
Earlier this week, OpenAI dropped a bomb on the computer vision world: two new groundbreaking models that hint at what's to come as massive GPT3-esque Transformer models encroach on the vision domain. While DALL-E (a model that can generate images from text prompts) has garnered much of the attention this week, this post focuses on CLIP: a zero-shot classifier which is arguably even more consequential.
Until now, classifying images has involved collecting a custom dataset of hundreds, thousands, or even millions of labeled images that suitably represent your targeted classes and using it to train a supervised classification model (usually a convolutional neural network). This approach (and extensions of it like object detection) has led to the rapid proliferation of computer vision over the past decade (powering everything from self driving cars to augmented reality).
The downside of supervised training is that the resultant models do not generalize particularly well. If you show them an image from a different domain, they usually do no better than randomly guessing. This means you need to curate a wide variety of data that is sufficiently representative of the exact task your model will perform in the wild.
The difference between supervised vs unsupervised learning
Enter OpenAI CLIP
The recent introduction of CLIP (Contrastive Language-Image Pre-training) has disrupted this paradigm. It's a zero-shot model, meaning it can identify an enormous range of things it has never seen before.
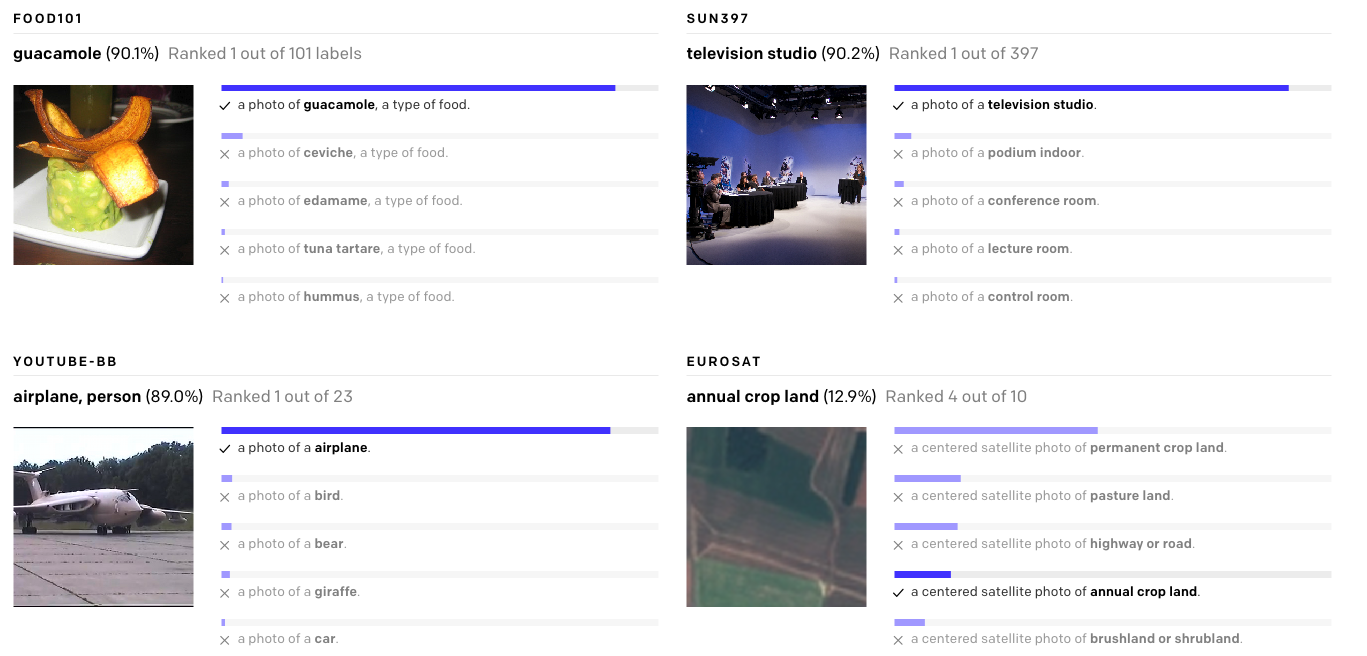
In traditional classifiers, the meaning of the labels is ignored (in fact, they're often simply discarded and replaced with integers internally). By contrast, CLIP creates an encoding of its classes and is pre-trained on over 400 million text to image pairs. This allows it to leverage transformer models' ability to extract semantic meaning from text to make image classifications out of the box without being fine-tuned on custom data.
All you need to do is define a list of possible classes, or descriptions, and CLIP will make a prediction for which class a given image is most likely to fall into based on its prior knowledge. Think of it as asking the model "which of these captions best matches this image?"
In this post, we will walk through a demonstration of how to test out CLIP's performance on your own images so you can get some hard numbers and an intuition for how well CLIP actually does on various use case. We found that CLIP does better than our custom trained ResNet classification models on a flower classification task. It also does surprisingly well over a range of more obscure and challenging tasks (including identifying mushroom species in pictures from our camera roll and identifying breeds of dogs and cats).
Resources in this tutorial:
- Public flower classification dataset
- CLIP benchmarking Colab notebook
- CLIP repo
- Corresponding YouTube
Assembling Your Dataset
To try out CLIP, you will need to bring a dataset of images that you want classified, partitioned into the classes that you would like to see.
If you do not already have a dataset, and would like to just try out the new technology, take a look at Roboflow's public computer vision datasets.
In this post, we'll be benchmarking CLIP on the public flower classification dataset. If using your own data, uploading your data to Roboflow is easy and free (up to 1000 images), and then you can follow the same flow in this blog.
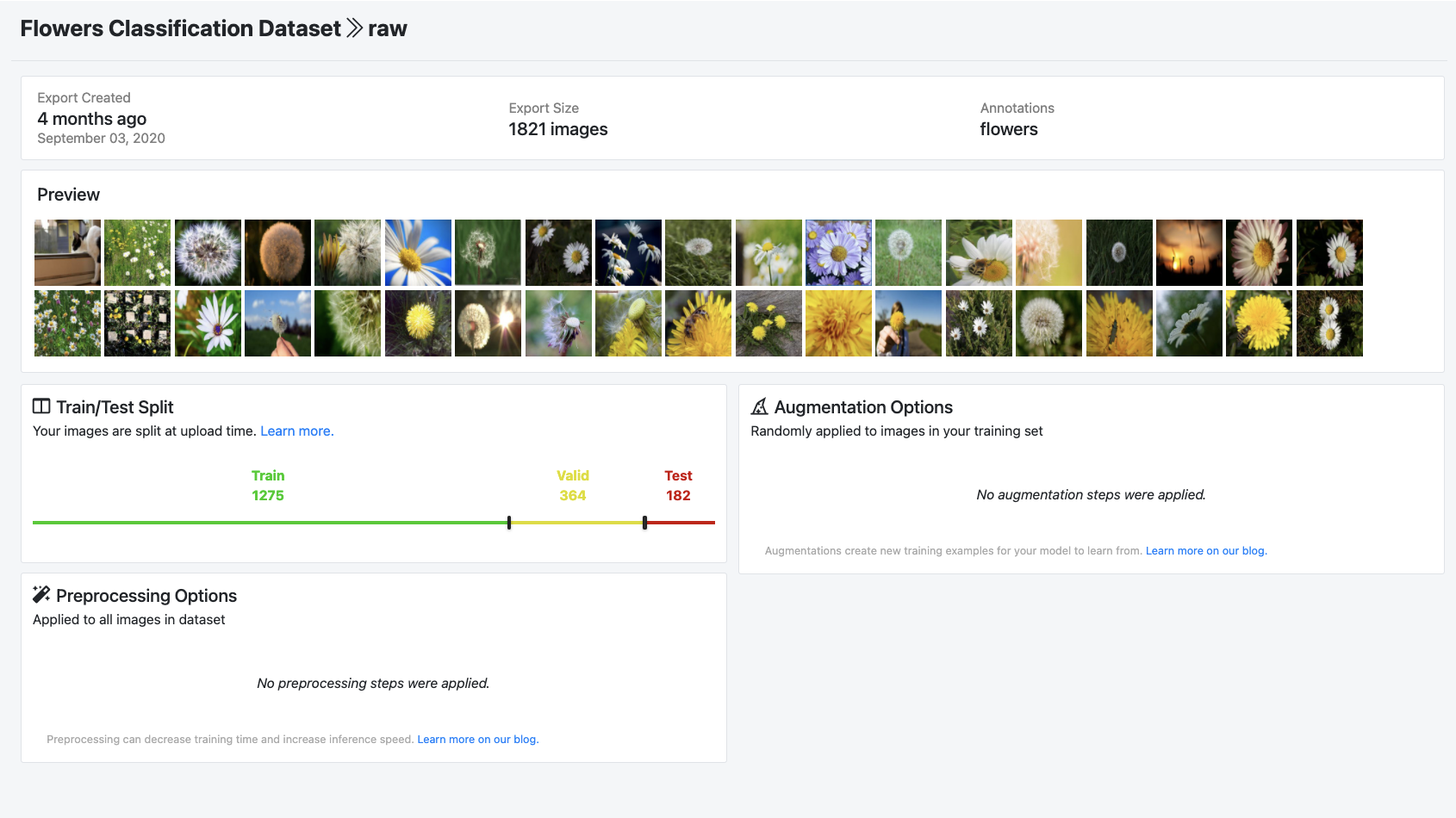
Once you've assembled your dataset, it's on to the CLIP benchmarking Colab notebook.
***Using Your Own Data***
To export your own data for this tutorial, sign up for Roboflow and make a public workspace, or make a new public workspace in your existing account. If your data is private, you can upgrade to a paid plan for export to use external training routines like this one or experiment with using Roboflow's internal training solution.
Installing CLIP Dependencies
To try CLIP out on your own data, make a copy of the notebook in your drive and make sure that under Runtime, the GPU is selected (Google Colab will give you a free GPU for use). Then, we make a few installs along with cloning the CLIP Repo.
Downloading Your Dataset into Colab
The next step is to download your classification dataset into Colab.
If you made a dataset in Roboflow, this is achieved by hitting Generate, then Download in the OpenAI CLIP Classification format. This will put all of your test images in a folder called test with separate subdirectories of images for each class in your dataset and give you a _tokenization.txt file that lets you experiment with "Prompt Engineering" which can drastically improve or degrade the model's performance.
We've also created a converter for object detection datasets which will create a textual description from the bounding boxes present. We had mixed results with these but they are certainly interesting to play with.
Additionally, we have made all of our open source datasets available to download for free in the CLIP format.
Inferring Class Labels with CLIP
The final step is to pass your test images through a predictions step.
CLIP takes an image and a list of possible class captions as inputs. You can define the class captions as you see fit in the _tokenization.txt file. Be sure to make sure they stay in the same order as the alphabetically sorted class_names (defined by the folder structure).
The notebook contains code to iterate over each of the class folders in the test set and pass the relevant images through a prediction step.
Experimenting with Ontologies and Results
When you use CLIP for your classification task, it is useful to experiment with different class captions for your classification ontology, and remember that CLIP was trained to differentiate between image captions.
On the flowers dataset, we tried the following ontologies and saw these results:
"daisy" vs "dandelion"]--> 46% accuracy (worse than guessing)"daisy flower" vs "dandelion flower"--> 64% accuracy"picture of a daisy flower" vs "picture of a dandelion flower"--> 97% accuracy
97% accuracy is higher than any other classification model that we have trained on this dataset.
These results show the importance of providing the right class descriptions to CLIP and express the richness of the pretraining procedure, a feature that is altogether lost in traditional, binary classification. OpenAI calls this process "prompt engineering".
Flipping the Script
CLIP may have many additional use cases including ranking images against a target query string, or sorting images among their uniqueness.
In the notebook, you'll see code defining two variables image_features and text_features. The cosine similarity between any pair of these features represents their semantic distance - and from our experience thus far, it is strikingly accurate. These are the early days...
Conclusion
If you find that CLIP's performance is not as high as you would like, you may still want to consider training a custom image classification model with supervision.
For more on CLIP research, consider reading the paper, see our guide on building an image search engine, and checking out OpenAI's blog post. And we'd love to hear if you discover anything interesting when playing around with the model! Be sure to drop us a line on twitter.
As always, happy inferencing!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Brad Dwyer. (Jan 8, 2021). How to Try CLIP: OpenAI's Zero-Shot Image Classifier. Roboflow Blog: https://blog.roboflow.com/how-to-use-openai-clip/