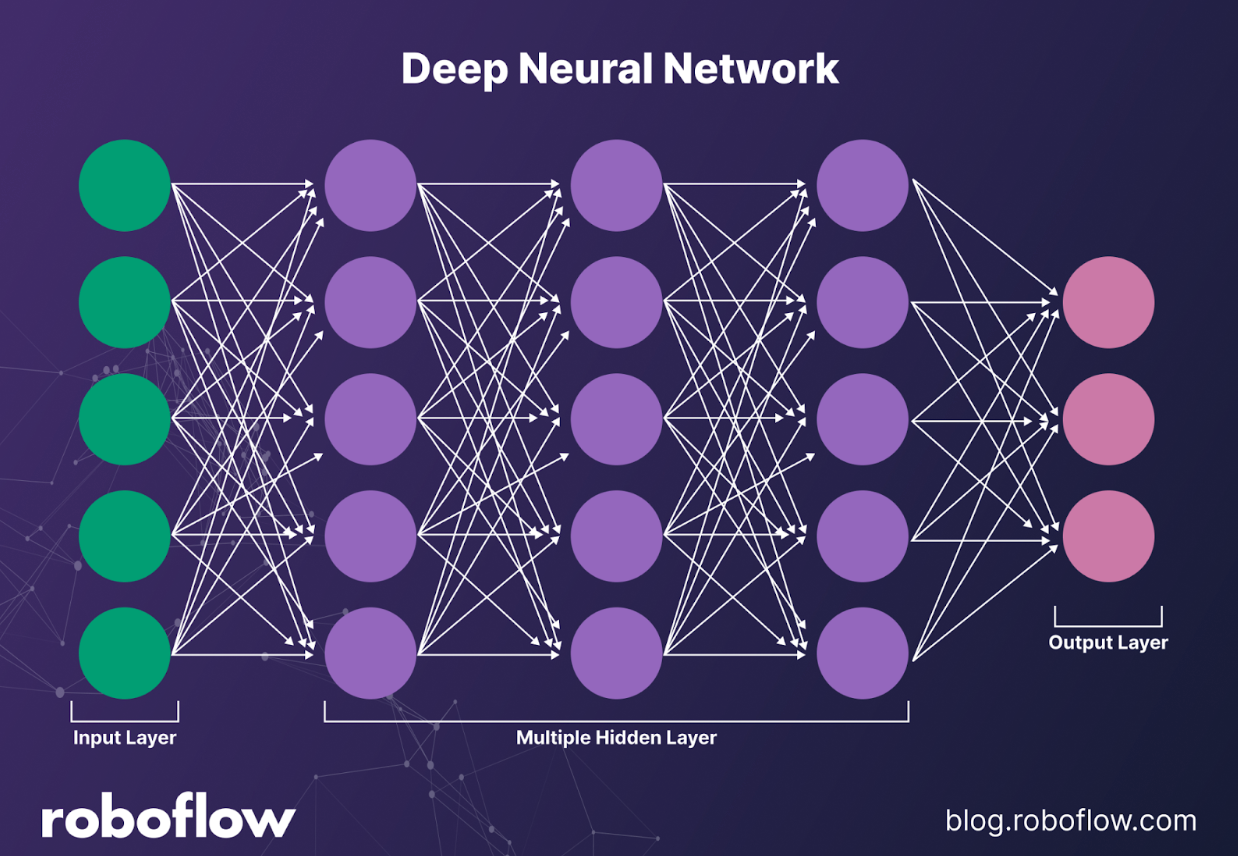
How Deep Networks Work
At a high level, a deep network stacks layers of simple computations - linear transformations followed by nonlinear activations. Each layer transforms the data representation into something more meaningful: pixels into edges, edges into textures, textures into parts, and parts into complete objects. In language, the same principle applies: characters become words, words become phrases, and phrases become meaning. Training relies on backpropagation to measure how much each weight contributed to error, then uses gradient descent to adjust those weights, gradually making the model less wrong with every pass.
Why Teams Pick Deep Learning
Teams turn to deep learning when they need to handle unstructured data such as images, video, speech, or free text. Unlike traditional approaches, performance improves as data and compute scale, and the availability of transfer learning and foundation models makes it easier than ever to adapt large pre-trained networks to specific tasks. Deep learning also enables end-to-end training, reducing brittle hand-offs and engineered features, which leads to more resilient systems in production.
What You Need to Run Deep Learning
Running deep learning effectively requires more than just a big model. Data quality and coverage matter as much as raw volume. Compute budgets must be planned carefully, with attention to GPU resources, edge hardware constraints, and latency requirements. Successful teams also bring disciplined MLOps practices to the table: versioning datasets, ensuring reproducibility across experiments, and monitoring models in deployment to catch drift or performance regressions early.
How a Deep Net Learns in One Pass
In a single pass, a deep net applies a weighted sum to inputs, runs the result through nonlinear activations like ReLU or GELU, and continues through stacked layers. Parameters and bias terms control how strongly inputs influence outputs, and backpropagation computes the gradient of a loss function (such as cross-entropy or IoU/Dice) with respect to each weight. Optimizers like SGD or Adam then update those weights. To keep training stable and avoid overfitting, techniques like batch normalization, layer normalization, dropout, weight decay, and data augmentation are commonly applied.
Scaling with Transfer Learning and Foundation Models
Deep networks can approximate extremely complex functions, which is why they power today’s state-of-the-art systems in vision, language, speech, recommendation, and multimodal AI. Many teams no longer start from scratch. Instead, they adapt pretrained checkpoints: fine-tuning a small head, or applying lightweight adapters like LoRA or QLoRA. This reduces both the data and compute required to reach production-grade performance.
Throughput, Latency, and Deployment
Finally, modern architectures like Transformers are designed for parallelism, which makes them efficient to train and deploy on today’s hardware. When running at the edge, quantization and optimized runtimes such as ONNX or TensorRT help models meet real-world latency constraints. The combination of scale, flexibility, and deployment readiness explains why deep learning continues to be the default approach for solving the hardest machine learning problems.
Deep Learning Architectures
With that mental model, the next question is which deep architecture fits your problem and constraints. The sections below summarize the most common families, why they work, and where they shine.
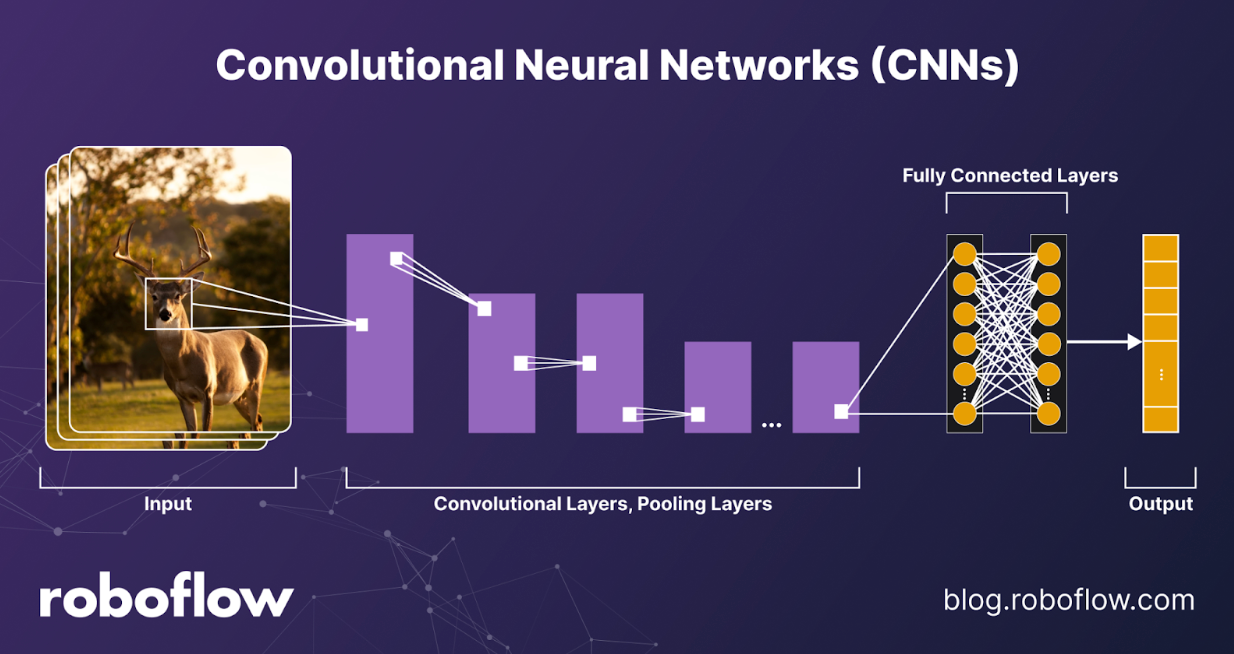
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks remain the backbone of modern computer vision. By applying convolutional filters with shared weights across an image, CNNs detect local patterns such as edges, corners, and textures. Pooling layers add spatial invariance, enabling recognition of the same object even when it shifts in the frame. Their parameter efficiency and strong inductive bias for locality make them a natural fit for image data.
Architectures like ResNet, RegNet, and EfficientNet dominate classification tasks, while U-Net and Mask R-CNN shine in segmentation. CNNs are widely used for defect detection, PPE compliance, document layout parsing with OCR, and medical imaging. Their main limitation is modeling long-range dependencies without additional mechanisms such as dilated convolutions or attention, and they can struggle when inputs span highly diverse modalities.
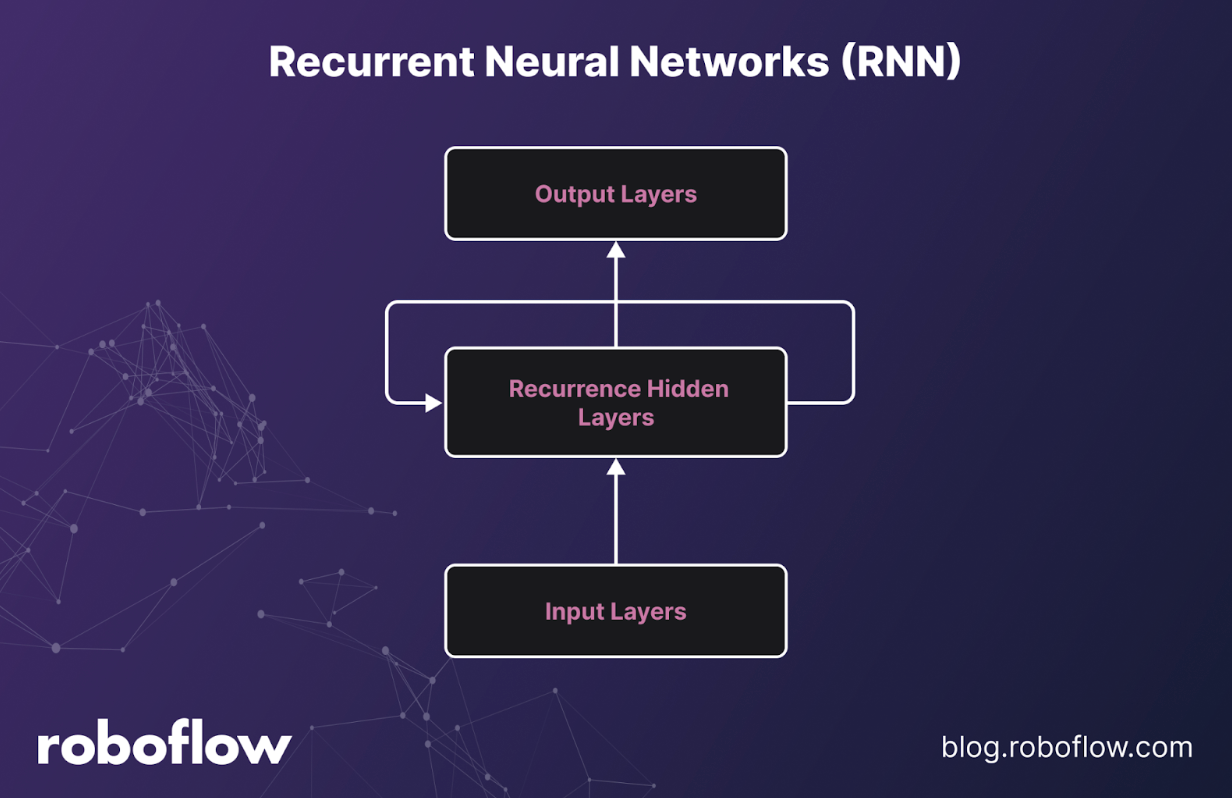
Recurrent Neural Networks (RNNs: LSTM/GRU)
Recurrent Neural Networks, including LSTMs and GRUs, process sequences step by step, carrying forward a hidden state that summarizes past information. Gating mechanisms allow them to remember or forget over time, which makes them well suited for compact sequential signals and time-series data. They’re also a strong fit for edge use cases, where low-latency streaming inference matters.
However, RNNs struggle with long contexts due to vanishing or exploding gradients, and their sequential nature makes them slower to train at scale compared to parallelizable architectures. Still, they remain useful in sensor forecasting, keyword spotting, classic NLP, and lightweight sequence modeling on embedded devices.
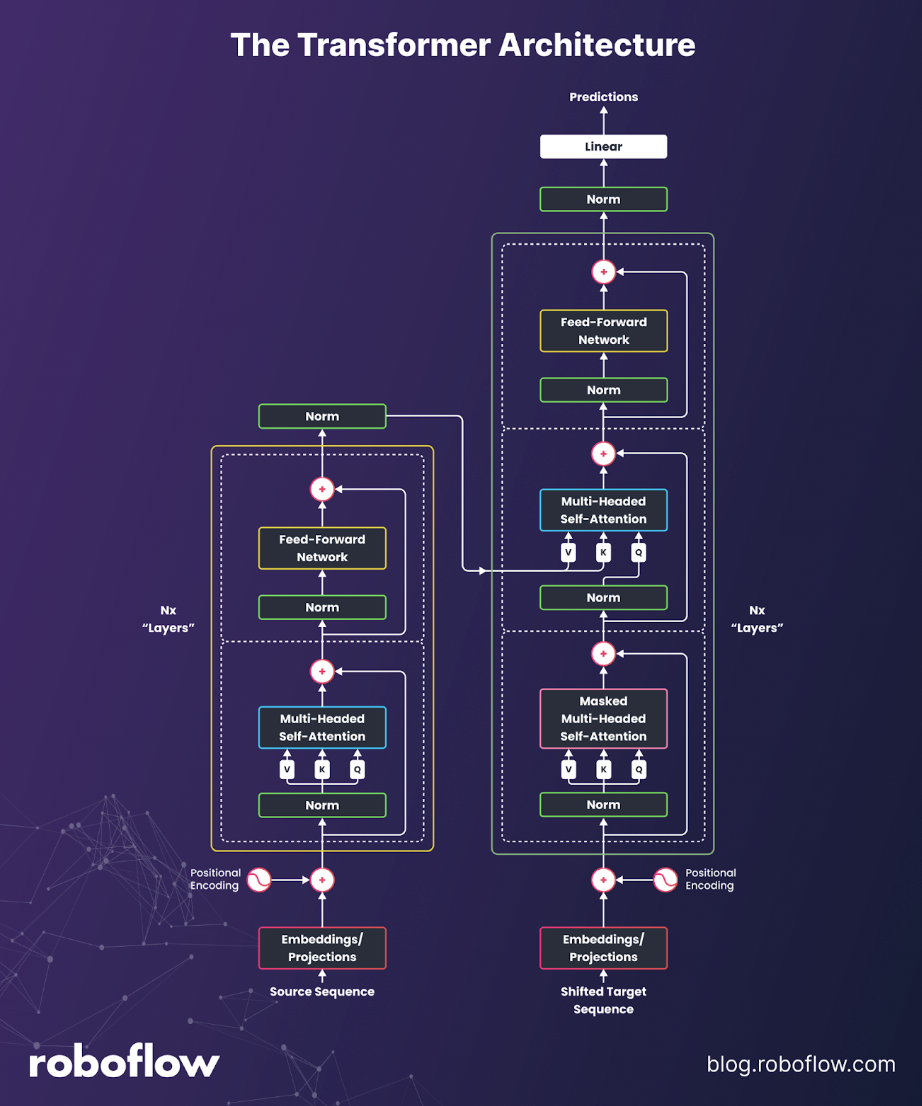
Transformers (Self-Attention)
Transformers replaced recurrence with self-attention, giving models the ability to weigh any part of the input when producing outputs. This innovation unlocked massive parallelism in training and enabled long-range reasoning across text, images, and audio. Transformers now define the state of the art in language (LLMs), vision (ViTs, DETR), and multimodal applications like image-text models. They scale gracefully with more data and compute, and they transfer effectively across domains.
The trade-off is cost: naïve attention scales quadratically with sequence length, which requires optimizations such as windowing, sparsity, FlashAttention, or hybrid approaches. On edge devices, Transformers can also be compute-heavy, though quantization and distillation help. Today, they power chat assistants, document understanding, DETR-style vision heads for detection and segmentation, video understanding, and large-scale retrieval and ranking systems.
State Space Models (SSMs)/Mamba-style
State Space Models, particularly modern “selective” variants like Mamba, are an emerging alternative to Transformers for sequence modeling. These models evolve a learned state linearly over positions, offering streaming efficiency and throughput advantages while still handling long contexts. Their natural fit for real-time applications makes them appealing for speech, audio, code, and emerging LLM tasks where speed and context length matter most.
The ecosystem, however, is younger than that of Transformers, and best practices are still evolving. Performance can vary across tasks, so hybrid architectures are common. Nonetheless, SSMs are attracting attention as a promising option for high-throughput, memory-efficient sequence modeling.
Autoencoders and Variational Autoencoders (VAEs)
Autoencoders compress data into a latent representation and then reconstruct the input, making them useful for dimensionality reduction and anomaly detection. Variational Autoencoders add a probabilistic prior over the latent space, which improves generalization. Both approaches shine when explicit labels are scarce, since they can learn representations directly from data.
The trade-off is reconstruction quality: outputs may appear overly smooth, and complex textures can be underfit. In practice, autoencoders and VAEs are often used for industrial anomaly detection (by learning “normal” and flagging deviations), as well as for data compression and denoising pipelines.
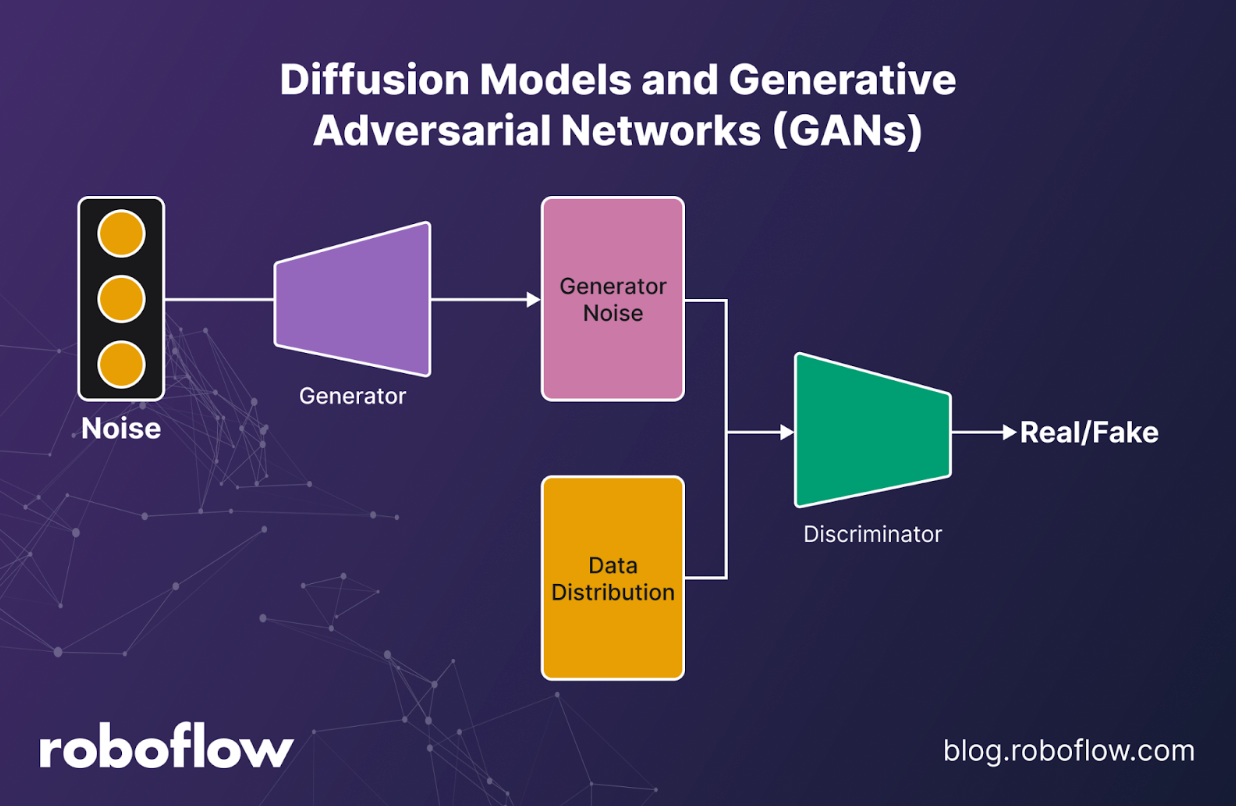
Diffusion Models and Generative Adversarial Networks (GANs)
Diffusion models and GANs lead the charge in generative modeling. Diffusion works by iteratively denoising from random noise back to structured data, while GANs pit a generator against a discriminator to synthesize realistic samples. These models produce high-fidelity images and videos, power in-painting and super-resolution, and generate synthetic datasets for augmentation. Diffusion models tend to be slow at inference unless accelerated, while GANs can be unstable to train. Despite these challenges, both are heavily used in creative tooling, simulation for rare edge cases, and synthetic augmentation pipelines to reduce bias and strengthen downstream models.
Graph Neural Networks (GNNs)
Graph Neural Networks operate directly on graph structures of nodes and edges, passing messages along connections to learn relational patterns. Their strength lies in modeling relationships rather than isolated entities, which makes them powerful for applications like supply chain modeling, drug discovery, fraud detection, recommender systems, and route optimization.
Scaling GNNs to very large graphs can be challenging, often requiring careful batching and sampling strategies. Still, their ability to reason over structured relationships sets them apart from other model families and makes them indispensable in domains where connections matter as much as individual data points.
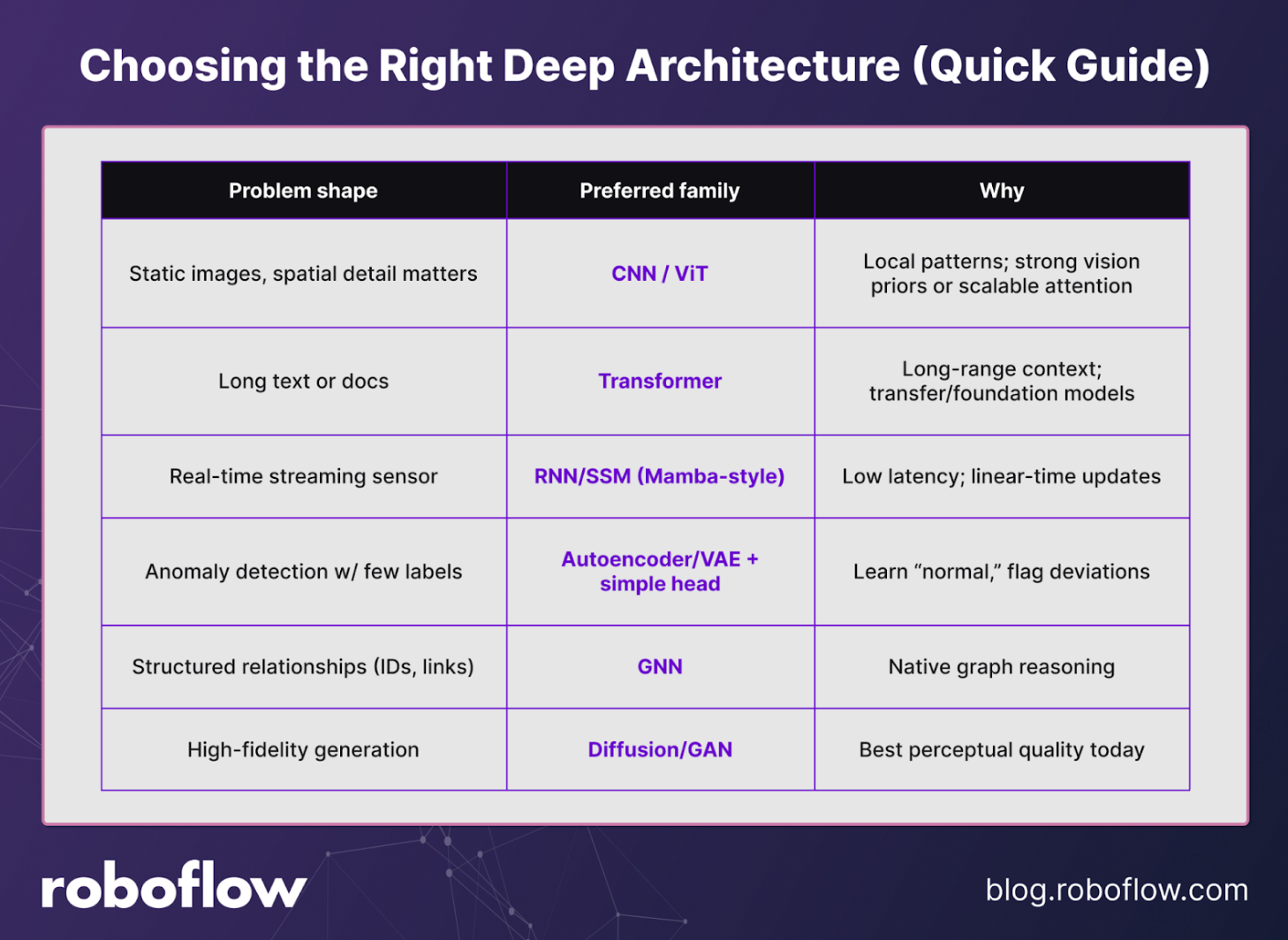
How to Choose the Right Deep Learning Architecture
Business Use Cases of Machine Learning
One of the most impactful applications of machine learning in business is computer vision. Unlike traditional tabular ML, which works on rows and columns, vision models learn spatial patterns like edges, textures, and shapes - and often temporal cues like motion or continuity across video frames.
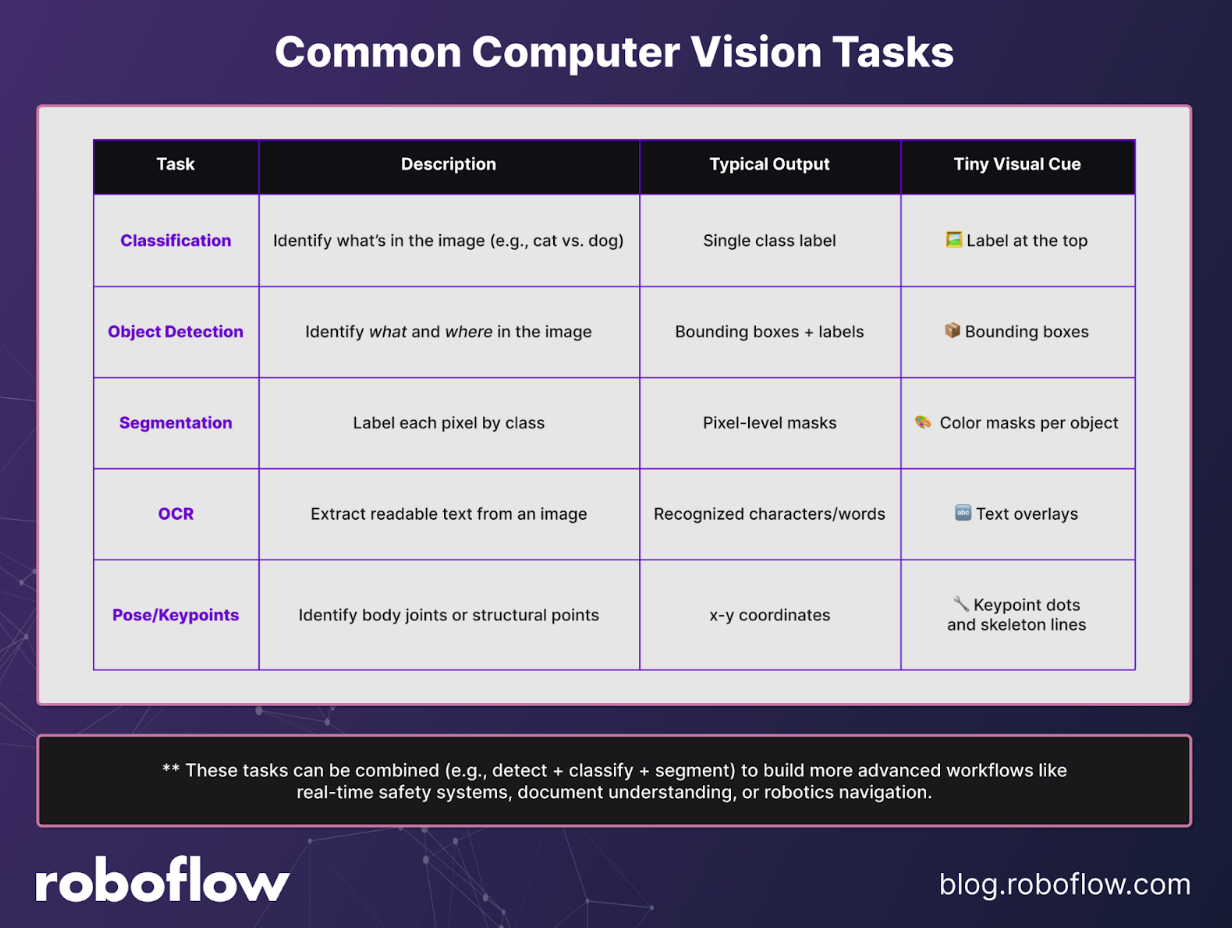
At its core, computer vision gives software the ability to “see,” turning grids of pixels into features, and those features into predictions that drive real-time decisions. This means factories can spot defects as parts roll off the line, retailers can monitor shelves automatically, and logistics providers can track pallets as they move through warehouses. In the next section, we’ll look at five of the most common computer vision tasks and how they translate into practical business outcomes.
1. Classification
Classification answers the question: “What is in this image?” A classification model predicts a single label—or sometimes a ranked set of top labels—for each image or frame. This approach is powerful for presence or absence checks, quality gates such as good vs. bad, or simple triage tasks. It’s a straightforward way to decide whether something meets requirements before moving forward.
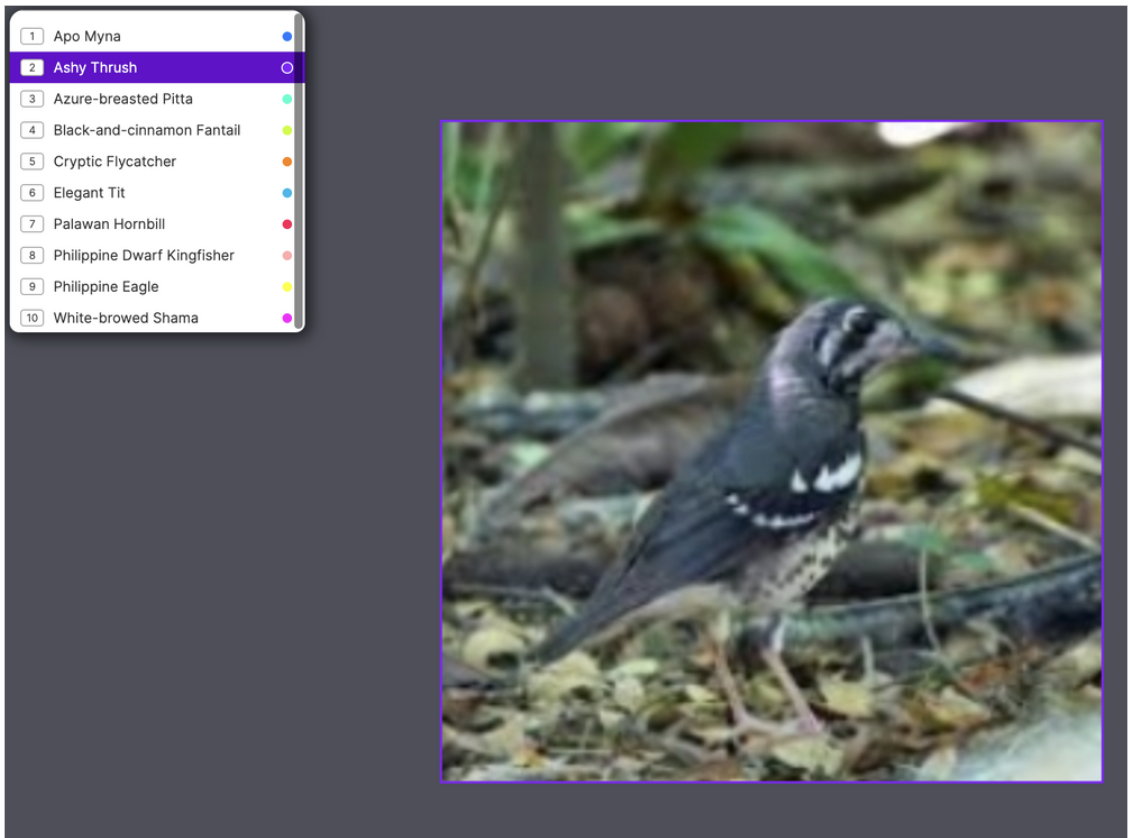
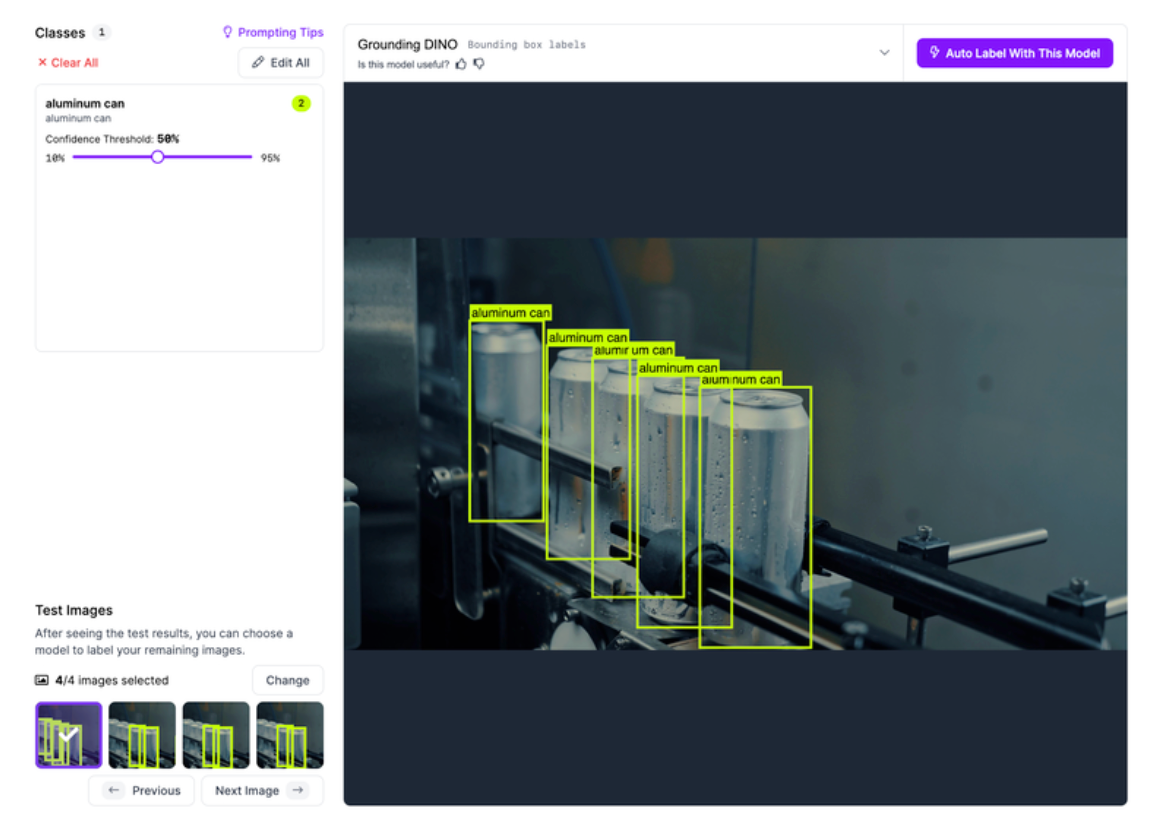
2. Object Detection
Object detection takes the next step by answering “What and where?” Instead of a single label for the whole image, detection models identify objects and draw bounding boxes around them, each with a class label. This makes them ideal for counting parts, locating defects, or identifying where specific components appear on a line.
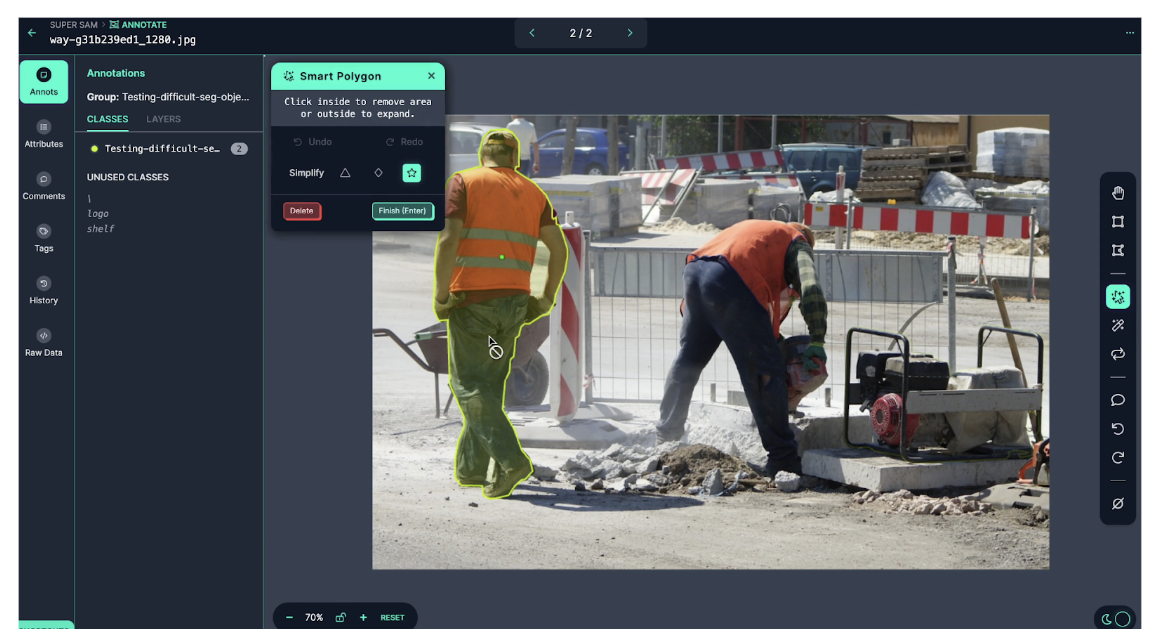
3. Segmentation
Segmentation goes deeper, predicting which pixels belong where. Models return pixel-accurate masks, either at the class level (semantic segmentation) or for individual objects (instance segmentation). This is critical in use cases where geometry or area matters, such as measuring paint coverage, detecting spills, or calculating the size of damaged regions.
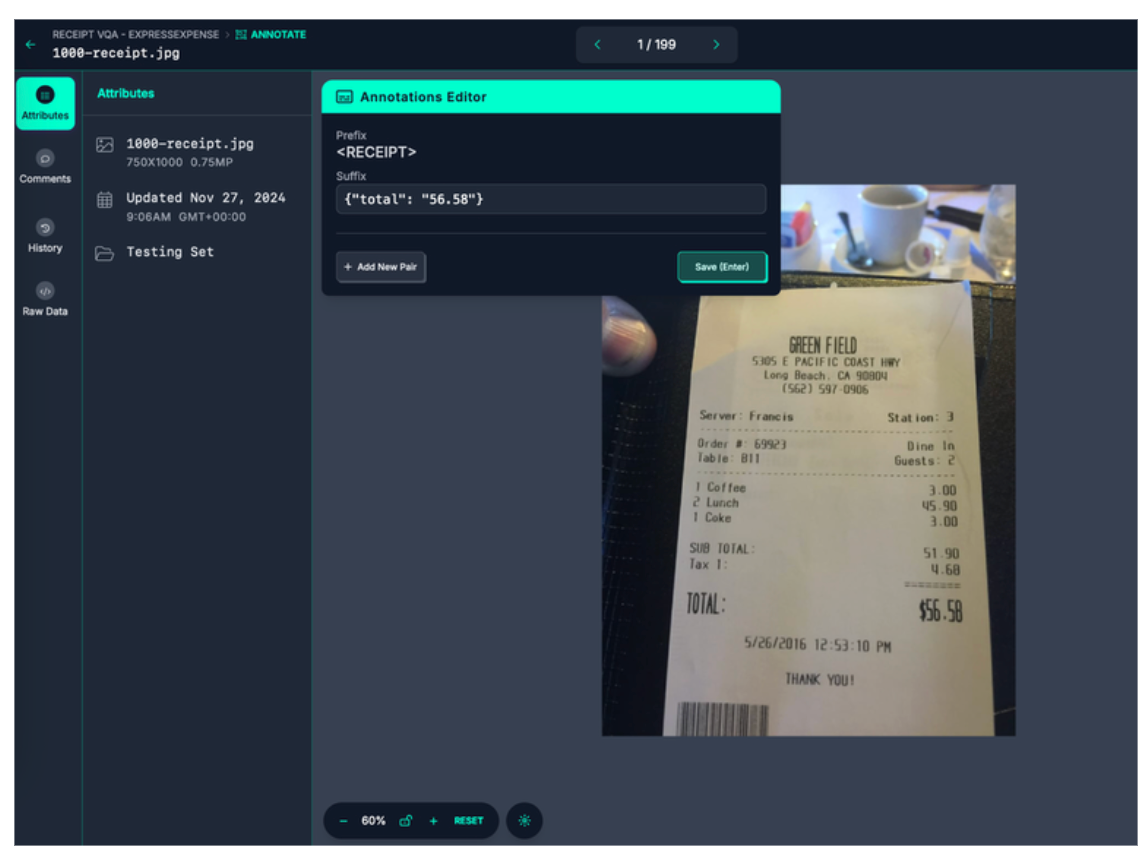
4. Object Character Recognition (OCR)
OCR models shift the focus to text, answering “What text is present?” These models detect text regions and then transcribe characters, words, or lines directly from the image. OCR is used across industries to read labels, dockets, IDs, lot codes, signage, or even meters. With Roboflow, you can annotate multimodal OCR datasets and train models to handle real-world variability in fonts, backgrounds, and lighting.
5. Pose/Keypoints
Pose and keypoint models help answer “How are parts and people aligned?” Instead of bounding boxes or masks, they predict specific landmarks—such as human joints or fiducials on equipment. These landmarks make it possible to measure posture, ensure assembly alignment, or verify PPE usage. From workplace safety to robotic assembly, pose estimation provides fine-grained insights about how things are positioned in space.
You can combine these tasks (e.g., detect + classify + segment) to build more advanced workflows like real-time safety systems, document understanding, or robotics navigation.
Here are some typical use cases:
- Manufacturing quality: missing-component detection (detection), surface defect grading (segmentation), and pass/fail checks (classification).
- Warehouse and logistics: pallet/parcel counting (detection), label/OCR verification (OCR), and load alignment (pose/keypoints).
- Retail analytics: on-shelf availability (detection/segmentation), queue length (detection), and planogram compliance (classification/detection).
- Construction and safety: PPE checks (detection/pose), site hazard identification (segmentation), and zone breaches (detection).
- Document capture and back office: invoices, IDs, and forms (OCR + detection), field validation (post-processing rules).
Why Machine Learning Matters for Your Business
Machine learning is no longer a research project. It’s the engine powering competitive advantage across industries. ML is about teaching software to learn patterns from data and make decisions at scale, whether that means predicting demand or spotting defects.
As you explore where to apply machine learning, computer vision will likely be one of the most practical starting points. Vision AI connects directly to your operations: your products, your lines, your assets, and translates raw pixels into actionable insight.
- Start free with Roboflow. Upload 20 images, label a few examples, click Train, and call your first prediction in minutes.
- Book a Vision Strategy Call. Scope a pilot with our team and leave with a concrete plan.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Sep 8, 2025). What Is Machine Learning?. Roboflow Blog: https://blog.roboflow.com/machine-learning/