
Multimodality, which involves combining various data input formats such as text, video, and audio in a single model, will undoubtedly become one of the critical directions for AI progress in the coming years. Large Multimodal Models (LMMs) ability to process and interpret the contents of images is usually limited. It comes down primarily to Object Character Recognition (OCR), Visual Question Answering (VQA), and Image Captioning.
Detection and segmentation are out of the question unless you use clever prompts. In this post, I'll show you how to expand the range of LMMs' capabilities using Multimodal Maestro.
Set-of-Marks
The authors of the Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V paper discovered that you can unleash LMM grounding abilities through skillful visual prompting. Effectively enabling object detection and even segmentation.
Instead of uploading the image directly to the LMM, we first enhance it with marks generated by GroundingDINO, Segment Anything Model (SAM), or Semantic-SAM. As a result, the LMM can refer to the added marks while answering our questions.
Multimodal Maestro
Inspired by Set-of-Mark, we created a library to facilitate the prompting of LMMs. Introducing Multimodal Maestro!
The library includes advanced prompting strategies that allow for greater control and, as a result, a better result from LMMs.

Prompting GPT-4 Vision
Multimodal Maestro can significantly expand GPT-4 Vision's capabilities and enable detection and/or segmentation. As an experiment, let's ask GPT-4V to detect the red apples in the photo. GPT-4V cannot return boxes or segmentation masks, so it tries to describe the position of the search objects using language.
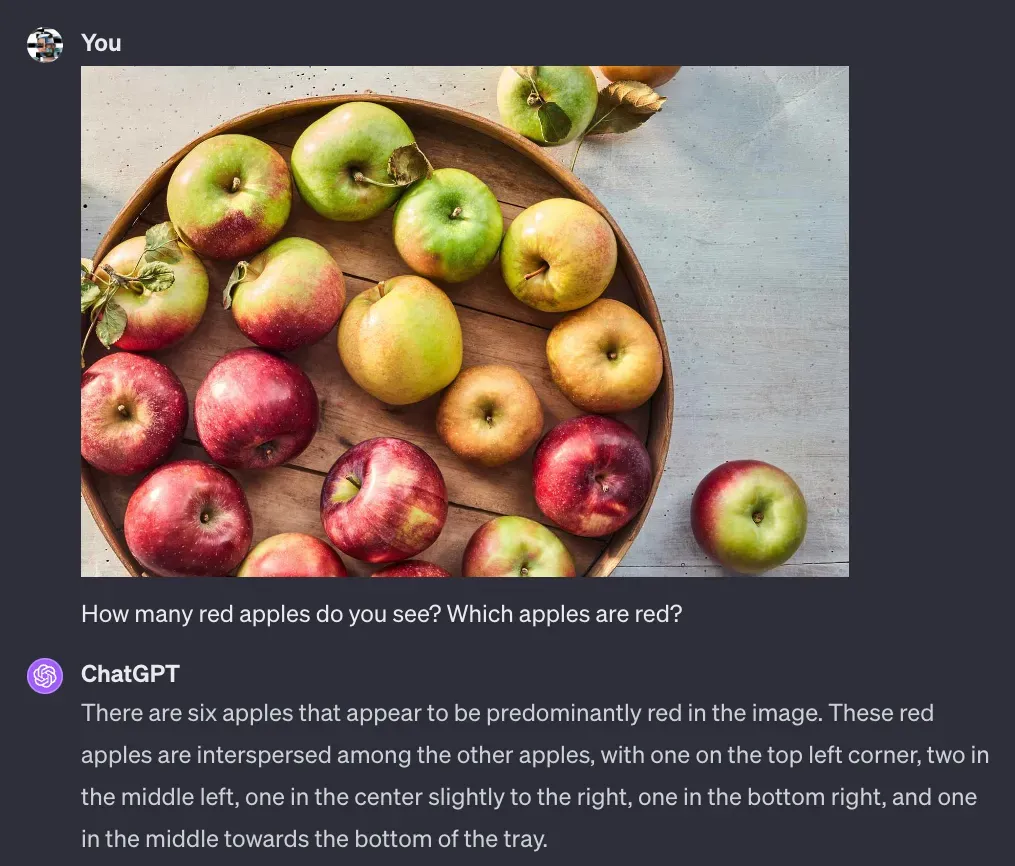
With Multimodal Maestro, we can create an image prompt in the Set-of-Mark style and ask the question again. This time, the output is much better.
There are six apples that appear red in the image. These apples are labeled with the following numbers: [1], [3], [5], [6], [8], and [9].
Prompting CogVML
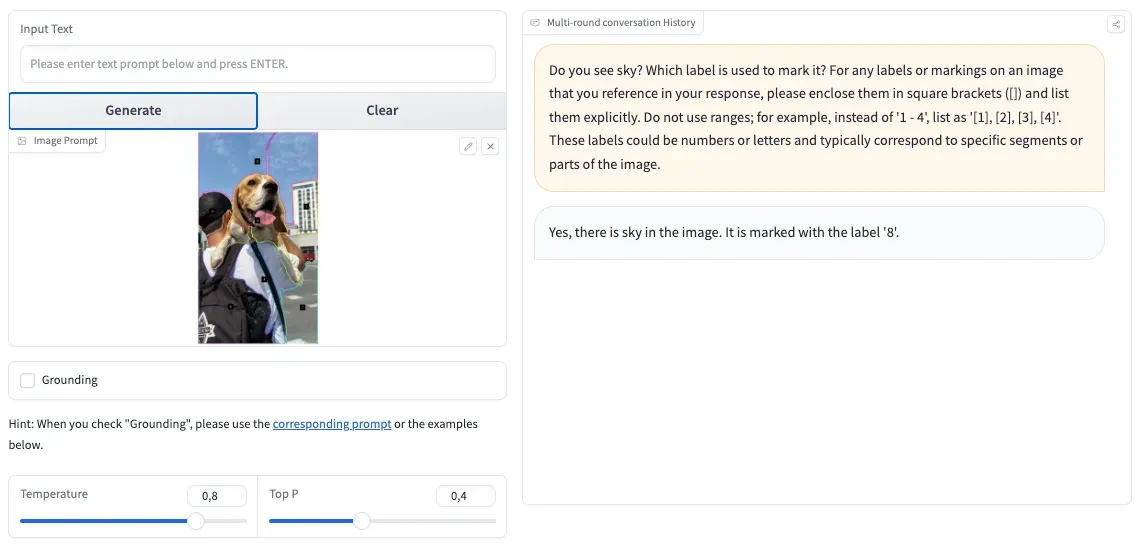
OpenAI's GPT-4 Vision is the most recognized among LMMs but there are other options. Our latest blog post explored four prominent alternatives to GPT-4V: LLaVA, BakLLaVA, Qwen-VL, and CogVLM. CogVLM emerged as a strong contender, demonstrating impressive capabilities in Visual Query Language (VQL), Optical Character Recognition (OCR), and zero-shot detection, rivaling GPT-4.
We decided to test whether CogVLM could use marks generated by Multimodal Maestro, and the results exceeded our expectations.
Conclusions
LMMs can do a lot more than we thought. However, there is a lack of a convenient interface for us to communicate with them.
In the coming weeks, we will add more strategies to Multimodal Maestro to use LMM more effectively. Stay tuned and star the repository to follow our progress. New features – and prompts – are coming soon!
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Nov 29, 2023). Multimodal Maestro: Advanced LMM Prompting. Roboflow Blog: https://blog.roboflow.com/multimodal-maestro-advanced-lmm-prompting/