
On December 6th, 2023, Google announced Gemini, a new Large Multimodal Model (LMM) that works across text, images, and audio. Gemini’s text capabilities were introduced into Bard on the same day, with an announcement that multimodality would be coming to Bard soon.
On December 13th, Google released an API for Gemini, allowing you to integrate the Gemini model directly into your applications.
The Roboflow team has analyzed Gemini across a range of standard prompts that we have used to evaluate other LMMs, including GPT-4 with Vision, LLaVA, and CogVLM. Our goal is to better understand what Gemini can and cannot do well at the time of writing this piece.
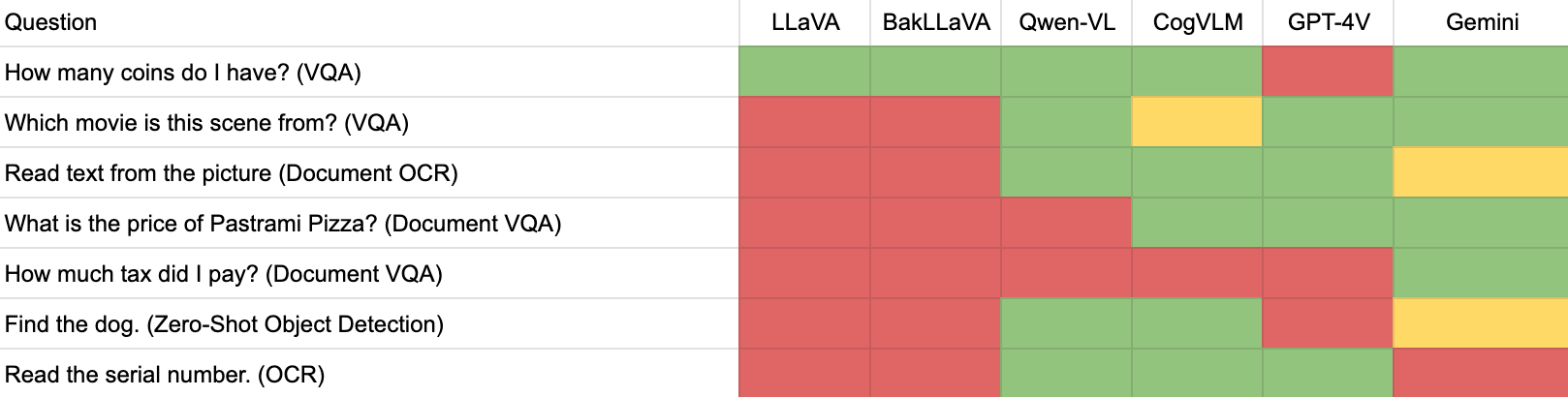
Here is how Gemini performed, where green cells denote a model returned an accurate response, yellow denote almost complete accuracy, red denotes a model was wrong, and blue means there was a technical issue preventing us from running a test that was out of our control.
In this guide, we are going to discuss what Gemini is and analyze how Gemini performs across a range of computer vision tasks. We will also share the resources you need to start building with Gemini. Without further ado, let’s get started!
What is Gemini?
Gemini is a Large Multimodal Model (LMM) developed by Google. LMMs are large language models that are able to work with more “modalities” than text. Gemini is capable of answering questions about text, images, and audio.
Gemini launched with demos that show Gemini writing code, explaining math problems, finding similarities between two images, turning images into code, understanding “unusual” emojis, and more. With that said, there were claims as to the extent to which one or more demos were edited, with TechCrunch reporting that their “best demo was faked.”
Gemini has three versions, designed for different purposes:
- Ultra: The largest model, useful for accomplishing complex tasks.
- Pro: A task that can scale across a range of tasks.
- Nano: A model for use on your devices (i.e. on mobile phones).
A limited version of Gemini’s text capabilities is available in Bard at the time of writing this article.
According to Google, the Ultra model, presently unavailable, “exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.” With that said, we are unable to get hands on with the Ultra model at the time of writing this article.
Gemini is one of many LMMs available today. GPT-4 with Vision, OpenAI’s multimodal model, launched in September 2023. Other open source models have since launched, including LLaVA, BakLLaVA, and CogVLM. Thus, there are many options you have available if you want to integrate multimodal models into your applications.
How to Run Gemini
You can run Gemini using the Google Cloud Vertex AI Multimodal playground. This playground offers a web interface through which you can interact with Gemini Pro Vision, which has support for asking questions about images. You can also send requests to the Gemini API by providing a multimodal prompt over HTTP. Read the Gemini API documentation to learn more.
To explore Gemini with less effort, try our Gemini playground page.
Evaluating Gemini on Computer Vision Tasks
We have evaluated Gemini across four separate vision tasks:
- Visual Question Answering (VQA)
- Optical Character Recognition (OCR)
- Document OCR
- Object Detection
We have used the same images and prompts we used to evaluate other LMMs in our GPT-4 with Vision Alternatives post. This is our standard set of benchmarks for use with learning more about the breadth of capabilities relevant to key computer vision tasks.
Our tests were run in the Gemini web interface.
Test #1: Visual Question Answering (VQA)
We started with a coin test, asking Gemini “How many coins do I have?”:
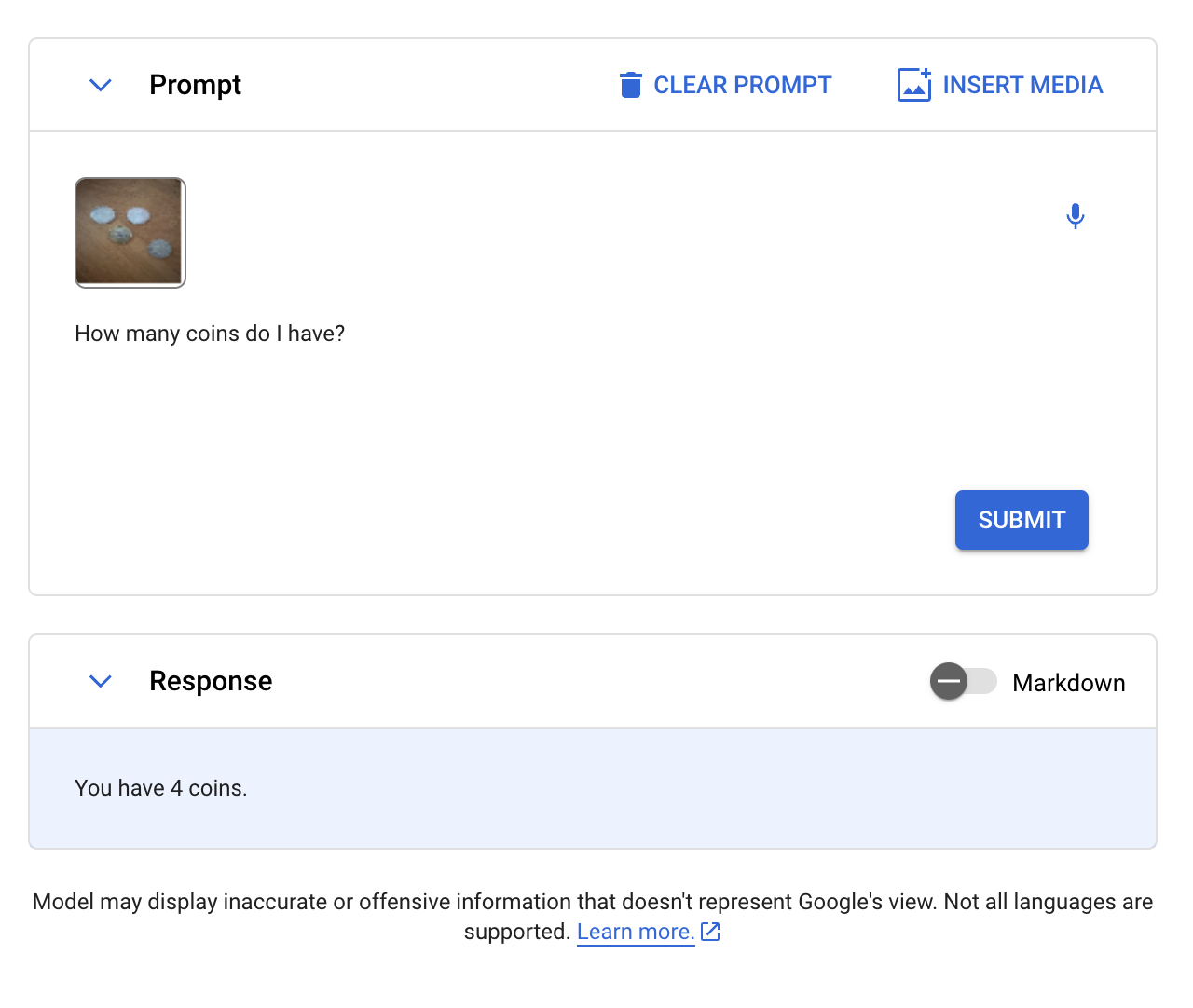
Gemini successfully counted the number of coins in the image. LLaVA, BakLLaVA, Qwen-VL, and CogVLM were all able to pass this test, too. GPT-4 with Vision did not return an accurate response when we tested GPT-4 with Vision with the same prompt.
We then went on to ask if Gemini could identify which movie was featured in an image. Here is the image we sent to Gemini:

The model successfully identified that the movie featured was “Home Alone”.
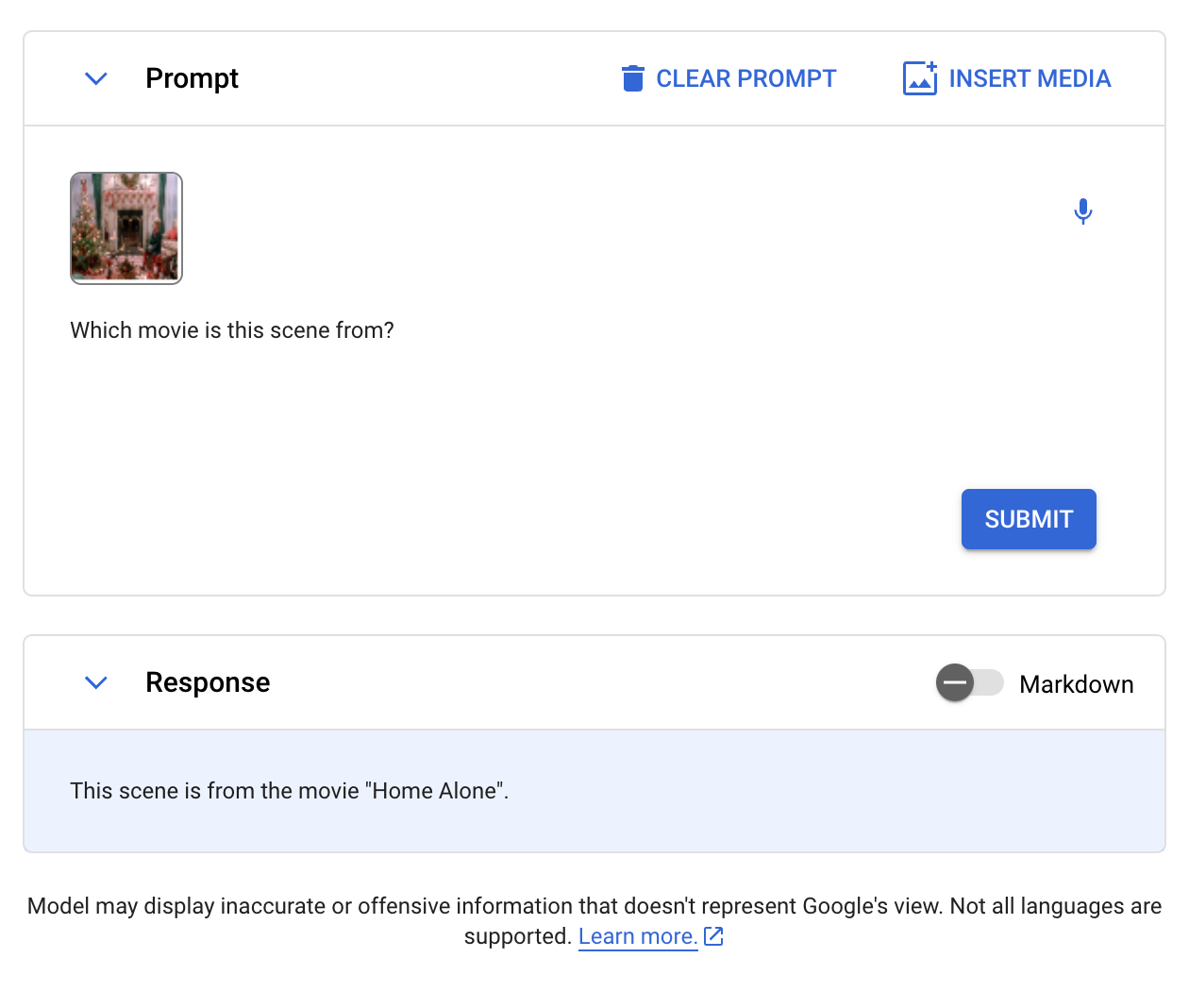
Qwen-VL and GPT-4 with Vision were both able to answer this prompt successfully. LLaVA, BakLLaVA, and CogVLM failed the Home Alone scene test above.
We also asked Gemini a question about a menu. Given the menu below, we asked Gemini “What is the price of Pastrami Pizza?”

Gemini successfully answered the question, noting that Pastrami Pizza costs $27:
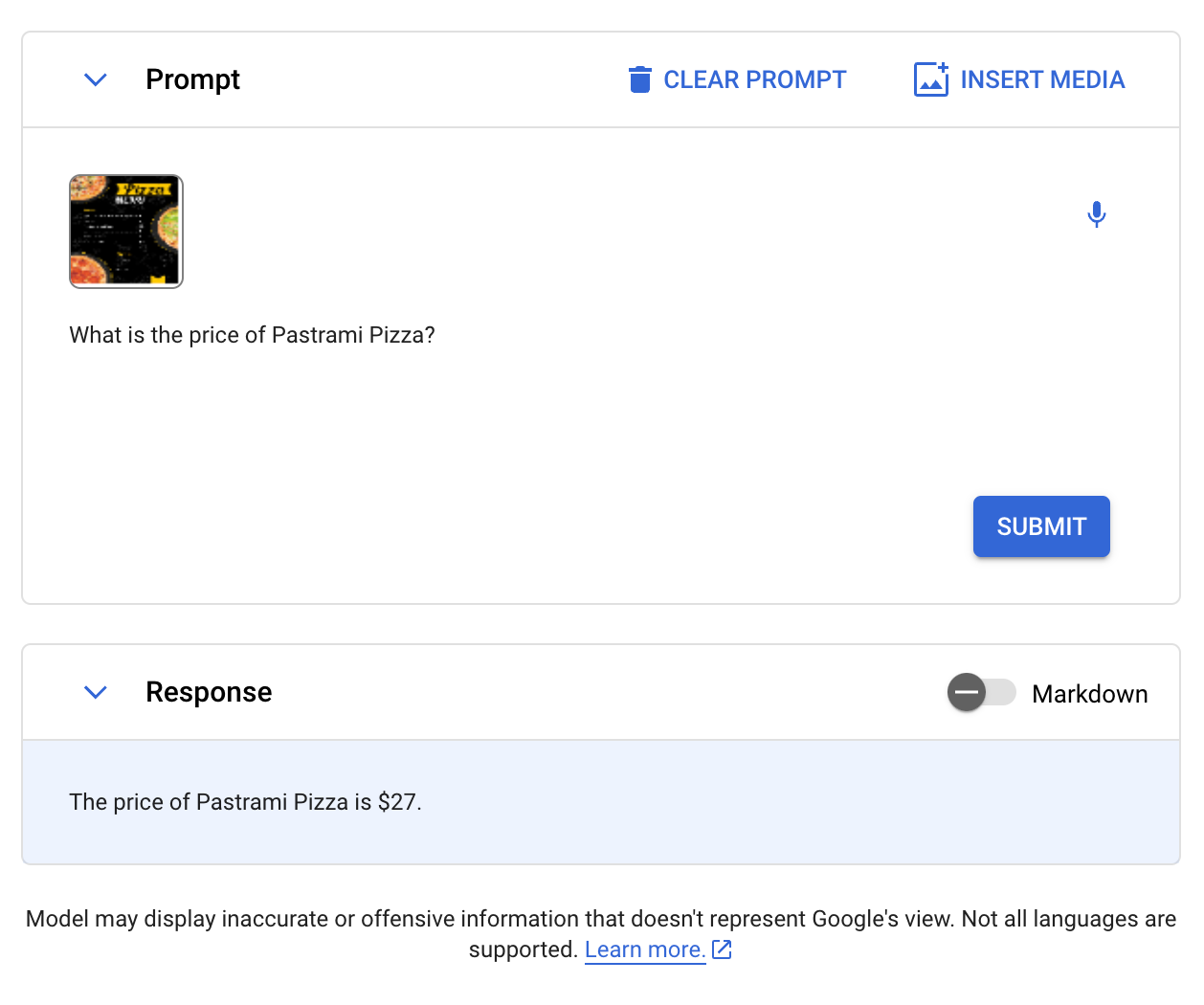
CogVLM, Gemini and GPT-4 with Vision passed this test. LLaVA, BakLLaVA, and Qwen-VL failed the test.
Test #2: Optical Character Recognition (OCR)
We then went on to evaluate Gemini’s OCR abilities. We provided an image of a tire, asking the model to read the serial number. Here is the image we sent to Gemini:

With our standard prompt, “Read the serial number.”, Gemini provided an incorrect response, adding letters that were not present to the serial number. We then revised our prompt to be more specific, asking “What is the serial number in the image?”
In both cases, the model was wrong.
The ground truth serial number is 3702692432. Gemini said it was 11020422.
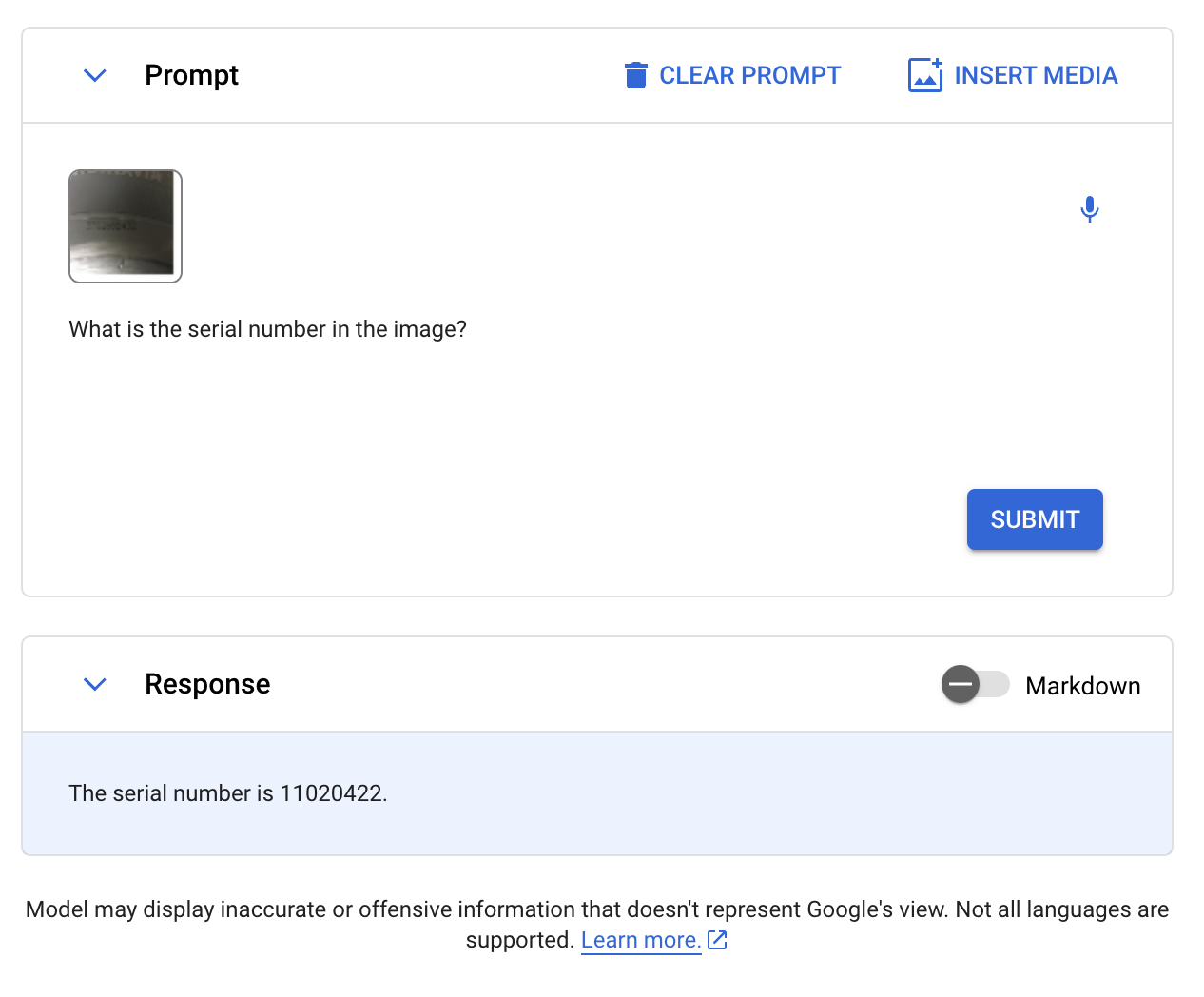
Qwen-VL, CogVLM, and GPT-4 with Vision all answered this question accurately. LLaVA, BakLLaVA, and Gemini failed to answer the question accurately.
Test #3: Document OCR
Next, we evaluated Gemini on document OCR. We provided the following image, with the prompt “Read text from the picture.”

Gemini was almost correct, but missed a “‘s” in the first sentence when compared against ground truth:
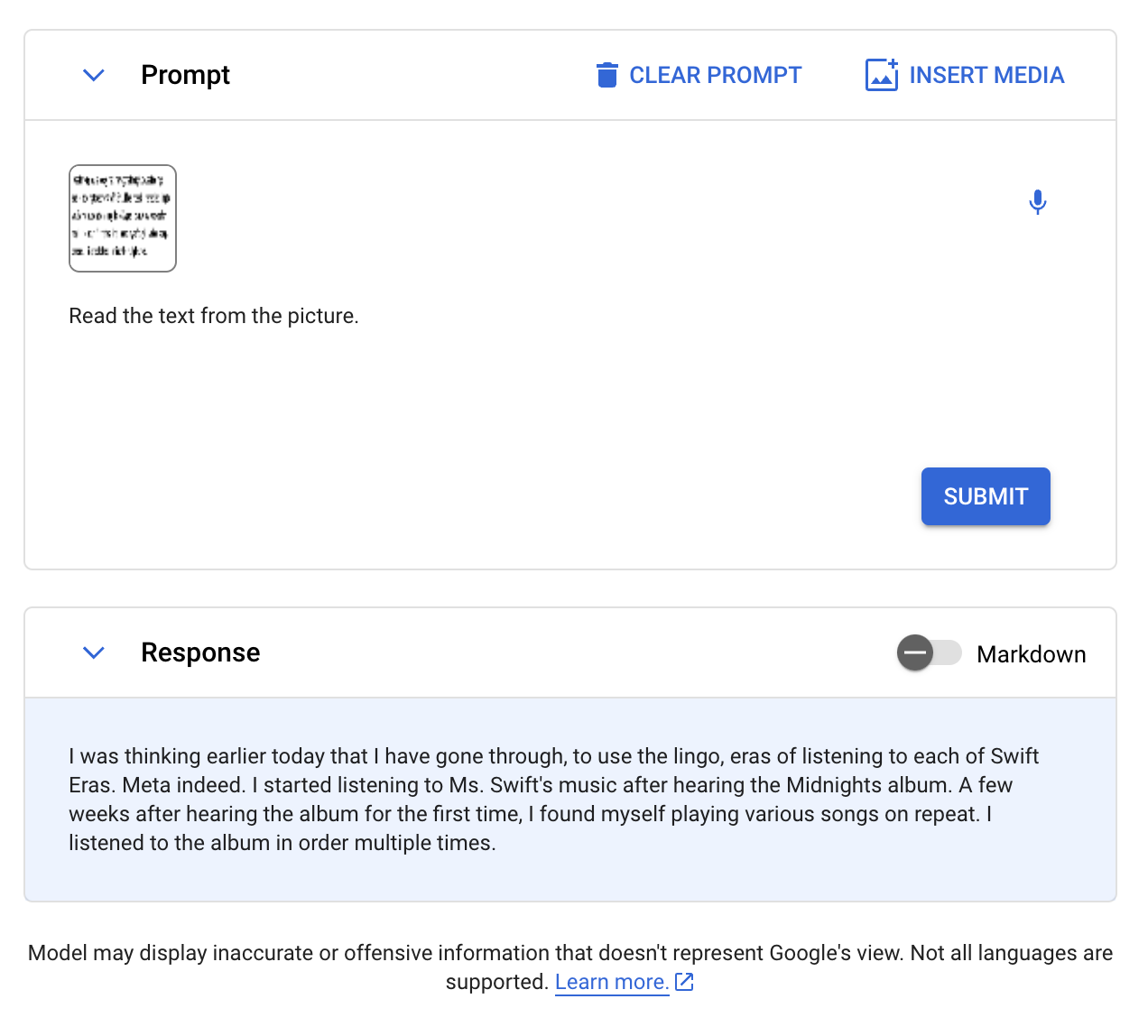
Qwen-VL, CogVLM, and GPT-4 with Vision all passed this test with complete accuracy.
We then asked Gemini to retrieve the amount of tax a receipt states was paid on a meal. Our prompt was “How much tax did I pay?” Here is the image we sent to Gemini:

Gemini successfully answered the question, noting that $2.30 was paid in tax.
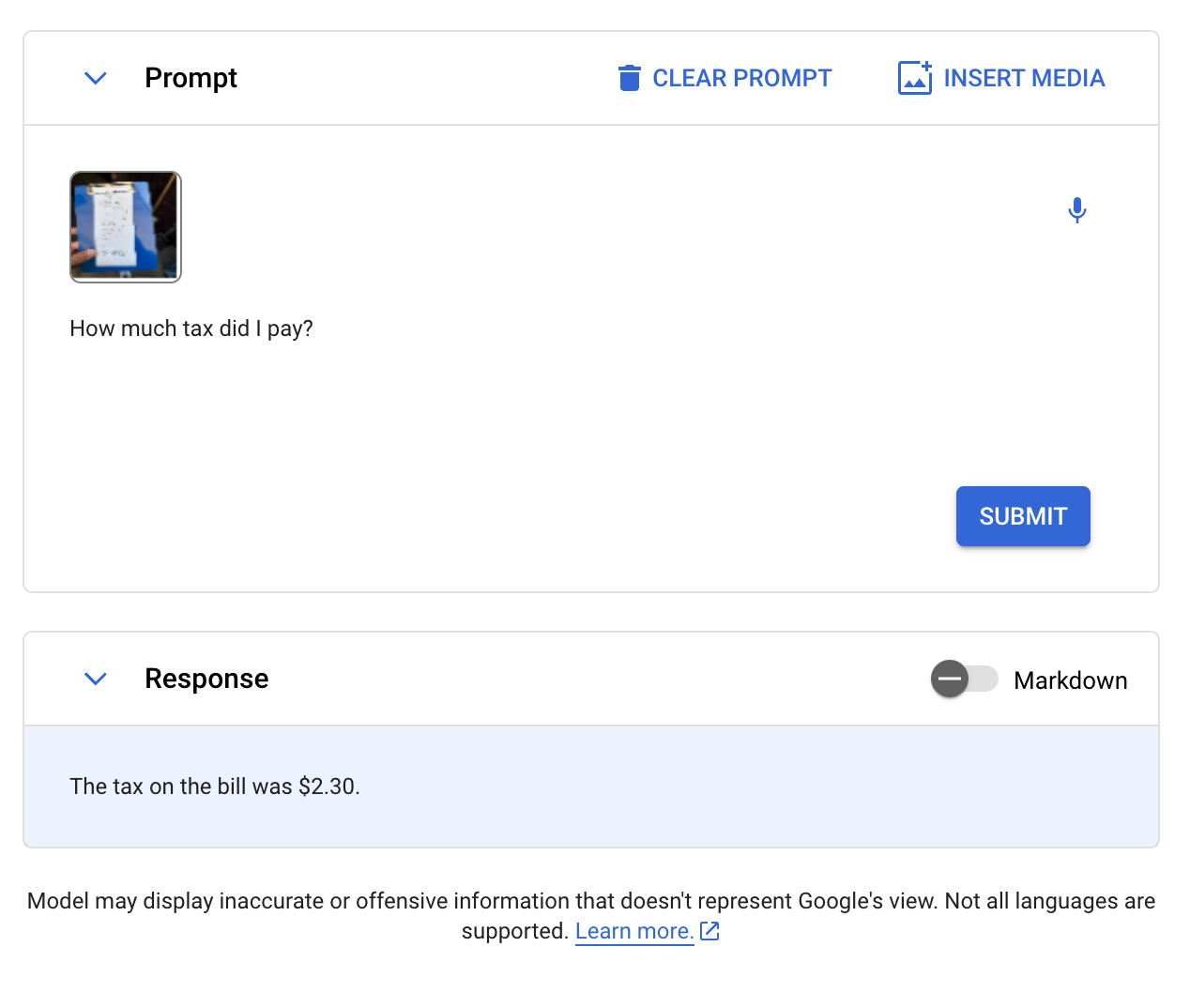
Test #4: Object Detection
Most multimodal models we have tested struggle with object detection. This refers to returning the specific coordinates of an object in an image. Only Qwen-VL and CogVLM were able to accurately identify the location of a dog in an image, our standard test.
We prompted Gemini with the text “Find the dog.” and the following image:

At first, Gemini continually returned “The model will generate a response after you click Submit” with this prompt. We will update this post if we are able to get the test working.
We retried requests and prompts, which we suspect is not related to this task as we have experienced issues running other prompts. We tried the prompt "Find the x/y/w/h position of the dog, with xy as the center point." and received the response:
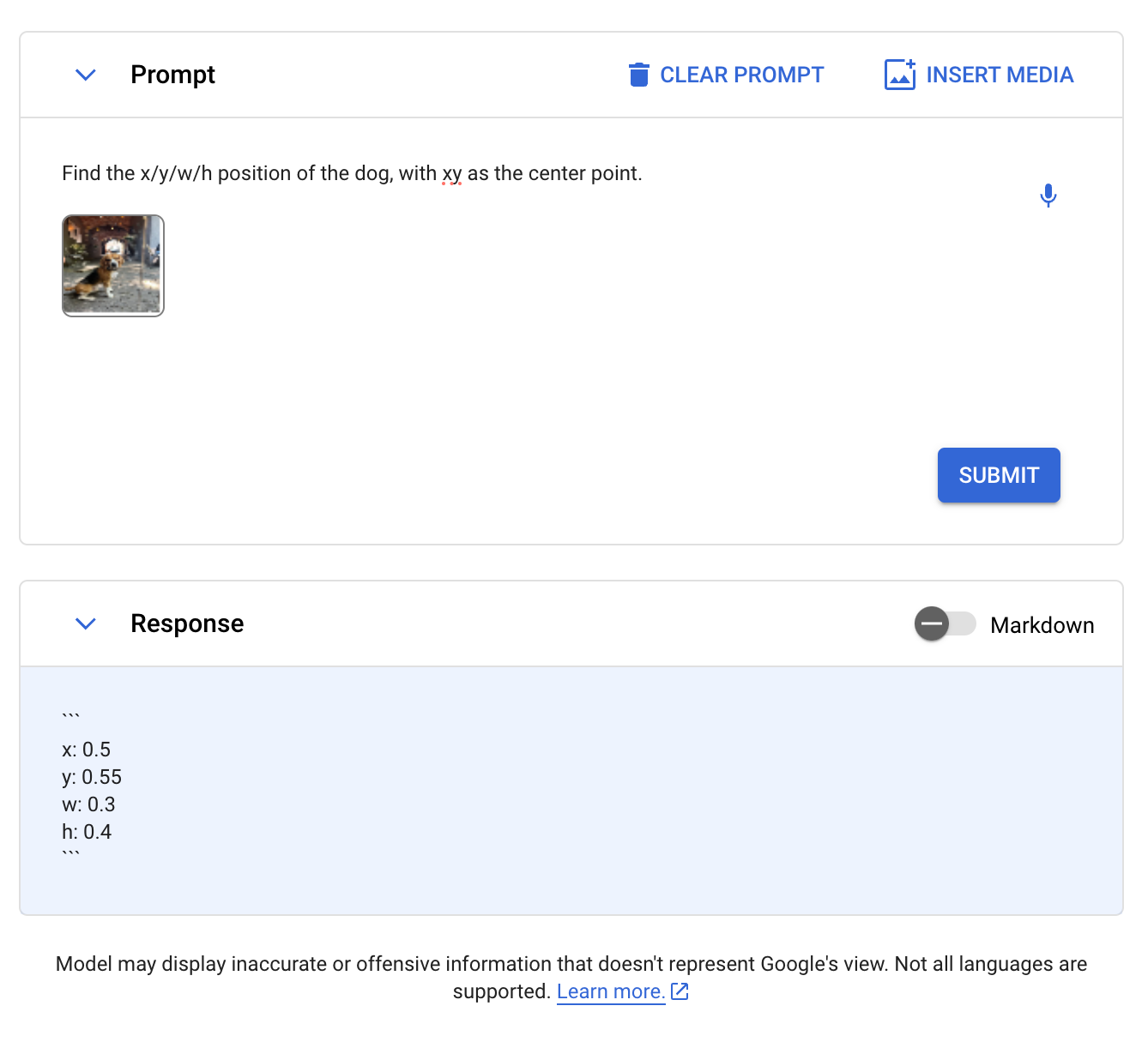
We plotted the coordinates on an image:

Gemini correctly identified the general position of the dog, but the coordinate region only covered a portion of the dog. It is unclear if Gemini identified the center point or the dog since the dog is in the center.
We ran another test, looking for the Christmas tree in the Home Alone image from earlier in this post:
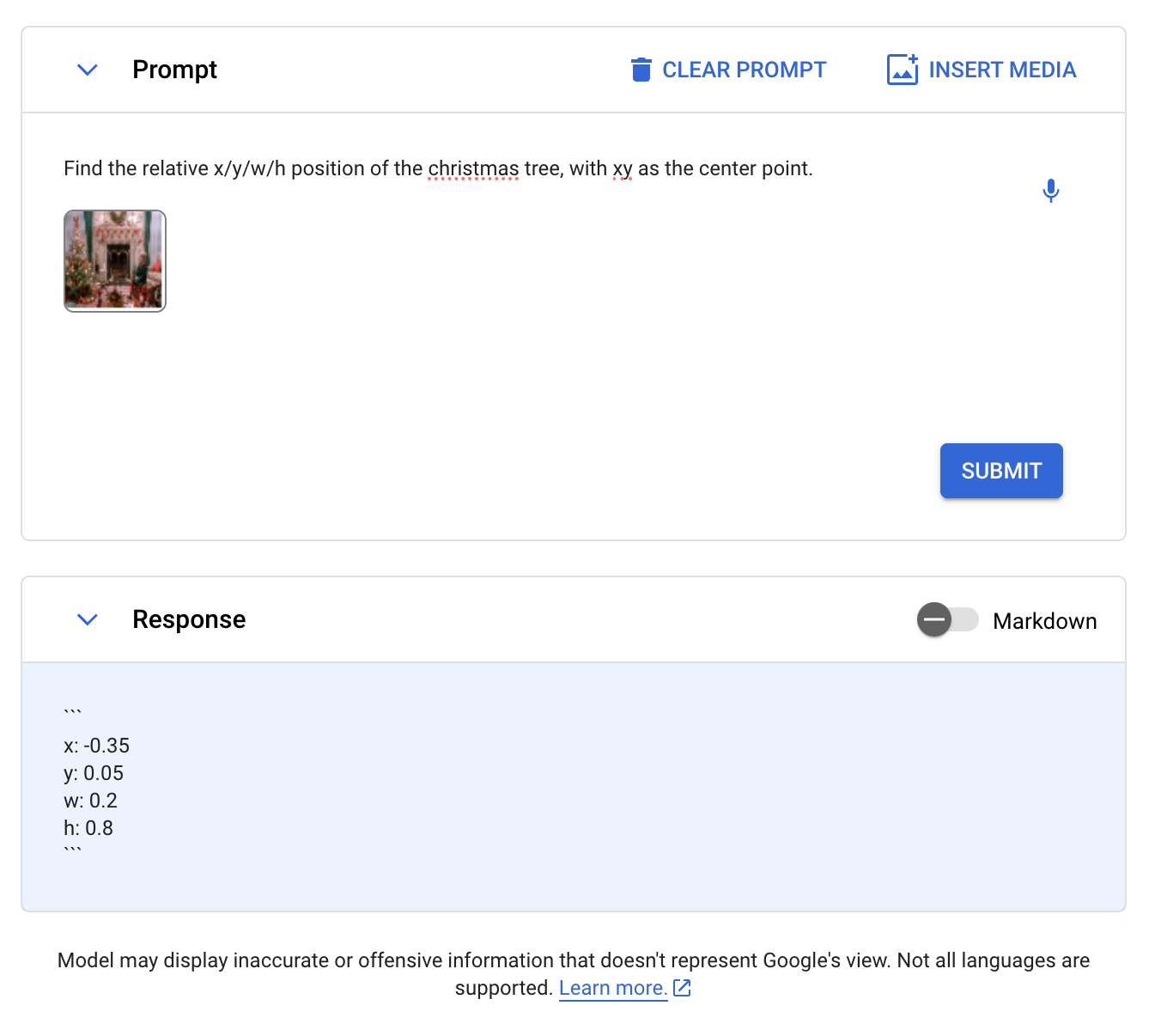
The resultant coordinates are invalid.
Conclusion
Gemini is a multimodal model developed by Google. Gemini can interact with text, images, audio, and code. With Gemini, you can ask questions about the contents of images, a powerful capability in computer vision applications.
In this guide, we evaluated how Gemini performs across a range of vision tasks, from VQA to OCR.
Interested in reading more about multimodal models? Explore our other multimodal content.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 13, 2023). First Impressions with Google’s Gemini. Roboflow Blog: https://blog.roboflow.com/first-impressions-with-google-gemini/