
CNNs and Vision Transformers represent two fundamentally different ways of understanding images, and the right choice can dramatically affect accuracy, speed, and deployment performance. This guide explains their strengths, trade-offs, and real-world performance for detection, and shows you how to evaluate both inside Roboflow so you can confidently select the right model for your application.
CNNS vs. ViTs
Convolutional Neural Networks (CNNs) have been the foundation of computer vision for many years. They powered most object detection models we rely on today, from early R-CNN systems to fast real-time detectors like YOLO and SSD. CNNs work well because they use local filters, weight sharing, and translation equivariance to learn visual patterns efficiently.
The introduction of the Vision Transformer (ViT) changed the detection landscape. Instead of using convolutions, ViTs rely on self-attention, a mechanism adapted from natural language processing (NLP). This allows the model to capture global context across an image from the very first layer, something CNNs build up gradually through deeper layers.
Convolutional Neural Networks (CNNs)
A CNN applies convolutional filters, activation functions, and pooling operations across an image to build feature maps that represent edges, textures, shapes, and eventually complete objects. Early layers capture simple patterns, while deeper layers combine these into increasingly complex structures. Toward the end, fully connected layers use these features to make predictions. CNNs often include Batch Normalization and Dropout to stabilize training and reduce overfitting. Their structure (local receptive fields, hierarchical feature learning, and efficient computation) makes them fast, reliable, and well-suited for many object detection tasks.
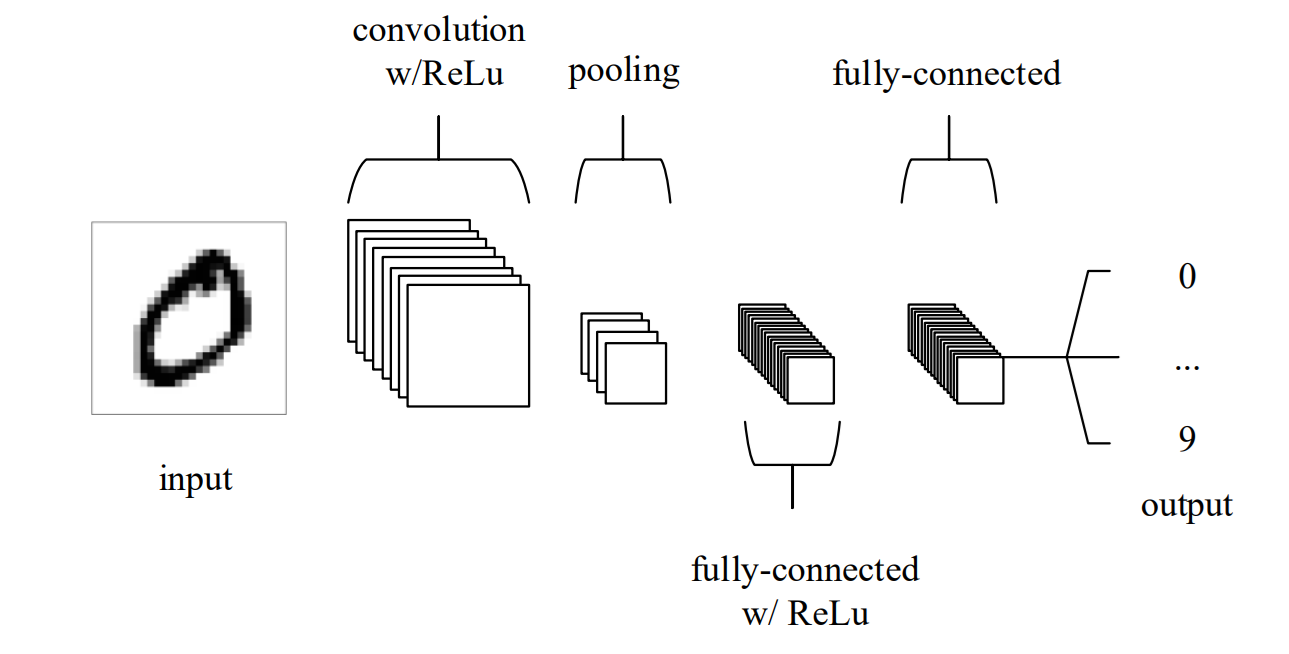
Key Features of CNNs
- Local Receptive Fields: CNNs examine small regions of the image at a time, efficiently learning local patterns like edges, corners, and textures.
- Weight Sharing: The same convolutional filter is applied across the entire image, drastically reducing parameters and computational cost.
- Translation Equivariance: If a pattern in the image moves, the activation pattern in the feature map moves by the same amount. This helps the model recognize objects consistently regardless of where they appear in the image.
- Hierarchical Feature Learning: Features build progressively, from simple edges in early layers to object parts in middle layers to complete objects in deeper layers.
- Hardware Efficiency: CNNs run efficiently on GPUs, mobile processors, and embedded devices due to highly optimized convolution operations.
- Strong Inductive Biases: CNNs assume spatial locality (nearby pixels are related) and use weight sharing, enabling good performance even with limited training data.
Vision Transformers (ViTs)
A Vision Transformer (ViT) is a deep learning architecture that processes images using the Transformer framework instead of convolutional filters. It splits an image into fixed-size patches, converts each patch into a token through linear embedding, and adds positional embeddings to preserve spatial information. These tokens then pass through Transformer Encoder Blocks containing Layer Normalization, Multi-Head Self-Attention, MLP layers, and residual connections.
The key innovation is self-attention: every patch can directly interact with every other patch across the entire image. For example, a patch showing a wheel can attend to distant patches showing the car's body or headlights. This allows ViTs to capture both local details and global context simultaneously, without relying on the locality assumptions built into CNNs. Stacking multiple encoder blocks enables ViTs to progressively learn rich visual patterns and understand the full scene structure.
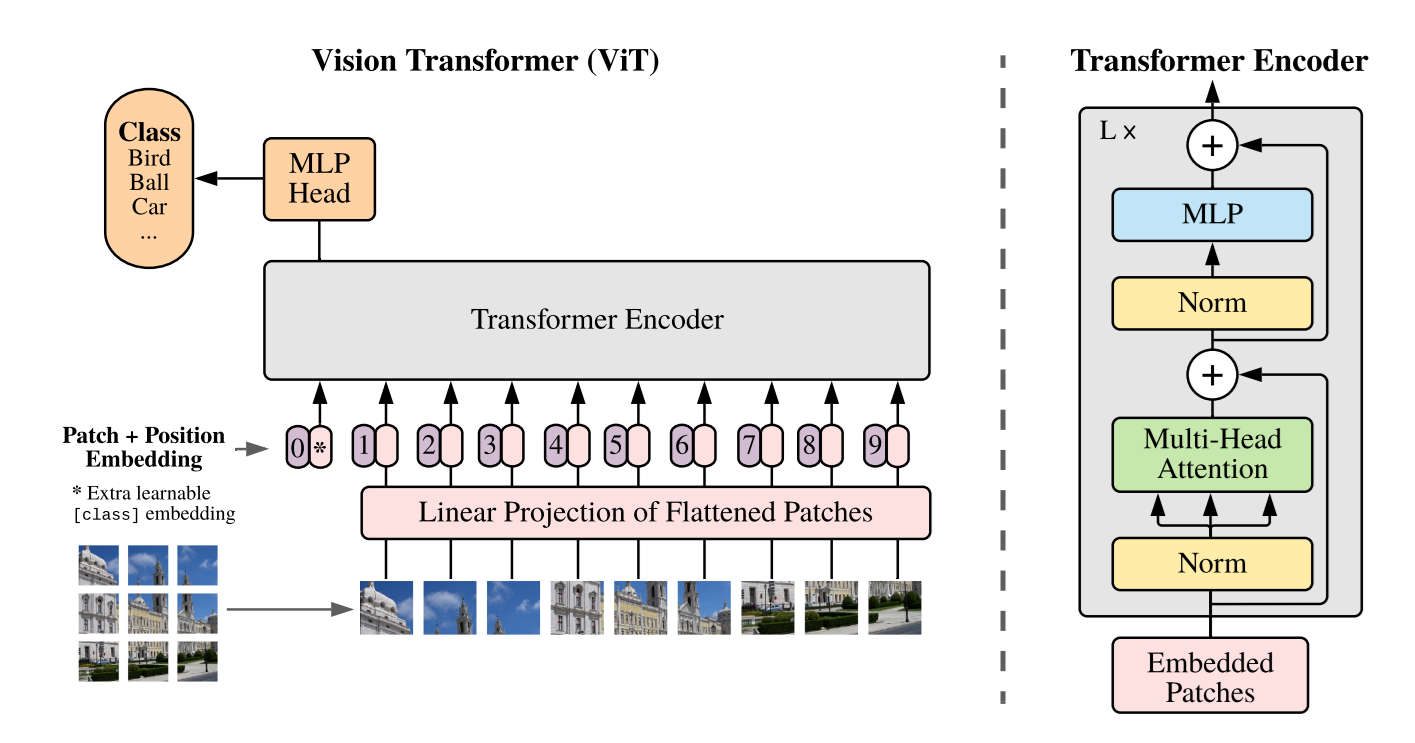
Key Features of Vision Transformers (ViTs)
- Patch-Based Processing: ViTs split images into patches and process them as sequences instead of using convolutions.
- Global Self-Attention: Every patch can interact with any other patch across the entire image.
- Long-Range Dependencies: ViTs easily connect distant image regions, useful for detecting small or spread-out objects.
- Weak Inductive Bias: ViTs learn patterns directly from data without built-in assumptions, making them flexible but data-hungry.
- Highly Scalable: Performance improves consistently with larger datasets, models, and compute resources.
- Uniform Architecture: ViTs use the same Transformer block repeatedly, making them simple to scale and modify.
- Strong Global Reasoning: ViTs excel at understanding object relationships across the whole image, especially in cluttered or complex scenes.
Comparison of CNNs and Vision Transformers
Here's how CNNs and Vision Transformers differ across key technical dimensions that matter when building and deploying object detection systems.
Architecture
CNNs use convolutional layers, pooling layers, and activation functions arranged in successive layers. Early layers identify basic features like edges and corners, while deeper layers build upon this information to detect increasingly complex features like objects. This layer-by-layer progression creates a predictable processing pipeline.
ViTs divide images into fixed-size patches treated as tokens. These pass through Transformer Encoder Blocks where self-attention lets every patch interact with every other patch simultaneously. ViTs process local details and global relationships at once. They're uniform and easier to scale but lack built-in assumptions like locality and translation equivariance.
Performance
CNNs deliver strong, reliable performance even on small datasets. This enables detectors like YOLO, SSD, and Faster R-CNN to achieve excellent accuracy-efficiency trade-offs, making them practical for production systems.
ViTs achieve higher accuracy on large datasets with strong pretraining. Their self-attention captures complex spatial relationships that CNNs might miss. ViTs outperform CNNs on benchmarks like COCO with sufficient data and compute, but require more resources during training and inference.
Data Requirements
CNNs handle limited data well because inductive biases (locality, translation equivariance, weight sharing) guide learning, making them ideal when datasets are small or annotation costs are high.
Vision Transformers need much larger datasets or strong pretraining because they do not assume any structure in the visual data. With enough data, ViTs outperform CNNs, but they struggle on small datasets.
Inference Speed
CNNs run faster because convolution operations are heavily optimized on GPUs, NPUs, and mobile processors, achieving low latency and high throughput.
ViTs are slower due to quadratic self-attention complexity with patch count. High-resolution images increase processing time significantly. Models like Swin Transformer use window-based attention to reduce cost, but ViTs still need more compute than CNNs.
However, both can be optimized. CNNs through pruning, quantization, and TensorRT. ViTs through windowed attention, knowledge distillation, patch merging, and optimized formats.
Context Understanding
CNNs focus on local details because each layer looks at small regions of the image. They learn global context gradually after many stacked layers.
ViTs capture context from the start. Their self-attention lets every patch interact with every other patch, giving the model an immediate global view of the image. This helps ViTs detect small or hidden objects and understand relationships between distant regions more effectively.
Training Stability
CNNs are easier and more stable to train due to strong inductive biases. Models like ResNet train reliably with standard optimizers (SGD, Adam) and minimal tuning.
ViTs are more sensitive, requiring learning-rate warmup, careful initialization, and strong regularization. Techniques like data augmentation, distillation, gradient clipping, and stochastic depth are often necessary, especially when training data is limited or when the model is very deep.
Transfer Learning & Pretraining
CNNs work well when you start with a model that was trained on a large dataset like ImageNet, but they usually perform best when the new task is similar to the original training data.
ViTs often transfer better to many different tasks because they learn more flexible and general features. Their global attention helps them understand shapes and relationships across the whole image, making them easier to adapt to new datasets even when the images look very different.
Robustness & Generalization
CNNs struggle when test images differ from training data. Their reliance on local textures makes them vulnerable to texture changes, lighting shifts, adversarial attacks, and pixel-level variations.
Vision Transformers are more robust. Self-attention enables shape-based reasoning instead of texture-based, handling clutter and out-of-distribution data better. However, without strong pretraining or enough data, ViTs can overfit faster. With proper pretraining, they generalize well across diverse conditions.
Model Size & Parameter Efficiency
CNNs are more parameter-efficient. Architectures like EfficientNet achieve high accuracy with relatively few parameters through compact design.
ViTs need more parameters for comparable performance when trained from scratch due to lacking inductive biases. However, pretrained ViTs scale predictably, their performance improves steadily with model size and may surpass CNNs at larger scales.
Interpretability
CNNs are easier to interpret due to their hierarchical structure: early layers detect edges, middle layers capture textures, and deeper layers recognize objects. Techniques like activation maps and Grad-CAM show which regions influence predictions.
Vision Transformers are harder to interpret because self-attention creates complex interaction patterns between patches. Attention maps reveal focus regions, and research shows attention heads often learn meaningful patterns such as object boundaries.
Computational Complexity
CNNs scale efficiently. Operations grow linearly with resolution O(H × W × C × K²). Each convolution examines small local regions, making CNNs practical for high-resolution images.
Vision Transformers have quadratic complexity O(N² × D) because every patch compares with every other patch. Higher resolution images make standard ViTs expensive. Models like Swin Transformer limit attention to local windows, reducing the cost.
Domain-Specific Performance
CNNs excel where local patterns matter: medical imaging, satellite imagery, industrial defect detection, and fine-grained classification. Local receptive fields capture subtle spatial features like textures, edges, and structural changes.
Vision Transformers perform best when global context matters: scene understanding, image captioning, multi-object tracking, and tasks requiring long-range relationships. ViTs also excel in video understanding, naturally modeling spatial and temporal relationships across frames.
The following table summarizes the comparison between the two:
| Category | CNNs | Vision Transformers (ViTs) |
|---|---|---|
| Architecture | Use convolution and pooling layers to build features from edges -> objects in a step-by-step hierarchy. | Split images into patches and process them with self-attention so all patches interact. Capture local and global features together. |
| Performance | Strong accuracy–speed balance, especially on small datasets. Power models like YOLO, SSD, Faster R-CNN. | Higher accuracy on large datasets with good pretraining; better at complex spatial relationships. |
| Data Requirements | Work well with limited data due to inductive biases like locality and weight sharing. | Need large datasets or strong pretraining since they learn patterns without built-in assumptions. |
| Inference Speed | Fast on GPUs/NPUs and mobile devices; convolutions are highly optimized. | Slower because self-attention grows with patch count. Window attention helps but still heavier. |
| Context Understanding | Capture local details first, global understanding appears deeper in the network. | Capture global context from the first layer thanks to self-attention across all patches. |
| Training Stability | Stable and easy to train with standard optimizers and minimal tuning. | More sensitive, need warmup, careful initialization, and stronger regularization. |
| Transfer Learning & Pretraining | Transfer well to tasks similar to ImageNet. | Transfer well across many domains due to flexible, general feature learning. |
| Robustness & Generalization | More affected by texture bias, lighting changes, and adversarial attacks. | More robust due to shape-based reasoning and global attention, require strong pretraining. |
| Model Size & Parameter Efficiency | Very parameter-efficient (e.g., EfficientNet). High accuracy with fewer weights. | Need more parameters from scratch but scale well and surpass CNNs at large sizes. |
| Interpretability | Easier to understand, clear feature hierarchy. Grad-CAM works well. | Harder to interpret due to complex attention patterns, attention maps help but are less intuitive. |
| Computational Complexity | Nearly linear with image size; efficient for high-res inputs. | Quadratic with patch count; expensive for large images unless using window attention. |
| Domain-Specific Performance | Strong in tasks relying on local details such as medical, satellite, defect detection, fine-grained textures. | Strong in tasks needing global context such as scene understanding, tracking, video, multi-object reasoning. |
Hybrid Models: Combining the Best of CNNs and ViTs
One of the popular trends in computer vision is the use of a hybrid approach that merges convolutional layers with transformers. In this approach CNNs handle local feature extraction efficiently, while ViT excel at capturing global relationships. Several designs exemplify this idea.
DETR (Detection Transformer) is one of the clearest examples of this hybrid approach. DETR uses a CNN backbone such as ResNet to extract feature maps from the image. These features are then passed into a Transformer encoder–decoder, where self-attention models global relationships. Finally, the decoder outputs set-based object predictions without the need for anchors or non-maximum suppression. Variants like Deformable DETR make this even faster by using sparse, multi-scale attention instead of global attention, reducing computational cost.
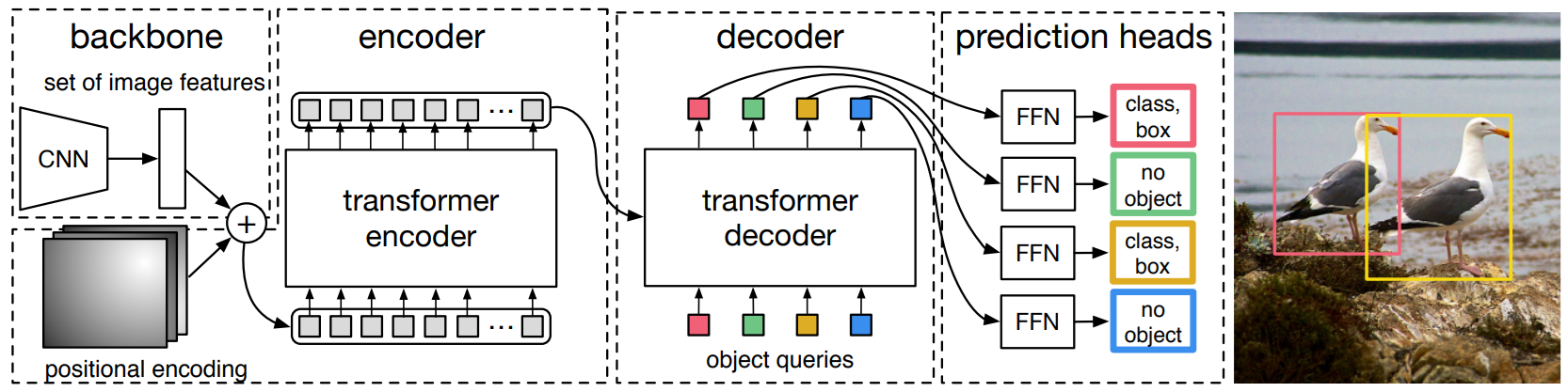
This hybrid design shows how CNNs and Transformers can work together. CNNs handle the low-level visual details efficiently, while the Transformer layers add powerful global context understanding for more accurate object detection.
Train ViT and CNN based models with Roboflow
Roboflow makes it straightforward to experiment with both CNN and Vision Transformer architectures for object detection. On the ViT side, you can train models like RF-DETR, a transformer-based detector built with deformable attention for strong global reasoning. For CNN-based approaches, Roboflow supports fast and efficient models such as YOLOv11 and Roboflow 3.0, which rely on optimized convolutional backbones.
What makes Roboflow especially useful is that both model types can be trained through the same simple ML pipeline. Upload your own dataset or fork it from thousands of dataset from Roboflow Universe, prepare a dataset version with the built in augmentation and preprocessing steps, and start training by choosing your architecture type and other training settings with just a few clicks.
After training, Roboflow automatically provides detailed evaluation metrics, including mAP, precision, recall, confusion matrices, and per-class performance. You can also build a Roboflow Workflow using blocks to visually compare model performance side-by-side, analyze predictions, and understand how each model performs. This makes it easy to see compare different architectures suitable for your specific object detection problem.
Following are the steps that you can use to train the ViT based RF-DETR model. Similar steps can also be used to train the CNN based models YOLOv11 or Roboflow 3.0.
Step 1. Fork a benchmark project from Roboflow Universe
Start by choosing a dataset you want to experiment with. For this example, I forked the Drone_Airplane_Bird dataset. Forking imports the dataset into your workspace so you can train models on it directly.
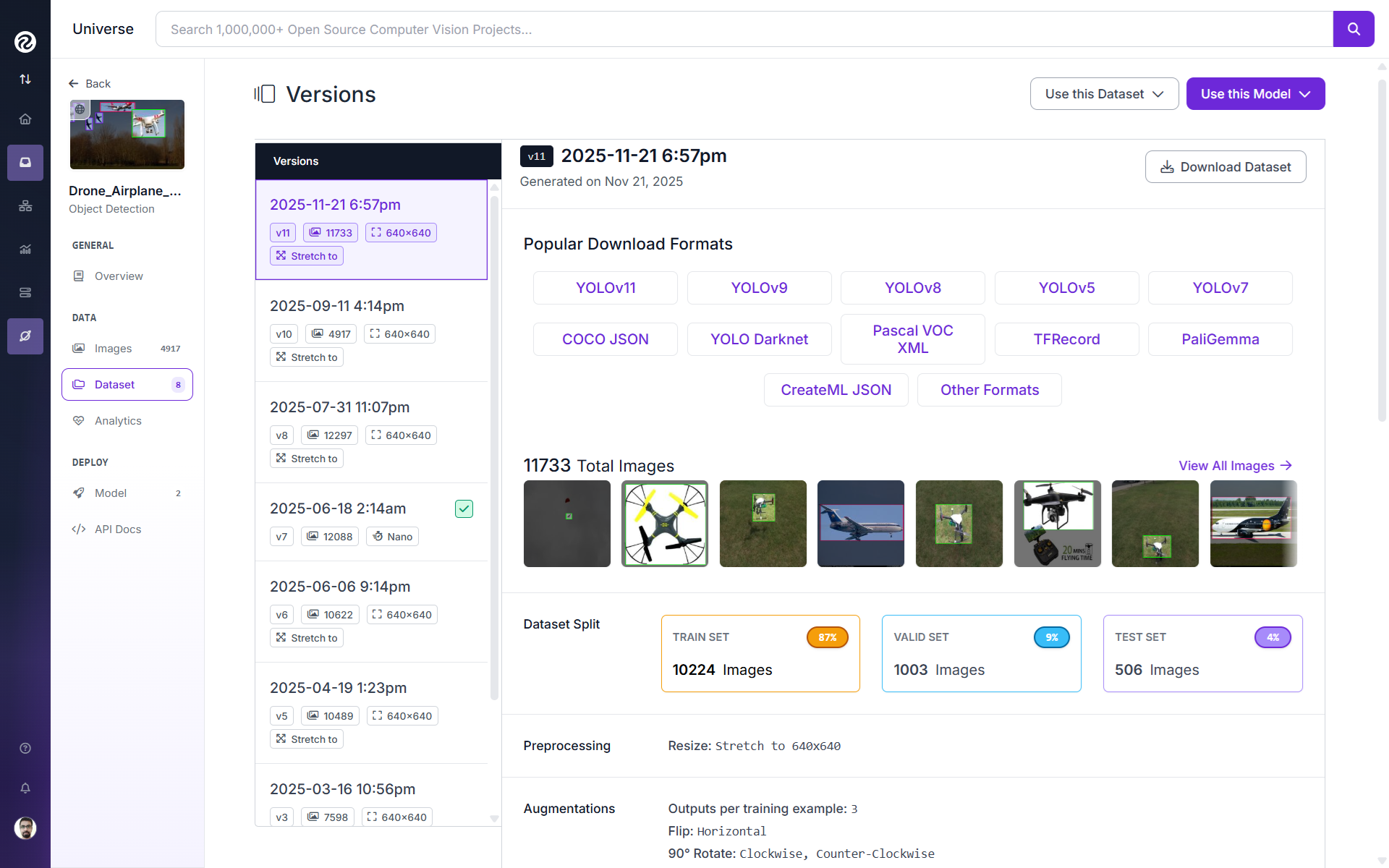
Step 2. Train a ViT-based model (RF-DETR)
After forking, prepare the dataset version and train using “Custom Training” option in Roboflow. Use following options:
- Model: RF-DETR
- Model size: Small
- Checkpoint: Object365 pretrained weights
And click start training. Once the model is trained you will see the metrics and test it by uploading images.
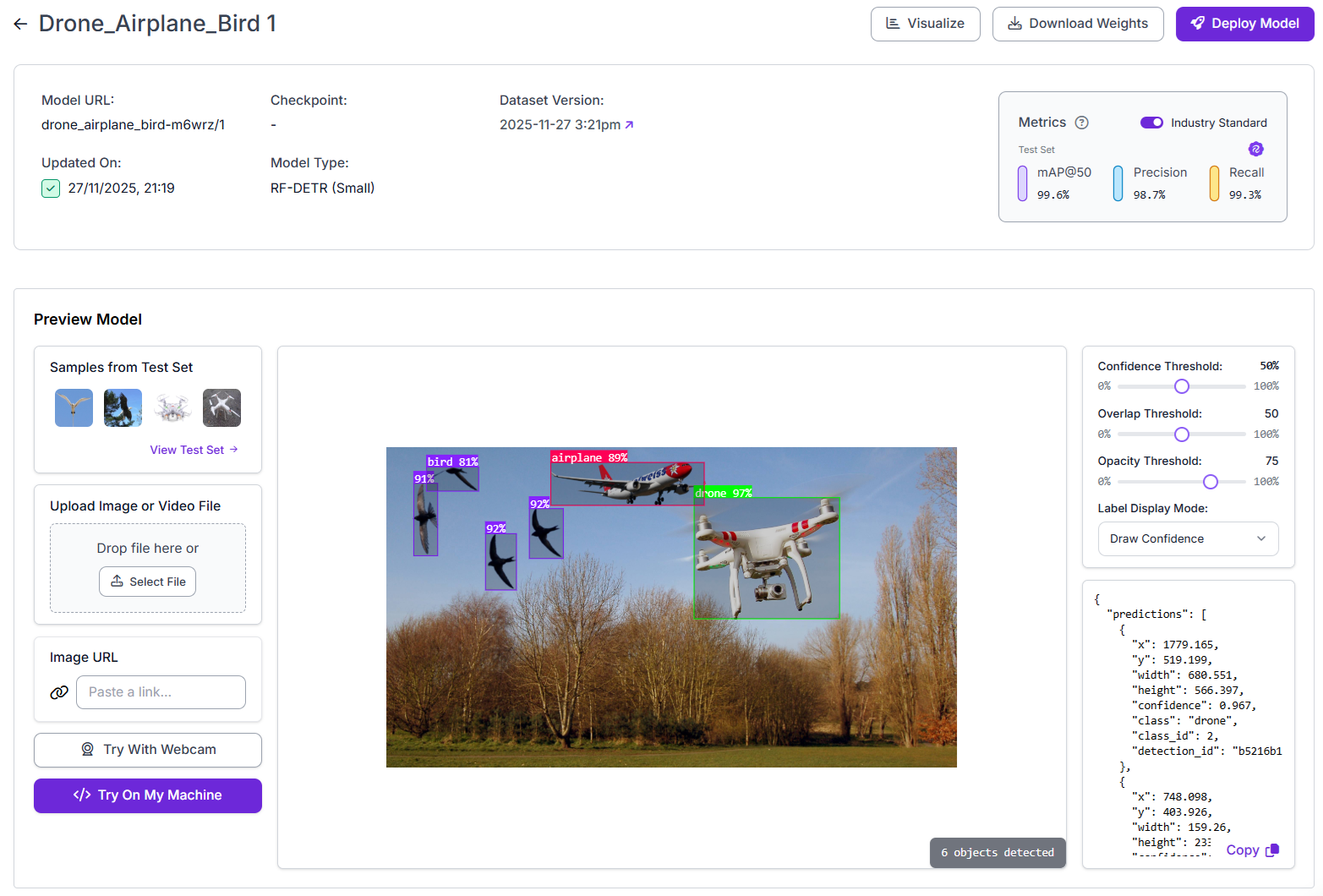
Step 3. Train a CNN-based model
To compare architectures, you can repeat the same process using a CNN based model. Choose either of the following:
- YOLOv11: Fast and efficient CNN-based detector
- Roboflow 3.0: Modern CNN-based architecture optimized for accuracy and speed
Both models train in the same interface, so you can compare them directly. I trained YOLOv11 model.
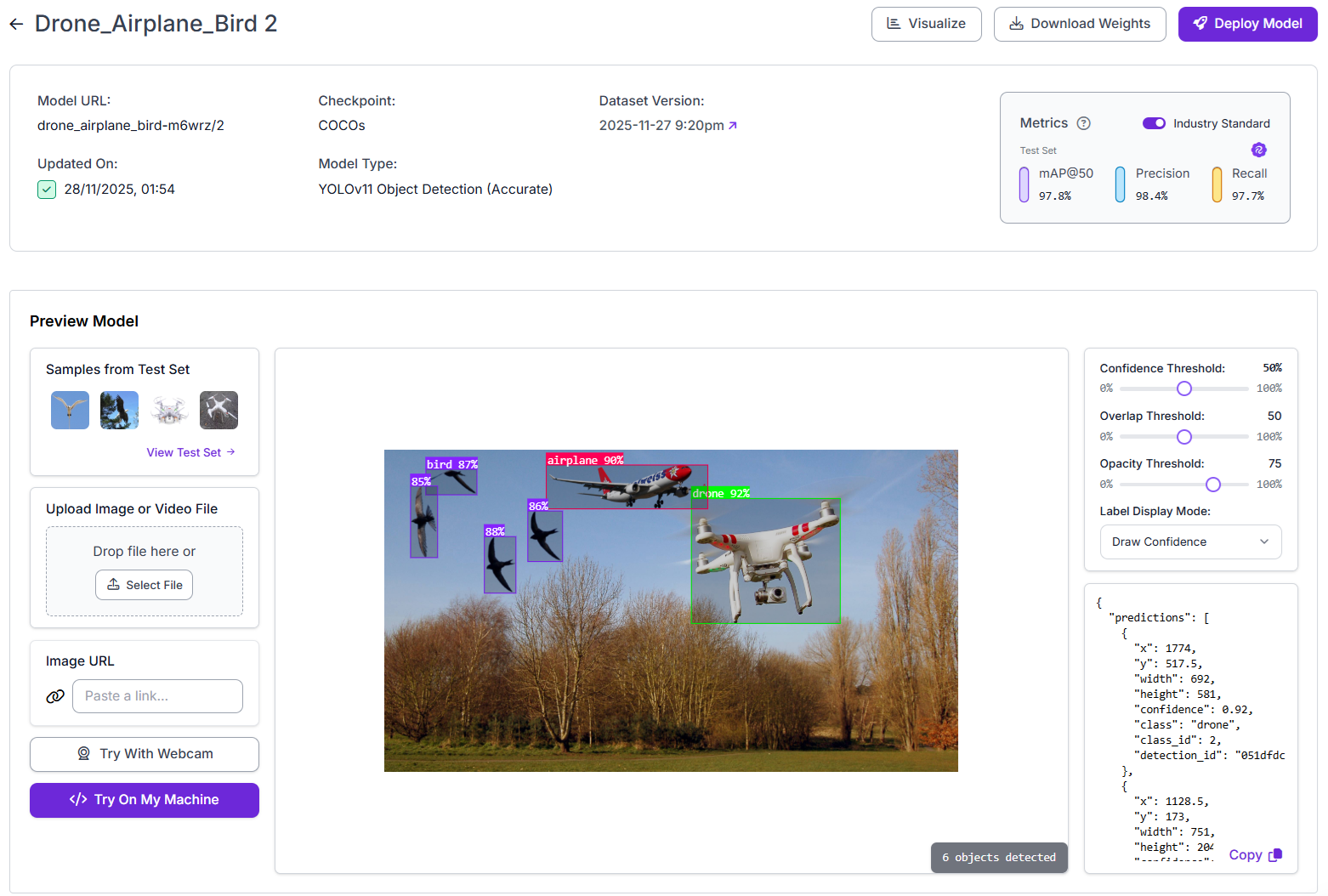
Step 4. View and compare the metrics
Once training completes, Roboflow provides detailed metrics for each model, including:
- mAP@50
- Precision
- Recall
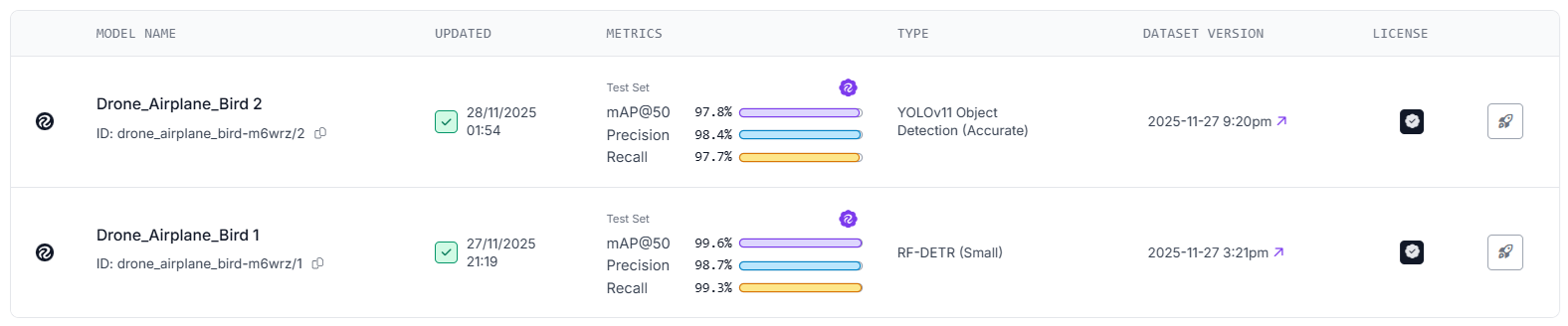
You can also view class-by-class results and a confusion matrix:
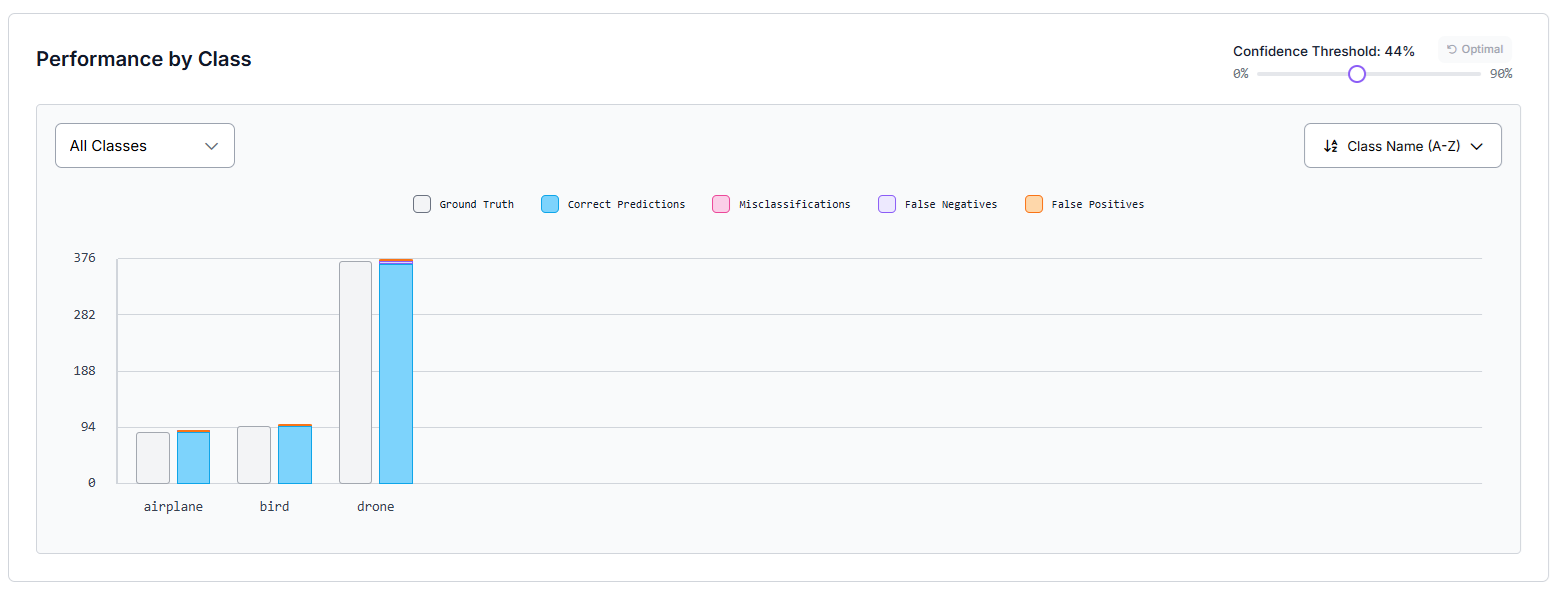
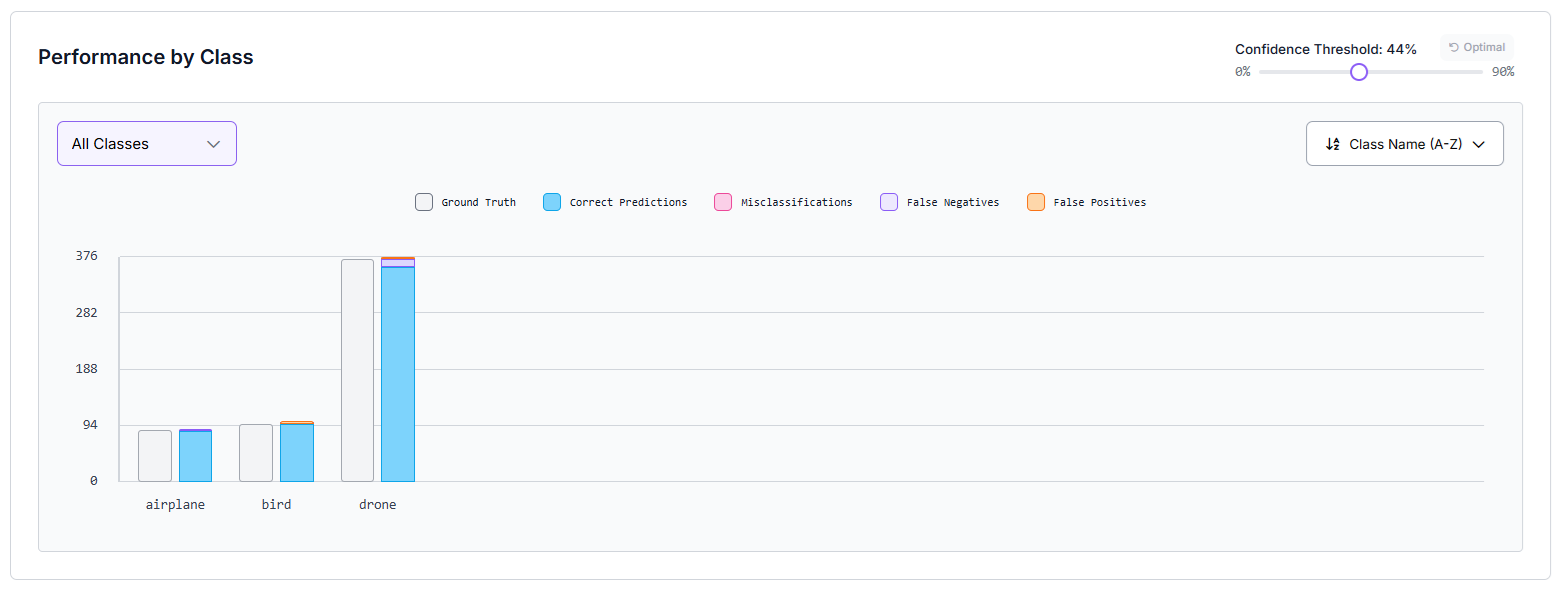
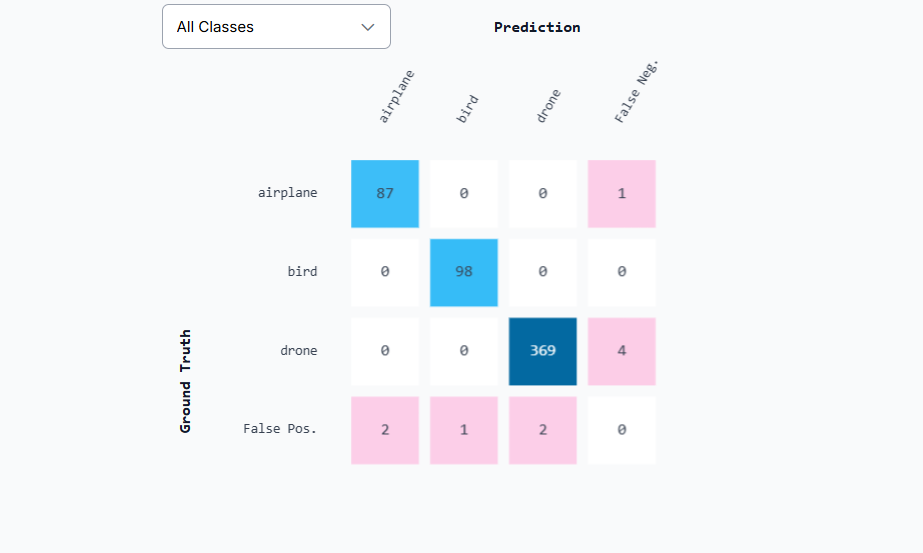
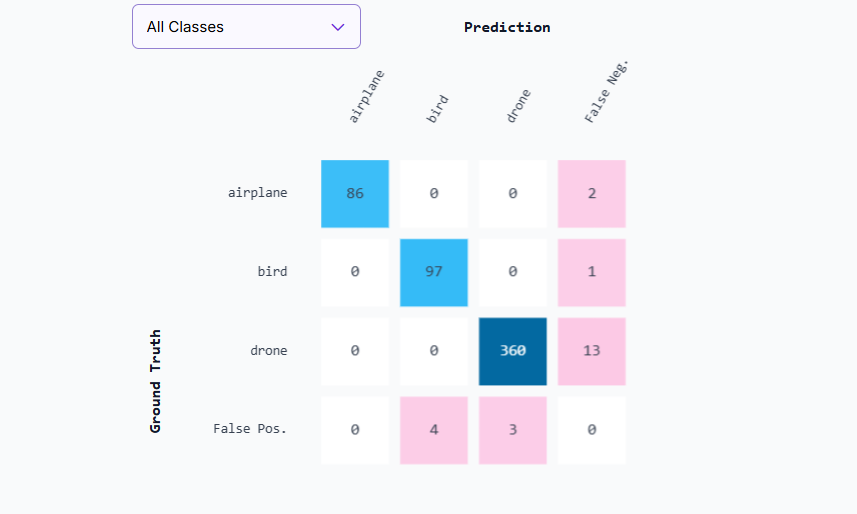
This makes it easy to see how a ViT-based model (RF-DETR) performs versus a CNN-based model (YOLOv11 or Roboflow 3.0) on the same dataset.
Step 5. Build the Workflow in Roboflow
Once both models are trained, you can create a Roboflow Workflow to compare them visually. Add an Inputs block, then drop in your two trained models i.e. one RF-DETR (ViT-based) and one YOLOv11 (CNN-based). Connect both models to the Model Comparison Visualization block, which shows both models’ predictions on the same image. This workflow makes it easy to understand how each architecture behaves in real-world test cases.
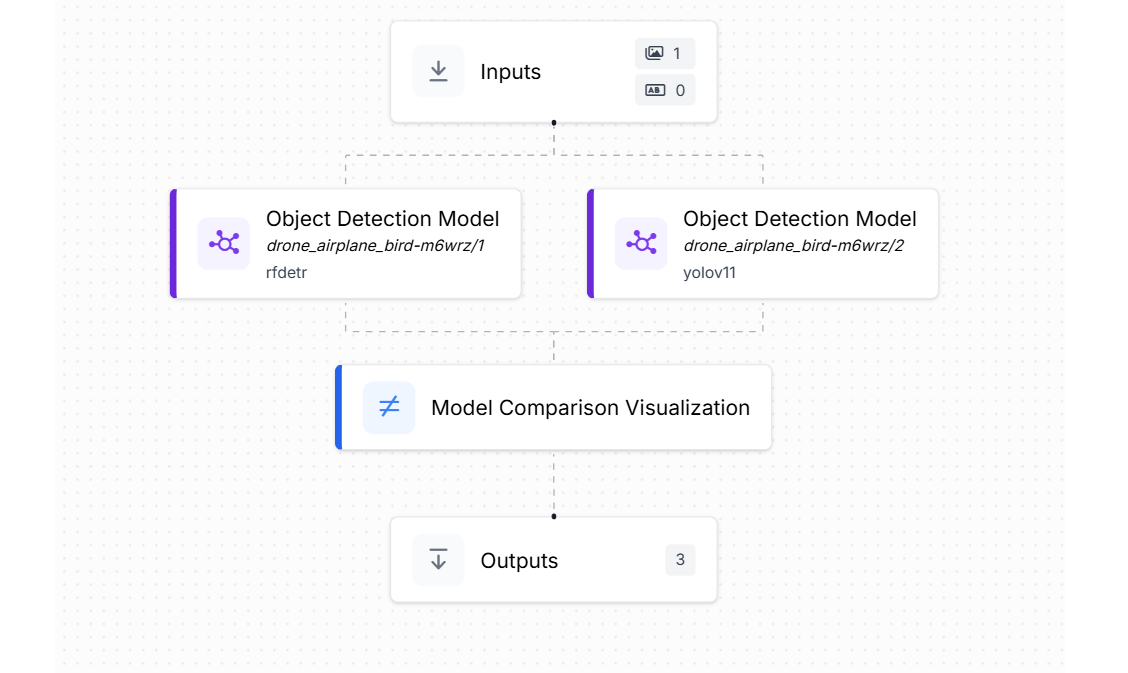
When you run the workflow you will see output similar to following.
JSON output:
[
{
"model_comparison_visualization": <IMAGE_OUTPUT>,
"model_1_predictions": {
"image": {
"width": 1200,
"height": 814
},
"predictions": [
{
"width": 817,
"height": 720,
"x": 673.5,
"y": 401,
"confidence": 0.9156492948532104,
"class_id": 0,
"class": "airplane",
"detection_id": "8fb6a261-75dd-4693-a135-1582c0838183",
"parent_id": "image"
}
]
},
"predictions": {
"image": {
"width": 1200,
"height": 814
},
"predictions": [
{
"width": 830.5173034667969,
"height": 720.1442718505859,
"x": 672.4267730712891,
"y": 397.5630569458008,
"confidence": 0.908603847026825,
"class_id": 0,
"class": "airplane",
"detection_id": "f0f3bd64-b5c5-4782-9ff2-2cc27e8021b0",
"parent_id": "image"
}
]
}
}
]Image output:

CNNs Compared To Vision Transformers Conclusion
CNNs and Vision Transformers each bring powerful strengths to object detection depending on the application. CNNs remain efficient, stable, and well-suited for smaller datasets or systems that require fast inference and low computation. Vision Transformers provide stronger global understanding and often achieve higher accuracy when enough data and compute are available.
Modern AI workflows increasingly use both approaches, and tools like Roboflow make it straightforward to train, evaluate, and compare them on the same dataset. The best choice ultimately depends on your data size, hardware limits, and how much global context your object detection task requires. Get started free today.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Dec 1, 2025). Vision Transformer vs. CNN for Object Detection. Roboflow Blog: https://blog.roboflow.com/vision-transformer-vs-cnn-for-detection/