
Deep learning has transformed computer vision over the last decade. Tasks that once required training custom neural networks from scratch, taking months of data collection and computing, can now be achieved by reusing pre-trained models. Pre-trained models are models that have already learned useful patterns from massive and diverse datasets, and they serve as ready-to-use building blocks for a wide range of vision problems.
Instead of beginning model training with a blank neural network, a pre-trained backbone or a task-specific model can be used to train a task specific model. This shift has unlocked enormous efficiency. What used to be a research-only capability is now accessible to startups, researchers, and engineers.
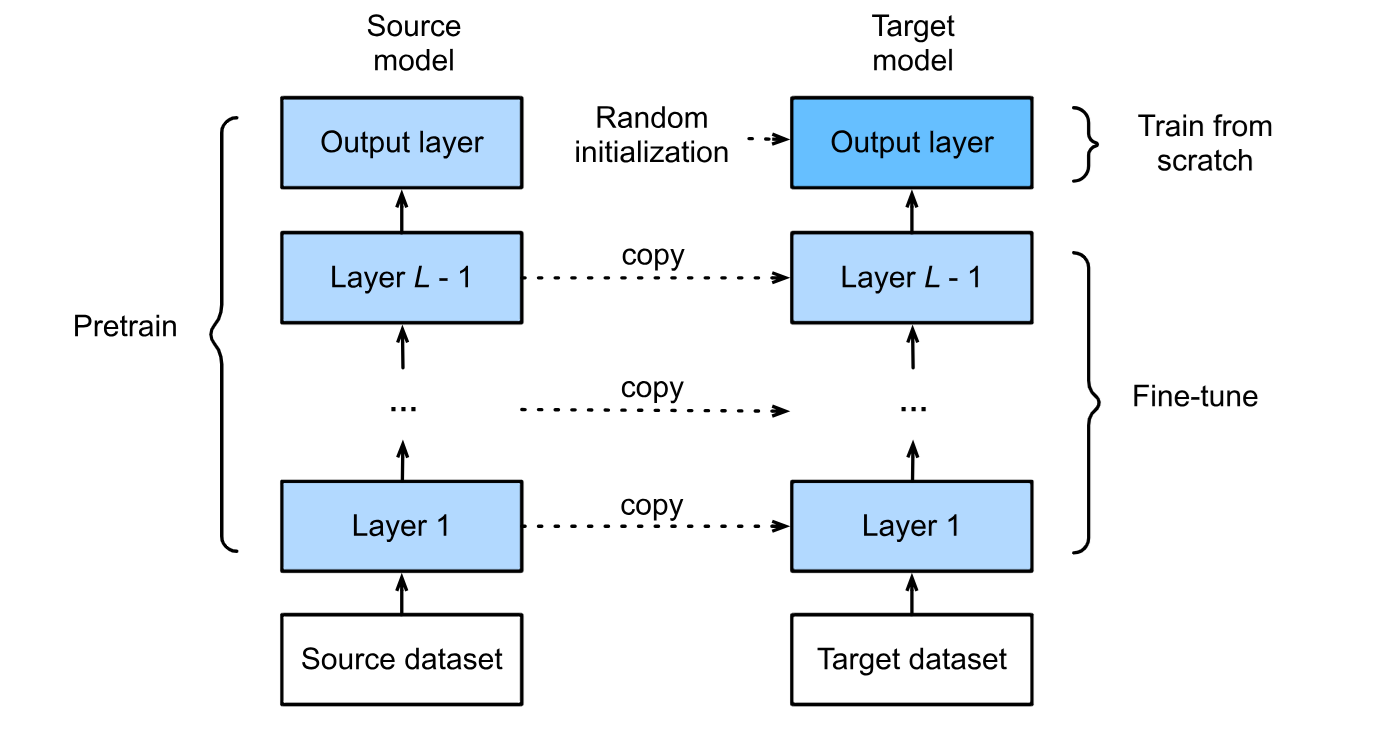
The above figure depicts two important processes in terms of pre-trained models i.e. pre-training and fine-tuning. Where:
- Pre-training means training a model on a large, general dataset first so that it can learn useful features (like shapes, patterns, or language structures). This gives the model a strong starting point instead of beginning from scratch.
- Fine-tuning happens after pre-training. The model is then trained further on a smaller, task-specific dataset so it can adapt those general features to the new problem. In other words, pre-training teaches the “basics,” and fine-tuning specializes the model for the exact task you care about.
Importantly, pre-trained models are not limited to particular computer vision tasks. Today, you can find state-of-the-art pre-trained models for image classification, object detection, semantic and instance segmentation, monocular depth estimation, vision–language models (VLMs), keypoint estimation, and even multimodal reasoning systems that combine text, images, and video.
This blog explores what pre-trained models are, why they are so powerful, and highlights some of the most popular models. We also share tips for using them effectively across different vision tasks.
So, let’s get started.
What Are Pre-Trained Models?
A pre-trained model is a neural network that has already been trained on a large, general dataset and then released for reuse. Instead of learning from scratch, you inherit the knowledge embedded in its weights i.e. the patterns, representations, and features it has already discovered.
For example, models trained on broad image datasets (e.g., ImageNet, COCO) learn to detect edges, textures, shapes, and object structures. Others models like CLIP, are trained jointly on billions of images paired with text, giving them the ability to connect visual and language concepts. Models like Segment Anything 2 have been trained on millions of masks to generalize across segmentation tasks.
This pre-training process turns them into universal feature extractors or even complete solutions for specific tasks. Once trained, these models can be used in two ways;
- Feature extraction: Freeze most of the pre-trained network and only train a lightweight, task-specific head (e.g., a new classification layers, detection heads, or segmentation decoders). This approach uses pre‑trained feature extractor and is particularly useful when you have limited data or computational resources.
- Fine Tuning: Start with the pre-trained weights but allow more (or all) of the layers to update when training on your dataset. Fine-tuning significantly improves the model’s performance to specialized or domain specific tasks but requires more data and careful training strategies to avoid overfitting while preserving the valuable learned representations.
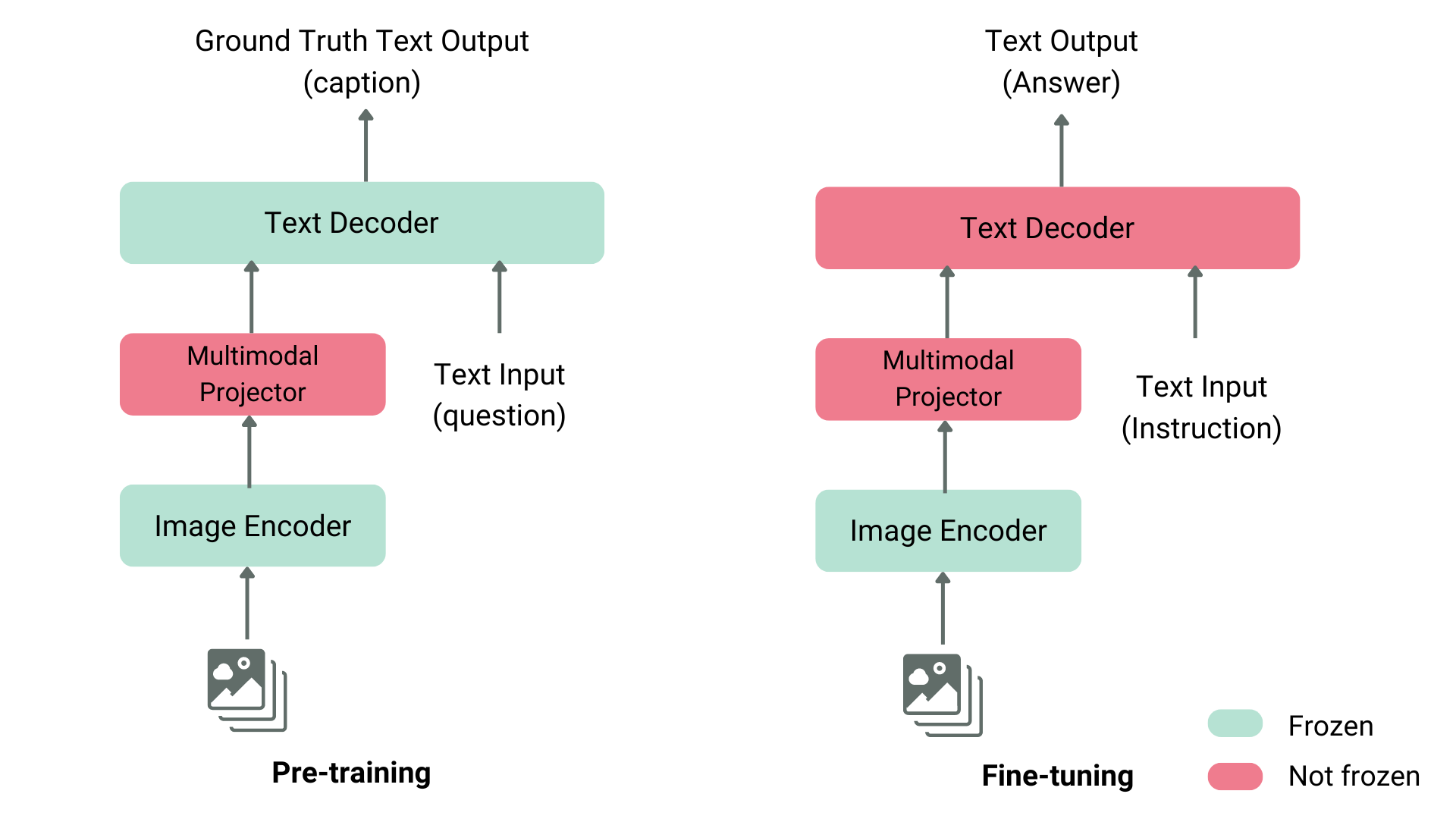
Because the heavy lifting of representation learning has already been done, pre-trained models save time, reduce compute costs, and often achieve higher accuracy than models trained from scratch. There are various pre-trained models available for variety of computer vision tasks such as classification, detection, segmentation, multimodal reasoning, and other vision tasks that are now core to applied AI.
Benefits of Using Pre-Trained Models in Computer Vision
Following are the important benefits of using pre-trained models in a computer vision project:
Reduced Training Time
Pre-trained models already understand a wide range of visual patterns (edges, textures, object parts, shapes, and even cross-modal cues in VLMs). Instead of training a full network from scratch, you often only need to adapt a smaller task-specific head or fine-tune selected layers. This cuts training time from weeks or months down to hours or days.
Lower Data Requirements
Because the base model has already learned general visual representations, it requires far fewer labelled samples for target tasks. This is important in domains like medical imaging, industrial inspection, or aerial surveys, where annotated data is limited or expensive to collect.
Improved Accuracy and Robustness
Models pre-trained on massive, diverse datasets capture broad visual knowledge, which helps them generalize well on new tasks. Starting from pre-trained weights usually yields higher accuracy and more stable results than training the model from scratch.
Efficient Use of Compute and Storage
Pre-training offloads the heavy computational cost onto large labs or communities. The weights from these pre-trained models can be re-used. Many architectures (e.g., EfficientNet, MobileNetV2 etc.) are optimized for edge devices while still gives the benefits of large-scale pre-training, making them practical for IoT and edge deployments.
Transferability Across Tasks
A strong pre-trained backbone can serve as the foundation for multiple downstream tasks. For example, a ResNet backbone trained on ImageNet is used not only for classification but also as the feature extractor in Faster R-CNN for object detection, Mask R-CNN for segmentation, and even pose estimation models. Similarly, VLMs like CLIP or Florence-2 can be adapted for retrieval, captioning, or grounding tasks.
Faster Prototyping and Experimentation
Pre-trained models make it easy to test new ideas quickly. You can plug them into a workflow (e.g., detection + depth estimation + segmentation) and immediately start experimenting, instead of waiting weeks for a model to converge from scratch.
Community Support and Ecosystem
Many pre-trained models are released with robust tooling, documentation, and model zoos (PyTorch Hub, TensorFlow Hub, HuggingFace). This ecosystem accelerates adoption, ensures reproducibility, and provides a starting point for further innovation.
Top Pre‑Trained Models in Computer Vision
Here are some of the most widely used pre‑trained models. For each model we provide a brief description, a citation to the original paper or an authoritative source, approximate size (number of parameters), typical license, major tasks it is used for and link to fine tuning guides.
RF‑DETR
RF‑DETR is a transformer‑based object detector designed by Roboflow. It seeks to combine the speed of one‑stage detectors with the accuracy of transformer architecture. RF‑DETR achieves over 60 average precision (AP) on the Microsoft COCO benchmark and is small enough to run on edge devices. Following are the key details about RF-DETR:
- Variants: RF‑DETR has two main variants, a base model (29 M parameters) and a large model (128 M parameters).
- Tasks. RF‑DETR performs bounding‑box object detection on images and videos. Because it is based on a transformer architecture, the model can generalize across domains and tasks.
- License: The model is released under the Apache 2.0 licence, facilitating commercial and research use.
- Pre-training: RF‑DETR is trained on large datasets such as COCO and RF100‑VL dataset, producing weights that can be used out‑of‑the‑box or fine‑tuned for specific applications. The model’s open weights and licensing allow researchers to use it as a starting point for new detection tasks.

YOLOv12
YOLOv12 is the latest version of the “You Only Look Once” family of real‑time detectors. YOLOv12 architecture uses attention‑centric detector that introduces a new area‑attention mechanism, Residual Efficient Layer Aggregation Networks (R‑ELAN) and optimized attention blocks. These innovations allow the model to process large receptive fields efficiently while preserving real‑time performance. Following are the key details about YOLOv12:
- Variants: YOLO12n through YOLO12x for classification, object detection and instance segmentation. Each balancing speed and accuracy.
- Tasks. YOLOv12 supports a wide range of computer‑vision tasks such as object detection, instance segmentation, image classification, pose estimation, and oriented bounding‑box detection.
- License: software is licensed under GNU AGPL‑3.0.
- Pre‑training: The model is trained on large datasets such as MS COCO and released with weights so developers can fine‑tune it for domain‑specific detection. Because of the strong AGPL license, derivative works distributed to others must also be open‑sourced.

Research Paper/Source: YOLO12: Attention-Centric Object Detection
Fine Tuning: How to Train a YOLOv12 Object Detection Model on a Custom Dataset
PaliGemma 2
PaliGemma 2 is Google’s open vision‑language model based on SigLIP for vision and Gemma 2 language models. PaliGemma 2 takes both images and text as input and can answer questions about images, generate captions, perform object detection and segmentation, and read text embedded in images. Pali Gemma 2 uses a Transformer decoder initialized from Gemma 2 and a Vision Transformer image encoder initialized from SigLIP. Following are the key details about PaliGemma 2:
- Variants: PaliGemma 2 is available in 3 B, 10 B and 28 B parameter sizes and resolutions (224px, 448px, 896px).
- Tasks. PaliGemma 2 excels at image captioning, visual question answering (VQA), object detection, segmentation and reading text (OCR). It outputs text responses, bounding boxes or segmentation codewords, enabling open‑vocabulary detection.
- License: The license for PaliGemma 2 is the Gemma license (a permissive open license requiring attribution), and the page content is under CC BY‑4.0 with code samples under Apache 2.0.
- Pre‑training: Pali Gemma 2 is pre‑trained on large multimodal datasets including WebLI, CC3M‑35L, OpenImages and other multilingual image‑text corpora. This pre‑training yields strong visual and linguistic representations that can be adapted via supervised fine‑tuning for specific tasks. Because the weights are open, researchers can download and fine‑tune them without training from scratch.

Research Paper/Source: PaliGemma 2: A Family of Versatile VLMs for Transfer
Fine Tuning: How to Fine-tune PaliGemma 2
Florence‑2
Florence‑2 is a vision‑language foundation model developed by Microsoft and released in June 2024. Florence‑2 uses a sequence‑to‑sequence prompt‑based representation to support tasks such as captioning, object detection, grounding and segmentation. It is trained on the FLD‑5B dataset (5.4 billion visual annotations across 126 million images) collected via automated annotation and iterative model refinement. Florence‑2 is a lightweight vision‑language model released under the MIT license and demonstrates strong zero‑shot and fine‑tuning capabilities. Following are the key details about Florence-2:
- Variants: Florence-2 comprised two model variants, Florence-2-Base (232 million parameters) and Florence-2-Large (771 million parameters).
- Tasks. Because of its prompt‑based design, Florence‑2 can perform dense captioning, open‑vocabulary detection, grounded text generation, object detection, segmentation, phrase grounding, OCR, region proposal etc. via a single interface. The large training dataset enables good generalization even in zero‑shot settings. Fine‑tuning can further improve performance on domain‑specific tasks.
- License: Florence-2 uses an MIT license.
- Pre‑training: The massive FLD‑5B dataset allows Florence‑2 to learn a generalized mapping between images and textual descriptions. The MIT license encourages community adoption and researchers can fine‑tune or extend the model while retaining open‑source status.

Research Paper/Source: Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Fine Tuning: How to Fine-tune Florence-2 for Object Detection Tasks
Segment Anything 2 (SAM 2)
SAM 2 is Meta’s successor to the Segment Anything Model, released in July 2024 and updated to version 2.1 in February 2025. SAM 2 is a unified model for real‑time, prompt‑based segmentation and tracking in images and videos. It combines an image/video encoder, a prompt encoder, a memory mechanism and a mask decoder to handle occlusions and long videos. It is trained on SA‑V dataset consisting of 51 k videos and 600 k patio-temporal "masklet" annotations, specifically designed to advance general-purpose object segmentation in open-world videos. Following are the key details about SAM 2:
- Variants: SAM 2 has four variants Tiny (38.9M), Small (46M), Base Plus (b+) (80.8M), Large (224.4M).
- License: The dataset is available under the permissive CC BY 4.0 license.
- Tasks. SAM 2 performs promptable segmentation. Given an image or video plus a user prompt (points, bounding box or mask), the model returns accurate instance masks. It supports video segmentation, object tracking, interactive segmentation and can handle previously unseen domains (zero‑shot generalization).
- Pre‑training: By training on millions of mask annotations (the SA‑V dataset), SAM 2 learns to generalize across object categories without class labels. The open weights allow practitioners to integrate segmentation into pipelines or fine‑tune the model for specialized domains. The permissive license supports commercial use.
SAM 2 Examples
Research Paper/Source: SAM 2: Segment Anything in Images and Videos
Fine-Tuning: How to Fine-Tune SAM-2.1 on a Custom Dataset
Gemini
Gemini is Google’s family of multimodal large language models. It is the successor to PaLM 2 and combining ideas from PaLM (large language models) and Flamingo (vision–language models). It’s designed to work across text, images, audio, video, and code in a single unified framework. The latest Gemini 2.5 includes Gemini 2.5 Pro, 2.5 Flash and 2.5 Flash‑Lite. The models accept audio, images, video and text inputs and return text responses. Gemini 2.5 Pro is Google’s most powerful thinking model with maximum response accuracy and state‑of‑the‑art performance. Flash focuses on price‑performance and Flash‑Lite is optimized for cost efficiency and low latency. Gemini 2.5 Pro has enhanced reasoning and coding capabilities and a 1 million‑token context window. Gemini models are proprietary and made available through API subscription, no open weights are provided. Following are the key details about Gemini:
- Variants: Gemini 2.0 (Flash/Flash-Lite), and Gemini 2.5 (Pro/Flash/Flash-Lite).
- License: Gemini Code Assist Standard.
- Tasks. Gemini models perform text generation, coding assistance, multimodal reasoning, image interpretation, audio and video comprehension and long‑context document analysis. Because they are multimodal, they support interleaved inputs users can combine text, images, video and audio in any order. Some variants (e.g., Gemini 2.5 Pro and Flash) can also output audio.
- Pre‑training: Gemini models are trained on extremely large multimodal corpora (web documents, books, code, images, audio and video). They serve as proprietary foundation models that power Google’s AI products. Fine‑tuning for domain‑specific tasks occurs internally at Google or via the Vertex AI platform. End users access them via API rather than downloading weights.

Research Paper/Source: Gemini: A Family of Highly Capable Multimodal Models
Fine Tuning: Tune Gemini models by using supervised fine-tuning
LLaMA 3.2-Vision
LLaMA 3.2-Vision is a vision–language model (VLM) from Meta’s LLaMA 3.2 family. It extends the LLaMA 3.2 language model with multimodal capabilities by integrating a visual encoder into the transformer architecture. The model supports both image and text inputs, enabling tasks that combine visual reasoning with natural language understanding. Following are the key details about LLaMA3.2-Vision:
- Variants: LLaMA 3.2-Vision is released in parameter scales of 11 B Vision (a compact variant suited for many vision-language tasks0 and 90 B Vision (a larger version for more complex and demanding scenarios).
- License: Released under the Meta LLaMA Community License. This license allows for research and commercial use with certain restrictions (e.g., safety and compliance conditions).
- Tasks: LLaMA 3.2-Vision supports a wide range of vision-language tasks, including image captioning, visual question answering (VQA), chart and diagram interpretation, OCR and document understanding (forms, tables, receipts), grounding (object localization with bounding boxes or coordinates), reasoning across text + images (science diagrams, math word problems), multimodal dialogue (describing images in natural conversation). The model accepts images + text as input and produces textual outputs, with optional structured predictions (bounding boxes, regions, etc.).
- Pre-training: Trained on a large multimodal corpus including web image–text pairs, curated document datasets, and structured visual reasoning corpora. The architecture combines a frozen ViT encoder (for image feature extraction) with a LLaMA 3.2 decoder for unified reasoning. It ues contrastive alignment, instruction tuning on multimodal tasks, and reinforcement learning from human feedback (RLHF) to align outputs for conversational settings.
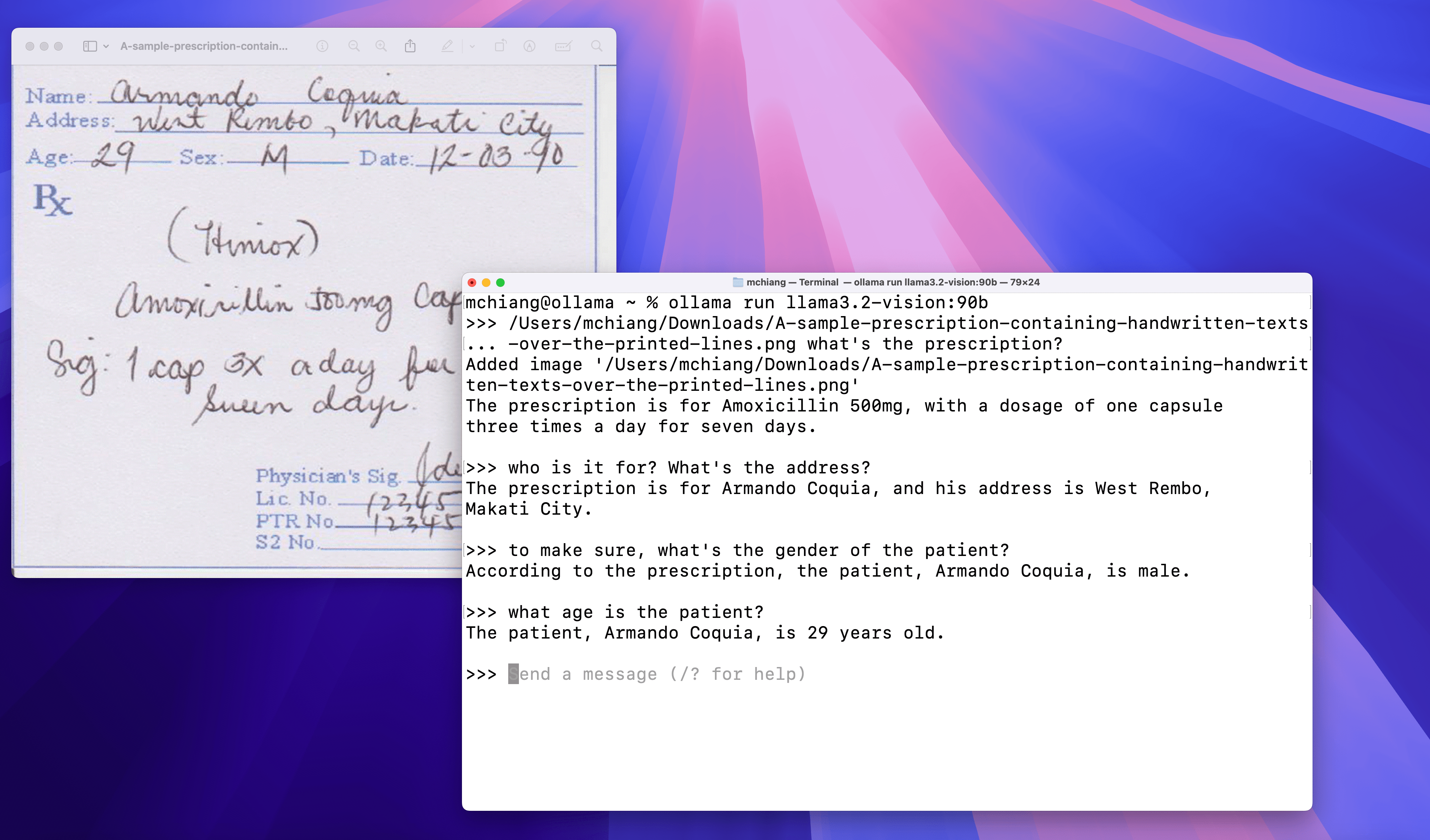
Research Paper/Source: Llama 3.2 Vision Page
Fine Tuning: Fine-tuning Llama 3.2 Vision using Trainer
Qwen 2.5‑VL
Qwen 2.5‑VL is a vision‑language model from Alibaba’s Qwen series. It as a “flagship” model that features dynamic‑resolution processing and absolute time encoding to support images and videos of varying sizes. Qwen 2.5‑VL excels at visual recognition, object localization, document parsing and long‑video comprehension, and it can act as a visual agent by performing tool‑use and task execution. Following are the key details about Qwen 2.5-VL:
- Variants: Qwen 2.5‑VL is available in 3 B, 7 B and 72 B parameter sizes and can analyze charts, icons and generate structured outputs from invoices, forms and tables.
- License: The model is released under the Apache 2.0 license.
- Tasks. Qwen 2.5‑VL supports a wide spectrum of tasks such as image captioning, visual question answering, chart and diagram analysis, document OCR and form understanding, video understanding and agentic tasks such as interacting with a computer or mobile. The model accepts images, text and long videos as input and produces text responses. It can also output bounding boxes or points when requested. Its dynamic resolution training ensures efficient inference on both low‑ and high‑resolution media.
- Pre‑training: Qwen 2.5‑VL is trained on large multi‑modal corpora and incorporates a dynamic ViT (Vision Transformer) backbone. The authors distill and fine‑tune the model to produce three sizes for different compute budgets. The open Apache 2.0 license encourages adaptation and fine‑tuning for industrial applications.

Research Paper: Qwen2.5-VL Technical Report
Fine Tuning: Fine-Tune and Deploy Qwen2.5-VL Models with Roboflow
Depth Anything V2
Depth Anything V2 is a foundation model for monocular depth estimation presented at NeurIPS 2024. The model was trained using synthetic data along with pseudo-labeled real images, it’s more than 10× faster and more accurate than Stable Diffusion-based alternatives. Following are the key details about Depth Anything V2:
- Variants: DepthAnything V2 has four variants Depth-Anything-V2-Small (24.8M), Depth-Anything-V2-Base (97.5M), Depth-Anything-V2-Large (335.3M). The variant Depth-Anything-V2-Giant (1.3B) is not released yet.
- License: The model was released under an Apache 2.0 license.
- Tasks. Depth Anything V2 takes a single image as input and predicts a dense depth map. The pre‑trained models can be used for robotic navigation, 3D scene reconstruction, autonomous driving, AR/VR and relighting tasks. Fine‑tuning with metric depth labels can convert the relative‑depth models to metric‑depth models.
- Pre‑training: Training depth models from scratch typically requires large amounts of metric depth data, which is expensive. By pre‑training on synthetic and pseudo‑labelled data, Depth Anything V2 provides strong depth representations that can be fine‑tuned with a small amount of real depth data to achieve high accuracy.
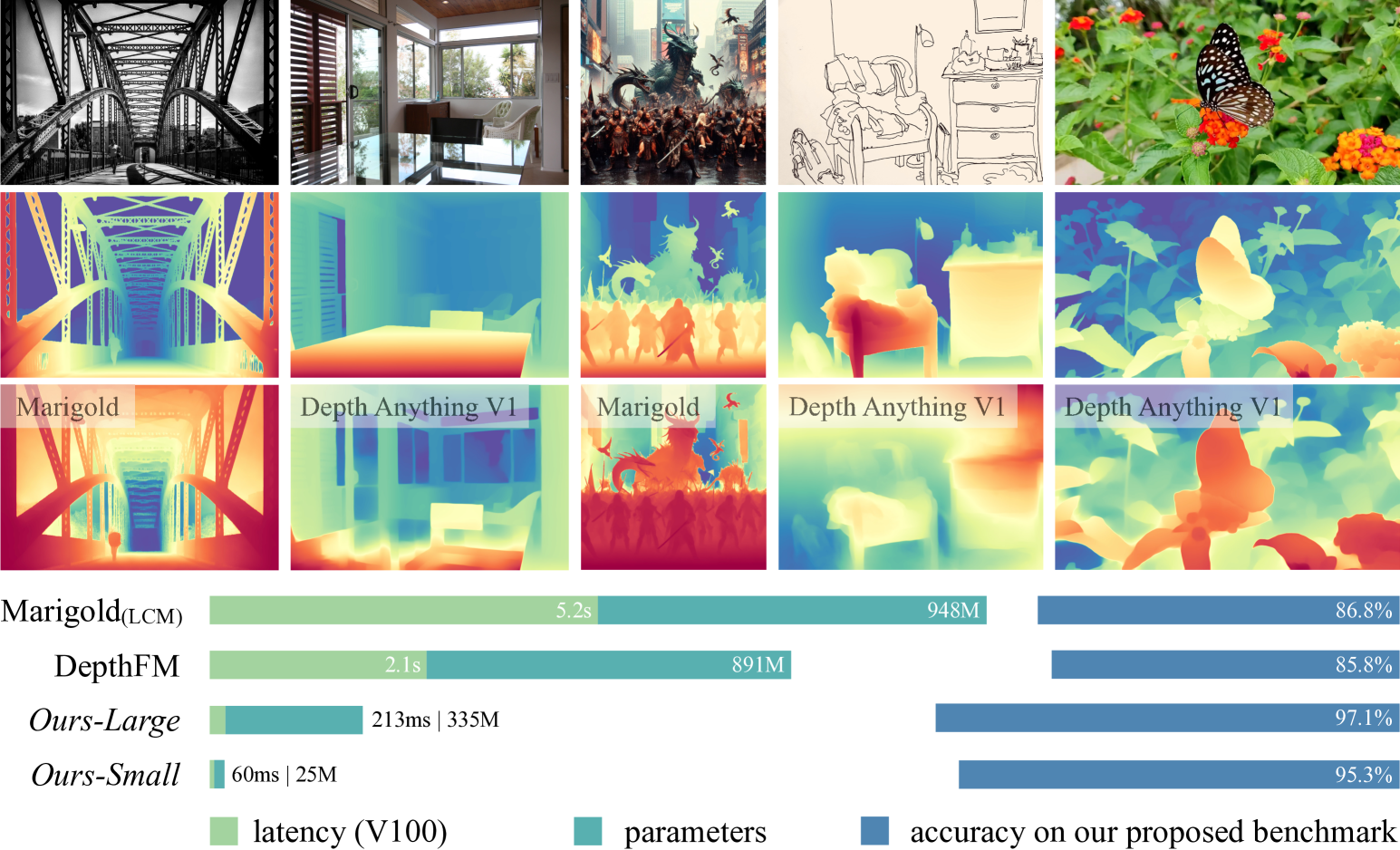
Research Paper/Source: Depth Anything V2
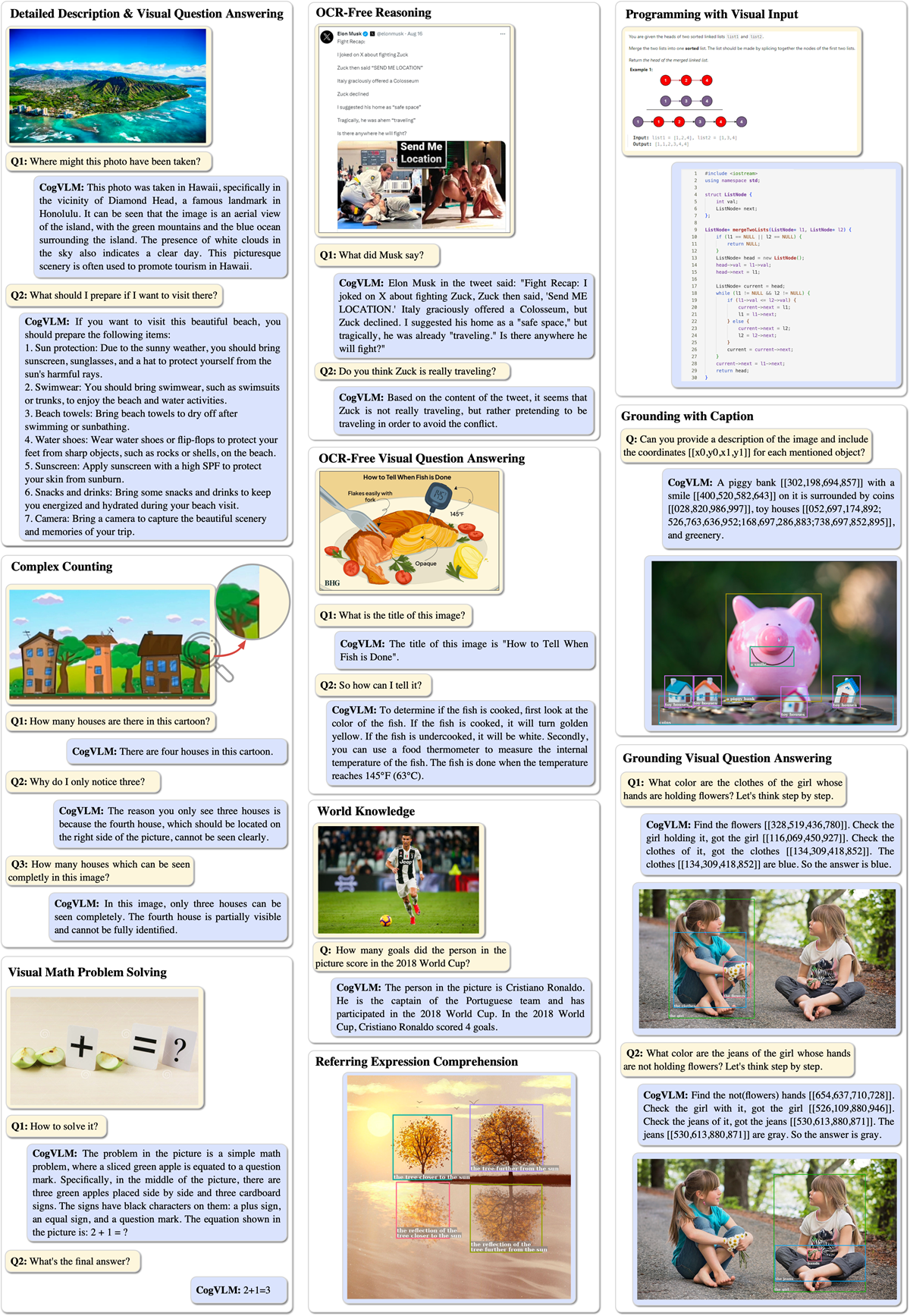
CogVLM
CogVLM is an open-source visual language foundation model developed by researchers from Shanghai AI Lab and Tsinghua University. It goes beyond basic shallow integration of vision and language by introducing a trainable visual expert module inside the transformer layers of a frozen language model. This design enables deep fusion of visual and language features while preserving strong NLP abilities and it boosts cross-modal performance. CogVLM and CogVLM2 can be deployed on edge hardware and that quantization allows 4‑bit versions to run on a NVIDIA T4 GPU. Following are the key details about CogVLM:
- Variants: CogVLM has two variants CogVLM (17 B total parameters: 10 B vision + 7 B language) and CogVLM2, which adds 2 B parameters and is based on Llama-3-8B-Instruct.
- License: CogVLM2 is licensed under the Apache License 2.0.
- Tasks. CogVLM supports image captioning, visual question answering, OCR/document understanding, chart analysis, visual grounding and open vocabulary detection.
- Pre‑training: CogVLM is trained on large image–text datasets and integrates a vision encoder and language model via a trainable visual expert module. The pre‑trained weights provide strong multimodal capabilities that can be fine‑tuned for specific applications. The Apache 2.0 license allows broad use, including commercial projects.
Research Paper/Source: CogVLM: Visual Expert for Pretrained Language Models
Tips For Using Pre‑Trained Models
Given the diversity of models above, selecting and using a pre‑trained model requires strategic consideration. The following tips can help:
Define your task and modality
Determine whether you need object detection, segmentation, depth estimation, language generation, or multimodal reasoning. Vision tasks alone may benefit from models like RF-DETR, YOLOv12 or SAM 2, whereas multimodal tasks might require PaliGemma 2, Qwen2.5‑VL, CogVLM or Gemini.
Choose the appropriate model size
Larger models generally achieve better accuracy but require more compute. For edge deployment or limited resources, select small variants but for high‑performance servers you can consider using large variants (Gemini Ultra, CogVLM‑17B, Pali Gemma 28B).
Understand license requirements
Understanding licensing is very important. Open‑source licenses (Apache 2.0, MIT) permit modification and redistribution. Proprietary models Gemini restrict how you can use the model and may incur usage fees. Ensure compliance with model licences and any separate licences for weights (e.g. CogVLM Model License).
Fine‑tuning vs. zero‑shot
Some models (Florence‑2, Segment Anything 2) deliver strong zero‑shot performance, making them suitable for tasks where labelled data is scarce. Others benefit from fine‑tuning on domain‑specific data (e.g. RF-DETR for custom object detection). Use techniques like transfer learning, LoRA (Low‑Rank Adaptation) or adapters to efficiently fine‑tune large models.
Consider input constraints
Multimodal models may have limits on sequence length or resolution. Qwen2.5‑VL uses dynamic resolution to handle different image sizes, while PaliGemma 2 requires images at the pre‑training resolutions (224-896 px). Ensure your inputs match the model’s expectations.
Monitor ethical and safety considerations
Pre‑trained models may inadvertently learn biases. Evaluate your application for fairness and safety. For generative models (Gemini), implement content filters and human oversight, particularly in sensitive domains like healthcare.
Stay informed about updates
The model landscape evolves rapidly. For example, Depth Anything V2 supersedes V1 with improved training and performance. Keeping abreast of new releases ensures you deploy state‑of‑the‑art models.
Using Pre-Trained Models in Roboflow Workflows
In this example, we will explore how to use pre-trained models within a Roboflow Workflow by building an automated book inventory system. The Workflow will begin with the RF-DETR model, which detects the book placed on a desk. After detection, we will crop the book region, since there may be other objects present and we only want to focus on the book. This step ensures that only the relevant portion of the image is passed forward for processing. Next, we will use the LLaMA 3.2 Vision model to extract the book’s details in a structured JSON format. These extracted details can then serve as input for a book inventory application or database.
The Roboflow Workflow can be created as follows:
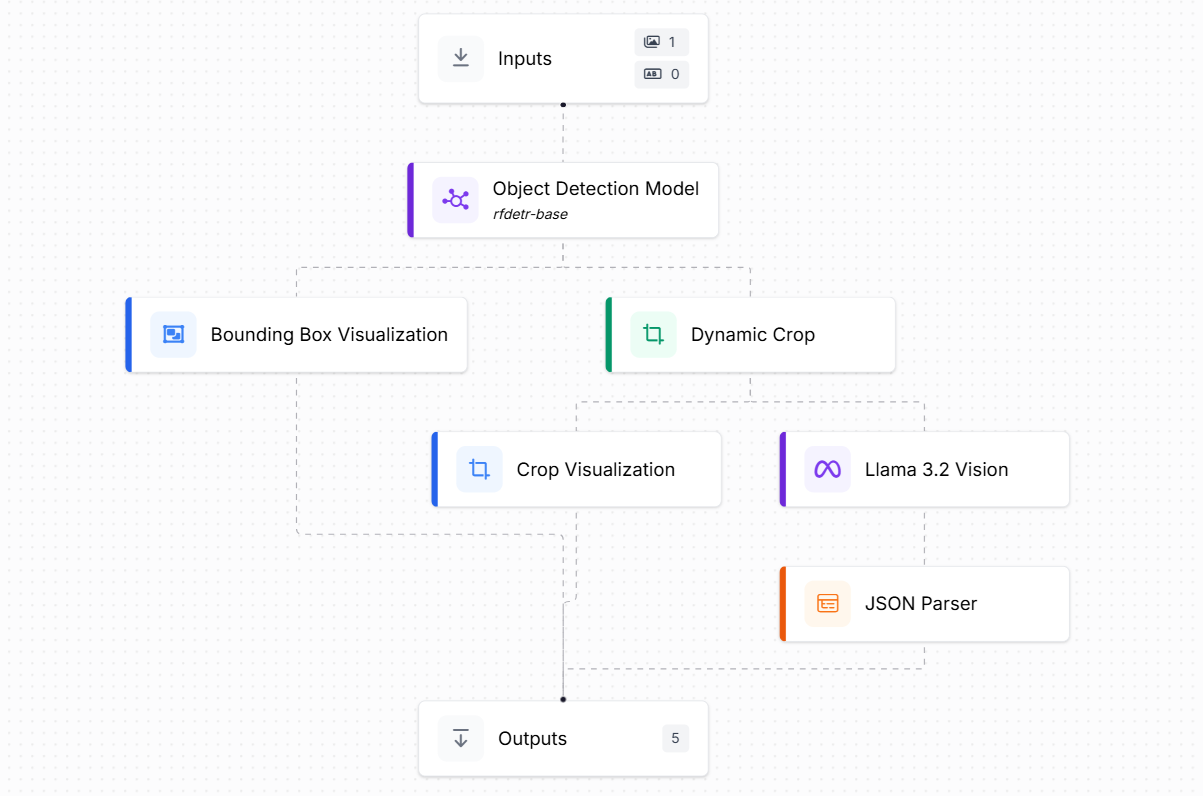
The Workflow accepts an input image and consists of following main parts:
- Object Detection Model (rf-detr-base) Block: This block uses the RF-DETR model to detect the location of books in the input image. The model outputs a bounding box around the detected book(s). This step is crucial because the image may have other items on the desk, and we only want to focus on the book. FOr this block set the "class filter" property to book.
- Bounding Box Visualization Block: This block visually displays the bounding box around the detected book. It’s mainly for debugging and human verification, showing where the model thinks the book is.
- Dynamic Crop Block: This block takes the bounding box from the object detection step and crops the detected region. This ensures that only the book area is passed forward, ignoring irrelevant background or other objects.
- Crop Visualization Block: It displays the cropped image of the book. Again, this is a helpful checkpoint for verifying that the cropping worked correctly before further processing.
- LLaMA 3.2 Vision Block: The cropped book image is sent to LLaMA 3.2 Vision, a vision-language model. This model analyzes the image of the book and extracts structured details (e.g., title, author, publisher etc.). The output is text, usually in structured form like JSON. This block must be configured for “Structured Output Generation” as below:
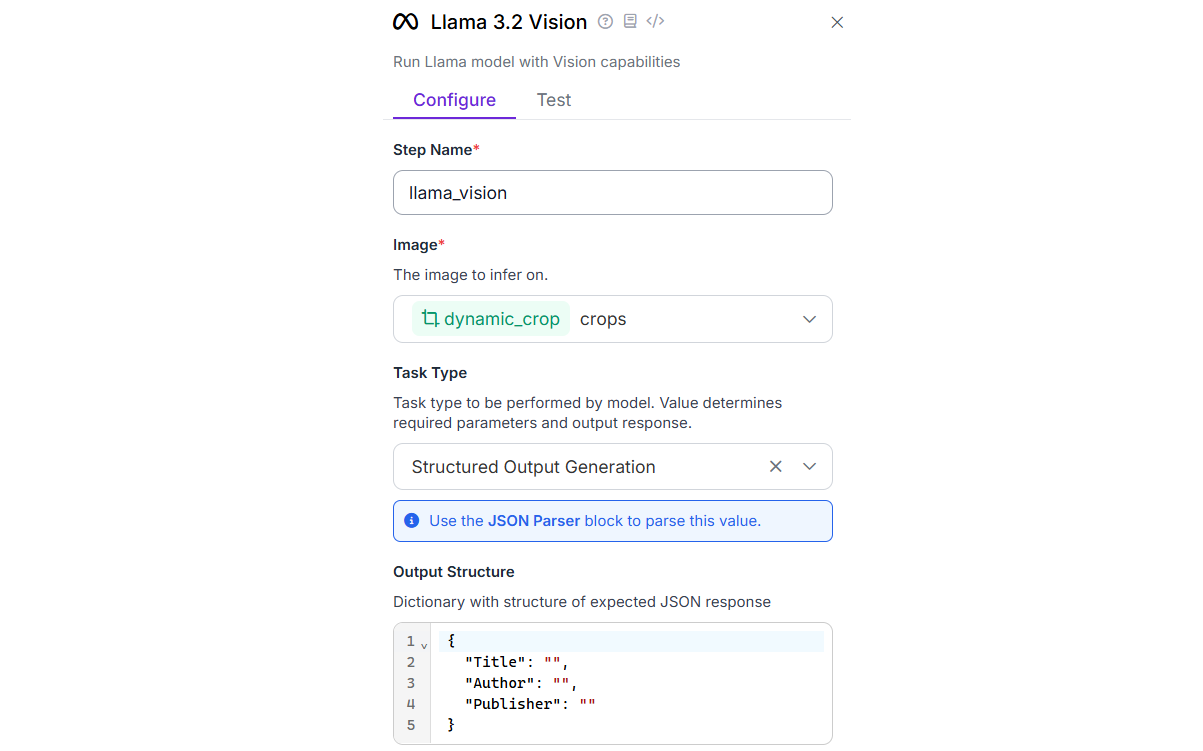
- JSON Parser Block: This block takes the structured output from LLaMA 3.2 Vision and converts it into a JSON format that can be easily integrated with software or a database.
Running the above workflow on following input image:

Will generate following JSON output text.
"json_parser": [
{
"Title": "AI and Machine Learning for Coders",
"Author": "Laurence Moroney",
"Publisher": "O'Reilly",
"error_status": false
}
],This makes the workflow practical for automated systems (like a book inventory system).
Pre-Trained Models Conclusion
Pre‑trained models have become the backbone of modern computer vision and multimodal systems. By training on large datasets, these models learn rich representations that generalize across tasks, enabling developers to achieve high performance even with limited labelled data. We learned the models from RF‑DETR for real‑time detection to PaliGemma 2 and Qwen 2.5‑VL for vision–language understanding, and Gemini for full multimodality demonstrate the diversity and rapid advancement of pre‑trained architectures. Careful consideration of model size, licensing and task requirements allows to select the right foundation model and build powerful AI applications efficiently.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Aug 25, 2025). Pre‑Trained Models in Deep Learning. Roboflow Blog: https://blog.roboflow.com/pre-trained-models/