
Synthetic data generated with NVIDIA Omniverse Replicator can dramatically reduce the cost and time of building computer vision models for use cases like defect detection, where real examples of rare defects are hard to collect. This post shows how to combine Omniverse Replicator's 3D domain randomization with Roboflow: the TAA Omniverse Extension automates scene variation and pushes annotated images directly to a Roboflow project for training, with no coding required. The approach yields perfectly labeled, diverse training data at a fraction of the effort of manual collection.
Computer vision models require significant amounts of data to train. That data is often difficult to collect. Additionally, when creating datasets for training multimodal models – models that combine different types of input data such as images and text – to power robots or autonomous vehicles, the amount of data required is so large that labeling it by hand is not a realistic solution.
This is where synthetic data comes in. Synthetic data is extremely helpful for creating production ready computer models across industries. In the past, we've shown you how to generate synthetic data by randomizing object placement on image backgrounds, using state-of-the-art image generation models like Stable Diffusion, and with tools like Unity Perception.
Today we are highlighting the power of using NVIDIA Omniverse Replicator with Roboflow to combine real world data with synthetic 3D assets to train a high performing defect detection computer vision model.
Let's get started!
Why is Synthetic Data Helpful for Computer Vision?
NVIDIA recently hosted their global AI conference for developers, GTC, and presented the session 3D Synthetic Data: Simplifying and Accelerating the Training of Vision AI Models for Industrial Workflows [S51663]. They did a great job explaining the utility of synthetic data. Use your GTC login to view the session, click here to see the slides, or continue reading for a recap.

Synthetic data is especially useful when building computer vision models for use cases like defect detection because data on defects is usually not easy to find.
With synthetic data, you can quickly generate large amounts of data at a lower cost. Two major benefits of synthetic data is the diversity of data and the data comes with perfect annotations generated programmatically.
In the case of defect detection, you can generate synthetic images that feature the defects that you want to be able to identify without having to take hundreds or thousands of images of defects. Taking so many images may be infeasible for rare defects, especially.
Omniverse Replicator is a great tool for synthetic data generation thanks to:
- Cloud native
- Import files from CAD, Houdini, and Blender
- Domain and feature randomization
- Custom annotation writers
- Multi-GPU support
Now that we've covered the benefits of synthetic data, let's take a look how to use it in practice.
Building a Computer Vision Model with Synthetic Data
The NVIDIA presentation highlights the steps of the model training pipeline: importing data, building a scene, randomizing domains, generating data, and training a model.
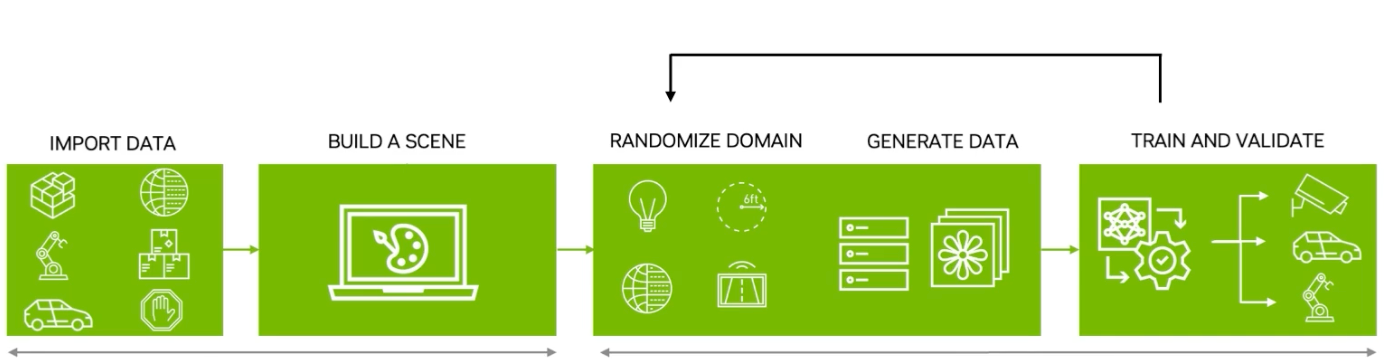
With this process in mind, you can apply it to any domain. For this example, NVIDIA created a defect detection model for automotive panel manufacturers.
They started with 50 ground truth images (below) and uploaded them to Roboflow as a base for the dataset. They trained a model, using Roboflow Train, and validated that 50 ground truth images was not enough to meet the needs of their production-ready model.
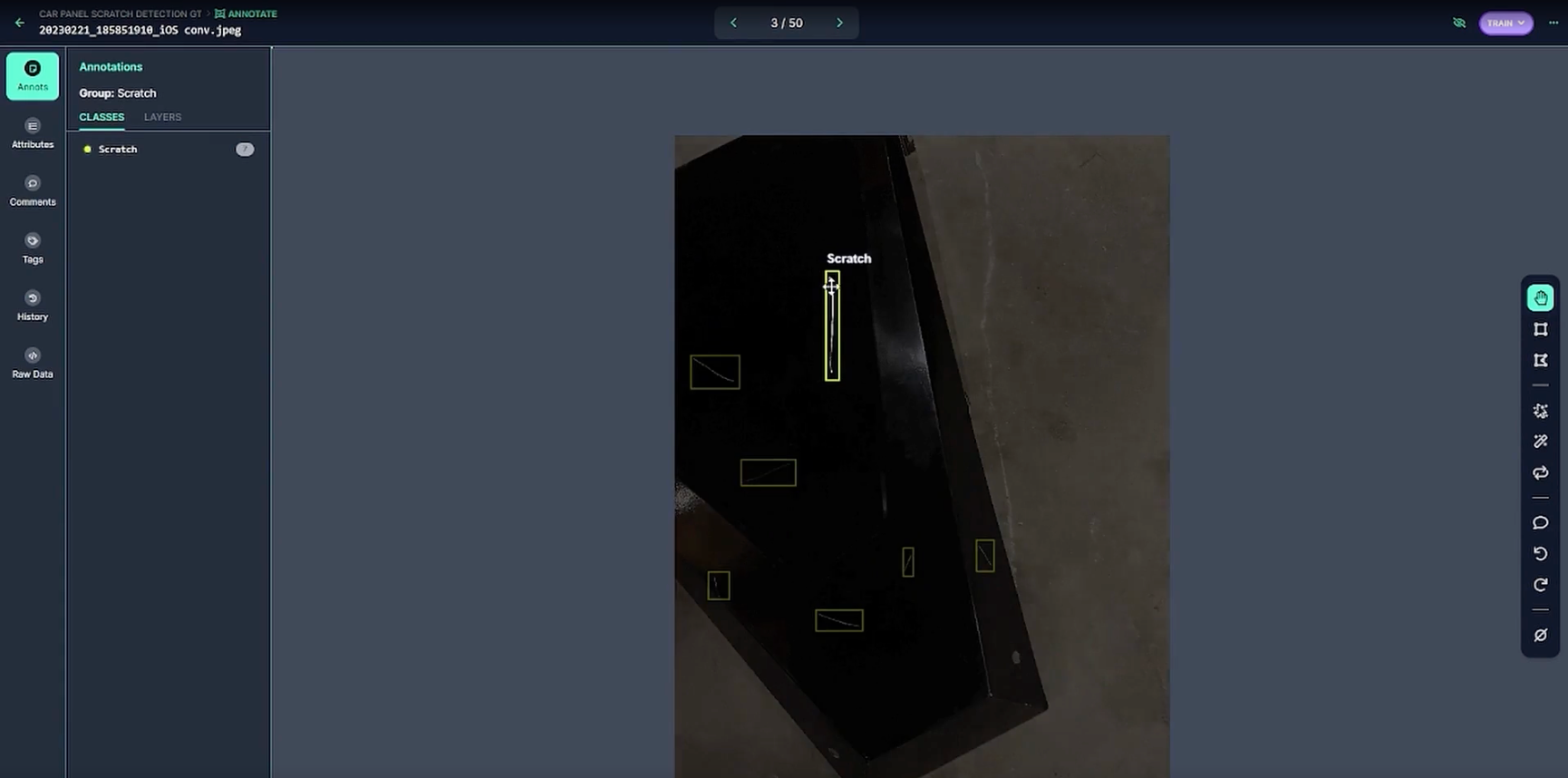
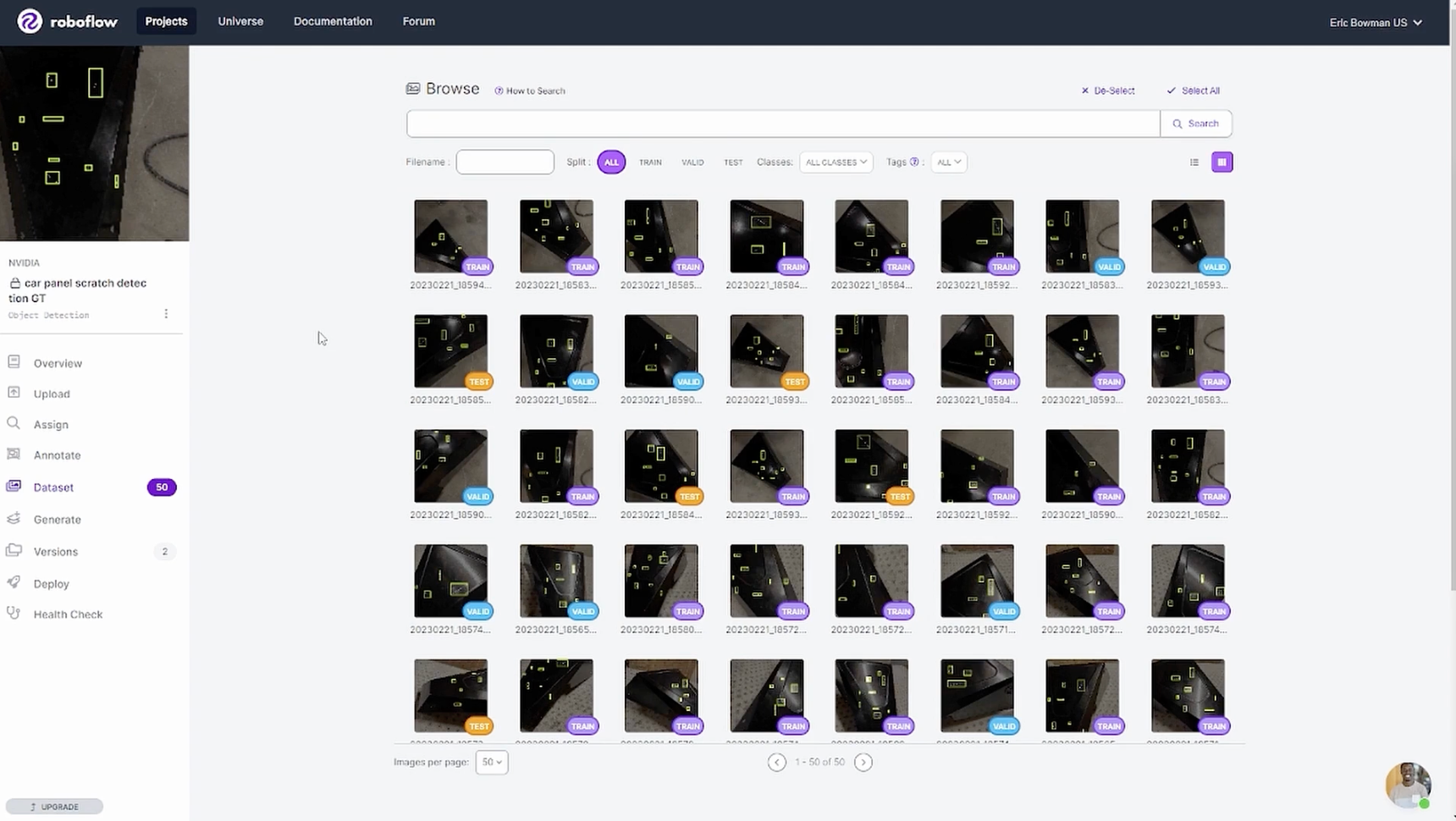
Generating Synthetic Data with NVIDIA Omniverse Replicator
In order to generate more training data, the team at NVIDIA imported 3D files to build a scene and then randomized the different domains (color, location, texture, lighting, camera, etc) in the scene. This detailed level of domain randomization is helpful to account for edge cases which could lead the model to fail in production.
Using the NVIDIA Omniverse Replicator UI, the team was able to control for critical domains, like lighting and reflection, which helped make the model accurate in real world conditions.
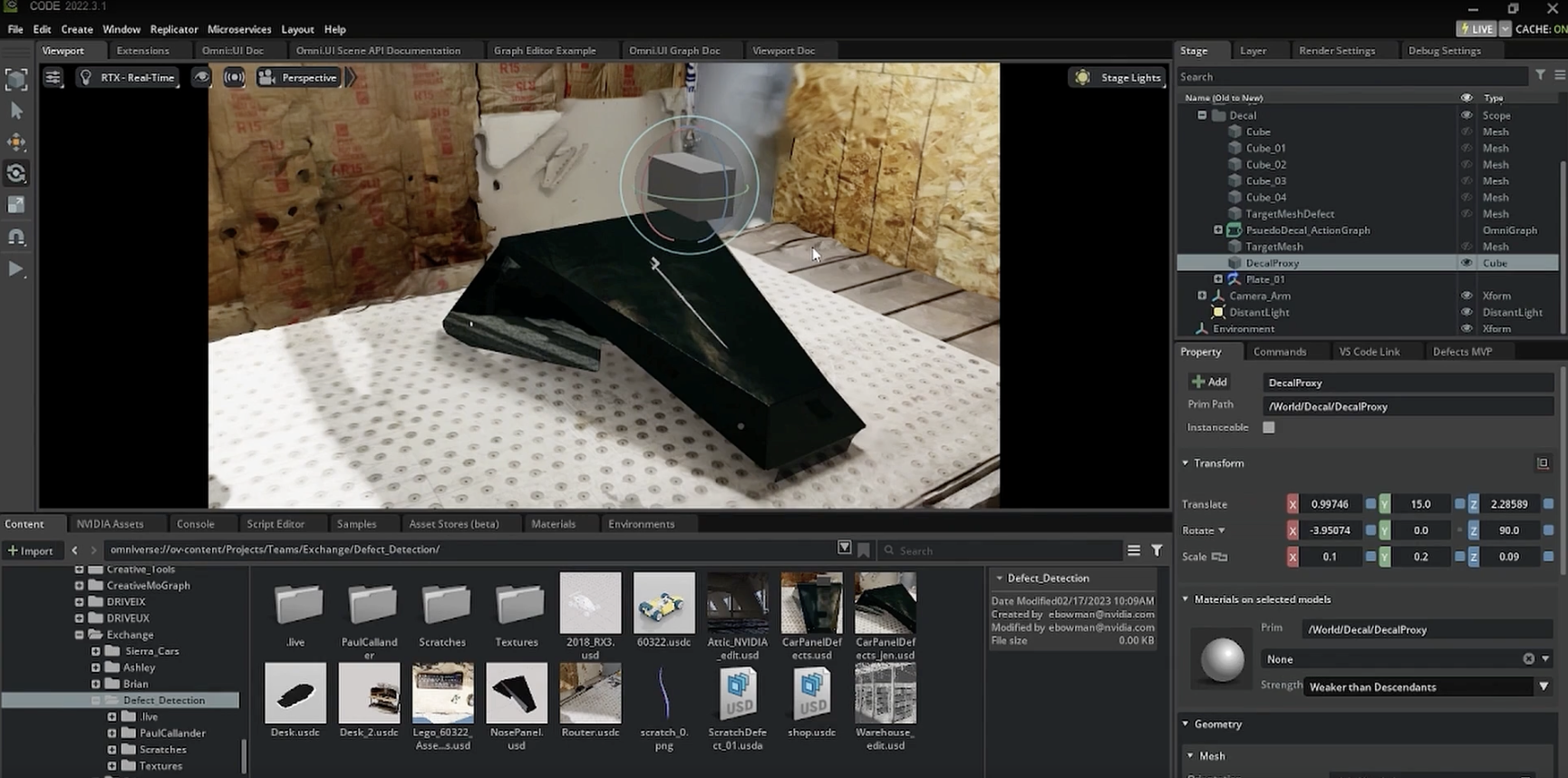
Training a Model with Synthetic Data
Once the synthetic data has been generated and uploaded into Roboflow, model training with synthetic data is the same as real world data. The NVIDIA team created multiple models to test which variables would lead to better performance. This includes expanding the real world data, using different augmentations, increasing scene variables, and more.
After kicking off parallel training runs with different variations, they were able to produce a high performing model.
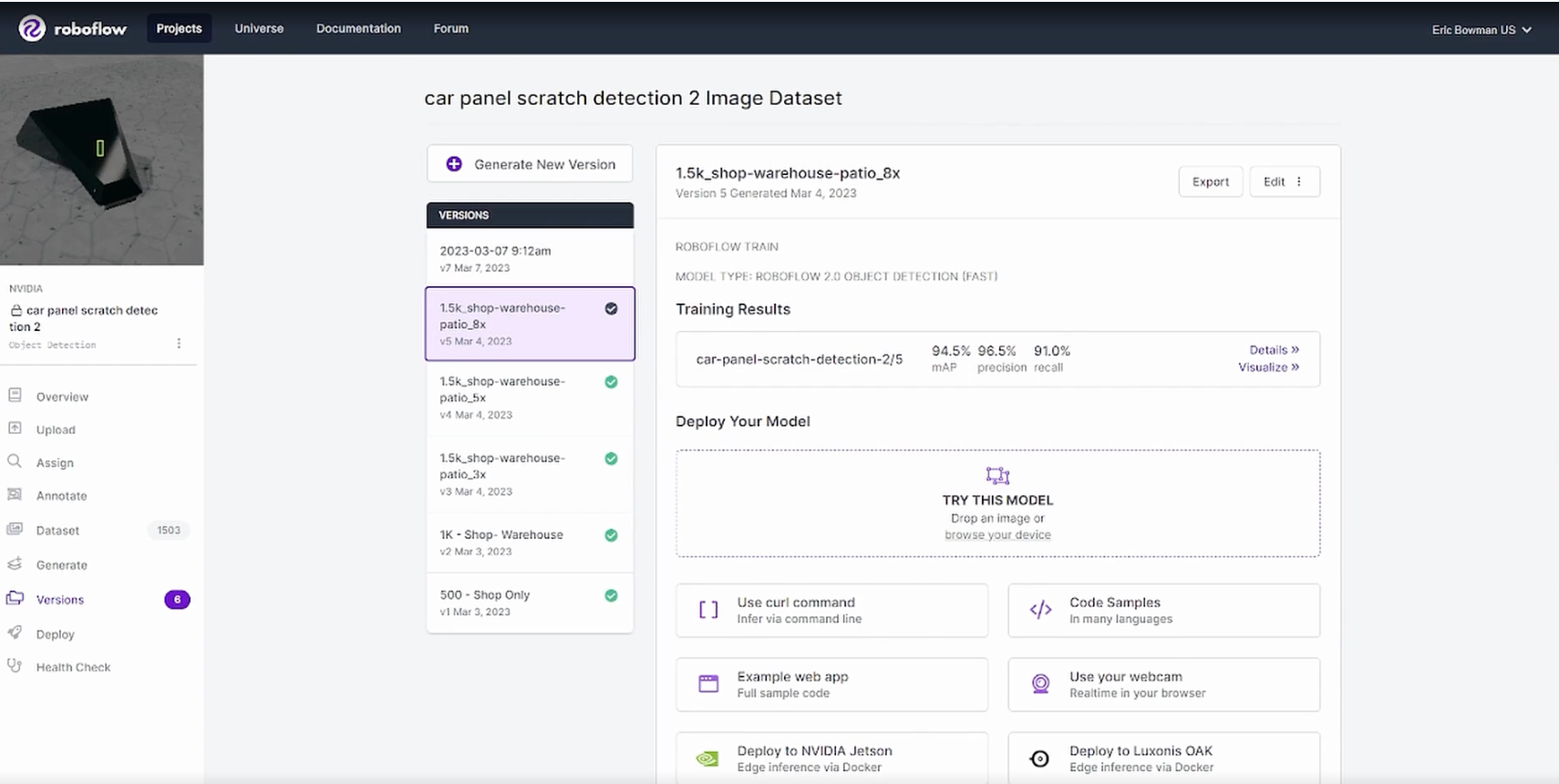
Regardless of Training Results statistics, it's important to test models on real world data in different environments, lighting, and with different devices. This will help ensure the model is robust and performs well across the various locations it may be deployed.
Additional NVIDIA Omniverse Replicator Examples
The synthetic data generation process is custom to each use case and how you build your pipeline is dependent on your overall computer vision pipeline. Let's take a look at two real world ways you can do this today.
TAA Omniverse and Roboflow Extension
Below is an example of generating synthetic data and automatically sending it to Roboflow with the TAA Omniverse Extension. This extension allows you automate domain randomization with a simple UI and automate uploading the data to the correct Roboflow Project for model training. No coding required.
0:00/1×
Open Source Python Script
Dave's Armoury used synthetic data to build an autonomous recliner that uses object tracking for navigation. You can view the dataset and use the open source python script to randomize a scene in Omniverse Replicator yourself!
Conclusion
Synthetic data is a great way to to quickly generate large amounts of diverse data with perfect annotations generated programmatically. This reduces the time it takes to get a model to production, helps manage edge cases, and reduces the cost and overhead of managing a manual data labeling operation.
Give synthetic data a try in your next project and let us know how it goes. If you need any assistance, we encourage you to ask a question in the Roboflow Discussion forum.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Mar 31, 2023). Synthetic Data Generation with NVIDIA and Roboflow. Roboflow Blog: https://blog.roboflow.com/roboflow-nvidia-omniverse-replicator/