
Segmentation models in computer vision are designed to understand the structure of a scene by assigning pixel-level labels to objects. Traditional approaches such as semantic, instance, and panoptic segmentation provide detailed maps of where things are and what they belong to. These methods are widely used in applications such as autonomous navigation and medical imaging.
However, existing segmentation models work with a predefined set of object categories (labels). If an object is not part of that list, the model cannot segment it. These models also run one full inference pass per query, which limits flexibility. As vision systems begin to integrate language understanding, a more flexible approach has been introduced, known as Promptable Concept Segmentation (PCS).
PCS avoids the restrictions of a fixed vocabulary and allows the model to segment objects described directly by a text prompt or example images. So, instead of limiting the model to predefined labels, PCS accepts prompts such as noun phrases (“red apple”) or example images.
The model then returns segmentation masks for all instances of the described concept in an image or video. This makes segmentation more flexible, scalable, and aligned with how humans naturally describe visual concepts. The following image illustrates the concept of PCS.
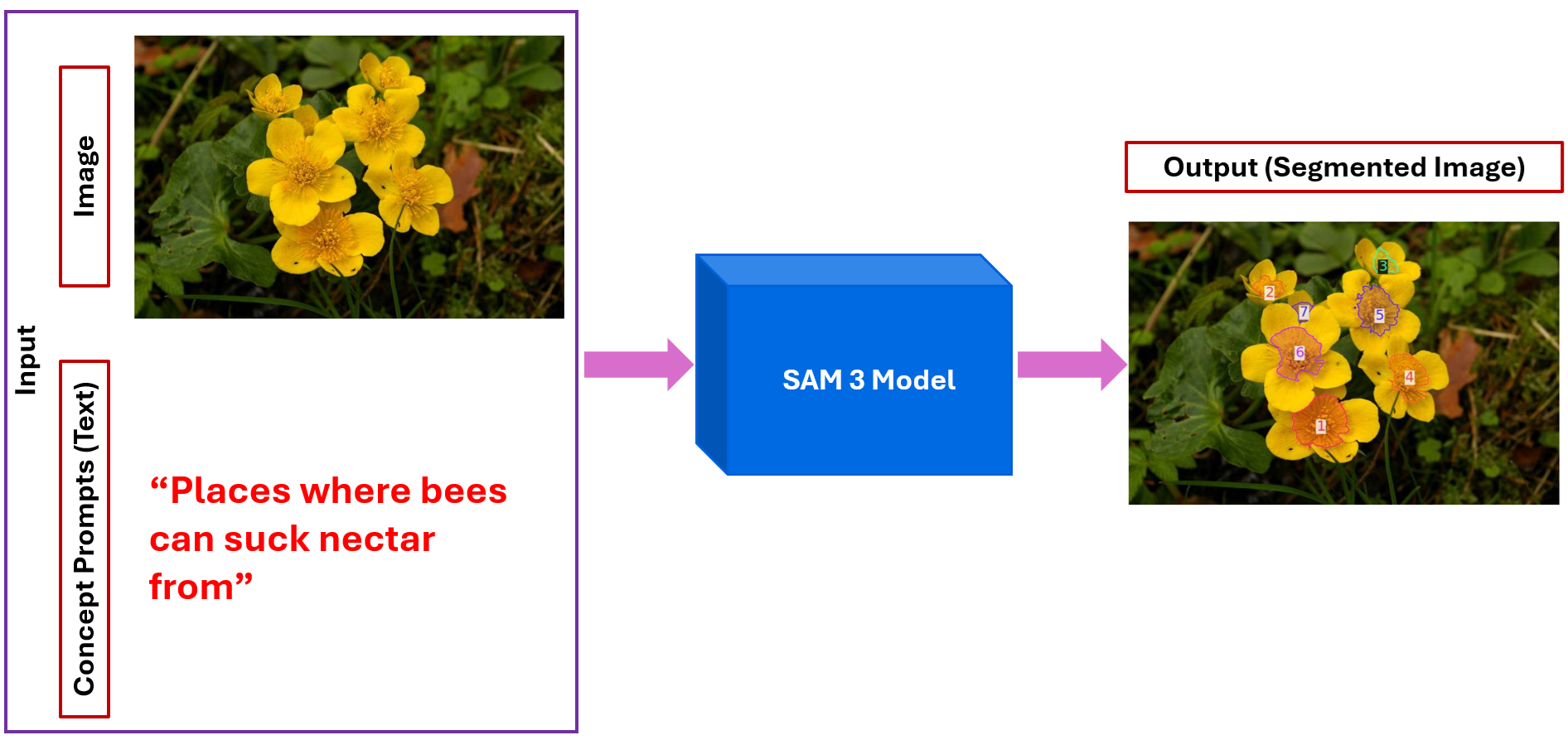
The image shows how SAM 3 uses a natural-language prompt to segment concepts in an image. The user provides the text “Places where bees can suck nectar from,” and SAM 3 identifies and segments all flower centers that match this description. The output highlights each instance separately, demonstrating prompt-controlled, open-vocabulary segmentation. This article explores:
- What PCS is
- Why it matters
- How PCS compares to semantic, instance, and panoptic segmentation
- The architecture of SAM 3, the third generation of the Segment Anything Model.
- The data and training system behind SAM 3.
At the end of this article you will have clear understanding about PCS and how PCS extends the capabilities of segmentation models.
What Is Promptable Concept Segmentation?
Promptable Concept Segmentation (PCS) generalizes interactive segmentation by allowing users to segment every object matching a concept instead of a single instance. The SAM 3 paper defines the PCS task as follows:
“Given an image or short video (≤30 secs), detect, segment, and track all instances of a visual concept specified by a short text phrase, image exemplars, or a combination of both.”
Here, concepts are restricted to simple noun phrases (NPs) consisting of a noun and optional modifiers. Text prompts are global across frames, while image exemplars can be provided on individual frames and can be positive or negative bounding boxes.
SAM 3 formalizes this by taking text and/or image exemplars as input and predicting instance and semantic masks for every object matching the concept while preserving object identities across video frames. In other words, PCS returns a set of masks (and optionally bounding boxes) for all objects that satisfy the user’s prompt.

Unlike traditional segmentation, PCS is prompt‑based and open‑vocabulary. Users provide a query in the form of a noun phrase or exemplar images, and the model segments all corresponding objects in the input. This is powerful for tasks where pre‑defined class lists fall short for example, segmenting “striped cat”, “yellow school bus” or “blue recycling bin” in an image or video. The SAM 3 paper highlights that PCS can be used to recognize atomic visual concepts like “red apple” or “striped cat”, enabling fine‑grained segmentation beyond standard categories.
Why Is Promptable Concept Segmentation So Impactful?
Open‑vocabulary segmentation unlocks new applications. Annotators can quickly label datasets by prompting for rare objects or specific attributes, robotic systems can interact with objects described by natural language, and creative tools can isolate elements defined by arbitrary descriptions. PCS also bridges vision and language: the prompt is expressed as text and/or images, and the model must align these modalities to produce accurate segmentation masks.
How PCS Is Different from Classic Segmentation Models
PCS is different from semantic, instance, and panoptic segmentation because it doesn’t rely on a fixed list of object categories. In the classical segmentation tasks, the model can only label what it was trained to recognize. Semantic segmentation assigns a pixel-level class from a limited set, instance segmentation separates individual objects but still from that fixed set, and panoptic segmentation combines both but remains restricted to predefined classes.
PCS overcomes this limitation. The model finds all objects matching the concept and segments them, even if the category never existed in its training data. PCS is open-vocabulary, prompt-driven, and adaptable, while the traditional segmentation methods are closed-vocabulary and fixed.
| Task | What it Does | Vocabulary | User Control | Video Tracking |
|---|---|---|---|---|
| Semantic | Pixel-wise class labels | Fixed | None | No |
| Instance | Segments each object instance | Fixed | None | No |
| Panoptic | Combines semantic + instance | Fixed | None | No |
| PCS | Detects, segments & tracks all instances of a prompted concept | Open vocabulary | Text / Exemplar Image prompts | Yes |
SAM 3 Architecture
Let’s now understand the SAM 3 model architecture that enables PCS.
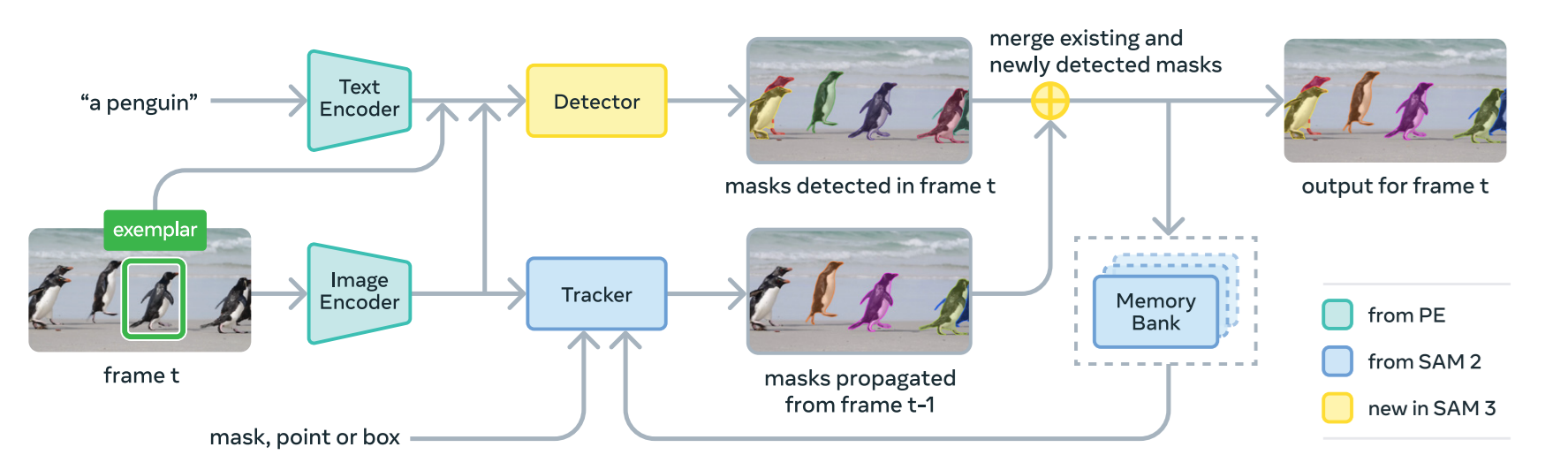
SAM 3 uses a dual encoder-decoder transformer architecture inspired by the earlier SAM models and by DETR. The goal is to support both Promptable Concept Segmentation (PCS) and Promptable Visual Segmentation (PVS), for images and videos, and for multiple prompt types such as concept prompts (simple noun phrases, image exemplars) or visual prompts (points, boxes, masks).
Image and Text Encoders
SAM 3 uses a vision encoder to extract image features and a text encoder to process the prompt. These encoder and decoders are Transformer-based and trained with contrastive vision–language learning on 5.4 billion image–text pairs through the Perception Encoder (PE). These encoders basic image features and text features that serve as inputs to the rest of the architecture.
Geometry and Exemplar Encoder
When prompts include visual examples, such as cropped objects, points or boxes, SAM 3 uses a geometry and exemplar encoder to turn them into learnable tokens using positional embeddings and ROI-pooled features. These tokens add visual and spatial information to the prompt.
Fusion Encoder
The text tokens and any geometry or exemplar tokens are combined into a single set of prompt tokens, which guide how the model interprets the image. The fusion encoder takes the unconditioned frame embeddings from the vision encoder and injects prompt information into them using six Transformer blocks with self-attention and cross-attention layers. This conditioning process effectively tells the model “what to look for,” resulting in conditioned frame embeddings that are aligned with the user’s prompt, whether it is text, visual examples or both.
Decoder
For prediction, SAM 3 uses a DETR style decoder with 200 learned object queries. Through six Transformer blocks, these queries self-attend and cross-attend to both the prompt tokens and the conditioned frame embeddings. The decoder includes improvements such as iterative box refinement, look-forward-twice, hybrid matching and Divide And Conquer (DAC) DETR. MLP heads applied to the queries output bounding boxes and scores, forming the base for instance-level predictions.
Presence Head
To improve classification accuracy, SAM 3 separates global classification from local localization. This head predicts whether the noun phrase is present in the image and helps separate global presence from local matching, reducing false positives.
Segmentation Head
Segmentation is handled by a MaskFormer style segmentation head that supports both semantic and instance segmentation. The conditioned frame embeddings generated by the fusion encoder are used to produce semantic masks, while the decoder’s object queries are used to generate instance masks. Because the vision encoder is a single-scale ViT, the segmentation head receives additional multi-scale features generated by a SimpleFPN module, enabling it to operate effectively across different spatial resolutions.
Ambiguity Head
Some noun phrases can refer to more than one visual concept, such as “apple” referring to either a fruit or a logo. Without special handling, the model might output conflicting or overlapping masks. To address this, SAM 3 uses a mixture-of-experts (MoE) ambiguity head with two experts trained in parallel using a winner-takes-all strategy, where only the expert with the lowest loss receives gradients. A small classification head learns to choose the correct expert at inference time. Additionally, overlapping instances are detected using Intersection-over-Minimum (IoM), which is more effective than IoU for nested objects, reducing ambiguous outputs by around 15%.
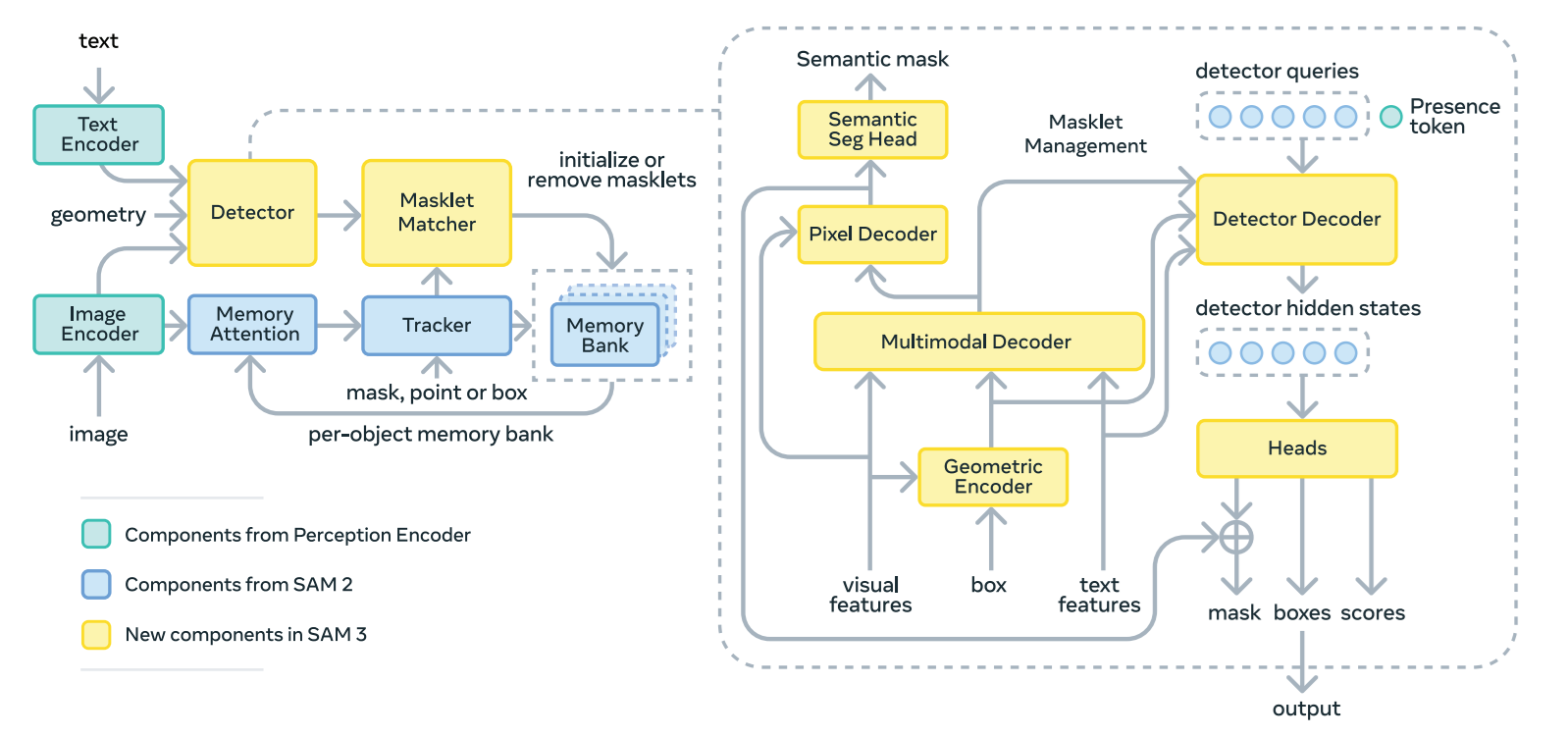
SAM 3 brings these components together into a unified system that can understand text and visual prompts, reason about object presence, and produce high-quality masks across images and videos. It expands segmentation beyond fixed category labels and make system more flexible, interactive and scalable.
SAM 3 Data and Training Infrastructure
The goal of SAM 3’s data and training system is to build a model that can segment any concept you name, not just a fixed list of object classes. To make this possible, the authors built two major pieces:
- A large-scale dataset called SA‑Co (Segment Anything with Concepts) covering millions of images, noun-phrases (concepts), and segmentation masks.
- A data engine that uses human and model in-loop annotation, to produce high quality data at large scale.
Let’s understand these.
SA-Co Dataset
The SA-Co (Segment Anything with Concepts) dataset forms the core training resource for SAM 3 and is designed to support large-scale, open-vocabulary concept segmentation across both images and videos. The data resource consists of training data and benchmark data.
SA-Co Training Data
Consists of three main image datasets and a video dataset:
- SA-Co/HQ: a high-quality collection produced through all stages of the data engine and containing 5.2 million images and 4 million unique noun phrases.
- SA-Co/SYN: a fully synthetic dataset labeled automatically by a mature version of the data engine.
- SA-Co/EXT: a group of fifteen external datasets enriched with additional noun-phrase labels and hard negatives using the SA-Co ontology.
- SA-Co/VIDEO: a video dataset with 52.5K videos, 24.8K unique phrases and 134K video-phrase pairs, with each video averaging 84 frames at 6 fps.
SA-Co Benchmark
For evaluation, the SA-Co Benchmark dataset is used which includes 214K unique phrases, 126K images and videos, and more than 3 million media-phrase pairs. The benchmark is divided into splits (Gold, Silver, Bronze, Bio and VEval) each differing in domain coverage and annotation depth, ranging from multi-annotator high-quality labels to masks generated using SAM 2.
- SA-Co/Gold: Covers 7 domains and provides three human annotations per pair for highest-quality evaluation.
- SA-Co/Silver: Includes 10 domains with one human annotation per image–phrase pair for scalable evaluation.
- SA-Co/Bronze and SA-Co/Bio: Includes 9 existing datasets either with existing mask annotations and masks generated by using boxes as prompts to SAM 2.
- SA-Co/VEval: A video benchmark spanning 3 domains, each with one annotation per video–phrase pair for temporal evaluation.
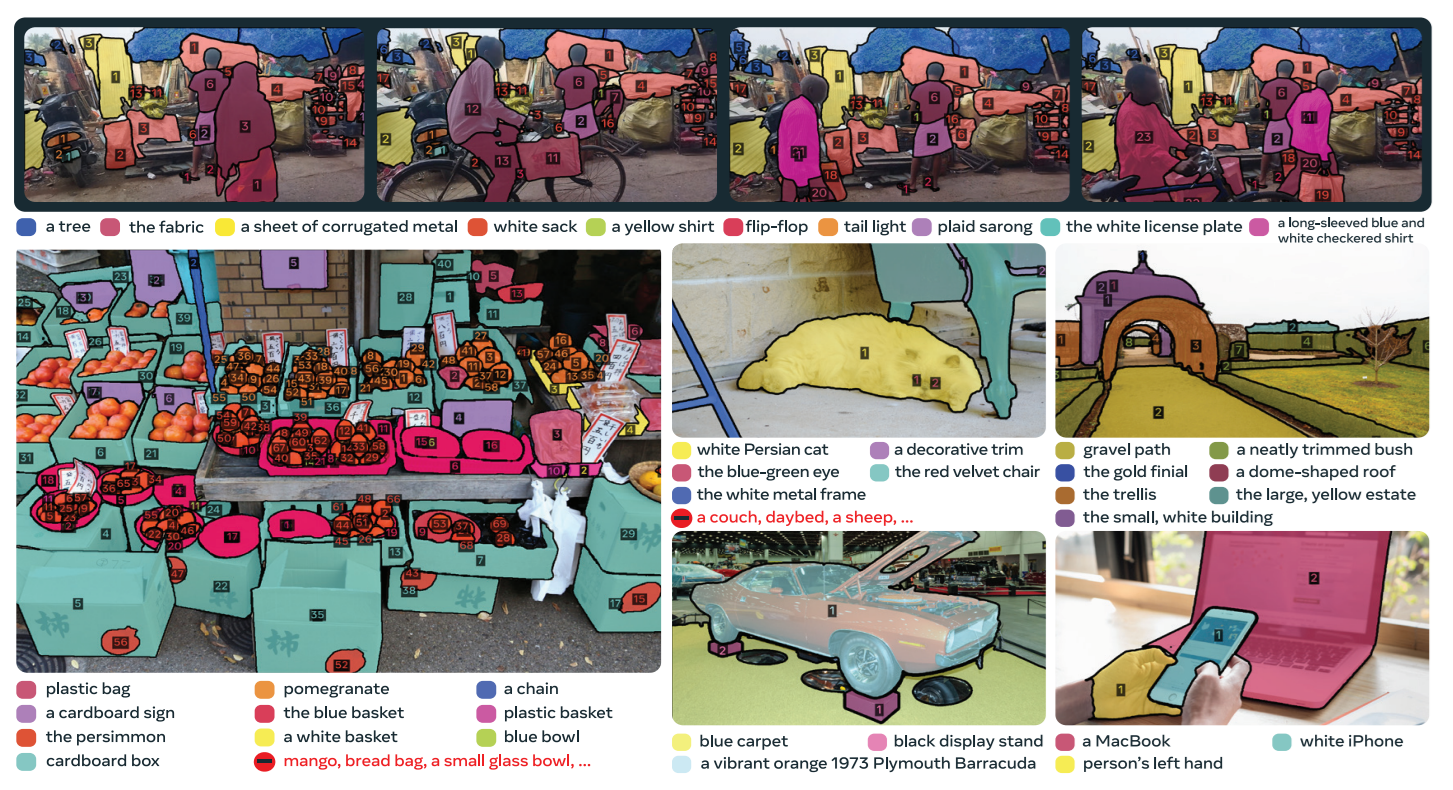
Data Engine
The SA-Co data engine is a large, human-model-in-the-loop system built to generate high-quality image and video annotations for training SAM 3. It combines captioning models, Llama-based AI verifiers, SAM models (SAM 1, SAM 2, SAM 3) and human annotators in a feedback loop. The core idea is straightforward:
- AI models propose concepts and masks
- humans and AI verifiers check them
- SAM 3 is retrained
- better annotations are produced in the next cycle
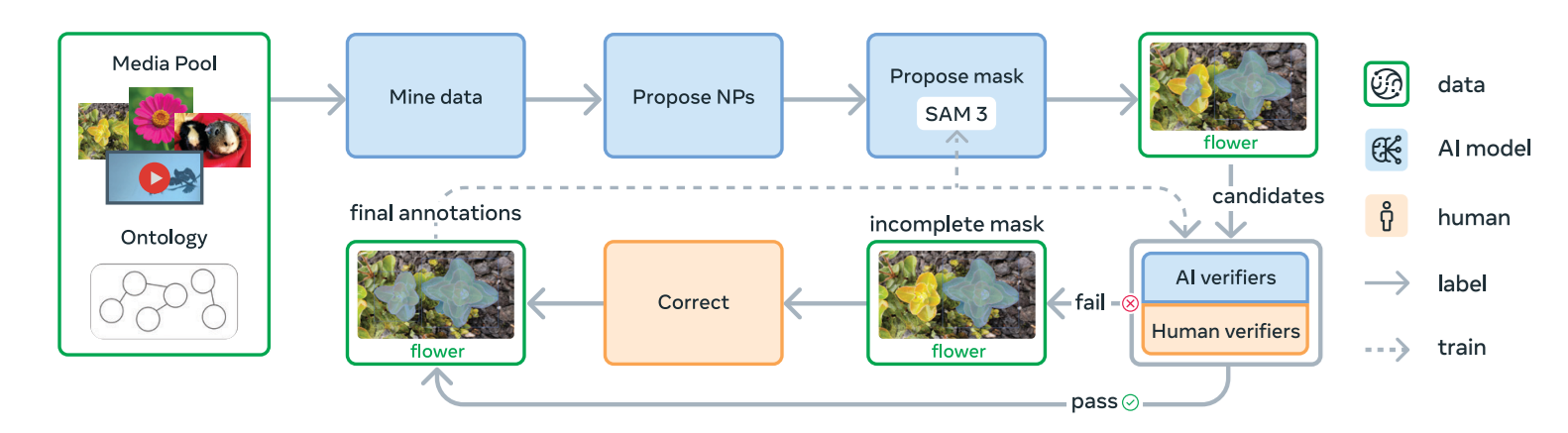
How the Data Engine Works (Components)
The engine begins by selecting images or videos from a large pool. A captioning model proposes noun phrases (NPs) that describe visual concepts in the media. A segmentation model (SAM 2 in Phase 1, and SAM 3 from Phase 2 onward) then generates candidate masks for each phrase.
These masks go through two human or AI-assisted checks:
- Mask Verification (MV): Annotators decide whether the mask is correct for the phrase.
- Exhaustivity Verification (EV): Annotators check if all instances of that concept have been masked.
If the result is incomplete, it goes to manual correction, where humans add, remove or adjust masks using a browser-based tool powered by SAM 1. Annotators may also use “group masks” for small objects or reject phrases that cannot be grounded.
The Four Phases of the Data Engine
Following are the four phases of data engine.
Phase 1: Human Verification
In the first phase, images are sampled randomly and a simple captioning model proposes noun phrases for each one. SAM 2 is used to generate candidate masks, and humans verify every mask for both quality and correctness. This phase produces 4.3 million image–phrase pairs, which serve as the initial training data for SAM 3.
Phase 2: Human + AI Verification
In Phase 2, the human annotations collected earlier are used to train Llama 3.2-based AI verifiers, which can automatically evaluate mask quality and exhaustiveness. The noun-phrase generator is upgraded to a Llama-based system, and SAM 3 replaces SAM 2 as the mask-proposal model. With humans now focused only on difficult cases, the pipeline becomes much faster and produces 122 million new image–phrase pairs.
Phase 3: Scaling and Domain Expansion
Phase 3 expands the dataset by having AI models mine harder examples across 15 different domains. New concepts are added by extracting noun phrases from image alt-text and from a large 22.4M-node Wikidata-based ontology. During this phase, SAM 3 and the AI verifiers are retrained multiple times, resulting in 19.5 million additional pairs and much broader concept coverage.
Phase 4: Video Annotation
The final phase extends the data engine from images to videos. A video-enabled version of SAM 3 generates masklets across frames, while the mining process focuses on challenging clips with crowding or tracking failures. Human effort is directed toward these difficult cases, ultimately producing 52.5K annotated videos and 467K masklets.
The data engine continuously improves itself through a cycle of AI proposals, human feedback and model retraining. Over four phases, it scales up in both complexity and automation, allowing SA-Co to grow in size, variety and quality. By combining captioning models, Llama-based AI verifiers and multiple generations of SAM, the engine produces the massive open-vocabulary dataset needed to train SAM 3.
Promptable Concept Segmentation Conclusion
Promptable Concept Segmentation changes the way we think about segmentation. Instead of choosing from a fixed set of labels, we can now describe what we want in natural language and let the model find it. SAM 3 shows how powerful this can be by handling flexible prompts, understanding complex concepts and segmenting them across images and video. SAM 3 with PCS proves that interacting with vision models will feel more natural, more open-ended and much closer to how we describe things in everyday life.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Nov 19, 2025). What Is Promptable Concept Segmentation (PCS)?. Roboflow Blog: https://blog.roboflow.com/what-is-promptable-concept-segmentation-pcs/