
Benefits to Existing Models
Polygons have traditionally been used for training image segmentation models, but polygons can also improve the training of object detection models (which predict bounding boxes). Object detection models are typically much faster and more widely supported, so they remain the best and most popular choice for solving many problems.
At first blush, this might seem confusing, why would you spend the extra time and effort annotating your images with polygons if your model is only able to predict boxes?
The answer is: because it gives your model more information about the objects it can use to learn from which helps them learn more and make better predictions.
Improved Augmentations with Polygon Annotations
Any augmentation that changes the size, shape, or orientation of an object will benefit from the additional information that polygons provide about the shapes and locations of objects.
This is best illustrated through a few examples of traditional augmentations performed on bounding boxes (top) vs polygons (bottom):
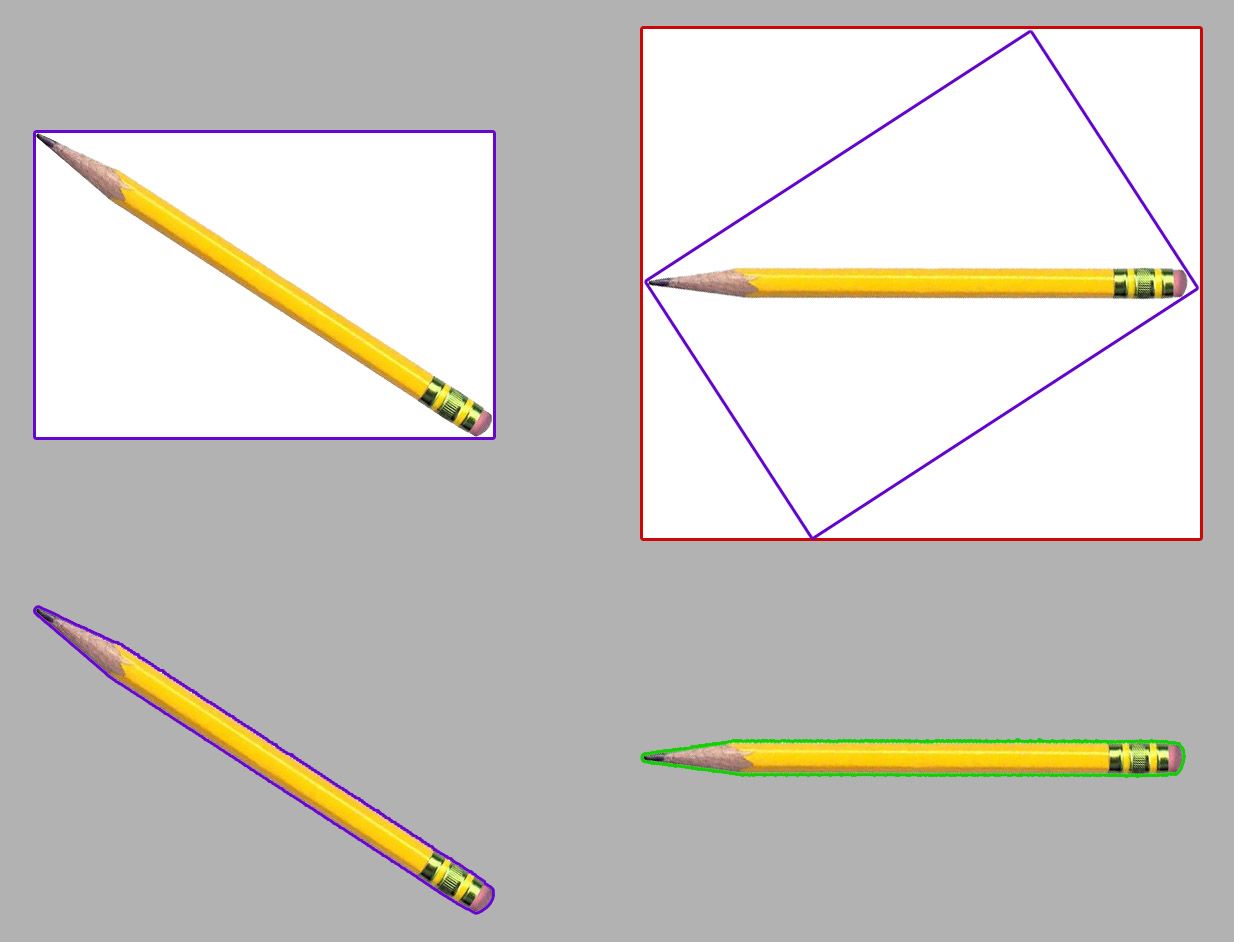
As you can see, the rotated polygon (green, bottom) retains a tight fit around the pencil, while the rotated bounding box (red, top) propagates white background pixels above and below the pencil into the transformed bounding box.
Note that there is no way for the bounding box rotation to reliably keep a tight fit when undergoing spatial augmentation because the augmentation code doesn't know where the edges of the object of interest lie in the box.
For example, imagine instead of a single pencil, the top-left bounding box contained two pencils making an X shape – the red rotated box would fit as tightly as possible to fully constrain the rotated cross; if your augmentation code instead optimized for the case in the image above, it would be throwing out useful pencil pixels from the 2-pencil X case.
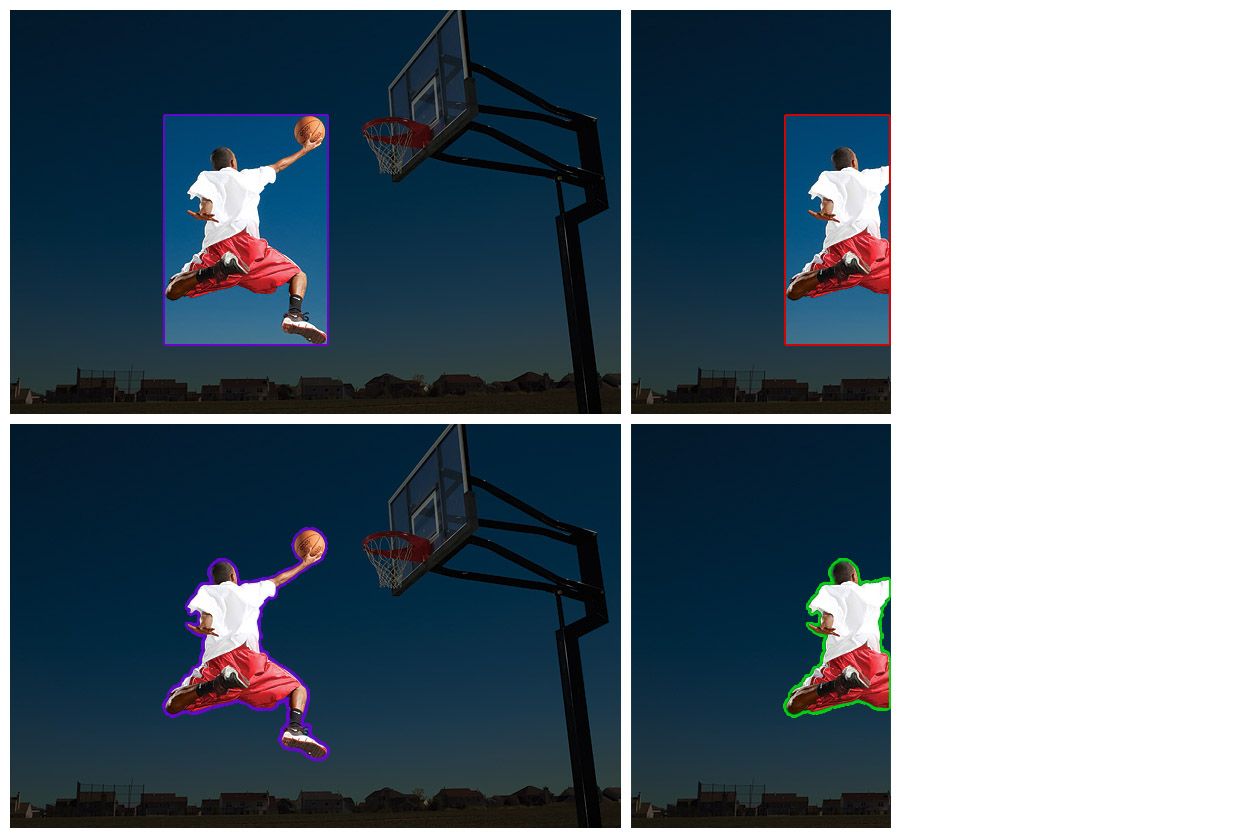
Here, we can see that when cropping the photo, the bounding box (top) is unable to constrain itself to the size of the remaining parts of the basketball player – leaving significant background pixels in the box above the head and below the legs – whereas the polygon annotation (bottom) remains tight after cropping.
Feeding loose bounding boxes into your model incentivizes it to learn to predict less tightly-fitting boxes and will degrade its performance.
The Double-Augmentation Problem
With rectangular annotations, the fit degrades each time you augment an image because there isn't any information about the portions of the box that represent the subject of interest and the portions of the box that enclose background pixels.
This means that, if you augment an image multiple times, the fit fit only gets worse and worse. For example, if you rotate a bounding-box annotated image 33 degrees and then rotate -33 degrees, you end up with the same image, but a much worse-fitting box:
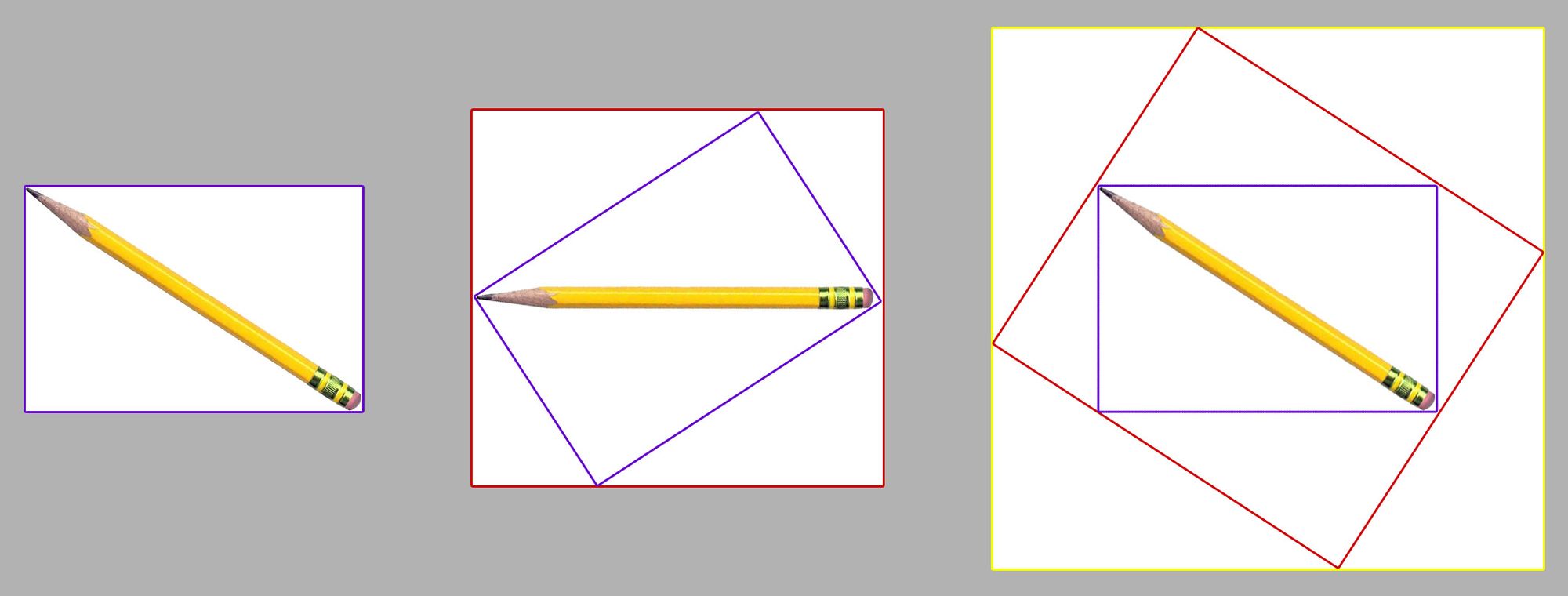
Polygons alleviate this problem, because the annotations are able to retain a tight fit after each transformation, only compositing to a box when fed into the model during training.
The more subsequent times you transform a bounding box's shape, the looser it will get, and the more your model's performance will degrade. Augmentations help teach your model more about how objects will look in different orientations and from different perspectives, at the expense of not fitting the objects as accurately.
Polygons give your object detection model the best of both worlds: tightly fitting annotations in a variety of orientations and perspectives.
New Augmentation Types with Polygon Annotations
Polygons also unlock wholly new augmentations like copy/paste, which we covered in our tutorial on synthetic dataset generation for computer vision.

The copy/paste augmentation (also called "context augmentation") puts your objects of interest on top of other images from your dataset to teach your model to recognize them in new contexts.
How to Use Polygons with Object Detection Models
Some new models like YOLOv5 have built-in functionality to take advantage of polygonal annotations. They will generally train better if you provide them with a dataset containing polygons instead of bounding boxes.
Most other object detection models' augmentation and training code are not yet able to take advantage of polygons; in this case, augmenting your images ahead of time with a tool like Roboflow can be very beneficial.
Roboflow Train also automatically takes full advantage of polygon annotations for object detection and also makes deploying the resulting model a breeze.
Experiment with Other Models
Polygons can always be converted back to bounding boxes, but bounding boxes cannot be as easily converted into polygons. Having polygon annotations available for your data can allow you to experiment with other model types (like instance segmentation or oriented (rotated) bounding boxes).
Polygons also greatly enhance Roboflow's isolate objects preprocessing step for use with classification projects by removing all of the background pixels.
You can find more models to try in our Model Library.
Cite this Post
Use the following entry to cite this post in your research:
Brad Dwyer. (Jul 14, 2022). Using Polygon Annotations for Object Detection in Computer Vision. Roboflow Blog: https://blog.roboflow.com/polygons-object-detection/